- Области применения НРС

Содержание
- 2. ОБЛАСТИ ПРИМЕНЕНИЯ НРС Проектирование инженерных сооружений, автомобилей, судов и летательных аппаратов, комплексный экологический мониторинг атмосферы и
- 3. CОВРЕМЕННЫЕ СУПЕРКОМПЬЮТЕРЫ Три группы компьютеров для НРС: векторные; высокопроизводительные универсальные; специализированные Векторные: создатель Сеймур Крей, SX-9
- 4. ОСНОВНЫЕ КЛАССЫ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ Основным параметром классификации паралелльных компьютеров является наличие общей (SMPОсновным параметром классификации паралелльных
- 5. Системы с распределенной памятью (МРР) Оперативная память Кэш-память Процессор Оперативная память Кэш-память Процессор
- 6. Массивно-параллельные системы МPP
- 7. Системы с общей памятью (SМР) Кэш-память Процессор Общая (разделяемая) оперативная память Кэш-память Процессор
- 8. Симметричные мультипроцессорные системы (SMP)
- 9. Системы с NUMA-архитектурой Оперативная память Оперативная память
- 10. Системы с неоднородным доступом к памяти (NUMA)
- 11. КЛАСТЕРННЫЕ СУПЕРКОМПЬЮТЕРЫ Появление высокопроизводительных кластеров не явилось большой неожиданностью. Вопрос об объединении сетевых ресурсов в единый
- 12. Общая структура кластерного суперкомпьютера Сеть управления Сеть обмена данными Управляющий узел Вычислитель- ный узел 1 Вычислитель-
- 13. Кластерные системы
- 14. Суперкомпьютер СКИФ МГУ Общая характеристика
- 15. Blade-шасси, СКИФ МГУ 10 модулей T-Blade, 960 GFlop/s
- 16. Скиф МГУ Площадь зала 98 кв. метров
- 17. Суперкомпьютер Roadrunner, IBM (10 июня 2008, Источник: BBC News) Пиковая производительность 1,5 Pflop/s 3456 оригинальных серверов
- 19. Платформы НРС На формирование образа суперкомпьютеров близкого будущего повлияют несколько ключевых технологических факторов: технологии миниатюризации серверов;
- 20. ВЫЧИСЛИТЕЛЬНЫЕ УЗЛЫ (СЕРВЕРА) История создания блейд - серверов Лезвия изобрел Крис Хипп во время Internet-бума конца
- 21. Одно из первых лезвий
- 22. Суперкомпьютер Green Destiny — кластер Beowulf (на лезвиях)
- 23. Основные требования к блейд – серверам (НР) Гибкость Снижение энергопотребления и ресурсов охлаждения Средства консолидированного управления
- 24. Сервер BladeCenter HS21 для кластера IBM 1350 Схема сервера
- 25. Кластер состоит из 6 «блейд-серверов» IBM BladeCenter HS21xx, один из которых управляющий, один запасной и четыре
- 26. Характеристики BladeCenter HS21
- 27. Программное обеспечение Операционная система - Red Hat Enterprise Linux Параллельная файловая система - IBM General Parallel
- 28. НР Полка c7000 — вид спереди Два форм-фактора блейдов Полноразмерный блейд-сервер (до 8 в одной полке)
- 29. Полка c7000 — вид сзади Восемь коммутационных отсеков До 4 резервированных фабрик ввода/вывода Ethernet, Fibre Channel,
- 30. Топология серверов НР Integrity
- 31. Integrity rx7640 имеют две связанные напрямую ячейки; координатные коммутаторы не используются (восемь процессорных разъемов, в стойке
- 32. КОММУНИКАЦИОННЫЕ ТЕХНОЛОГИИ Основные: Fast EthertnetОсновные: Fast Ethertnet, Gigabit EthernetОсновные: Fast Ethertnet, Gigabit Ethernet, MyrinetОсновные: Fast Ethertnet,
- 33. Gigabit Ethernet Производители оборудования: Intel, 3COM и др. Показатели производительности: Пиковая пропускная способность - 1 Gbit/sec
- 34. Myrinet 2000 Производители оборудования: Myricom Показатели производительности: Пиковая пропускная способность - 2 Gbit/sec, полный дуплекс. Аппаратная
- 35. InfiniBand Производители оборудования: InfiniBand Trade Association Показатели производительности: Пиковая пропускная способность каналов 10 GB/sec, латентность -
- 36. Архитектура InfiniBand Адаптер канала хоста (Host Channel Adapter, HCA). Инициация и организация обмена. Взаимодействие: с аналогичными
- 37. Архитектура InfiniBand Целевой адаптер канала (Target Channel Adapter, TCA). Используется для подключения не серверов, а внешних
- 38. Модуль InfiniBand на 24 канала
- 40. Скачать презентацию

ОБЛАСТИ ПРИМЕНЕНИЯ НРС
Проектирование инженерных сооружений, автомобилей, судов и летательных аппаратов, комплексный
Проектирование инженерных сооружений, автомобилей, судов и летательных аппаратов, комплексный

CОВРЕМЕННЫЕ СУПЕРКОМПЬЮТЕРЫ
Три группы компьютеров для НРС: векторные; высокопроизводительные универсальные; специализированные
Векторные:
CОВРЕМЕННЫЕ СУПЕРКОМПЬЮТЕРЫ
Три группы компьютеров для НРС: векторные; высокопроизводительные универсальные; специализированные
Векторные:

ОСНОВНЫЕ КЛАССЫ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
Основным параметром классификации паралелльных компьютеров является наличие общей
ОСНОВНЫЕ КЛАССЫ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
Основным параметром классификации паралелльных компьютеров является наличие общей
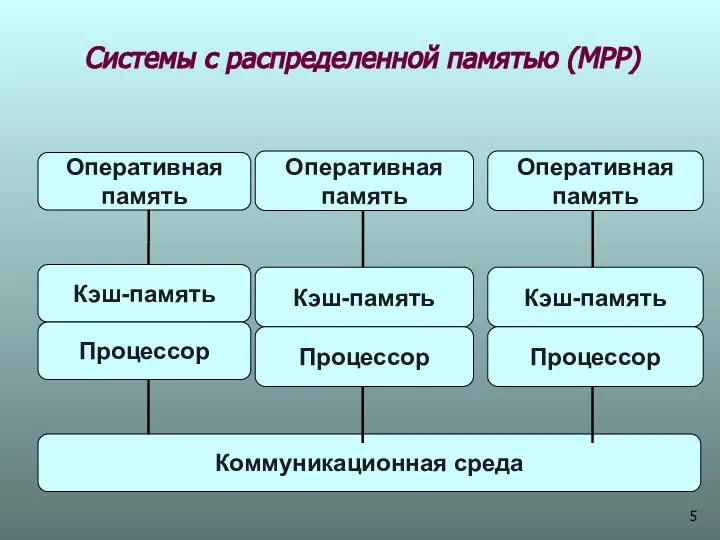
Системы с распределенной памятью (МРР)
Оперативная
память
Кэш-память
Процессор
Оперативная
память
Кэш-память
Процессор
Системы с распределенной памятью (МРР)
Оперативная
память
Кэш-память
Процессор
Оперативная
память
Кэш-память
Процессор
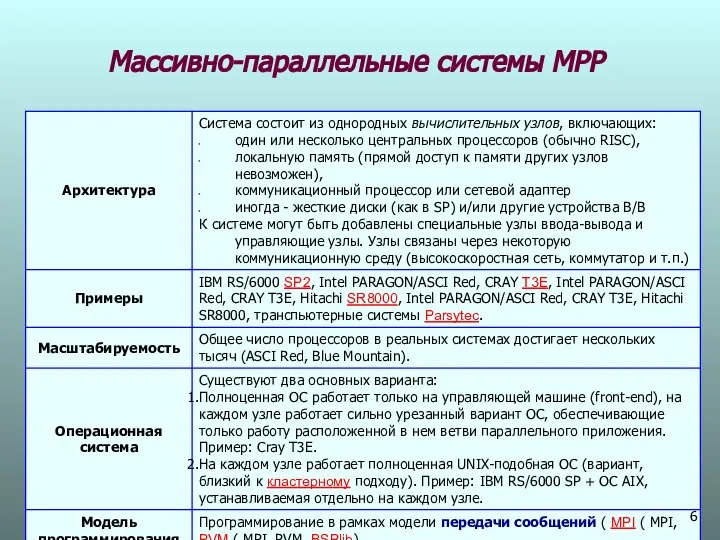
Массивно-параллельные системы МPP
Массивно-параллельные системы МPP
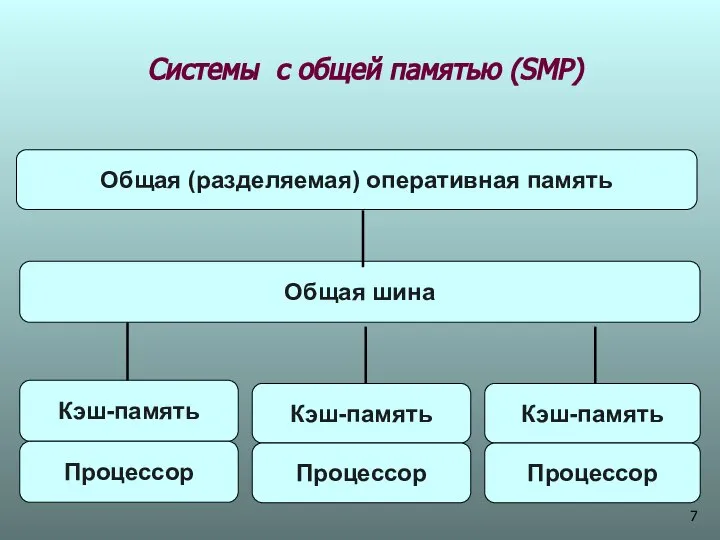
Системы с общей памятью (SМР)
Кэш-память
Процессор
Общая (разделяемая) оперативная память
Кэш-память
Процессор
Системы с общей памятью (SМР)
Кэш-память
Процессор
Общая (разделяемая) оперативная память
Кэш-память
Процессор

Симметричные мультипроцессорные системы (SMP)
Симметричные мультипроцессорные системы (SMP)
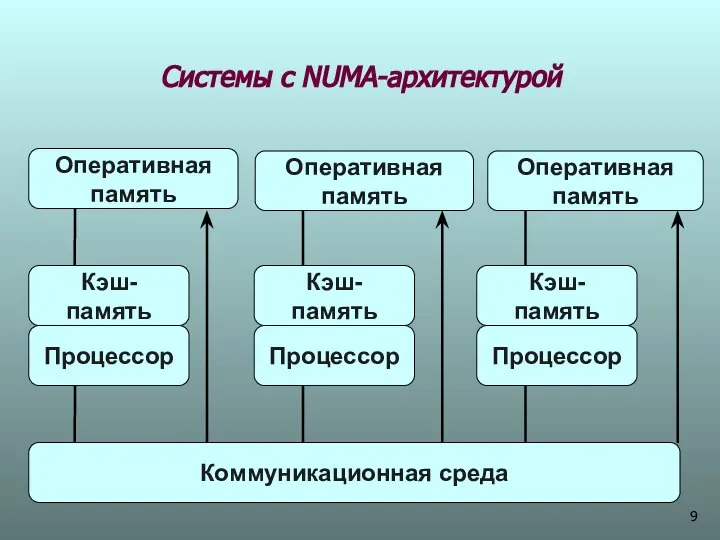
Системы с NUMA-архитектурой
Оперативная
память
Оперативная
память
Системы с NUMA-архитектурой
Оперативная
память
Оперативная
память

Системы с неоднородным доступом к памяти (NUMA)
Системы с неоднородным доступом к памяти (NUMA)

КЛАСТЕРННЫЕ СУПЕРКОМПЬЮТЕРЫ
Появление высокопроизводительных кластеров не явилось большой неожиданностью. Вопрос об объединении
КЛАСТЕРННЫЕ СУПЕРКОМПЬЮТЕРЫ
Появление высокопроизводительных кластеров не явилось большой неожиданностью. Вопрос об объединении
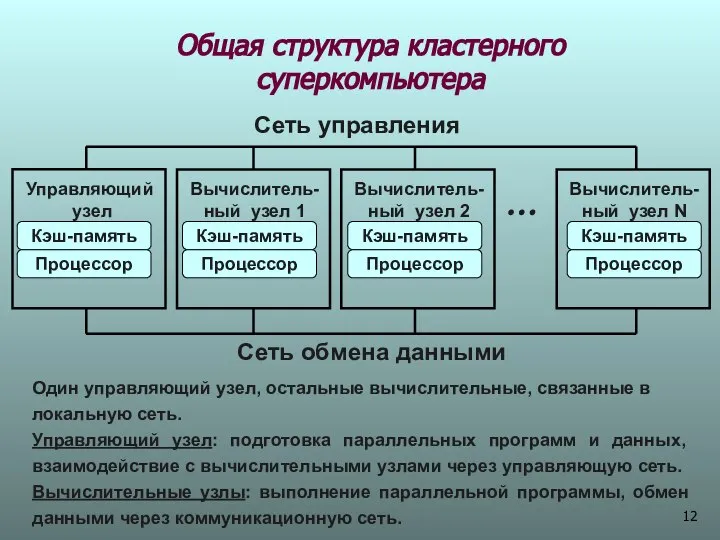
Общая структура кластерного суперкомпьютера
Сеть управления
Сеть обмена данными
Управляющий
узел
Вычислитель-
ный узел 1
Вычислитель-
ный узел
Общая структура кластерного суперкомпьютера
Сеть управления
Сеть обмена данными
Управляющий
узел
Вычислитель-
ный узел 1
Вычислитель-
ный узел

Кластерные системы
Кластерные системы

Суперкомпьютер СКИФ МГУ
Общая характеристика
Суперкомпьютер СКИФ МГУ
Общая характеристика

Blade-шасси, СКИФ МГУ
10 модулей T-Blade, 960 GFlop/s
Blade-шасси, СКИФ МГУ
10 модулей T-Blade, 960 GFlop/s

Скиф МГУ Площадь зала 98 кв. метров
Скиф МГУ Площадь зала 98 кв. метров

Суперкомпьютер Roadrunner, IBM
(10 июня 2008, Источник: BBC News)
Пиковая производительность 1,5
Суперкомпьютер Roadrunner, IBM
(10 июня 2008, Источник: BBC News)
Пиковая производительность 1,5


Платформы НРС
На формирование образа суперкомпьютеров близкого будущего повлияют несколько ключевых технологических
Платформы НРС
На формирование образа суперкомпьютеров близкого будущего повлияют несколько ключевых технологических

ВЫЧИСЛИТЕЛЬНЫЕ УЗЛЫ (СЕРВЕРА)
История создания блейд - серверов
Лезвия изобрел Крис Хипп
ВЫЧИСЛИТЕЛЬНЫЕ УЗЛЫ (СЕРВЕРА)
История создания блейд - серверов
Лезвия изобрел Крис Хипп

Одно из первых лезвий
Одно из первых лезвий

Суперкомпьютер Green Destiny — кластер Beowulf (на лезвиях)
Суперкомпьютер Green Destiny — кластер Beowulf (на лезвиях)

Основные требования к блейд – серверам (НР)
Гибкость
Снижение энергопотребления и ресурсов охлаждения
Средства
Основные требования к блейд – серверам (НР)
Гибкость
Снижение энергопотребления и ресурсов охлаждения
Средства
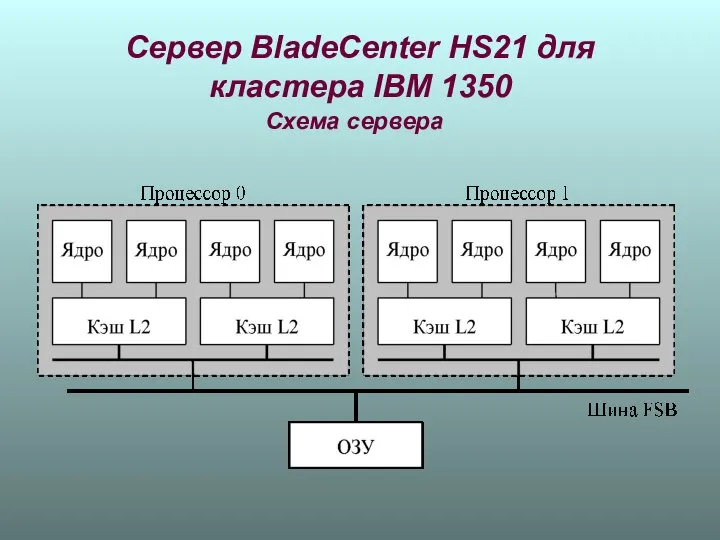
Сервер BladeCenter HS21 для кластера IBM 1350
Схема сервера
Сервер BladeCenter HS21 для кластера IBM 1350
Схема сервера

Кластер состоит из 6 «блейд-серверов» IBM BladeCenter HS21xx, один из которых
Кластер состоит из 6 «блейд-серверов» IBM BladeCenter HS21xx, один из которых

Характеристики BladeCenter HS21
Характеристики BladeCenter HS21

Программное обеспечение
Операционная система - Red Hat Enterprise Linux
Параллельная файловая система
Программное обеспечение
Операционная система - Red Hat Enterprise Linux
Параллельная файловая система
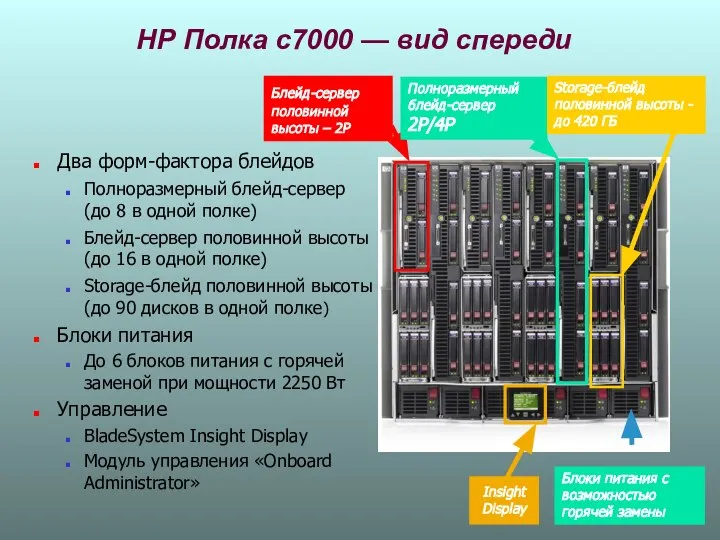
НР Полка c7000 — вид спереди
Два форм-фактора блейдов
Полноразмерный блейд-сервер (до
НР Полка c7000 — вид спереди
Два форм-фактора блейдов
Полноразмерный блейд-сервер (до
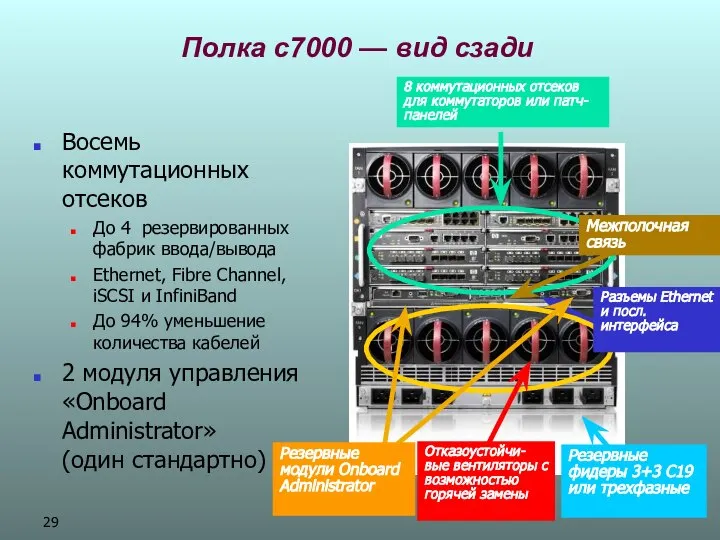
Полка c7000 — вид сзади
Восемь коммутационных отсеков
До 4 резервированных фабрик ввода/вывода
Ethernet,
Полка c7000 — вид сзади
Восемь коммутационных отсеков
До 4 резервированных фабрик ввода/вывода
Ethernet,
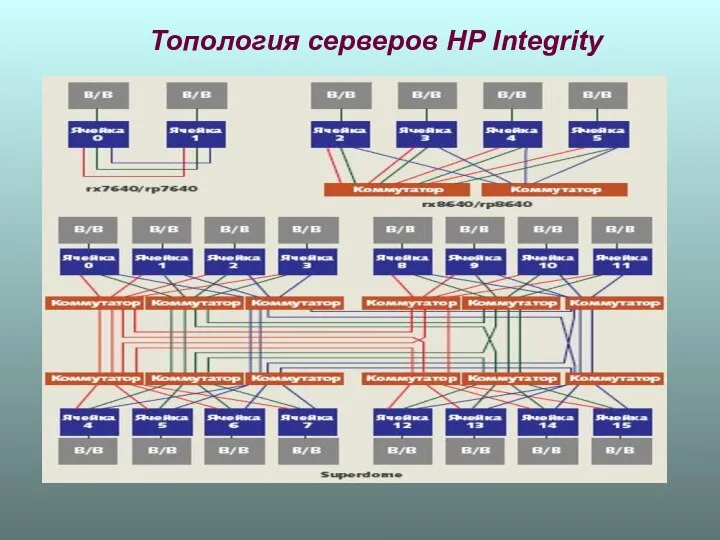
Топология серверов НР Integrity
Топология серверов НР Integrity

Integrity rx7640 имеют две связанные напрямую ячейки; координатные коммутаторы не используются
Integrity rx7640 имеют две связанные напрямую ячейки; координатные коммутаторы не используются

КОММУНИКАЦИОННЫЕ ТЕХНОЛОГИИ
Основные: Fast EthertnetОсновные: Fast Ethertnet, Gigabit EthernetОсновные: Fast Ethertnet, Gigabit
КОММУНИКАЦИОННЫЕ ТЕХНОЛОГИИ
Основные: Fast EthertnetОсновные: Fast Ethertnet, Gigabit EthernetОсновные: Fast Ethertnet, Gigabit

Gigabit Ethernet
Производители оборудования: Intel, 3COM и др.
Показатели производительности: Пиковая
Gigabit Ethernet
Производители оборудования: Intel, 3COM и др.
Показатели производительности: Пиковая

Myrinet 2000
Производители оборудования: Myricom
Показатели производительности: Пиковая пропускная способность -
Myrinet 2000
Производители оборудования: Myricom
Показатели производительности: Пиковая пропускная способность -

InfiniBand
Производители оборудования: InfiniBand Trade Association
Показатели производительности: Пиковая пропускная способность каналов
InfiniBand
Производители оборудования: InfiniBand Trade Association
Показатели производительности: Пиковая пропускная способность каналов

Архитектура InfiniBand
Адаптер канала хоста (Host Channel Adapter, HCA). Инициация и
Архитектура InfiniBand
Адаптер канала хоста (Host Channel Adapter, HCA). Инициация и

Архитектура InfiniBand
Целевой адаптер канала (Target Channel Adapter, TCA).
Используется для
Архитектура InfiniBand
Целевой адаптер канала (Target Channel Adapter, TCA).
Используется для

Модуль InfiniBand на 24 канала
Модуль InfiniBand на 24 канала
 Вид искусства дизайн
Вид искусства дизайн ООП. Класс. Объект класса. Конструктор класса. Поля. Методы
ООП. Класс. Объект класса. Конструктор класса. Поля. Методы Проектирование котлованов
Проектирование котлованов Презентация Стекло
Презентация Стекло Портфолио Дробязко - презентация для начальной школы
Портфолио Дробязко - презентация для начальной школы Дом кукол
Дом кукол Право собственности на землю.
Право собственности на землю.  Глубинная психология
Глубинная психология  Законодательные и нормативно-правовые акты, регулирующие проведение ресурсосбережения на объектах коммунального хозяйства
Законодательные и нормативно-правовые акты, регулирующие проведение ресурсосбережения на объектах коммунального хозяйства Преобразование графиков функций Учитель математики Шахова Т. А. Гимназия №3 Г. Мурманск
Преобразование графиков функций Учитель математики Шахова Т. А. Гимназия №3 Г. Мурманск  ЭКСПЛУАТАЦИЯ БЕСКОНТАКТНЫХ ТОКОСЪЁМНИКОВ СЕМЕЙСТВА КОНТРОЛЬНО-ИЗМЕРИТЕЛЬНЫХ СИСТЕМ «АГАТ
ЭКСПЛУАТАЦИЯ БЕСКОНТАКТНЫХ ТОКОСЪЁМНИКОВ СЕМЕЙСТВА КОНТРОЛЬНО-ИЗМЕРИТЕЛЬНЫХ СИСТЕМ «АГАТ Чайная церемония в Китае и Японии
Чайная церемония в Китае и Японии Романтизм в русской литературе
Романтизм в русской литературе Красный Крест
Красный Крест Тарас Григорович Шевченко — геніальний художник
Тарас Григорович Шевченко — геніальний художник Украина – Россия: состояние и перспективы отношений
Украина – Россия: состояние и перспективы отношений анализ наиболее эффективных решений в плане международного торгового сотрудничества в качестве посредника
анализ наиболее эффективных решений в плане международного торгового сотрудничества в качестве посредника Басқарудың стильдері
Басқарудың стильдері Особенности проведения закрытых торгов
Особенности проведения закрытых торгов Как принимать платежи Яндекс.Деньгами без подключения? Инструменты. Финансовые схемы. Примеры.
Как принимать платежи Яндекс.Деньгами без подключения? Инструменты. Финансовые схемы. Примеры. Общая фармакология
Общая фармакология Устный счёт МОУ СОШ №6 Метелкина Н.А.
Устный счёт МОУ СОШ №6 Метелкина Н.А. Кабельна система житлового містечка «Петрівський квартал» з розробкою питання охорони на оптоволоконних датчиків
Кабельна система житлового містечка «Петрівський квартал» з розробкою питання охорони на оптоволоконних датчиків Музей Солнца
Музей Солнца Стрілковий годинник
Стрілковий годинник Презентация Основные средства предприятия
Презентация Основные средства предприятия Синтез регулятора на основе модели объекта управления и желаемого вида передаточной функции замкнутой системы
Синтез регулятора на основе модели объекта управления и желаемого вида передаточной функции замкнутой системы Презентация Интеграционные процессы в мировой экономике
Презентация Интеграционные процессы в мировой экономике