- Speech Recognition and Synthesis. Waveform Synthesis (in Concatenative TTS)

Содержание
- 2. Goal of Today’s Lecture Given: String of phones Prosody Desired F0 for entire utterance Duration for
- 3. Outline: Waveform Synthesis in Concatenative TTS Diphone Synthesis Break: Final Projects Unit Selection Synthesis Target cost
- 4. The hourglass architecture
- 5. Internal Representation: Input to Waveform Wynthesis
- 6. Diphone TTS architecture Training: Choose units (kinds of diphones) Record 1 speaker saying 1 example of
- 7. Diphones Mid-phone is more stable than edge:
- 8. Diphones mid-phone is more stable than edge Need O(phone2) number of units Some combinations don’t exist
- 9. Voice Speaker Called a voice talent Diphone database Called a voice
- 10. Designing a diphone inventory: Nonsense words Build set of carrier words: pau t aa b aa
- 11. Designing a diphone inventory: Natural words Greedily select sentences/words: Quebecois arguments Brouhaha abstractions Arkansas arranging Advantages:
- 12. Making recordings consistent: Diiphone should come from mid-word Help ensure full articulation Performed consistently Constant pitch
- 13. Building diphone schemata Find list of phones in language: Plus interesting allophones Stress, tons, clusters, onset/coda,
- 14. Recording conditions Ideal: Anechoic chamber Studio quality recording EGG signal More likely: Quiet room Cheap microphone/sound
- 15. Labeling Diphones Run a speech recognizer in forced alignment mode Forced alignment: A trained ASR system
- 16. Diphone auto-alignment Given synthesized prompts Human speech of same prompts Do a dynamic time warping alignment
- 17. Dynamic Time Warping Slide from Richard Sproat
- 18. Finding diphone boundaries Stable part in phones For stops: one third in For phone-silence: one quarter
- 19. Diphone boundaries in stops Slide from Richard Sproat
- 20. Diphone boundaries in end phones Slide from Richard Sproat
- 21. Concatenating diphones: junctures If waveforms are very different, will perceive a click at the junctures So
- 22. Epoch-labeling An example of epoch-labeling useing “SHOW PULSES” in Praat:
- 23. Epoch-labeling: Electroglottograph (EGG) Also called laryngograph or Lx Device that straps on speaker’s neck near the
- 24. Less invasive way to do epoch-labeling Signal processing E.g.: BROOKES, D. M., AND LOKE, H. P.
- 25. Prosodic Modification Modifying pitch and duration independently Changing sample rate modifies both: Chipmunk speech Duration: duplicate/remove
- 26. Speech as Short Term signals Alan Black
- 27. Duration modification Duplicate/remove short term signals Slide from Richard Sproat
- 28. Duration modification Duplicate/remove short term signals
- 29. Pitch Modification Move short-term signals closer together/further apart Slide from Richard Sproat
- 30. Overlap-and-add (OLA) Huang, Acero and Hon
- 31. Windowing Multiply value of signal at sample number n by the value of a windowing function
- 32. Windowing y[n] = w[n]s[n]
- 33. Overlap and Add (OLA) Hanning windows of length 2N used to multiply the analysis signal Resulting
- 34. TD-PSOLA ™ Time-Domain Pitch Synchronous Overlap and Add Patented by France Telecom (CNET) Very efficient No
- 35. TD-PSOLA ™ Windowed Pitch-synchronous Overlap- -and-add
- 36. TD-PSOLA ™ Thierry Dutoit
- 37. Summary: Diphone Synthesis Well-understood, mature technology Augmentations Stress Onset/coda Demi-syllables Problems: Signal processing still necessary for
- 38. Problems with diphone synthesis Signal processing methods like TD-PSOLA leave artifacts, making the speech sound unnatural
- 39. Unit Selection Synthesis Generalization of the diphone intuition Larger units From diphones to sentences Many many
- 40. Why Unit Selection Synthesis Natural data solves problems with diphones Diphone databases are carefully designed but:
- 41. Unit Selection Intuition Given a big database For each segment (diphone) that we want to synthesize
- 42. Targets and Target Costs A measure of how well a particular unit in the database matches
- 43. Target Costs Comprised of k subcosts Stress Phrase position F0 Phone duration Lexical identity Target cost
- 44. How to set target cost weights (1) What you REALLY want as a target cost is
- 45. How to set target cost weights (2) Clever Hunt and Black (1996) idea: Hold out some
- 46. How to set target cost weights (3) Hunt and Black (1996) Database and target units labeled
- 47. How to set target cost weights (3) Collect phones in classes of acceptable size E.g., stops,
- 48. How to set target cost weights (4) Target distance is For examples in the database, we
- 49. Join (Concatenation) Cost Measure of smoothness of join Measured between two database units (target is irrelevant)
- 50. Join costs Hunt and Black 1996 If ui-1==prev(ui) Cc=0 Used MFCC (mel cepstral features) Local F0
- 51. Join costs The join cost can be used for more than just part of search Can
- 52. Hunt and Black 1996 We now have weights (per phone type) for features set between target
- 53. Improvements Taylor and Black 1999: Phonological Structure Matching Label whole database as trees: Words/phrases, syllables, phones
- 54. Unit Selection Search Slide from Richard Sproat
- 56. Database creation (1) Good speaker Professional speakers are always better: Consistent style and articulation Although these
- 57. Database creation (2) Good recording conditions Good script Application dependent helps Good word coverage News data
- 58. Creating database Unliked diphones, prosodic variation is a good thing Accurate annotation is crucial Pitch annotation
- 59. Practical System Issues Size of typical system (Rhetorical rVoice): ~300M Speed: For each diphone, average of
- 60. Unit Selection Summary Advantages Quality is far superior to diphones Natural prosody selection sounds better Disadvantages:
- 61. Recap: Joining Units (+F0 + duration) unit selection, just like diphone, need to join the units
- 62. Joining Units (just like diphones) Dumb: just join Better: at zero crossings TD-PSOLA Time-domain pitch-synchronous overlap-and-add
- 63. Evaluation of TTS Intelligibility Tests Diagnostic Rhyme Test (DRT) Humans do listening identification choice between two
- 64. Recent stuff Problems with Unit Selection Synthesis Can’t modify signal (mixing modified and unmodified sounds bad)
- 65. HMM Synthesis Unit selection (Roger) HMM (Roger) Unit selection (Nina) HMM (Nina)
- 67. Скачать презентацию

Goal of Today’s Lecture
Given:
String of phones
Prosody
Desired F0 for entire utterance
Duration for
Goal of Today’s Lecture
Given:
String of phones
Prosody
Desired F0 for entire utterance
Duration for

Outline: Waveform Synthesis in Concatenative TTS
Diphone Synthesis
Break: Final Projects
Unit Selection Synthesis
Target
Outline: Waveform Synthesis in Concatenative TTS
Diphone Synthesis
Break: Final Projects
Unit Selection Synthesis
Target
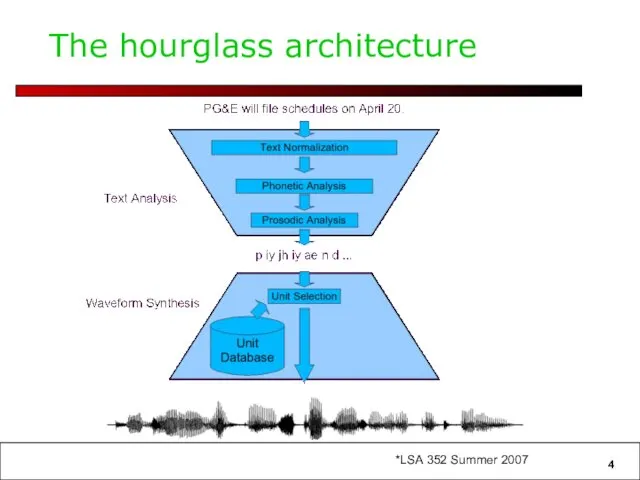
The hourglass architecture
The hourglass architecture
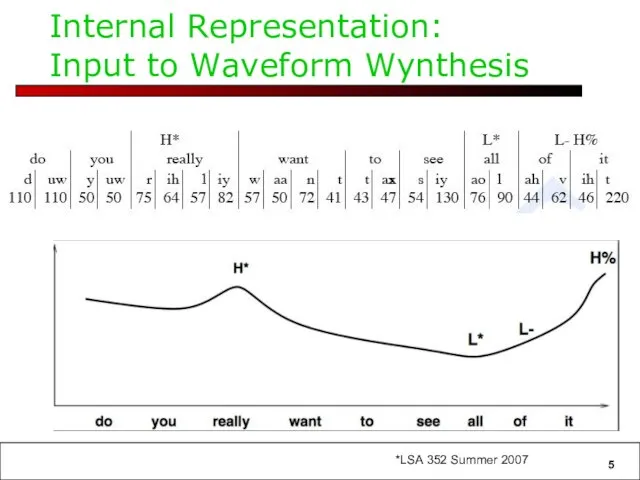
Internal Representation:
Input to Waveform Wynthesis
Internal Representation:
Input to Waveform Wynthesis

Diphone TTS architecture
Training:
Choose units (kinds of diphones)
Record 1 speaker saying 1
Diphone TTS architecture
Training:
Choose units (kinds of diphones)
Record 1 speaker saying 1
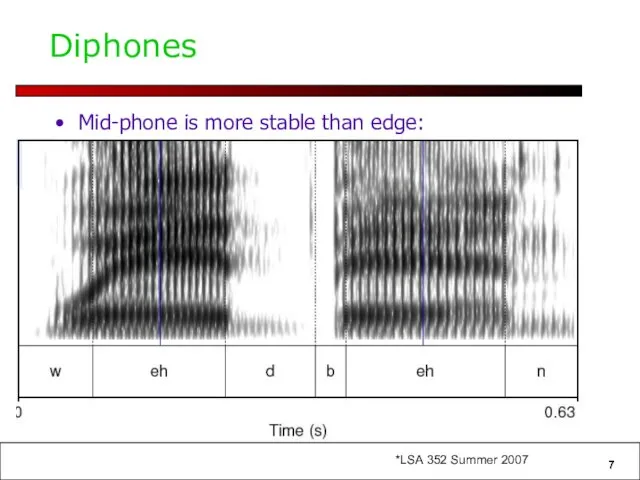
Diphones
Mid-phone is more stable than edge:
Diphones
Mid-phone is more stable than edge:

Diphones
mid-phone is more stable than edge
Need O(phone2) number of units
Some combinations
Diphones
mid-phone is more stable than edge
Need O(phone2) number of units
Some combinations

Voice
Speaker
Called a voice talent
Diphone database
Called a voice
Voice
Speaker
Called a voice talent
Diphone database
Called a voice

Designing a diphone inventory:
Nonsense words
Build set of carrier words:
pau t aa
Designing a diphone inventory:
Nonsense words
Build set of carrier words:
pau t aa

Designing a diphone inventory:
Natural words
Greedily select sentences/words:
Quebecois arguments
Brouhaha abstractions
Arkansas arranging
Advantages:
Will be
Designing a diphone inventory:
Natural words
Greedily select sentences/words:
Quebecois arguments
Brouhaha abstractions
Arkansas arranging
Advantages:
Will be

Making recordings consistent:
Diiphone should come from mid-word
Help ensure full articulation
Performed consistently
Constant
Making recordings consistent:
Diiphone should come from mid-word
Help ensure full articulation
Performed consistently
Constant

Building diphone schemata
Find list of phones in language:
Plus interesting allophones
Stress, tons,
Building diphone schemata
Find list of phones in language:
Plus interesting allophones
Stress, tons,

Recording conditions
Ideal:
Anechoic chamber
Studio quality recording
EGG signal
More likely:
Quiet room
Cheap microphone/sound blaster
No EGG
Headmounted
Recording conditions
Ideal:
Anechoic chamber
Studio quality recording
EGG signal
More likely:
Quiet room
Cheap microphone/sound blaster
No EGG
Headmounted

Labeling Diphones
Run a speech recognizer in forced alignment mode
Forced alignment:
A trained
Labeling Diphones
Run a speech recognizer in forced alignment mode
Forced alignment:
A trained

Diphone auto-alignment
Given
synthesized prompts
Human speech of same prompts
Do a dynamic time
Diphone auto-alignment
Given
synthesized prompts
Human speech of same prompts
Do a dynamic time
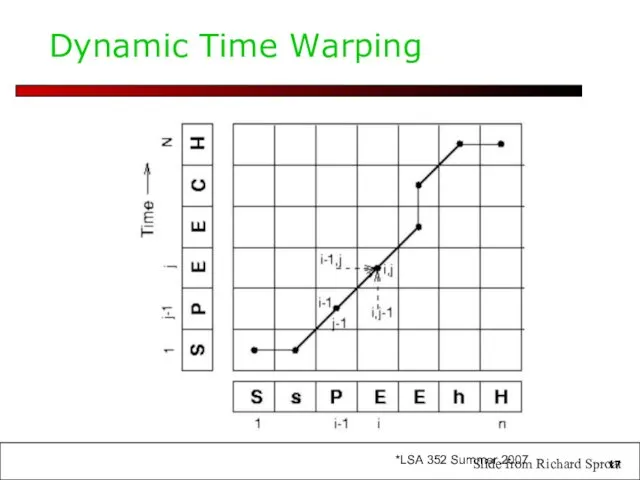
Dynamic Time Warping
Slide from Richard Sproat
Dynamic Time Warping
Slide from Richard Sproat

Finding diphone boundaries
Stable part in phones
For stops: one third in
For phone-silence:
Finding diphone boundaries
Stable part in phones
For stops: one third in
For phone-silence:
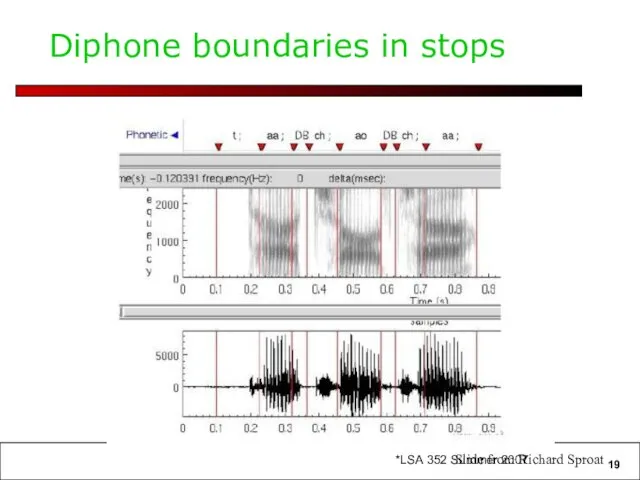
Diphone boundaries in stops
Slide from Richard Sproat
Diphone boundaries in stops
Slide from Richard Sproat
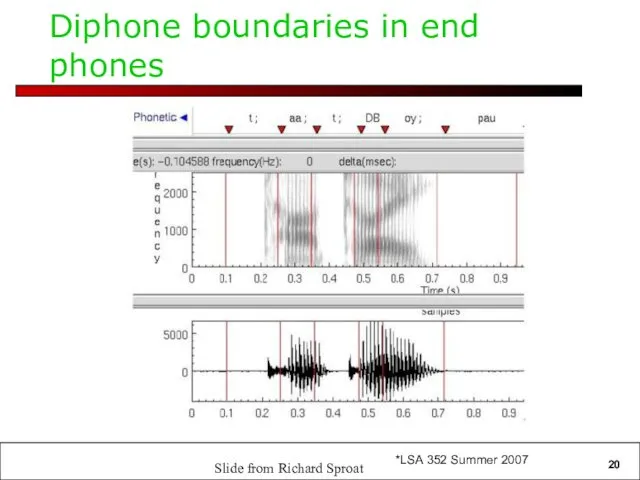
Diphone boundaries in end phones
Slide from Richard Sproat
Diphone boundaries in end phones
Slide from Richard Sproat

Concatenating diphones: junctures
If waveforms are very different, will perceive a click
Concatenating diphones: junctures
If waveforms are very different, will perceive a click

Epoch-labeling
An example of epoch-labeling useing “SHOW PULSES” in Praat:
Epoch-labeling
An example of epoch-labeling useing “SHOW PULSES” in Praat:

Epoch-labeling: Electroglottograph (EGG)
Also called laryngograph or Lx
Device that straps on speaker’s
Epoch-labeling: Electroglottograph (EGG)
Also called laryngograph or Lx
Device that straps on speaker’s

Less invasive way to do epoch-labeling
Signal processing
E.g.:
BROOKES, D. M., AND LOKE,
Less invasive way to do epoch-labeling
Signal processing
E.g.:
BROOKES, D. M., AND LOKE,

Prosodic Modification
Modifying pitch and duration independently
Changing sample rate modifies both:
Chipmunk speech
Duration:
Prosodic Modification
Modifying pitch and duration independently
Changing sample rate modifies both:
Chipmunk speech
Duration:
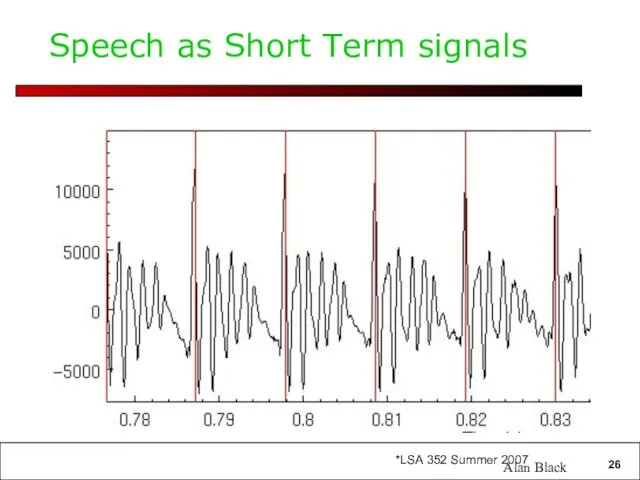
Speech as Short Term signals
Alan Black
Speech as Short Term signals
Alan Black

Duration modification
Duplicate/remove short term signals
Slide from Richard Sproat
Duration modification
Duplicate/remove short term signals
Slide from Richard Sproat
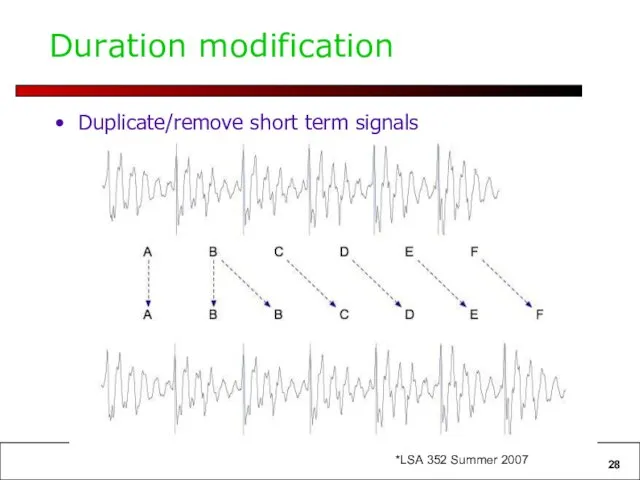
Duration modification
Duplicate/remove short term signals
Duration modification
Duplicate/remove short term signals
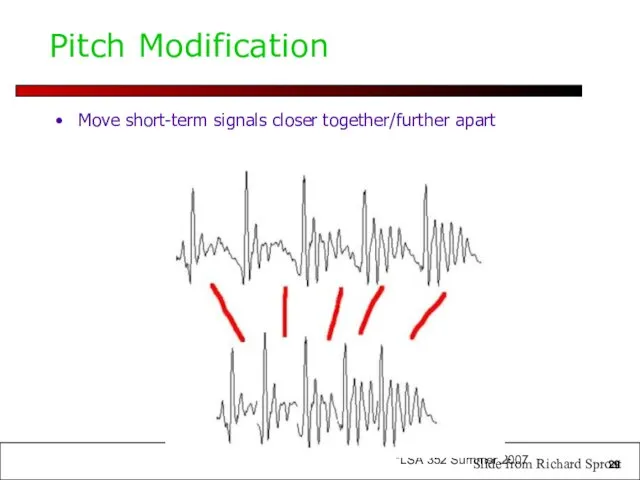
Pitch Modification
Move short-term signals closer together/further apart
Slide from Richard Sproat
Pitch Modification
Move short-term signals closer together/further apart
Slide from Richard Sproat
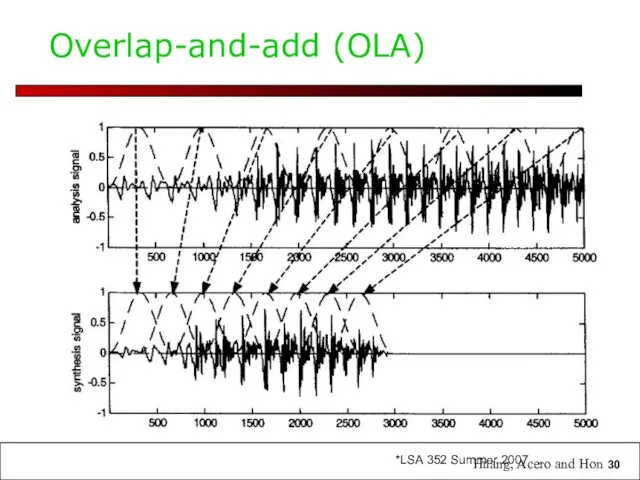
Overlap-and-add (OLA)
Huang, Acero and Hon
Overlap-and-add (OLA)
Huang, Acero and Hon

Windowing
Multiply value of signal at sample number n by the value
Windowing
Multiply value of signal at sample number n by the value
![Windowing y[n] = w[n]s[n]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/467518/slide-31.jpg)
Windowing
y[n] = w[n]s[n]
Windowing
y[n] = w[n]s[n]

Overlap and Add (OLA)
Hanning windows of length 2N used to multiply
Overlap and Add (OLA)
Hanning windows of length 2N used to multiply

TD-PSOLA ™
Time-Domain Pitch Synchronous Overlap and Add
Patented by France Telecom (CNET)
Very
TD-PSOLA ™
Time-Domain Pitch Synchronous Overlap and Add
Patented by France Telecom (CNET)
Very
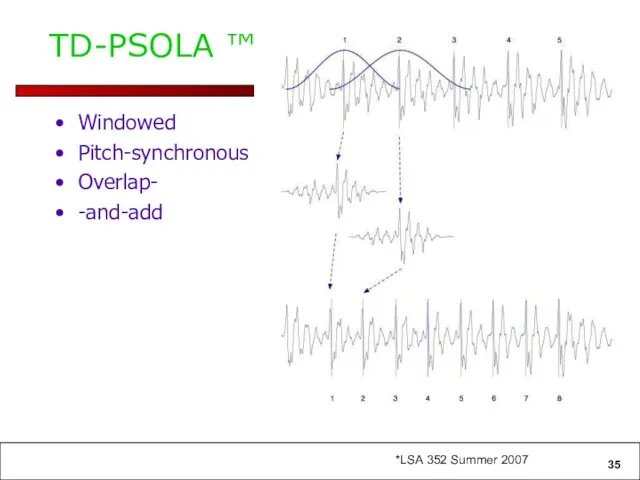
TD-PSOLA ™
Windowed
Pitch-synchronous
Overlap-
-and-add
TD-PSOLA ™
Windowed
Pitch-synchronous
Overlap-
-and-add
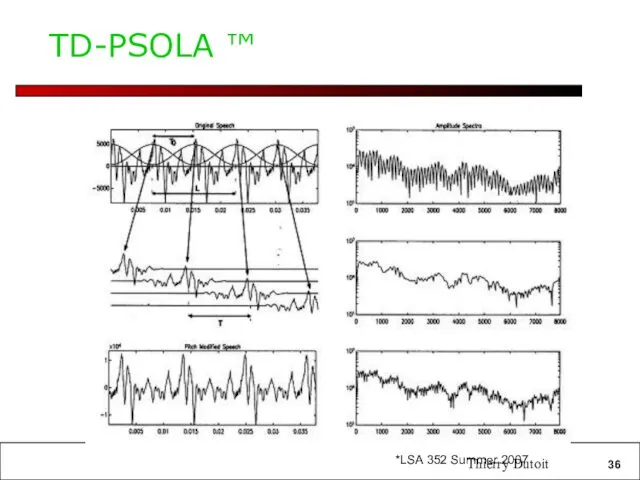
TD-PSOLA ™
Thierry Dutoit
TD-PSOLA ™
Thierry Dutoit

Summary: Diphone Synthesis
Well-understood, mature technology
Augmentations
Stress
Onset/coda
Demi-syllables
Problems:
Signal processing still necessary for modifying durations
Source
Summary: Diphone Synthesis
Well-understood, mature technology
Augmentations
Stress
Onset/coda
Demi-syllables
Problems:
Signal processing still necessary for modifying durations
Source

Problems with diphone synthesis
Signal processing methods like TD-PSOLA leave artifacts, making
Problems with diphone synthesis
Signal processing methods like TD-PSOLA leave artifacts, making

Unit Selection Synthesis
Generalization of the diphone intuition
Larger units
From diphones to
Unit Selection Synthesis
Generalization of the diphone intuition
Larger units
From diphones to

Why Unit Selection Synthesis
Natural data solves problems with diphones
Diphone databases are
Why Unit Selection Synthesis
Natural data solves problems with diphones
Diphone databases are

Unit Selection Intuition
Given a big database
For each segment (diphone) that we
Unit Selection Intuition
Given a big database
For each segment (diphone) that we

Targets and Target Costs
A measure of how well a particular unit
Targets and Target Costs
A measure of how well a particular unit

Target Costs
Comprised of k subcosts
Stress
Phrase position
F0
Phone duration
Lexical identity
Target cost for a
Target Costs
Comprised of k subcosts
Stress
Phrase position
F0
Phone duration
Lexical identity
Target cost for a

How to set target cost weights (1)
What you REALLY want as
How to set target cost weights (1)
What you REALLY want as

How to set target cost weights (2)
Clever Hunt and Black (1996)
How to set target cost weights (2)
Clever Hunt and Black (1996)

How to set target cost weights (3)
Hunt and Black (1996)
Database and
How to set target cost weights (3)
Hunt and Black (1996)
Database and

How to set target cost weights (3)
Collect phones in classes of
How to set target cost weights (3)
Collect phones in classes of

How to set target cost weights (4)
Target distance is
For examples in
How to set target cost weights (4)
Target distance is
For examples in

Join (Concatenation) Cost
Measure of smoothness of join
Measured between two database units
Join (Concatenation) Cost
Measure of smoothness of join
Measured between two database units

Join costs
Hunt and Black 1996
If ui-1==prev(ui) Cc=0
Used
MFCC (mel cepstral features)
Local F0
Local
Join costs
Hunt and Black 1996
If ui-1==prev(ui) Cc=0
Used
MFCC (mel cepstral features)
Local F0
Local

Join costs
The join cost can be used for more than just
Join costs
The join cost can be used for more than just

Hunt and Black 1996
We now have weights (per phone type) for
Hunt and Black 1996
We now have weights (per phone type) for

Improvements
Taylor and Black 1999: Phonological Structure Matching
Label whole database as trees:
Words/phrases,
Improvements
Taylor and Black 1999: Phonological Structure Matching
Label whole database as trees:
Words/phrases,
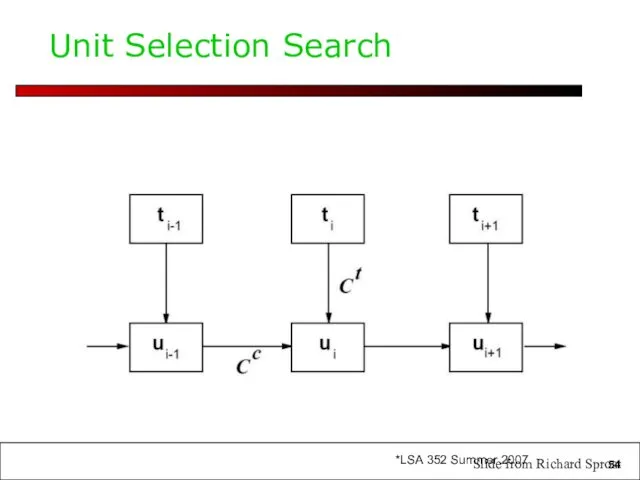
Unit Selection Search
Slide from Richard Sproat
Unit Selection Search
Slide from Richard Sproat


Database creation (1)
Good speaker
Professional speakers are always better:
Consistent style and articulation
Although
Database creation (1)
Good speaker
Professional speakers are always better:
Consistent style and articulation
Although

Database creation (2)
Good recording conditions
Good script
Application dependent helps
Good word coverage
News data
Database creation (2)
Good recording conditions
Good script
Application dependent helps
Good word coverage
News data

Creating database
Unliked diphones, prosodic variation is a good thing
Accurate annotation is
Creating database
Unliked diphones, prosodic variation is a good thing
Accurate annotation is

Practical System Issues
Size of typical system (Rhetorical rVoice):
~300M
Speed:
For each diphone, average
Practical System Issues
Size of typical system (Rhetorical rVoice):
~300M
Speed:
For each diphone, average

Unit Selection Summary
Advantages
Quality is far superior to diphones
Natural prosody selection sounds
Unit Selection Summary
Advantages
Quality is far superior to diphones
Natural prosody selection sounds

Recap: Joining Units (+F0 + duration)
unit selection, just like diphone, need
Recap: Joining Units (+F0 + duration)
unit selection, just like diphone, need

Joining Units (just like diphones)
Dumb:
just join
Better: at zero crossings
TD-PSOLA
Time-domain
Joining Units (just like diphones)
Dumb:
just join
Better: at zero crossings
TD-PSOLA
Time-domain

Evaluation of TTS
Intelligibility Tests
Diagnostic Rhyme Test (DRT)
Humans do listening identification choice
Evaluation of TTS
Intelligibility Tests
Diagnostic Rhyme Test (DRT)
Humans do listening identification choice

Recent stuff
Problems with Unit Selection Synthesis
Can’t modify signal
(mixing modified and unmodified
Recent stuff
Problems with Unit Selection Synthesis
Can’t modify signal
(mixing modified and unmodified

HMM Synthesis
Unit selection (Roger)
HMM (Roger)
Unit selection (Nina)
HMM (Nina)
HMM Synthesis
Unit selection (Roger)
HMM (Roger)
Unit selection (Nina)
HMM (Nina)
 Отношение сигнал-шум на выходе приёмника ЧМ сигнала
Отношение сигнал-шум на выходе приёмника ЧМ сигнала Открытие радиоактивности. Радиоактивные превращения СОСТАВИЛА УЧИТЕЛЬ ФИЗИКИ МБОУ МСОШ: МУХИНА ВАЛЕНТИНА ВЛАДИМИРОВНА ФИЗИКА
Открытие радиоактивности. Радиоактивные превращения СОСТАВИЛА УЧИТЕЛЬ ФИЗИКИ МБОУ МСОШ: МУХИНА ВАЛЕНТИНА ВЛАДИМИРОВНА ФИЗИКА  Лекция № 3 Принцип корпускулярно-волнового дуализма Л. де Бройля и его экспериментальное подтверждение
Лекция № 3 Принцип корпускулярно-волнового дуализма Л. де Бройля и его экспериментальное подтверждение Арматура и ее свойства. Робот для вязки арматуры (9 класс)
Арматура и ее свойства. Робот для вязки арматуры (9 класс) Шкала электромагнитных излучений
Шкала электромагнитных излучений Ценностные и правовые регулятивы развития новых технологий и направлений науки. Тема 5
Ценностные и правовые регулятивы развития новых технологий и направлений науки. Тема 5 Показатели качества регулирования. Точность регулирования
Показатели качества регулирования. Точность регулирования Общие физические модели
Общие физические модели Основные законы для расчета цепей постоянного тока
Основные законы для расчета цепей постоянного тока Волновые свойства света
Волновые свойства света Испарение, влажность
Испарение, влажность Голограмма – чудо современной оптики
Голограмма – чудо современной оптики Торговое оборудование. Холодильные машины и оборудование. Способы получения холода
Торговое оборудование. Холодильные машины и оборудование. Способы получения холода Механические колебания
Механические колебания Заболевания молочных желёз. Взгляд гинеколога
Заболевания молочных желёз. Взгляд гинеколога Исследовательская работа. Создание радуги в домашних условиях
Исследовательская работа. Создание радуги в домашних условиях Механическое движение. Плотность вещества. Решение задач, 7 класс
Механическое движение. Плотность вещества. Решение задач, 7 класс Ресурсный центр по учебному предмету физика
Ресурсный центр по учебному предмету физика Экспериментальная проверка закона Джоуля-Ленца
Экспериментальная проверка закона Джоуля-Ленца Истечение газов и паров
Истечение газов и паров Аэродинамические расчеты
Аэродинамические расчеты Температура и термометры
Температура и термометры харчування під час радіоактивної небезпеки Підготувала учениця 302 групи Авіакосмічного ліцею ім.І.Сікорського НАУ Гріднєва А
харчування під час радіоактивної небезпеки Підготувала учениця 302 групи Авіакосмічного ліцею ім.І.Сікорського НАУ Гріднєва А Антеннаның негізгі параметрлері мен сипаттамалары
Антеннаның негізгі параметрлері мен сипаттамалары Механические колебания. Волны
Механические колебания. Волны Элементы кинетической теории газов. (Лекция 2)
Элементы кинетической теории газов. (Лекция 2) Генератор переменного тока
Генератор переменного тока Специальная теория относительности
Специальная теория относительности