- Algorytmy sortujące

Содержание
- 2. ALGORYTMY SORTUJĄCE Sortowanie przez wstawianie Sortowanie przez wybór
- 3. Wstęp Sortowanie – jeden z podstawowych problemów informatyki. Polega na uporządkowaniu zbioru danych względem pewnych cech
- 4. Zbiór posortowany to taki zbiór, w którym kolejne elementy są poukładane w pewnym porządku (kolejności). Porządek
- 5. Czasowa złożoność obliczeniowa (ang. computational complexity) algorytmu sortującego (istnieje również złożoność pamięciowa) – określa statystycznie czas
- 6. W poniższej tabeli przedstawiono przykładowe zapisy klas złożoności obliczeniowej algorytmów.
- 7. Ze względu na złożoność pamięciową algorytmy sortujące dzielimy na dwie podstawowe grupy: Algorytmy sortujące w miejscu
- 8. Algorytmy sortujące dzieli się również na dwie grupy: Algorytmy stabilne - zachowują kolejność elementów równych. Oznacza
- 9. Algorytmy niestabilne - kolejność wynikowa elementów równych jest nieokreślona (zwykle nie zostaje zachowana). sortowanie przez wybór
- 10. Jest to jedna z prostszych metod sortowania posiadająca klasę czasowej złożoności obliczeniowej równą O(n2). Polega na
- 11. Posortujmy dany zbiór (5 8 2 9 4). Kolorem niebieskim oznaczone zostały elementy zbioru, które zostały
- 12. Dane wejściowe n - liczba elementów w sortowanym zbiorze, n ∈ N d[ ] - zbiór
- 13. Schemat blokowy Pętla zewnętrzna sterowana zmienną j wyznacza kolejne elementy zbioru o indeksach od 1 do
- 14. Sortowanie przez wstawianie - Insertion Sort Jest to prosty algorytm sortowania, o złożoności O(n2), sortowanie odbywa
- 15. Schemat działania algorytmu: Na początku sortowania lista uporządkowana zawiera tylko jeden, ostatni element zbioru. Jednoelementowa lista
- 16. Przykład Dla przykładu wstawmy według opisanej metody pierwszy element zbioru listę uporządkowaną utworzoną z pozostałych elementów
- 17. Ciąg dalszy przykładu:
- 18. Dane wejściowe n - liczba elementów w sortowanym zbiorze, n Î N d[ ] - zbiór
- 19. Schemat blokowy Pętlę główną rozpoczynamy od przedostatniej pozycji w zbiorze. Element na ostatniej pozycji jest zalążkiem
- 20. W obu przypadkach na puste miejsce ma trafić zawartość zmiennej x i pętla zewnętrzna jest kontynuowana.
- 21. Algorytm sortowania przez wstawianie nie uwzględnia faktu posortowania zbioru. Jednakże również nie wyróżnia on przypadku posortowania
- 23. Скачать презентацию

ALGORYTMY SORTUJĄCE
Sortowanie przez wstawianie Sortowanie przez wybór
ALGORYTMY SORTUJĄCE
Sortowanie przez wstawianie Sortowanie przez wybór

Wstęp
Sortowanie – jeden z podstawowych problemów informatyki. Polega na uporządkowaniu zbioru
Wstęp
Sortowanie – jeden z podstawowych problemów informatyki. Polega na uporządkowaniu zbioru

Zbiór posortowany to taki zbiór, w którym kolejne elementy są poukładane
Zbiór posortowany to taki zbiór, w którym kolejne elementy są poukładane

Czasowa złożoność obliczeniowa (ang. computational complexity) algorytmu sortującego (istnieje również złożoność
Czasowa złożoność obliczeniowa (ang. computational complexity) algorytmu sortującego (istnieje również złożoność
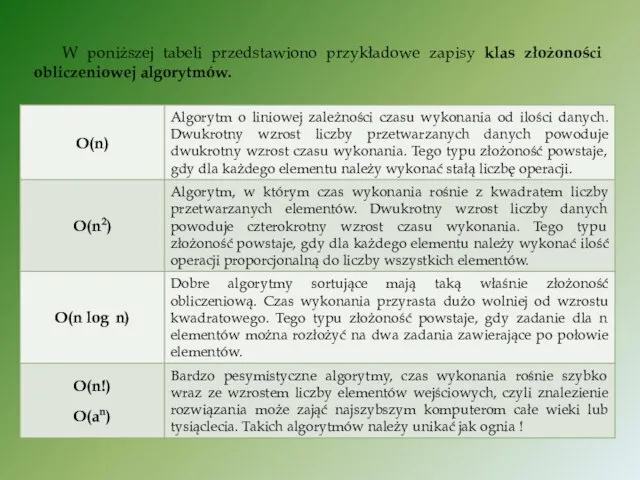
W poniższej tabeli przedstawiono przykładowe zapisy klas złożoności obliczeniowej algorytmów.
W poniższej tabeli przedstawiono przykładowe zapisy klas złożoności obliczeniowej algorytmów.

Ze względu na złożoność pamięciową algorytmy sortujące dzielimy na dwie podstawowe
Ze względu na złożoność pamięciową algorytmy sortujące dzielimy na dwie podstawowe

Algorytmy sortujące dzieli się również na dwie grupy:
Algorytmy stabilne - zachowują
Algorytmy sortujące dzieli się również na dwie grupy:
Algorytmy stabilne - zachowują

Algorytmy niestabilne - kolejność wynikowa elementów
równych jest nieokreślona (zwykle nie
Algorytmy niestabilne - kolejność wynikowa elementów
równych jest nieokreślona (zwykle nie

Jest to jedna z prostszych metod sortowania posiadająca klasę czasowej złożoności
Jest to jedna z prostszych metod sortowania posiadająca klasę czasowej złożoności
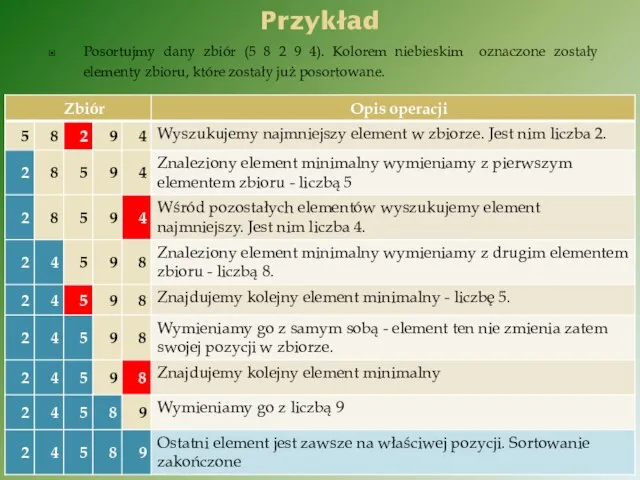
Posortujmy dany zbiór (5 8 2 9 4). Kolorem niebieskim oznaczone
Posortujmy dany zbiór (5 8 2 9 4). Kolorem niebieskim oznaczone

Dane wejściowe
n - liczba elementów w sortowanym zbiorze, n ∈ N
Dane wejściowe
n - liczba elementów w sortowanym zbiorze, n ∈ N
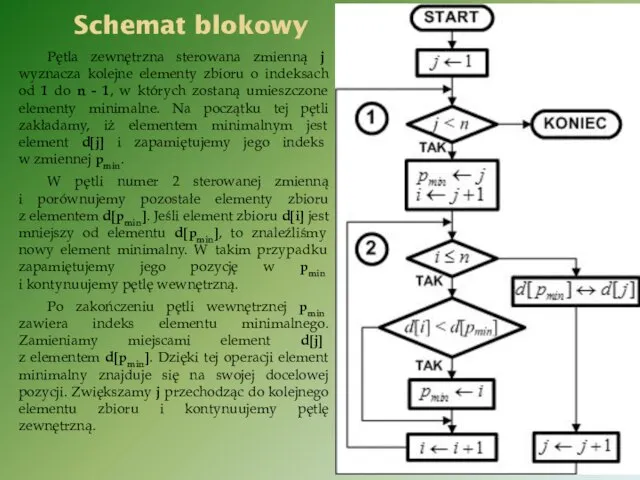
Schemat blokowy
Pętla zewnętrzna sterowana zmienną j wyznacza kolejne elementy zbioru o
Schemat blokowy
Pętla zewnętrzna sterowana zmienną j wyznacza kolejne elementy zbioru o

Sortowanie przez wstawianie
- Insertion Sort
Jest to prosty algorytm sortowania, o
Sortowanie przez wstawianie
- Insertion Sort
Jest to prosty algorytm sortowania, o

Schemat działania algorytmu:
Na początku sortowania lista uporządkowana zawiera tylko jeden, ostatni
Schemat działania algorytmu:
Na początku sortowania lista uporządkowana zawiera tylko jeden, ostatni
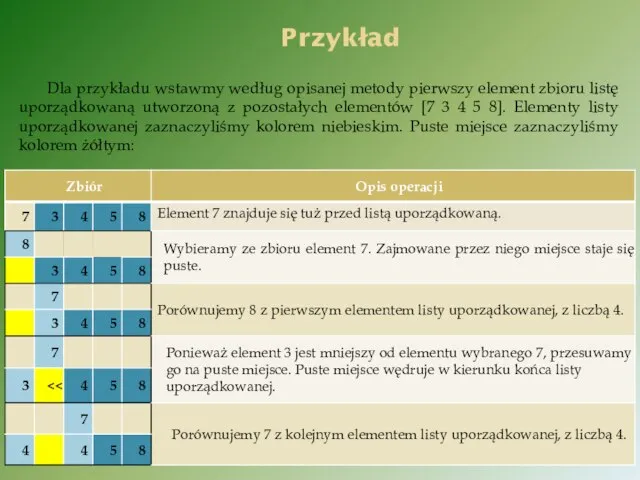
Przykład
Dla przykładu wstawmy według opisanej metody pierwszy element zbioru listę uporządkowaną
Przykład
Dla przykładu wstawmy według opisanej metody pierwszy element zbioru listę uporządkowaną
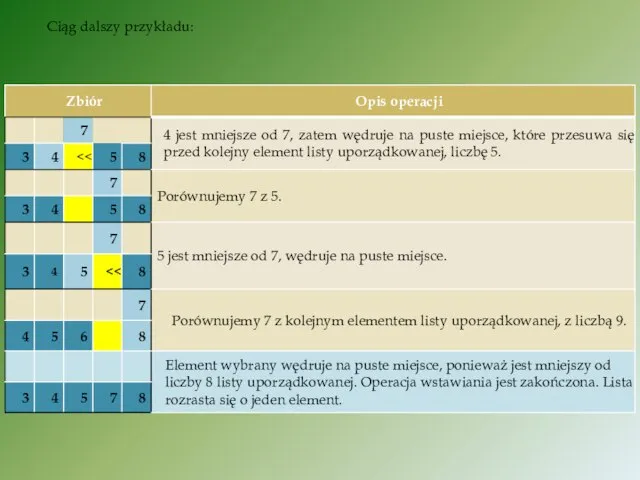
Ciąg dalszy przykładu:
Ciąg dalszy przykładu:

Dane wejściowe
n - liczba elementów w sortowanym zbiorze, n Î N
Dane wejściowe
n - liczba elementów w sortowanym zbiorze, n Î N
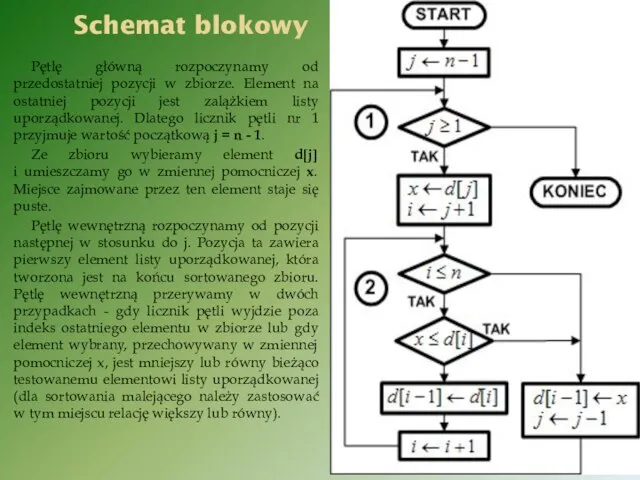
Schemat blokowy
Pętlę główną rozpoczynamy od przedostatniej pozycji w zbiorze. Element na
Schemat blokowy
Pętlę główną rozpoczynamy od przedostatniej pozycji w zbiorze. Element na
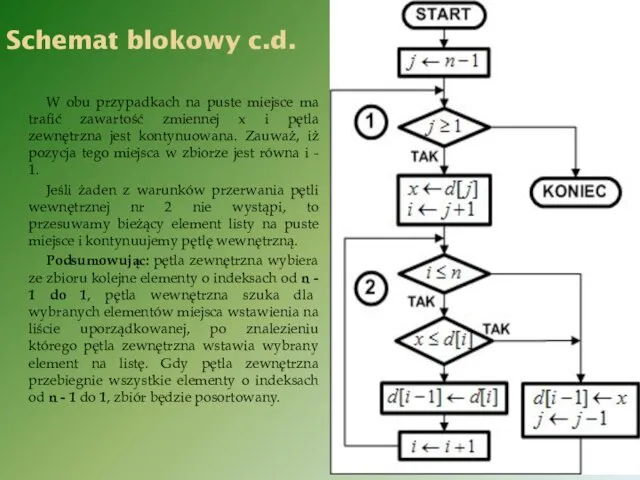
W obu przypadkach na puste miejsce ma trafić zawartość zmiennej x
W obu przypadkach na puste miejsce ma trafić zawartość zmiennej x

Algorytm sortowania przez wstawianie nie uwzględnia faktu posortowania zbioru. Jednakże również
Algorytm sortowania przez wstawianie nie uwzględnia faktu posortowania zbioru. Jednakże również
 Программирование на языке С++. Лекция 7. Указатели, ссылки и массивы
Программирование на языке С++. Лекция 7. Указатели, ссылки и массивы Презентация "ИНФОРМАЦИОННЫЙ КАЛЕЙДОСКОП" - скачать презентации по Информатике
Презентация "ИНФОРМАЦИОННЫЙ КАЛЕЙДОСКОП" - скачать презентации по Информатике Работа_в_REDMINE_
Работа_в_REDMINE_ Теория кодирования
Теория кодирования Программирование на языке Python
Программирование на языке Python AngularJS - Javascript библиотека
AngularJS - Javascript библиотека Сервер вычислений и web-интерфейс для работы с математическими и статистическими пакетами д-т Чичкарев Е.А. Стариков И.В.
Сервер вычислений и web-интерфейс для работы с математическими и статистическими пакетами д-т Чичкарев Е.А. Стариков И.В. Програмне забезпечення
Програмне забезпечення Способы подключения к Интернету
Способы подключения к Интернету Классификация ЭВМ
Классификация ЭВМ Модели жизненного цикла информационной системы. Каскадная модель
Модели жизненного цикла информационной системы. Каскадная модель Классификация ЭВМ по поколениям
Классификация ЭВМ по поколениям Социальные сети. Нехимические виды зависимости. Первичная профилактика. Межведомственный подход
Социальные сети. Нехимические виды зависимости. Первичная профилактика. Межведомственный подход Интеллект-карты
Интеллект-карты Основные типы запросов
Основные типы запросов Интернет - мошенничество вчера, сегодня, завтра. Взаимодействие компетентных организаций и регистраторов доменных имен
Интернет - мошенничество вчера, сегодня, завтра. Взаимодействие компетентных организаций и регистраторов доменных имен Влияние на здоровье беспроводных сетей
Влияние на здоровье беспроводных сетей Аудит Сайта
Аудит Сайта Технология цифровых подписей
Технология цифровых подписей Поиск информации в сети
Поиск информации в сети Кейс технологии. методология и содержание
Кейс технологии. методология и содержание Роль государства в развитии информационного общества
Роль государства в развитии информационного общества Введение в информатику
Введение в информатику  Криптографическая защита информации. Классические криптоалгоритмы – моноалфавитные подстановки
Криптографическая защита информации. Классические криптоалгоритмы – моноалфавитные подстановки Microsoft Office Еxcel
Microsoft Office Еxcel Микросервисы. Лекция 11
Микросервисы. Лекция 11 Сетевые службы. Кластеры
Сетевые службы. Кластеры Разработка программ с графическим интерфейсом. Интерфейс программы и событийное программирование (тема 8)
Разработка программ с графическим интерфейсом. Интерфейс программы и событийное программирование (тема 8)