- Классификция. Задача классификации

Содержание
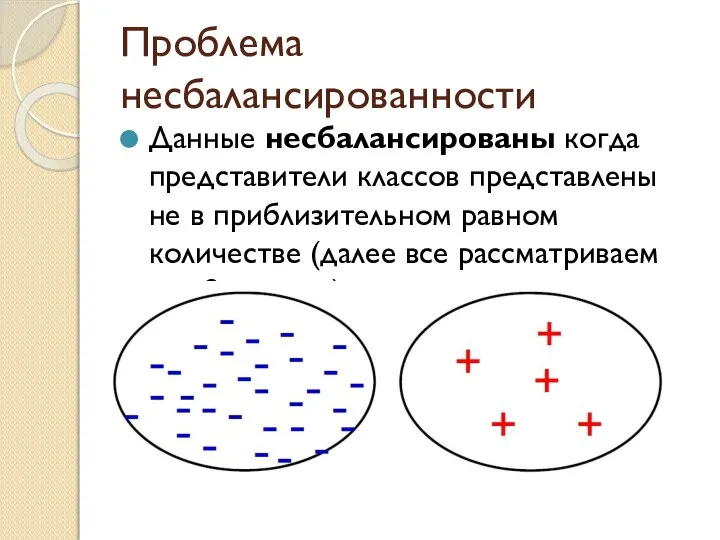
- 2. Проблема несбалансированности Данные несбалансированы когда представители классов представлены не в приблизительном равном количестве (далее все рассматриваем
- 3. В чем проблема? Многие стандартные классификаторы пытаются увеличить точность и не изменить распределение обучающей выборки, поэтому
- 4. Цель классификации - детектирование Стоимость ошибки неправильно классифицировать ненормальный образец данных как нормальный много выше чем
- 5. Примеры несбалансированных данных: 1) из 100 000 тысяч подавших заявку, только 2% проходят в гарвард на
- 6. Техники работы с несбалансированными данными I. Работа с данными : SMOTE Random Undersampling Random Oversampling II.Чувствительность
- 7. Метрики качества Пусть есть два класса — отрицательный и положительный (меньший)
- 8. 1) Accuracy – для сбалансированных данных Процент правильно классифицированных образцов от всего числа образцов
- 9. 2) ROC кривая – для несбалансированных представляет границы лучших решений для относительных TP (по оси У)
- 11. AUC - площадь под ROC кривой . Она эквивалентна вероятности того что классификатор ценит произвольно выбранный
- 12. Для одной точки
- 13. Преимущества ROC Когда алгоритм изучает больше образцов одного (-) класса он будет ошибочно классифицировать больше образцов
- 14. Алгоритм SMOTE Считываем число образцов меньшего класса Т Процент генерируемых образцов N Число ближайших соседей k
- 15. SMOTE
- 17. Преимущества SMOTE Этот способ увеличения меньшего класса не приводит к переобучению (в отличие от random oversampling),
- 18. Модификации SMOTE для дискретных атрибутов образцов При вычислении атрибутов генерируемого образца для номинальных атрибутов значением будут
- 20. Скачать презентацию
Проблема несбалансированности
Данные несбалансированы когда представители классов представлены не в приблизительном равном
Проблема несбалансированности
Данные несбалансированы когда представители классов представлены не в приблизительном равном

В чем проблема?
Многие стандартные классификаторы пытаются увеличить точность и не изменить
В чем проблема?
Многие стандартные классификаторы пытаются увеличить точность и не изменить

Цель классификации - детектирование
Стоимость ошибки неправильно классифицировать ненормальный образец данных как
Цель классификации - детектирование
Стоимость ошибки неправильно классифицировать ненормальный образец данных как

Примеры несбалансированных данных:
1) из 100 000 тысяч подавших заявку, только 2%
Примеры несбалансированных данных:
1) из 100 000 тысяч подавших заявку, только 2%

Техники работы с несбалансированными данными
I. Работа с данными :
SMOTE
Random Undersampling
Random
Техники работы с несбалансированными данными
I. Работа с данными :
SMOTE
Random Undersampling
Random

Метрики качества
Пусть есть два класса — отрицательный и положительный (меньший)
Метрики качества
Пусть есть два класса — отрицательный и положительный (меньший)

1) Accuracy – для сбалансированных данных
Процент правильно классифицированных образцов от всего
1) Accuracy – для сбалансированных данных
Процент правильно классифицированных образцов от всего

2) ROC кривая – для несбалансированных
представляет границы лучших решений для относительных
2) ROC кривая – для несбалансированных
представляет границы лучших решений для относительных


AUC - площадь под ROC кривой .
Она эквивалентна вероятности
AUC - площадь под ROC кривой .
Она эквивалентна вероятности
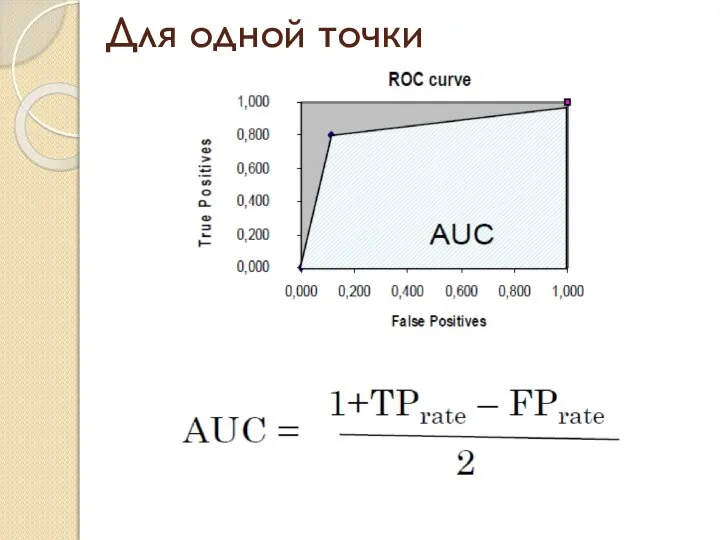
Для одной точки
Для одной точки

Преимущества ROC
Когда алгоритм изучает больше образцов одного (-) класса он будет
Преимущества ROC
Когда алгоритм изучает больше образцов одного (-) класса он будет

Алгоритм SMOTE
Считываем число образцов меньшего класса Т
Процент генерируемых образцов N
Число
Алгоритм SMOTE
Считываем число образцов меньшего класса Т
Процент генерируемых образцов N
Число

SMOTE
SMOTE


Преимущества SMOTE
Этот способ увеличения меньшего класса не приводит к переобучению (в
Преимущества SMOTE
Этот способ увеличения меньшего класса не приводит к переобучению (в

Модификации SMOTE для дискретных атрибутов образцов
При вычислении атрибутов генерируемого образца для
Модификации SMOTE для дискретных атрибутов образцов
При вычислении атрибутов генерируемого образца для
 Функции и их графики. 8 класс
Функции и их графики. 8 класс Тренажёр. Табличное умножение
Тренажёр. Табличное умножение Сложение и вычитание положительных и отрицательных чисел
Сложение и вычитание положительных и отрицательных чисел Математический брейн-ринг
Математический брейн-ринг Взаимно обратные функции
Взаимно обратные функции Презентация по математике "Решение задач" - скачать бесплатно
Презентация по математике "Решение задач" - скачать бесплатно Статистическая обработка массива однородных величин. Практическое занятие 1
Статистическая обработка массива однородных величин. Практическое занятие 1 Объём шара и его частей
Объём шара и его частей Решение задач (4 класс)
Решение задач (4 класс) Математические имена Отчет по проекту
Математические имена Отчет по проекту ДОЛИ И ДРОБИ УМК «Школа 2000» Учебник Л. Г. Петерсон, 4 класс
ДОЛИ И ДРОБИ УМК «Школа 2000» Учебник Л. Г. Петерсон, 4 класс  Объем пирамиды Определение. Формулы. Интересные сведения. Задачи.
Объем пирамиды Определение. Формулы. Интересные сведения. Задачи. Тетраэдр и его сечение
Тетраэдр и его сечение Задачи раскраски графов. Вершинная раскраска
Задачи раскраски графов. Вершинная раскраска Графические задания ЕГЭ. Чтение свойств функции по графику и распознавание графиков элементарных функций
Графические задания ЕГЭ. Чтение свойств функции по графику и распознавание графиков элементарных функций Математические средства представления информации. Таблицы. Диаграммы. Формулы. Графики
Математические средства представления информации. Таблицы. Диаграммы. Формулы. Графики Интерактивные тренинги по геометрии для подготовки к ОГЭ
Интерактивные тренинги по геометрии для подготовки к ОГЭ Тригонометрические функции числового аргумента
Тригонометрические функции числового аргумента Игра по геометрии
Игра по геометрии Применение производной при решении задач ЕГЭ. 11 класс
Применение производной при решении задач ЕГЭ. 11 класс Корень n – ой степени. Арифметический корень n – ой степени, его свойства
Корень n – ой степени. Арифметический корень n – ой степени, его свойства Задачи на проценты
Задачи на проценты Нахождение числа по его части. (6 класс. Тест №15)
Нахождение числа по его части. (6 класс. Тест №15) ГИА - 2016. Открытый банк заданий по математике. Задача №18
ГИА - 2016. Открытый банк заданий по математике. Задача №18 Нумерация чисел в пределах тысячи
Нумерация чисел в пределах тысячи Probability theory. Probability Distributions Statistical Entropy
Probability theory. Probability Distributions Statistical Entropy Решение задачи Бхаскары
Решение задачи Бхаскары Introductory Statistics 1. AP Statistics
Introductory Statistics 1. AP Statistics