- Алгоритм сортировки TimSort

Содержание
- 2. Timsort – гибридный алгоритм сортировки основанный на Insertion Sort и Merge Sort. Timsort сначала анализирует список,
- 3. Оценочное время работы Среди, на первый взгляд, огромного выбора в таблице есть всего 7 адекватных алгоритмов
- 4. Основные понятия N — размер входного массива run — упорядоченный подмассив во входном массиве. Причём упорядоченный
- 5. Как работает данный алгоритм? Начнем с того, что алгоритм состоит из трех частей: Вычисление minrun. Разбиение
- 6. Вычисление minrun Число minrun определяется на основе N исходя из следующих принципов: Оно не должно быть
- 7. Разбиение на подмассивы и их сортировка. Итак, на данном этапе у нас есть входной массив, его
- 8. Слияние. Нужно объединить полученные подмассивы для получения результирующего упорядоченного массива. Для достижения эффективности, нужно объединять подмассивы
- 9. Модификация слияния. Вышеуказанная процедура для них сработает, но каждый раз на её четвёртом пункте нужно будет
- 10. Были сгенерированы различные файлы и подсчитано время работы алгоритма в наносекундах. Тестирование на сгенерированных входных данных
- 11. Сравнение с другими сортировками
- 13. Скачать презентацию

Timsort – гибридный алгоритм сортировки основанный на Insertion Sort и Merge
Timsort – гибридный алгоритм сортировки основанный на Insertion Sort и Merge
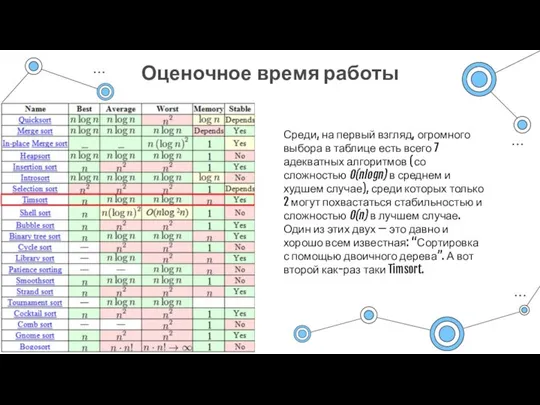
Оценочное время работы
Среди, на первый взгляд, огромного выбора в таблице есть
Оценочное время работы
Среди, на первый взгляд, огромного выбора в таблице есть

Основные понятия
N — размер входного массива
run — упорядоченный подмассив во входном массиве. Причём
Основные понятия
N — размер входного массива
run — упорядоченный подмассив во входном массиве. Причём

Как работает данный алгоритм?
Начнем с того, что алгоритм состоит из трех
Как работает данный алгоритм?
Начнем с того, что алгоритм состоит из трех

Вычисление minrun
Число minrun определяется на основе N исходя из следующих принципов:
Оно не должно быть слишком
Вычисление minrun
Число minrun определяется на основе N исходя из следующих принципов:
Оно не должно быть слишком

Разбиение на подмассивы и их сортировка.
Итак, на данном этапе у нас
Разбиение на подмассивы и их сортировка.
Итак, на данном этапе у нас

Слияние.
Нужно объединить полученные подмассивы для получения результирующего упорядоченного массива. Для достижения
Слияние.
Нужно объединить полученные подмассивы для получения результирующего упорядоченного массива. Для достижения

Модификация слияния.
Вышеуказанная процедура для них сработает, но каждый раз на её
Модификация слияния.
Вышеуказанная процедура для них сработает, но каждый раз на её

Были сгенерированы различные файлы и подсчитано время работы алгоритма в наносекундах.
Тестирование
Были сгенерированы различные файлы и подсчитано время работы алгоритма в наносекундах.
Тестирование

Сравнение с другими сортировками
Сравнение с другими сортировками
 Создание БД в ИРБИС
Создание БД в ИРБИС Комп'ютерні віруси
Комп'ютерні віруси Концептуальные основы обеспечения ИБ
Концептуальные основы обеспечения ИБ Порядок организации учебного процесса в ЭИОС
Порядок организации учебного процесса в ЭИОС Интернет заттар және
Интернет заттар және Этапы развития информационных технологий
Этапы развития информационных технологий Электронная почта
Электронная почта Обработка цифровой информации. Сайтостроение
Обработка цифровой информации. Сайтостроение Верстальщик HTML
Верстальщик HTML Экспертные системы
Экспертные системы Решение задач на кодирование звуковой информации Подготовка к ЕГЭ
Решение задач на кодирование звуковой информации Подготовка к ЕГЭ Системы обработки данных представленных в таблицах
Системы обработки данных представленных в таблицах Создание презентаций в Microsoft Power Point
Создание презентаций в Microsoft Power Point  Одномерные массивы целых чисел
Одномерные массивы целых чисел Си. Модуль 10
Си. Модуль 10 Классификация информационных систем
Классификация информационных систем Разработка приложения Расписание занятий
Разработка приложения Расписание занятий Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Инструменты Прибавить к Экрану. Вычесть из экран. Изучение их работ
Инструменты Прибавить к Экрану. Вычесть из экран. Изучение их работ Нормализация отношений
Нормализация отношений Кодирование графической информации
Кодирование графической информации UML. Принцип создания проектов
UML. Принцип создания проектов Математическое выражение
Математическое выражение Размещение данных 1С:Предприятия 8
Размещение данных 1С:Предприятия 8 Retro Neon
Retro Neon Схемы nanoCAD. Автоматизация процесса проектирования схем
Схемы nanoCAD. Автоматизация процесса проектирования схем Арбитраж трафика через тематические аккаунты
Арбитраж трафика через тематические аккаунты Знакомство с TRIK Studio
Знакомство с TRIK Studio