- Принципы построения параллельных вычислительных систем.

Содержание
- 2. Структура предметной области (Параллельные вычисления) Математические основы параллельных вычислений Архитектура параллельных вычислительных систем Технологии параллельного программирования
- 3. Литература В ИБЦ: Воеводин В. В. Параллельные вычисления. Богачев К. Ю. Основы параллельного программирования. Гергель В.
- 4. Что такое параллельные вычисления? Параллельные вычисления – процесс обработки данных, в котором могут одновременно выполняться несколько
- 5. Параллельные вычислительные системы Параллельные вычисления – процесс обработки данных, в котором одновременно выполняется более одной операции.
- 6. Теоретические и практические проблемы параллельных вычислений Разработка параллельных вычислительных систем (ПВС) Анализ эффективности параллельных вычислений Разработка
- 7. Показатели производительности параллельного выполнения Ускорение (Speedup) - за счёт параллельного выполнения программы в N потоках: a(N)
- 8. Оценки производительности. Гипотеза Мински. Потери производительности при организации параллелизма Гипотеза Марвина Ли Мински (Marvin Lee Minsky,
- 9. Оценки производительности. Закон Амдала. Максимальный теоретический выигрыш для сочетания параллельных вычислений с последовательными: Закон Амдала: если
- 10. Автор закона (конец 1960 г.г.) – главный разработчик мейнфреймов серии IBM/360 Джин Амдал (Gene Amdahl), основатель
- 11. Закон Амдала (графики от riki-koen.livejournal.com/75235.html) АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1
- 12. р=0.1, с=0.001, max=6.25 (чем меньше с, тем быстрее обмен данными) АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ.
- 13. Организация параллельных вычислений – возможные режимы Многозадачный режим, или режим разделения времени: Псевдопараллельность – для выполнения
- 14. Основные типы ПВС Суперкомпьютер: ВС рекордной производительности, выпускаемая отдельными экземплярами на оригинальной схемотехнической базе. ВС ценой
- 15. Основные типы ПВС Кластер – группа выделенных рабочих станций: объединены в ЛВС, эффективно и надежно работают
- 16. Классификация ПВС по архитектуре Архитектура ВС - общая логическая организация ВС: определяющая процесс обработки данных, включающая
- 17. Основные типы ВС по Флинну (Michael J. Flynn, Таксономия Флинна - 1966 г.) АЛГОРИТМЫ И ТЕХНОЛОГИИ
- 18. Основные типы ВС по Флинну SISD (Single Instruction Single Data) – 1 поток команд, 1 поток
- 19. Основные типы ВС по Флинну SIMD (Single Instruction Multiple Data) – 1 поток команд, много потоков
- 20. Основные типы ВС по Флинну MISD (Multiple Instruction Single Data) – много потоков команд, 1 поток
- 21. Разновидности ВС типа MIMD Дальнейшая классификация ВС – по способам организации оперативной памяти: Мультипроцессоры – ВС
- 22. Мультипроцессоры – способы построения общей памяти Единая общая память с равноправным (однородным) доступом (Uniform Memory Access,
- 23. Архитектура систем UMA АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1
- 24. Cache memory – кэш-память, кэш: промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена
- 25. Проблемы UMA Доступ с разных процессоров к общим данным ? Необходимо обеспечивать однозначность (когерентность) содержимого разных
- 26. Копии значения переменной x – в разных кэшах ? Возможно изменение х одним из процессоров. АЛГОРИТМЫ
- 27. Проблемы UMA Доступ с разных процессоров к общим данным ? Необходимость синхронизации взаимодействия одновременно выполняемых потоков
- 28. Мультипроцессоры – способы построения общей памяти 2. Физически распределенная общая память с неравноправным (неоднородным) доступом (Non-Uniform
- 29. Архитектура систем NUMA АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1
- 30. NUMA системы Для данных используются только локальные кэши процессоров – нет общей памяти => нет проблемы
- 31. Мультикомпьютеры МК – ВС с распределенной памятью самостоятельных компьютеров, объединенных в сеть МК – системы типа
- 32. Основные типы МК – многопроцессорных вычислительных систем Массивно (массово)-параллельные системы, MPP-системы (Massively Parallel Processing – массово-параллельная
- 33. Основные типы МК – многопроцессорных вычислительных систем Кластер - набор рабочих станций (или даже ПК) общего
- 34. Классификация многопроцессорных ВС (подробно см. http://parallel.ru/computers/classes.html) АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1
- 35. Коммуникация в МВС Коммуникация между процессорами обеспечивает: взаимодействие, синхронизацию, взаимоисключения выполняемых процессов ? Коммуникационная «трудоемкость» алгоритма
- 36. Примеры топологий сетей в МВС АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1
- 37. Особенности топологий сетей передачи данных Тип - Преимущества - Реализация Полный граф – минимум затрат на
- 38. Характеристики топологий сети Диаметр – определяет время передачи данных через max расстояние между 2 CPU сети
- 40. Скачать презентацию

Структура предметной области
(Параллельные вычисления)
Математические основы параллельных вычислений
Архитектура параллельных вычислительных систем
Технологии параллельного
Структура предметной области
(Параллельные вычисления)
Математические основы параллельных вычислений
Архитектура параллельных вычислительных систем
Технологии параллельного

Литература
В ИБЦ:
Воеводин В. В. Параллельные вычисления.
Богачев К. Ю. Основы параллельного программирования.
Гергель
Литература
В ИБЦ:
Воеводин В. В. Параллельные вычисления.
Богачев К. Ю. Основы параллельного программирования.
Гергель

Что такое параллельные вычисления?
Параллельные вычисления –
процесс обработки данных,
в котором
Что такое параллельные вычисления?
Параллельные вычисления – процесс обработки данных, в котором

Параллельные вычислительные системы
Параллельные вычисления – процесс обработки данных, в котором одновременно
Параллельные вычислительные системы
Параллельные вычисления – процесс обработки данных, в котором одновременно

Теоретические и практические проблемы параллельных вычислений
Разработка параллельных вычислительных систем (ПВС)
Анализ эффективности
Теоретические и практические проблемы параллельных вычислений
Разработка параллельных вычислительных систем (ПВС)
Анализ эффективности

Показатели производительности параллельного выполнения
Ускорение (Speedup) - за счёт параллельного выполнения программы
Показатели производительности параллельного выполнения
Ускорение (Speedup) - за счёт параллельного выполнения программы

Оценки производительности.
Гипотеза Мински.
Потери производительности при организации параллелизма
Гипотеза Марвина Ли Мински
(Marvin
Оценки производительности.
Гипотеза Мински.
Потери производительности при организации параллелизма
Гипотеза Марвина Ли Мински
(Marvin

Оценки производительности.
Закон Амдала.
Максимальный теоретический выигрыш для сочетания
параллельных вычислений с последовательными:
Закон
Оценки производительности.
Закон Амдала.
Максимальный теоретический выигрыш для сочетания
параллельных вычислений с последовательными:
Закон

Автор закона (конец 1960 г.г.) –
главный разработчик мейнфреймов серии IBM/360
Автор закона (конец 1960 г.г.) – главный разработчик мейнфреймов серии IBM/360
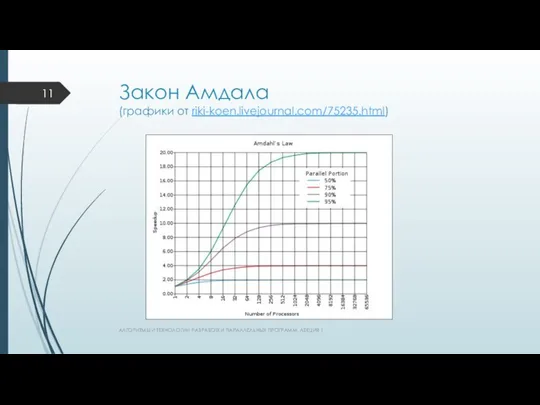
Закон Амдала
(графики от riki-koen.livejournal.com/75235.html)
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ
Закон Амдала
(графики от riki-koen.livejournal.com/75235.html)
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ

р=0.1, с=0.001, max=6.25
(чем меньше с, тем быстрее обмен данными)
АЛГОРИТМЫ И
р=0.1, с=0.001, max=6.25
(чем меньше с, тем быстрее обмен данными)
АЛГОРИТМЫ И

Организация параллельных вычислений – возможные режимы
Многозадачный режим, или режим разделения времени:
Псевдопараллельность
Организация параллельных вычислений – возможные режимы
Многозадачный режим, или режим разделения времени:
Псевдопараллельность

Основные типы ПВС
Суперкомпьютер:
ВС рекордной производительности, выпускаемая отдельными экземплярами на оригинальной
Основные типы ПВС
Суперкомпьютер:
ВС рекордной производительности, выпускаемая отдельными экземплярами на оригинальной

Основные типы ПВС
Кластер – группа выделенных рабочих станций:
объединены в ЛВС,
эффективно
Основные типы ПВС
Кластер – группа выделенных рабочих станций:
объединены в ЛВС,
эффективно

Классификация ПВС по архитектуре
Архитектура ВС - общая логическая организация ВС:
Классификация ПВС по архитектуре
Архитектура ВС - общая логическая организация ВС:

Основные типы ВС по Флинну
(Michael J. Flynn, Таксономия Флинна -
Основные типы ВС по Флинну (Michael J. Flynn, Таксономия Флинна -

Основные типы ВС по Флинну
SISD (Single Instruction Single Data) –
Основные типы ВС по Флинну
SISD (Single Instruction Single Data) –

Основные типы ВС по Флинну
SIMD (Single Instruction Multiple Data) –
Основные типы ВС по Флинну
SIMD (Single Instruction Multiple Data) –

Основные типы ВС по Флинну
MISD (Multiple Instruction Single Data) – много
Основные типы ВС по Флинну
MISD (Multiple Instruction Single Data) – много

Разновидности ВС типа MIMD
Дальнейшая классификация ВС – по способам организации оперативной
Разновидности ВС типа MIMD
Дальнейшая классификация ВС – по способам организации оперативной

Мультипроцессоры –
способы построения общей памяти
Единая общая память с равноправным (однородным)
Мультипроцессоры –
способы построения общей памяти
Единая общая память с равноправным (однородным)

Архитектура систем UMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1
Архитектура систем UMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1

Cache memory – кэш-память, кэш:
промежуточный буфер с быстрым доступом, содержащий информацию, которая
Cache memory – кэш-память, кэш: промежуточный буфер с быстрым доступом, содержащий информацию, которая

Проблемы UMA
Доступ с разных процессоров к общим данным ?
Необходимо обеспечивать однозначность
Проблемы UMA
Доступ с разных процессоров к общим данным ?
Необходимо обеспечивать однозначность

Копии значения переменной x – в разных кэшах ? Возможно изменение
Копии значения переменной x – в разных кэшах ? Возможно изменение

Проблемы UMA
Доступ с разных процессоров к общим данным ?
Необходимость синхронизации взаимодействия
Проблемы UMA
Доступ с разных процессоров к общим данным ?
Необходимость синхронизации взаимодействия

Мультипроцессоры –
способы построения общей памяти
2. Физически распределенная общая память с
Мультипроцессоры –
способы построения общей памяти
2. Физически распределенная общая память с

Архитектура систем NUMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1
Архитектура систем NUMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 1

NUMA системы
Для данных используются только локальные кэши процессоров – нет общей
NUMA системы
Для данных используются только локальные кэши процессоров – нет общей

Мультикомпьютеры
МК – ВС с распределенной памятью самостоятельных компьютеров, объединенных в сеть
МК
Мультикомпьютеры
МК – ВС с распределенной памятью самостоятельных компьютеров, объединенных в сеть
МК

Основные типы МК – многопроцессорных вычислительных систем
Массивно (массово)-параллельные системы, MPP-системы (Massively
Основные типы МК – многопроцессорных вычислительных систем
Массивно (массово)-параллельные системы, MPP-системы (Massively

Основные типы МК – многопроцессорных вычислительных систем
Кластер - набор рабочих станций
Основные типы МК – многопроцессорных вычислительных систем
Кластер - набор рабочих станций

Классификация многопроцессорных ВС
(подробно см. http://parallel.ru/computers/classes.html)
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ
Классификация многопроцессорных ВС
(подробно см. http://parallel.ru/computers/classes.html)
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ

Коммуникация в МВС
Коммуникация между процессорами обеспечивает:
взаимодействие, синхронизацию, взаимоисключения выполняемых процессов
Коммуникация в МВС
Коммуникация между процессорами обеспечивает:
взаимодействие, синхронизацию, взаимоисключения выполняемых процессов
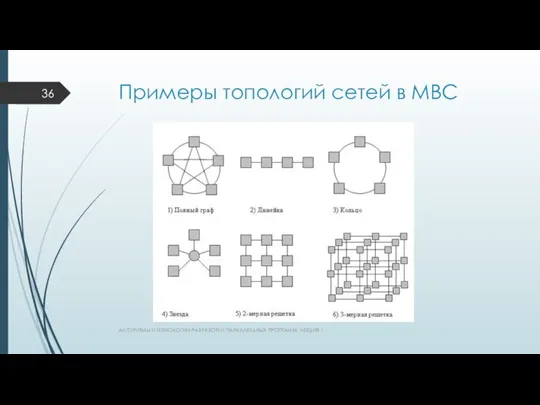
Примеры топологий сетей в МВС
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ
Примеры топологий сетей в МВС
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ

Особенности топологий сетей передачи данных
Тип - Преимущества - Реализация
Полный граф – минимум
Особенности топологий сетей передачи данных
Тип - Преимущества - Реализация
Полный граф – минимум

Характеристики топологий сети
Диаметр – определяет время передачи данных через max расстояние
Характеристики топологий сети
Диаметр – определяет время передачи данных через max расстояние
 Экологические новости Подготовила Парамонова Мария Группа Т1209
Экологические новости Подготовила Парамонова Мария Группа Т1209 Рекреационные ресурсы РФ
Рекреационные ресурсы РФ Зонирование. Планировка помещений
Зонирование. Планировка помещений Николай Носов - 10 ноября 1908 г. – 26 июля 1976 г
Николай Носов - 10 ноября 1908 г. – 26 июля 1976 г Актуализация внутренней документации в ОАО «Научно-технический прогресс»
Актуализация внутренней документации в ОАО «Научно-технический прогресс» Дмитрий Датмен. Экстремально-силовое шоу
Дмитрий Датмен. Экстремально-силовое шоу Арабо-мусульманская культура
Арабо-мусульманская культура Спряжение глаголов machen(делать), spielen(играть)
Спряжение глаголов machen(делать), spielen(играть) 70-я спартакиада школьников города Калуги
70-я спартакиада школьников города Калуги Новые группы лекарственных средств в фармакологической поддержке спортсменов Республиканский семинар «Актуальные вопросы с
Новые группы лекарственных средств в фармакологической поддержке спортсменов Республиканский семинар «Актуальные вопросы с Национальный состав населения Томской области
Национальный состав населения Томской области Определение сравнительной напряженности деятельности сотрудников таможенных органов Выполнили студентки экономического факул
Определение сравнительной напряженности деятельности сотрудников таможенных органов Выполнили студентки экономического факул ОГЭ по обществознанию. Тема: Сфера политики и социального управления
ОГЭ по обществознанию. Тема: Сфера политики и социального управления Внешний PR и имиджевая политика государства
Внешний PR и имиджевая политика государства эпоха Возрождения» По Культурологии
эпоха Возрождения» По Культурологии ЖИВОТНЫЕ ТРОПИЧЕСКОГО ЛЕСА
ЖИВОТНЫЕ ТРОПИЧЕСКОГО ЛЕСА  Счетчики делители
Счетчики делители Типы подвесок автомобилей
Типы подвесок автомобилей Язык С (часть 2)
Язык С (часть 2) Антуан де Сент-Экзюпери
Антуан де Сент-Экзюпери Линейчатые поверхности. Образование поверхностей
Линейчатые поверхности. Образование поверхностей МИКРОЭЛЕМЕНТЫ
МИКРОЭЛЕМЕНТЫ Анализ образа федеральной службы по аккредитации в СМИ
Анализ образа федеральной службы по аккредитации в СМИ Мікроекономіка як складова економічної теорії
Мікроекономіка як складова економічної теорії Презентация на тему "Применение компьютерных технологий в преподавании географии с использованием авторского курса «Электрон
Презентация на тему "Применение компьютерных технологий в преподавании географии с использованием авторского курса «Электрон Наша безопасность - презентация для начальной школы_
Наша безопасность - презентация для начальной школы_ Действительный цикл. Газообмен ДВС
Действительный цикл. Газообмен ДВС курение или здоровье - презентация для начальной школы
курение или здоровье - презентация для начальной школы