- Структуры данных. Примеры реализации на С++ для АСУб и ЭВМб. Тема 6-3

Содержание
- 2. Темы лекции
- 3. Абстрактные типы данных Абстрактный тип данных описывает, какие данные хранятся и какие операции должны выполняться Абстрактный
- 4. Абстрактные типы данных: выбор Будете ли вы часто искать данные? Будут ли данные добавляться часто? Будут
- 5. Абстрактные типы данных: выбор Добавление Поиск Удаление Изменение, Доступ и т.п. https://metanit.com/sharp/algoritm/1.1.php https://habr.com/ru/post/444594/ АТД: предметные данные
- 6. Абстрактные типы данных: сложность
- 7. Сложность вычислений
- 9. Структуры данных Основные структуры данных, существующие в языке Си ++ — это переменные, массивы, структуры, перечисления.
- 10. Структуры данных Существует, достаточно, много задач, в которых требуются данные с более сложной (динамической) структурой. Для
- 13. Связные списки Связный список является простейшим типом данных динамической структуры, состоящей из элементов (узлов). Каждый узел
- 14. Связные списки Доступ к списку осуществляется через указатель, который содержит адрес первого элемента списка, называемый корнем
- 15. Связные списки Классификация списков По количеству полей указателей различают однонаправленный (односвязный) и двунаправленный (двусвязный) списки. Связный
- 16. Связные списки Классификация списков Связный список, в котором, последний элемент указывает на NULL, называется линейным. Связный
- 17. Связные списки Виды списков Односвязный линейный список (ОЛС). Каждый узел ОЛС содержит 1 поле указателя на
- 18. Связные списки Виды списков Односвязный циклический список (ОЦС). Каждый узел ОЦС содержит 1 поле указателя на
- 19. Связные списки Виды списков Двусвязный линейный список (ДЛС). Каждый узел ДЛС содержит два поля указателей: на
- 20. Связные списки Виды списков Двусвязный циклический список (ДЦС). Каждый узел ДЦС содержит два поля указателей: на
- 21. Связные списки Сравнение массивов и связных списков
- 22. Односвязный линейный список Каждый узел однонаправленного (односвязного) линейного списка (ОЛС) содержит одно поле указателя на следующий
- 23. Односвязный линейный список Узел ОЛС можно представить в виде структуры struct list { int field; //
- 24. Односвязный линейный список Основные действия, производимые над элементами ОЛС: Инициализация списка Добавление узла в список Удаление
- 25. Односвязный линейный список Инициализация ОЛС Инициализация списка предназначена для создания корневого узла списка, у которого поле
- 26. Односвязный линейный список Инициализация ОЛС list * init(int a) // а- значение первого узла { struct
- 27. Односвязный линейный список Добавление узла в ОЛС Функция добавления узла в список принимает два аргумента: Указатель
- 28. Односвязный линейный список Добавление узла в ОЛС Добавление узла в ОЛС включает в себя следующие этапы:
- 29. Односвязный линейный список Добавление узла в ОЛС struct list * addelem(list *lst, int number) { struct
- 30. Односвязный линейный список Удаление узла ОЛС В качестве аргументов функции удаления элемента ОЛС передаются указатель на
- 31. Односвязный линейный список Удаление узла ОЛС Удаление узла ОЛС включает в себя следующие этапы: установка указателя
- 32. Односвязный линейный список Удаление узла ОЛС struct list * deletelem(list *lst, list *root) { struct list
- 33. Односвязный линейный список Удаление корня списка Функция удаления корня списка в качестве аргумента получает указатель на
- 34. Односвязный линейный список Удаление корня списка struct list * deletehead(list *root) { struct list *temp; temp
- 35. Односвязный линейный список Вывод элементов списка В качестве аргумента в функцию вывода элементов передается указатель на
- 36. Односвязный циклический список Каждый узел однонаправленного (односвязного) циклического списка (ОЦС) содержит одно поле указателя на следующий
- 37. Односвязный циклический список Узел ОЦС можно представить в виде структуры, аналогичной односвязному линейному списку struct list
- 38. Односвязный циклический список Основные действия, производимые над элементами ОЦС: Инициализация списка Добавление узла в список Удаление
- 39. Односвязный циклический список Инициализация ОЦС Инициализация списка предназначена для создания корневого узла списка, у которого поле
- 40. Односвязный циклический список Инициализация ОЦС struct list * init(int a) // а- значение первого узла {
- 41. Односвязный циклический список Добавление узла в ОЦС Функция добавления узла в список принимает два аргумента: Указатель
- 42. Односвязный циклический список Добавление элемента в ОЦС включает в себя следующие этапы: создание добавляемого узла и
- 43. Односвязный циклический список struct list * addelem(list *lst, int number) { struct list *temp, *p; temp
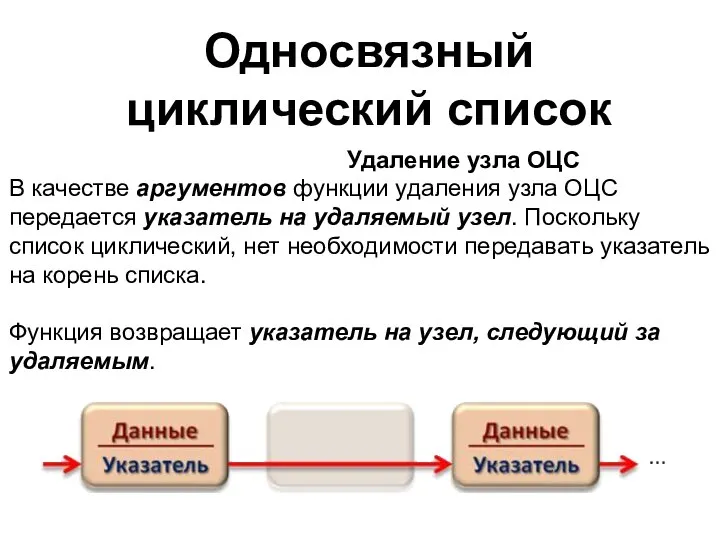
- 44. Односвязный циклический список Удаление узла ОЦС В качестве аргументов функции удаления узла ОЦС передается указатель на
- 45. Односвязный циклический список Удаление узла ОЦС включает в себя следующие этапы: установка указателя предыдущего узла на
- 46. Односвязный циклический список struct list * deletelem(list *lst) { struct list *temp; temp = lst; while
- 47. Односвязный циклический список Вывод элементов ОЦС Функция вывода элементов ОЦС аналогична функции для ОЛС за исключением
- 48. Односвязный циклический список Вывод элементов ОЦС void listprint(list *lst) { struct list *p; p = lst;
- 49. Двусвязный линейный список Каждый узел двунаправленного (двусвязного) линейного списка (ДЛС) содержит два поля указателей — на
- 50. Двусвязный линейный список Узел ДЛС можно представить в виде структуры: struct list { int field; //
- 51. Двусвязный линейный список Основные действия, производимые над узлами ДЛС: Инициализация списка Добавление узла в список Удаление
- 52. Двусвязный линейный список Инициализация ДЛС Инициализация списка предназначена для создания корневого узла списка, у которого поля
- 53. Двусвязный линейный список Инициализация ДЛС struct list * init(int a) // а- значение первого узла {
- 54. Двусвязный линейный список Добавление узла в ДЛС Функция добавления узла в список принимает два аргумента: Указатель
- 55. Двусвязный линейный список Добавление узла в ДЛС включает в себя следующие этапы: создание узла добавляемого элемента
- 56. Двусвязный линейный список struct list * addelem(list *lst, int number) { struct list *temp, *p; temp
- 57. Двусвязный линейный список Удаление узла ДЛС В качестве аргументов функции удаления узла ДЛС передается указатель на
- 58. Двусвязный линейный список Удаление узла ДЛС включает в себя следующие этапы: установка указателя «следующий» предыдущего узла
- 59. Двусвязный линейный список struct list * deletelem(list *lst) { struct list *prev, *next; prev = lst->prev;
- 60. Двусвязный линейный список Удаление корня ДЛС Функция удаления корня ДЛС в качестве аргумента получает указатель на
- 61. Двусвязный линейный список struct list * deletehead(list *root) { struct list *temp; temp = root->next; temp->prev
- 62. Двусвязный линейный список Вывод элементов ДЛС Функция вывода элементов ДЛС аналогична функции для ОЛС. В качестве
- 63. Двусвязный линейный список void listprint(list *lst) { struct list *p; p = lst; do { printf("%d
- 64. Двусвязный линейный список Вывод элементов ДЛС в обратном порядке Функция вывода элементов ДЛС в обратном порядке
- 65. Двусвязный линейный список void listprintr(list *lst) { struct list *p; p = lst; while (p->next !=
- 67. СТРУКТУРА ДАННЫХ СТЕК Стек (stack) — абстрактный тип данных, представляющий собой список элементов, организованных по принципу
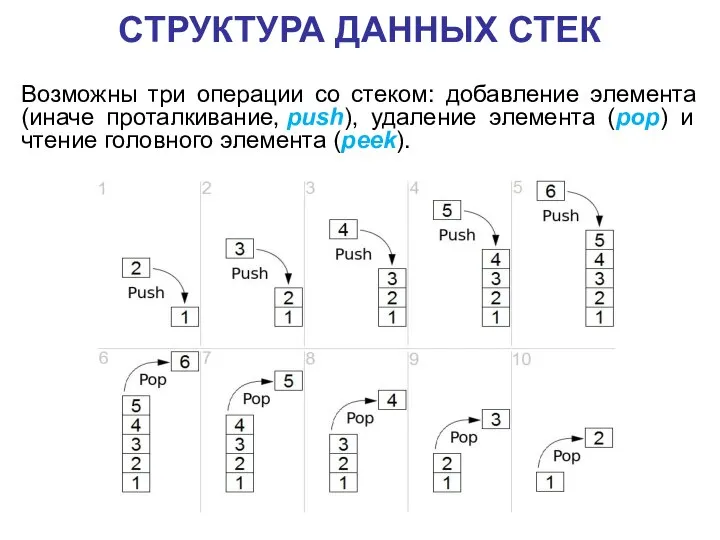
- 68. СТРУКТУРА ДАННЫХ СТЕК Возможны три операции со стеком: добавление элемента (иначе проталкивание, push), удаление элемента (pop)
- 70. Очередь О́чередь — тип данных с принципом организации «первый пришёл — первый вышел» (FIFO, First In
- 71. Деревья
- 72. Деревья Деревья наилучшим образом приспособлены для решения задач искусственного интеллекта и синтаксического анализа текста. Примеры применения:
- 73. Деревья Деревом типа Т называется структура данных, которая образована данным типа Т, называемым корнем дерева, и
- 74. Деревья (терминология) Лист – это корень поддерева, не имеющего, в свою очередь, поддеревьев Вершина – это
- 75. Дерево Корень Листья
- 76. Двоичное дерево — иерархическая структура данных, в которой каждый узел имеет не более двух потомков (детей).
- 77. Дерево Степень исхода бинарное N-арное По полноте полное Неполное По порядку узлов упорядоченные Неупорядоченные
- 78. Двоичное дерево Двоичным деревом типа Т называют структуру, которая либо пуста либо образована: - данным типа
- 79. Двоичное дерево (логическое описание) При представлении данных в виде двоичного дерева будем считать, что каждое звено
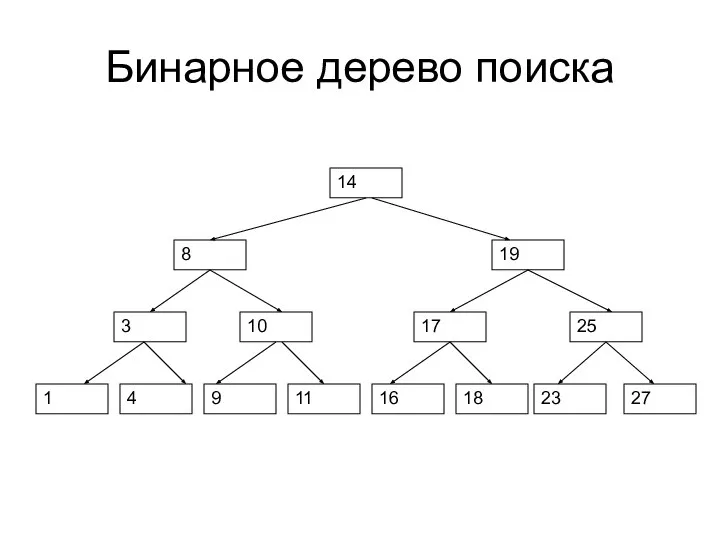
- 80. Бинарное дерево поиска Бинарное дерево называется деревом поиска, если Левый потомок любого элемента и все элементы
- 81. Бинарное дерево поиска
- 82. Бинарное дерево. Поиск 4
- 83. Бинарное дерево. Добавление элемента 2.5 2.5
- 84. Бинарное дерево поиска Как и отсортированный массив, поддерживает поиск за log(N) В отличие от отсортированного массива,
- 85. Сбалансированное дерево Дерево является сбалансированным, если разница между его максимальной и минимальной глубиной (количеством элементов от
- 86. Сбалансированное дерево
- 87. Сбалансированное дерево 2.5
- 88. Несбалансированное дерево 4.5 4.2
- 89. Сбалансированное дерево Дерево должно быть сбалансированным, чтобы поддерживать поиск и добавление элемента за log(N) Существуют различные
- 91. Скачать презентацию

Темы лекции
Темы лекции

Абстрактные типы данных
Абстрактный тип данных описывает, какие данные хранятся и какие
Абстрактные типы данных
Абстрактный тип данных описывает, какие данные хранятся и какие

Абстрактные типы данных: выбор
Будете ли вы часто искать данные?
Будут ли данные
Абстрактные типы данных: выбор
Будете ли вы часто искать данные?
Будут ли данные

Абстрактные типы данных: выбор
Добавление
Поиск
Удаление
Изменение, Доступ и т.п.
https://metanit.com/sharp/algoritm/1.1.php
https://habr.com/ru/post/444594/
АТД:
предметные данные
служебные данные
Абстрактные типы данных: выбор
Добавление
Поиск
Удаление
Изменение, Доступ и т.п.
https://metanit.com/sharp/algoritm/1.1.php
https://habr.com/ru/post/444594/
АТД:
предметные данные
служебные данные
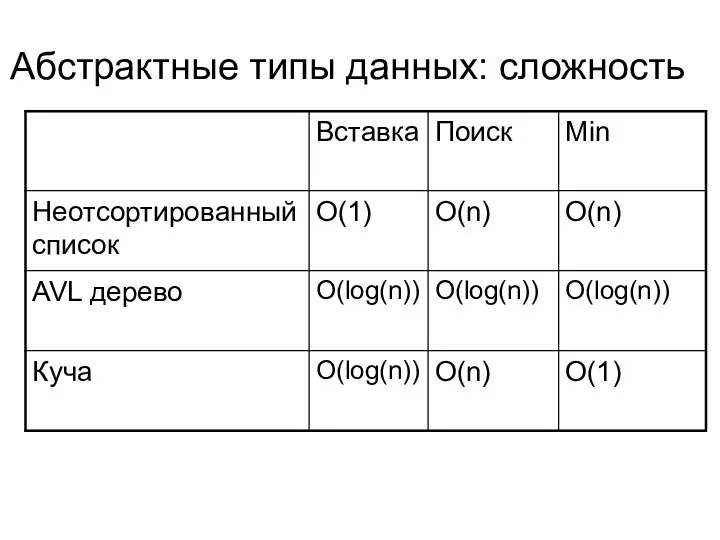
Абстрактные типы данных: сложность
Абстрактные типы данных: сложность
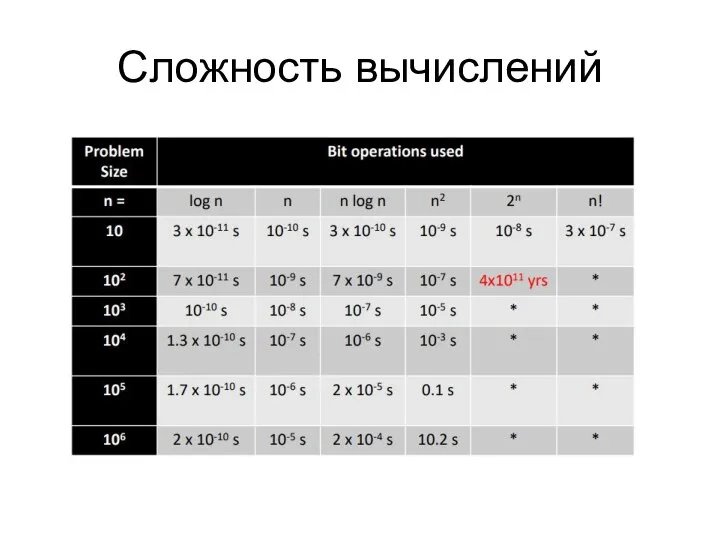
Сложность вычислений
Сложность вычислений


Структуры данных
Основные структуры данных, существующие в языке Си ++ — это
Структуры данных
Основные структуры данных, существующие в языке Си ++ — это

Структуры данных
Существует, достаточно, много задач, в которых требуются данные с более
Структуры данных
Существует, достаточно, много задач, в которых требуются данные с более



Связные списки
Связный список является простейшим типом данных динамической структуры, состоящей из
Связные списки
Связный список является простейшим типом данных динамической структуры, состоящей из
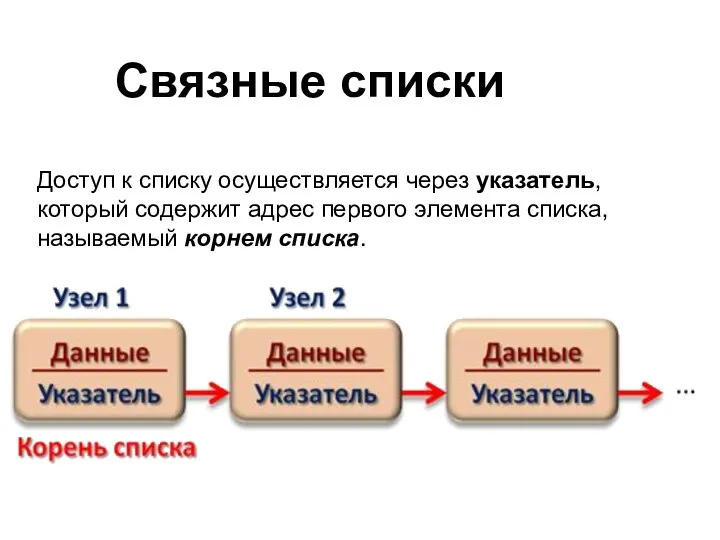
Связные списки
Доступ к списку осуществляется через указатель, который содержит адрес первого
Связные списки
Доступ к списку осуществляется через указатель, который содержит адрес первого

Связные списки
Классификация списков
По количеству полей указателей различают однонаправленный (односвязный) и двунаправленный
Связные списки
Классификация списков
По количеству полей указателей различают однонаправленный (односвязный) и двунаправленный
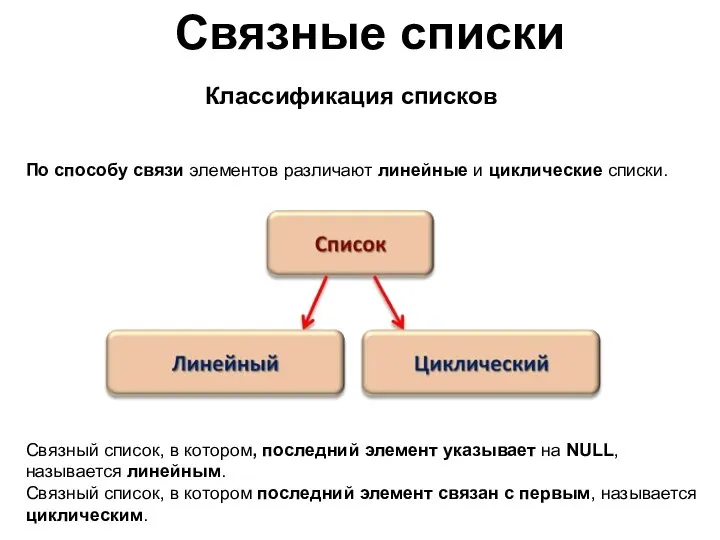
Связные списки
Классификация списков
Связный список, в котором, последний элемент указывает на NULL,
Связные списки
Классификация списков
Связный список, в котором, последний элемент указывает на NULL,
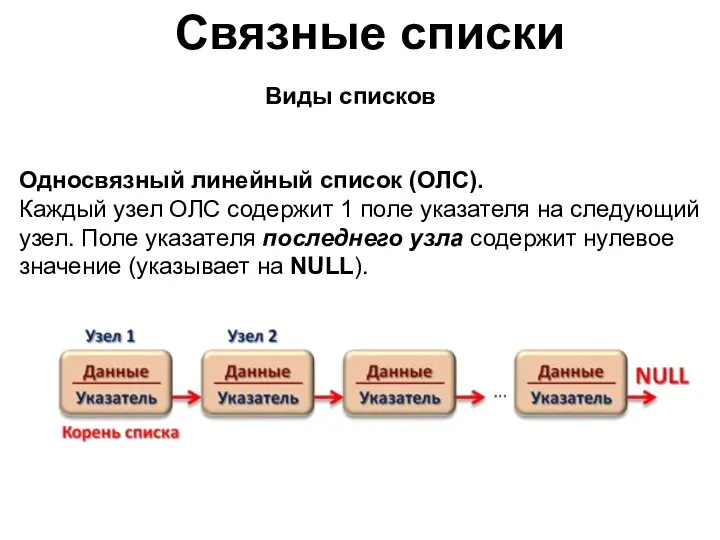
Связные списки
Виды списков
Односвязный линейный список (ОЛС).
Каждый узел ОЛС содержит 1 поле
Связные списки
Виды списков
Односвязный линейный список (ОЛС).
Каждый узел ОЛС содержит 1 поле

Связные списки
Виды списков
Односвязный циклический список (ОЦС).
Каждый узел ОЦС содержит 1
Связные списки
Виды списков
Односвязный циклический список (ОЦС).
Каждый узел ОЦС содержит 1

Связные списки
Виды списков
Двусвязный линейный список (ДЛС).
Каждый узел ДЛС содержит два поля
Связные списки
Виды списков
Двусвязный линейный список (ДЛС).
Каждый узел ДЛС содержит два поля

Связные списки
Виды списков
Двусвязный циклический список (ДЦС).
Каждый узел ДЦС содержит два поля
Связные списки
Виды списков
Двусвязный циклический список (ДЦС).
Каждый узел ДЦС содержит два поля

Связные списки
Сравнение массивов и связных списков
Связные списки
Сравнение массивов и связных списков
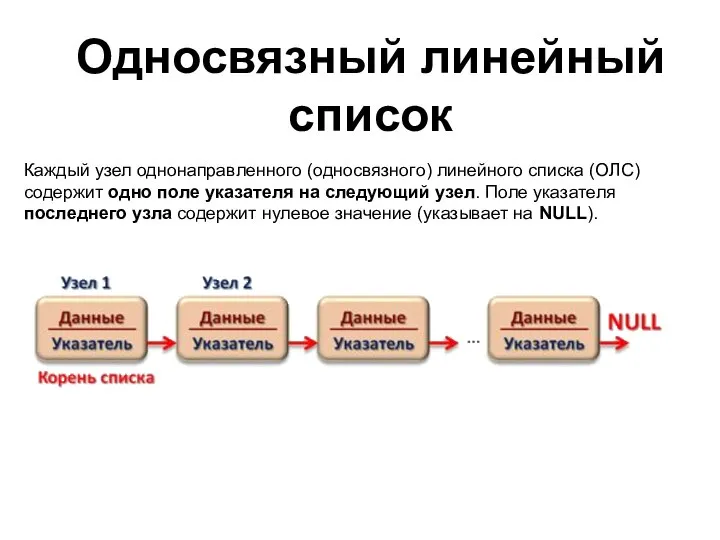
Односвязный линейный
список
Каждый узел однонаправленного (односвязного) линейного списка (ОЛС) содержит одно
Односвязный линейный
список
Каждый узел однонаправленного (односвязного) линейного списка (ОЛС) содержит одно

Односвязный линейный
список
Узел ОЛС можно представить в виде структуры
struct list
{
int
Односвязный линейный
список
Узел ОЛС можно представить в виде структуры
struct list
{
int

Односвязный линейный
список
Основные действия, производимые над элементами ОЛС:
Инициализация списка
Добавление узла в
Односвязный линейный
список
Основные действия, производимые над элементами ОЛС:
Инициализация списка
Добавление узла в

Односвязный линейный
список
Инициализация ОЛС
Инициализация списка предназначена
для создания корневого узла списка,
Односвязный линейный
список
Инициализация ОЛС
Инициализация списка предназначена
для создания корневого узла списка,

Односвязный линейный
список
Инициализация ОЛС
list * init(int a) // а- значение первого
Односвязный линейный
список
Инициализация ОЛС
list * init(int a) // а- значение первого
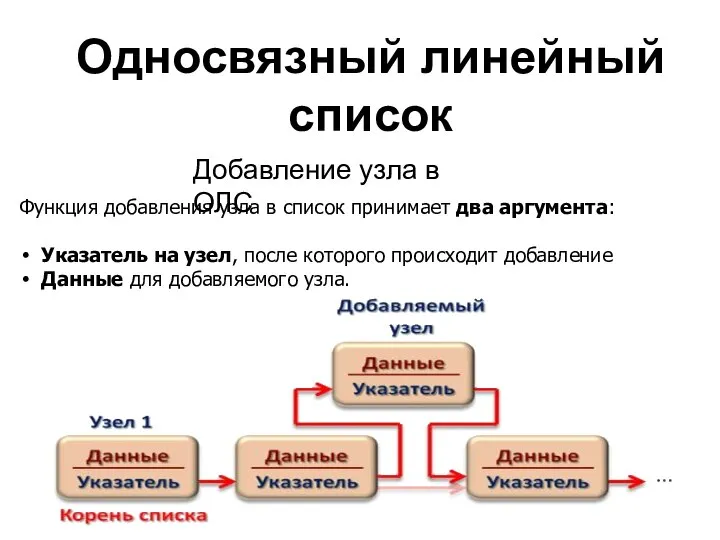
Односвязный линейный
список
Добавление узла в ОЛС
Функция добавления узла в список принимает
Односвязный линейный
список
Добавление узла в ОЛС
Функция добавления узла в список принимает

Односвязный линейный
список
Добавление узла в ОЛС
Добавление узла в ОЛС включает в
Односвязный линейный
список
Добавление узла в ОЛС
Добавление узла в ОЛС включает в

Односвязный линейный
список
Добавление узла в ОЛС
struct list * addelem(list *lst, int
Односвязный линейный
список
Добавление узла в ОЛС
struct list * addelem(list *lst, int

Односвязный линейный
список
Удаление узла ОЛС
В качестве аргументов функции удаления элемента ОЛС
Односвязный линейный
список
Удаление узла ОЛС
В качестве аргументов функции удаления элемента ОЛС

Односвязный линейный
список
Удаление узла ОЛС
Удаление узла ОЛС включает в себя следующие
Односвязный линейный
список
Удаление узла ОЛС
Удаление узла ОЛС включает в себя следующие

Односвязный линейный
список
Удаление узла ОЛС
struct list * deletelem(list *lst, list *root)
{
Односвязный линейный
список
Удаление узла ОЛС
struct list * deletelem(list *lst, list *root)
{

Односвязный линейный
список
Удаление корня списка
Функция удаления корня списка в качестве аргумента
Односвязный линейный
список
Удаление корня списка
Функция удаления корня списка в качестве аргумента

Односвязный линейный
список
Удаление корня списка
struct list * deletehead(list *root)
{
struct list
Односвязный линейный
список
Удаление корня списка
struct list * deletehead(list *root)
{
struct list

Односвязный линейный
список
Вывод элементов списка
В качестве аргумента в функцию вывода элементов
Односвязный линейный
список
Вывод элементов списка
В качестве аргумента в функцию вывода элементов

Односвязный
циклический список
Каждый узел однонаправленного (односвязного) циклического списка (ОЦС) содержит одно
Односвязный
циклический список
Каждый узел однонаправленного (односвязного) циклического списка (ОЦС) содержит одно

Односвязный
циклический список
Узел ОЦС можно представить в виде структуры, аналогичной односвязному
Односвязный
циклический список
Узел ОЦС можно представить в виде структуры, аналогичной односвязному

Односвязный
циклический список
Основные действия, производимые над элементами ОЦС:
Инициализация списка
Добавление узла в
Односвязный
циклический список
Основные действия, производимые над элементами ОЦС:
Инициализация списка
Добавление узла в

Односвязный
циклический список
Инициализация ОЦС
Инициализация списка предназначена для создания корневого узла списка,
Односвязный
циклический список
Инициализация ОЦС
Инициализация списка предназначена для создания корневого узла списка,

Односвязный
циклический список
Инициализация ОЦС
struct list * init(int a) // а- значение
Односвязный
циклический список
Инициализация ОЦС
struct list * init(int a) // а- значение
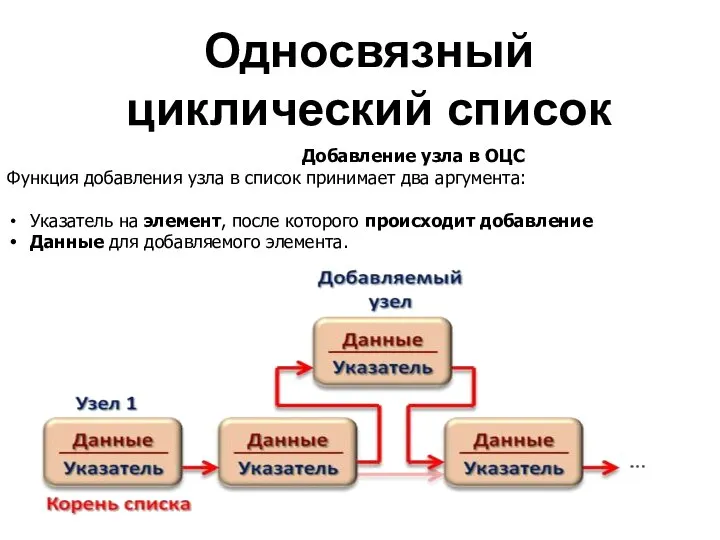
Односвязный
циклический список
Добавление узла в ОЦС
Функция добавления узла в список
Односвязный
циклический список
Добавление узла в ОЦС
Функция добавления узла в список

Односвязный
циклический список
Добавление элемента в ОЦС включает в себя следующие этапы:
создание
Односвязный
циклический список
Добавление элемента в ОЦС включает в себя следующие этапы:
создание

Односвязный
циклический список
struct list * addelem(list *lst, int number)
{
struct list
Односвязный
циклический список
struct list * addelem(list *lst, int number)
{
struct list
Односвязный
циклический список
Удаление узла ОЦС
В качестве аргументов функции удаления узла
Односвязный
циклический список
Удаление узла ОЦС
В качестве аргументов функции удаления узла

Односвязный
циклический список
Удаление узла ОЦС включает в себя следующие этапы:
установка указателя
Односвязный
циклический список
Удаление узла ОЦС включает в себя следующие этапы:
установка указателя

Односвязный
циклический список
struct list * deletelem(list *lst)
{
struct list *temp;
temp
Односвязный
циклический список
struct list * deletelem(list *lst)
{
struct list *temp;
temp

Односвязный
циклический список
Вывод элементов ОЦС
Функция вывода элементов ОЦС аналогична функции
Односвязный
циклический список
Вывод элементов ОЦС
Функция вывода элементов ОЦС аналогична функции

Односвязный
циклический список
Вывод элементов ОЦС
void listprint(list *lst)
{
struct list *p;
p
Односвязный
циклический список
Вывод элементов ОЦС
void listprint(list *lst)
{
struct list *p;
p

Двусвязный
линейный список
Каждый узел двунаправленного (двусвязного) линейного списка (ДЛС) содержит два
Двусвязный
линейный список
Каждый узел двунаправленного (двусвязного) линейного списка (ДЛС) содержит два

Двусвязный
линейный список
Узел ДЛС можно представить в виде структуры:
struct list
{
int
Двусвязный
линейный список
Узел ДЛС можно представить в виде структуры:
struct list
{
int

Двусвязный
линейный список
Основные действия, производимые над узлами ДЛС:
Инициализация списка
Добавление узла в
Двусвязный
линейный список
Основные действия, производимые над узлами ДЛС:
Инициализация списка
Добавление узла в

Двусвязный
линейный список
Инициализация ДЛС
Инициализация списка предназначена для создания корневого узла
Двусвязный
линейный список
Инициализация ДЛС
Инициализация списка предназначена для создания корневого узла

Двусвязный
линейный список
Инициализация ДЛС
struct list * init(int a) // а- значение
Двусвязный
линейный список
Инициализация ДЛС
struct list * init(int a) // а- значение

Двусвязный
линейный список
Добавление узла в ДЛС
Функция добавления узла в список
Двусвязный
линейный список
Добавление узла в ДЛС
Функция добавления узла в список

Двусвязный
линейный список
Добавление узла в ДЛС включает в себя следующие этапы:
создание
Двусвязный
линейный список
Добавление узла в ДЛС включает в себя следующие этапы:
создание

Двусвязный
линейный список
struct list * addelem(list *lst, int number)
{
struct list
Двусвязный
линейный список
struct list * addelem(list *lst, int number)
{
struct list

Двусвязный
линейный список
Удаление узла ДЛС
В качестве аргументов функции удаления узла
Двусвязный
линейный список
Удаление узла ДЛС
В качестве аргументов функции удаления узла

Двусвязный
линейный список
Удаление узла ДЛС включает в себя следующие этапы:
установка указателя
Двусвязный
линейный список
Удаление узла ДЛС включает в себя следующие этапы:
установка указателя

Двусвязный
линейный список
struct list * deletelem(list *lst)
{
struct list *prev, *next;
Двусвязный
линейный список
struct list * deletelem(list *lst)
{
struct list *prev, *next;

Двусвязный
линейный список
Удаление корня ДЛС
Функция удаления корня ДЛС в качестве аргумента
Двусвязный
линейный список
Удаление корня ДЛС
Функция удаления корня ДЛС в качестве аргумента

Двусвязный
линейный список
struct list * deletehead(list *root)
{
struct list *temp;
temp
Двусвязный
линейный список
struct list * deletehead(list *root)
{
struct list *temp;
temp

Двусвязный
линейный список
Вывод элементов ДЛС
Функция вывода элементов ДЛС аналогична функции
Двусвязный
линейный список
Вывод элементов ДЛС
Функция вывода элементов ДЛС аналогична функции

Двусвязный
линейный список
void listprint(list *lst)
{
struct list *p;
p = lst;
Двусвязный
линейный список
void listprint(list *lst)
{
struct list *p;
p = lst;

Двусвязный
линейный список
Вывод элементов ДЛС в обратном порядке
Функция вывода элементов ДЛС
Двусвязный
линейный список
Вывод элементов ДЛС в обратном порядке
Функция вывода элементов ДЛС

Двусвязный
линейный список
void listprintr(list *lst)
{
struct list *p;
p = lst;
Двусвязный
линейный список
void listprintr(list *lst)
{
struct list *p;
p = lst;


СТРУКТУРА ДАННЫХ СТЕК
Стек (stack) — абстрактный тип данных, представляющий собой список
СТРУКТУРА ДАННЫХ СТЕК
Стек (stack) — абстрактный тип данных, представляющий собой список
СТРУКТУРА ДАННЫХ СТЕК
Возможны три операции со стеком: добавление элемента (иначе проталкивание, push),
СТРУКТУРА ДАННЫХ СТЕК
Возможны три операции со стеком: добавление элемента (иначе проталкивание, push),


Очередь
О́чередь — тип данных с принципом организации «первый пришёл — первый вышел» (FIFO, First In —
Очередь
О́чередь — тип данных с принципом организации «первый пришёл — первый вышел» (FIFO, First In —

Деревья
Деревья

Деревья
Деревья наилучшим образом приспособлены для решения задач искусственного интеллекта и синтаксического
Деревья
Деревья наилучшим образом приспособлены для решения задач искусственного интеллекта и синтаксического

Деревья
Деревом типа Т называется структура данных, которая образована данным типа Т,
Деревья
Деревом типа Т называется структура данных, которая образована данным типа Т,

Деревья (терминология)
Лист – это корень поддерева, не имеющего, в свою очередь,
Деревья (терминология)
Лист – это корень поддерева, не имеющего, в свою очередь,

Дерево
Корень
Листья
Дерево
Корень
Листья

Двоичное дерево — иерархическая структура данных, в которой каждый узел имеет

Дерево
Степень исхода
бинарное
N-арное
По полноте
полное
Неполное
По порядку
узлов
упорядоченные
Неупорядоченные
Дерево
Степень исхода
бинарное
N-арное
По полноте
полное
Неполное
По порядку
узлов
упорядоченные
Неупорядоченные

Двоичное дерево
Двоичным деревом типа Т называют структуру, которая либо пуста либо
Двоичное дерево
Двоичным деревом типа Т называют структуру, которая либо пуста либо

Двоичное дерево
(логическое описание)
При представлении данных в виде двоичного дерева будем
Двоичное дерево
(логическое описание)
При представлении данных в виде двоичного дерева будем

Бинарное дерево поиска
Бинарное дерево называется деревом поиска, если
Левый потомок любого элемента
Бинарное дерево поиска
Бинарное дерево называется деревом поиска, если
Левый потомок любого элемента
Бинарное дерево поиска
Бинарное дерево поиска

Бинарное дерево. Поиск
4
Бинарное дерево. Поиск
4
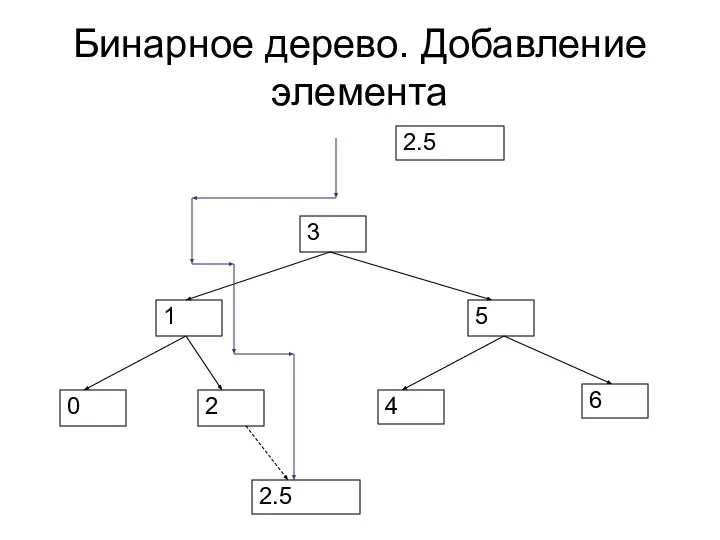
Бинарное дерево. Добавление элемента
2.5
2.5
Бинарное дерево. Добавление элемента
2.5
2.5

Бинарное дерево поиска
Как и отсортированный массив, поддерживает поиск за log(N)
В отличие
Бинарное дерево поиска
Как и отсортированный массив, поддерживает поиск за log(N)
В отличие

Сбалансированное дерево
Дерево является сбалансированным, если разница между его максимальной и минимальной
Сбалансированное дерево
Дерево является сбалансированным, если разница между его максимальной и минимальной

Сбалансированное дерево
Сбалансированное дерево
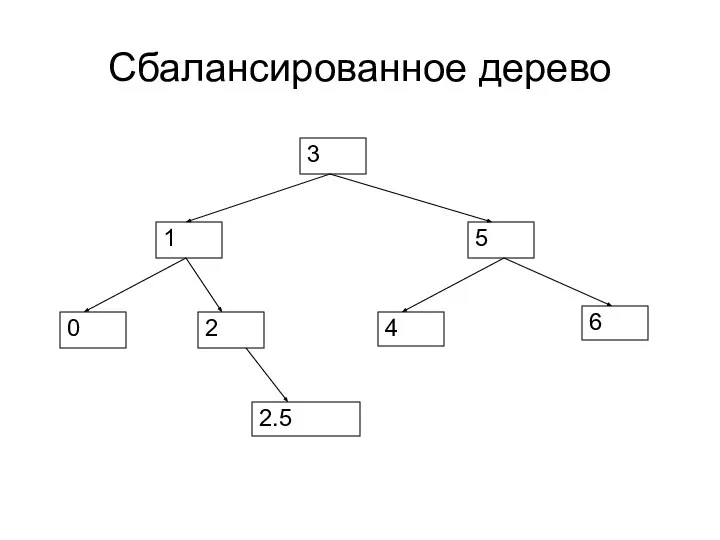
Сбалансированное дерево
2.5
Сбалансированное дерево
2.5

Несбалансированное дерево
4.5
4.2
Несбалансированное дерево
4.5
4.2

Сбалансированное дерево
Дерево должно быть сбалансированным, чтобы поддерживать поиск и добавление элемента
Сбалансированное дерево
Дерево должно быть сбалансированным, чтобы поддерживать поиск и добавление элемента
 Деление числа по разрядам. Полный разбор задачи
Деление числа по разрядам. Полный разбор задачи Двоичная система счисления
Двоичная система счисления Компьютер – универсальная машина для работы с информацией Что умеет компьютер Как устроен компьютер Техника безопасности и орг
Компьютер – универсальная машина для работы с информацией Что умеет компьютер Как устроен компьютер Техника безопасности и орг Освоение технологии работы в графическом редакторе
Освоение технологии работы в графическом редакторе Каналы связи
Каналы связи Информационная паутинка
Информационная паутинка Презентация "Взаимодействующие параллельные процессы" - скачать презентации по Информатике
Презентация "Взаимодействующие параллельные процессы" - скачать презентации по Информатике Intent'ы, IntentFilter'ы и BackStack Activity
Intent'ы, IntentFilter'ы и BackStack Activity Проблемы информационной безопасности
Проблемы информационной безопасности Правила регистрации доменов
Правила регистрации доменов Лекция 2 Delphi
Лекция 2 Delphi  Особенности покупки товаров на маркетплейсах
Особенности покупки товаров на маркетплейсах Моделирование в MS Excel
Моделирование в MS Excel Базовые логические элементы. Дешифратор. Мультиплексор. Сумматор
Базовые логические элементы. Дешифратор. Мультиплексор. Сумматор Дипломная работа
Дипломная работа Возможности платформы ZOOM для проведения онлайн-уроков
Возможности платформы ZOOM для проведения онлайн-уроков Подготовка к ГИА (часть А1). А2. Умение определять значение логического выражения
Подготовка к ГИА (часть А1). А2. Умение определять значение логического выражения Язык программирования Python. SQL 2
Язык программирования Python. SQL 2 Аптека 1С:Розница 8
Аптека 1С:Розница 8 Power BI. Описание платформы и материалы для самостоятельного изучения
Power BI. Описание платформы и материалы для самостоятельного изучения Курсоры. СУБД. (Лекция 12)
Курсоры. СУБД. (Лекция 12) Сервис Интернет Коммуникационные и информационные службы
Сервис Интернет Коммуникационные и информационные службы  BrawlStars
BrawlStars От иконоскопа до плазмы Разработал: Нелипа А.А.
От иконоскопа до плазмы Разработал: Нелипа А.А. Компьютер внутри нас
Компьютер внутри нас Space Internet
Space Internet Департамент образования Кировской области КОГОБУ СПО «Кировский механико-технологический техникум молочной промышленности» С
Департамент образования Кировской области КОГОБУ СПО «Кировский механико-технологический техникум молочной промышленности» С Computer Systems. Lecture 2 (part 1)
Computer Systems. Lecture 2 (part 1)