- Базовые модели данных. Лекция 9

Содержание
- 2. 1. Основные понятия моделей данных Под моделью данных понимают совокупность принципов организации данных. Модель отражает наиболее
- 3. Информационные единицы составляющие основу организации моделей знак — элементарная единица информации, являющаяся реализацией свойств объекта в
- 4. сущность — элемент модели (совокупность атрибутов и знаков), описывающая законченный объект или понятие; · атрибут —
- 5. Предметной областью называется подмножество (часть реального мира), на котором определяется набор данных и методы манипулирования с
- 6. Обобщение в свою очередь подразделяется на две категории: собственно обобщение и классификация. собственно обобщение – процедура
- 7. Схема структурирования данных с применением процедур абстракции: а) прямые процедуры; б) обратные процедуры
- 8. Пример построения модели на основе процедур обобщения
- 9. Пример построения модели на основе процедур агрегации
- 10. 2. Классификация моделей данных в ГИС
- 11. Все модели данных делятся на статические и динамические модели К статическим относятся модели инвариантные относительно времени.
- 12. Классификация моделей по степени типизации Сильно типизированные – это модели, в которых большинство данных удовлетворяет неким
- 13. Представление моделей Выделяют табличные и графовые формы представления моделей. Табличная форма дает представление модели или ее
- 14. Графовая форма основана на построении модели в виде графической схемы, называемой графом. Эта схема включает элементы
- 15. По форме отображения модели данных делятся на аналоговые и дискретные Аналоговые модели в свою очередь разбиваются
- 16. Дискретные модели строятся путем замены непрерывных функций набором дискретных значений аргументов и функций. Дискретность определяется шагом
- 17. В ГИС РАЗЛИЧАЮТ СПЕЦИАЛЬНЫЕ МОДЕЛИ БАЗОВЫЕ МОДЕЛИ
- 18. Базовые модели данных Среди базовых моделей данных выделяют Квадратомическое дерево Иерархическая модель Инфологическая модель Сетевые модели
- 19. Специальные модели данных Среди специальных моделей выделяют: Растровые Векторные Векторные топологические Векторные нетопологические
- 20. 3. Иерархическая модель Иерархическая модель относится к наиболее простым структурно определенным моделям. В этой модели данных
- 21. Иерархическая модель проектирования ГИС
- 22. В иерархических моделях данных существует два внутренних ограничения: все типы связей должны быть фукнциональными; структура связей
- 24. Недостатком иерархической модели является снижение времени доступа при большом числе уровней, поэтому в ГИС не используются
- 25. Данная модель имеет множество названий: - Квадротомическая модель; - Квадротомическое представление (данных); - квадродерево; - дерево
- 26. Это модель является один из способов представления пространственных объектов в виде иерархической древовидной структуры основанный на
- 27. Квадратомическиое дерево – структура, используемая для накопления и хранения географической информации. В этой структуре двухмерная геометрическая
- 28. На рисунке показан фрагмент двухмерной области Qt, состоящей из 16 пикселей. Каждый пиксель обозначен цифрой. Вся
- 29. Двухмерная область Qt, состоящая из 16 пикселей
- 30. Квадратомическое дерево в виде Е-структуры
- 31. На этом слайде показано квадратомическое дерево, построенное по данным двухмерной области Qt из 16 пикселей. Как
- 32. В модели списка можно пользоваться только одним индексным компонентом – номером строки, получить доступ к которому
- 33. Модель дерева подобна модели таблицы при следующих отличиях. Как и в модели таблицы, родительский элемент элементов
- 34. Модель дерева
- 35. Модели, основанные на квадратомических деревьях, обеспечивают расчеты площадей, центроидные определения, распознавание образов, выявление связанных компонентов, определение
- 36. Разбиение пространства карты с помощью квадродерева
- 37. Определение средневзвешенной густоты бассейна реки
- 38. Квадродерево представления векторной информации
- 39. Примеры визуализации квадродеревьев Визуализация карты Москвы по принципу квадродерева
- 40. Пример матричного квадродерева
- 41. Реляционная модель данных – логическая модель данных. Представляет интерес как наиболее математически проработанная. Впервые была предложена
- 42. ЭДГАР КОДД (1923-2003)
- 43. Реляционная модель данных представляет собой хранилище данных, организованных в виде двумерных таблиц. С таблицами знакомы все,
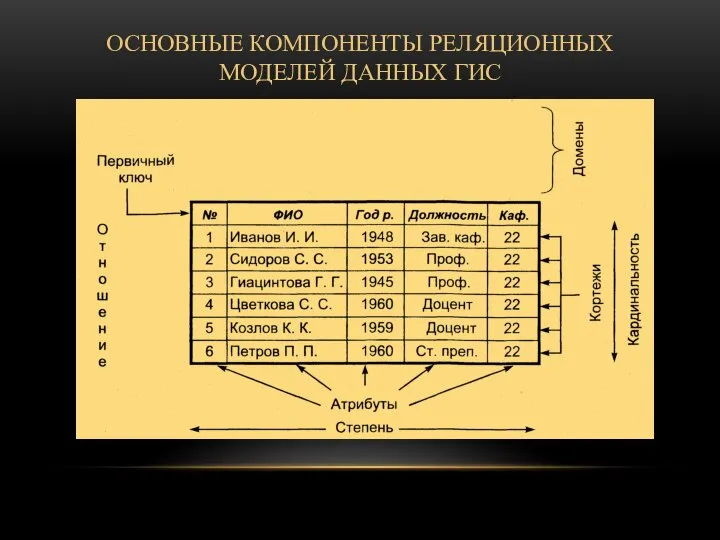
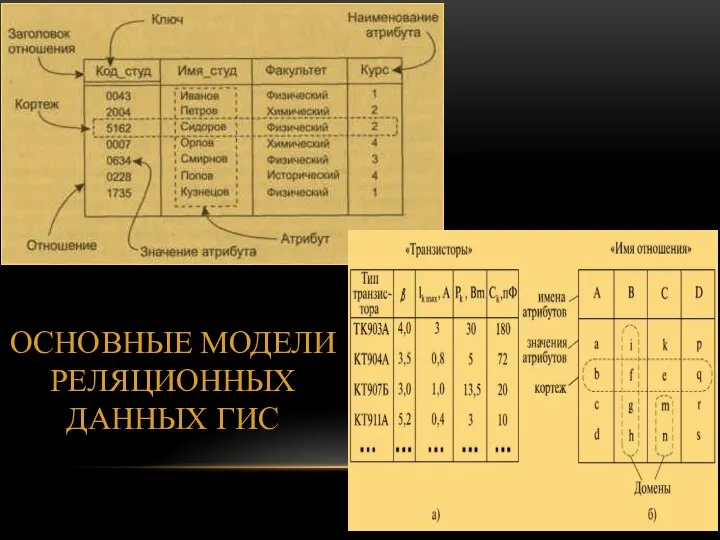
- 44. Основными понятиями реляционной модели являются: атрибут кортеж отношение
- 45. Атрибуты Это самые простые элементы структуры таблицы. В таблице мы их видим как названия столбцов. Атрибуты
- 46. Атрибуты различаются по типам. Наиболее известные из них: числовой; текстовой; логический. Есть и другие типы, в
- 47. Например: в таблице-каталоге скважин могут быть следующие атрибуты: Номер/индекс скважины ID; Координаты X и Y; Высота
- 48. Пример атрибутов в реляционной модели
- 49. Кортежи Это аналоги строк в таблице. Каждый кортеж содержит несколько элементов по числу атрибутов таблицы, каждый
- 50. В примере для каталога скважин можно записать строку-кортеж так:
- 51. Основные типы данных в реляционной модели те же, что и в программировании: целочисленный INTEGER; дробночисленный (с
- 52. Однако любых математических типов будет недостаточно, чтобы построить целостную базу данных и избежать несоответствий. Например, координаты
- 53. Домен это потенциально возможное множество значений. Domain в переводе означает «область», здесь смысл не расходится с
- 54. Первичный ключ (primary key) Это очень важное понятие, можно сказать «ключевое». Теоретически это набор значений, который
- 55. Пример: для таблицы-каталога скважин первичный ключ – номер (индекс) скважины, для таблицы замеров грунтовых вод первичный
- 56. Внешний ключ (Foreign key) Служит для связи таблиц. Это значения из одной таблицы, по которым можно
- 57. Внешний ключ
- 58. Внешний ключ должен ссылаться на первичный ключ другой таблицы. В своей таблице он может быть обычным
- 59. ОСНОВНЫЕ КОМПОНЕНТЫ РЕЛЯЦИОННЫХ МОДЕЛЕЙ ДАННЫХ ГИС
- 60. ОСНОВНЫЕ МОДЕЛИ РЕЛЯЦИОННЫХ ДАННЫХ ГИС
- 61. Выделяют три составные части реляционной модели данных: структурную манипуляционную целостную
- 62. Структурная часть модели Определяет, что единственной структурой данных является нормализованное парное отношение. Отношения удобно представлять в
- 63. Манипуляционная часть модели Определяет два фундаментальных механизма манипулирования данными – реляционная алгебра и реляционное исчисление. Основной
- 64. Целостная часть модели определяет требования целостности сущностей и целостности ссылок. Первое требование состоит в том, что
- 65. Недостатки реляционной модели
- 67. Скачать презентацию

1. Основные понятия моделей данных
Под моделью данных понимают совокупность принципов
1. Основные понятия моделей данных
Под моделью данных понимают совокупность принципов

Информационные единицы составляющие основу организации моделей
знак — элементарная единица информации,
Информационные единицы составляющие основу организации моделей
знак — элементарная единица информации,

сущность — элемент модели (совокупность атрибутов и знаков), описывающая
сущность — элемент модели (совокупность атрибутов и знаков), описывающая

Предметной областью называется подмножество (часть реального мира), на котором определяется набор
Предметной областью называется подмножество (часть реального мира), на котором определяется набор

Обобщение в свою очередь подразделяется на две категории: собственно обобщение и
Обобщение в свою очередь подразделяется на две категории: собственно обобщение и
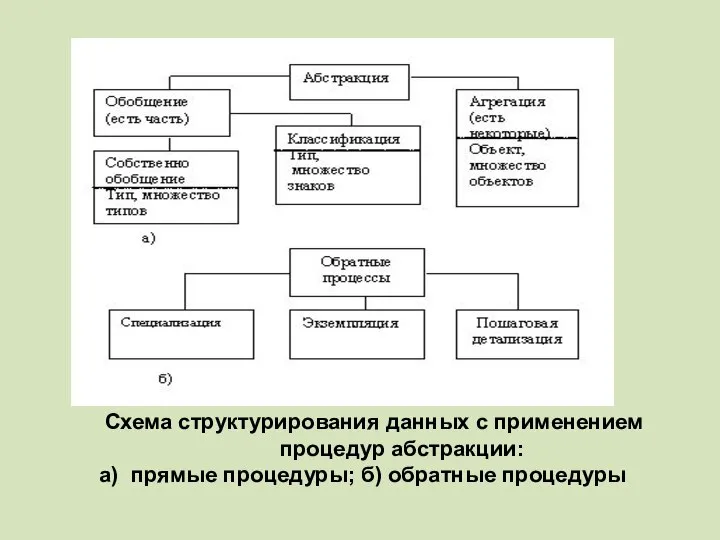
Схема структурирования данных с применением процедур абстракции:
а) прямые процедуры;
Схема структурирования данных с применением процедур абстракции: а) прямые процедуры;
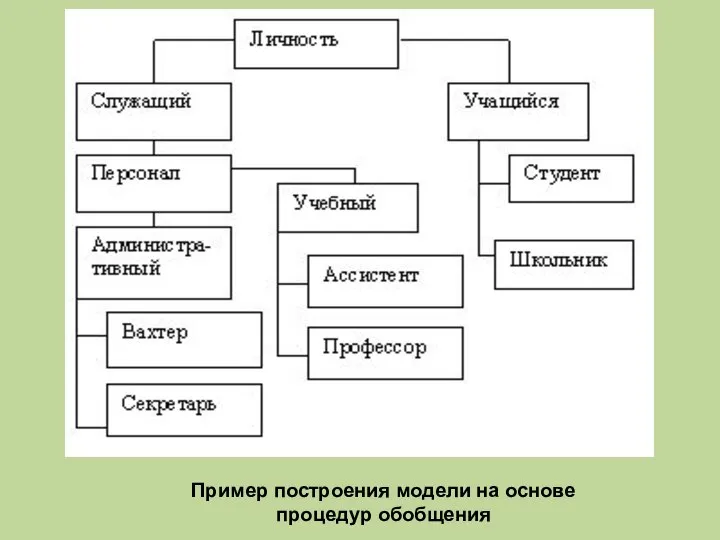
Пример построения модели на основе
процедур обобщения
Пример построения модели на основе
процедур обобщения
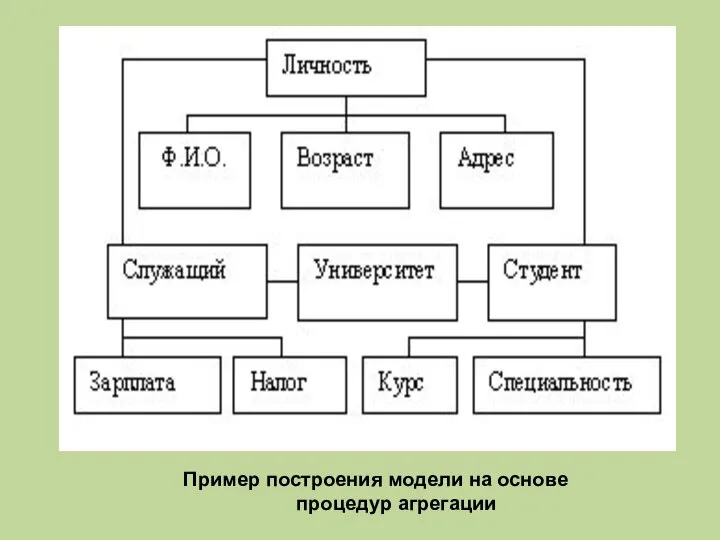
Пример построения модели на основе
процедур агрегации
Пример построения модели на основе
процедур агрегации

2. Классификация моделей данных в ГИС
2. Классификация моделей данных в ГИС

Все модели данных делятся на статические и динамические модели
К статическим относятся
Все модели данных делятся на статические и динамические модели
К статическим относятся

Классификация моделей по степени типизации
Сильно типизированные – это модели, в которых
Классификация моделей по степени типизации
Сильно типизированные – это модели, в которых

Представление моделей
Выделяют табличные и графовые формы представления моделей.
Табличная форма дает представление
Представление моделей
Выделяют табличные и графовые формы представления моделей.
Табличная форма дает представление

Графовая форма основана на построении модели в виде графической схемы, называемой
Графовая форма основана на построении модели в виде графической схемы, называемой

По форме отображения модели данных делятся на аналоговые и дискретные
Аналоговые
По форме отображения модели данных делятся на аналоговые и дискретные
Аналоговые

Дискретные модели строятся путем замены непрерывных функций набором дискретных значений аргументов
Дискретные модели строятся путем замены непрерывных функций набором дискретных значений аргументов
В ГИС РАЗЛИЧАЮТ
СПЕЦИАЛЬНЫЕ МОДЕЛИ
БАЗОВЫЕ МОДЕЛИ
В ГИС РАЗЛИЧАЮТ
СПЕЦИАЛЬНЫЕ МОДЕЛИ
БАЗОВЫЕ МОДЕЛИ

Базовые модели данных
Среди базовых моделей данных выделяют
Квадратомическое дерево
Иерархическая модель
Инфологическая модель
Сетевые модели
Модель
Базовые модели данных
Среди базовых моделей данных выделяют
Квадратомическое дерево
Иерархическая модель
Инфологическая модель
Сетевые модели
Модель
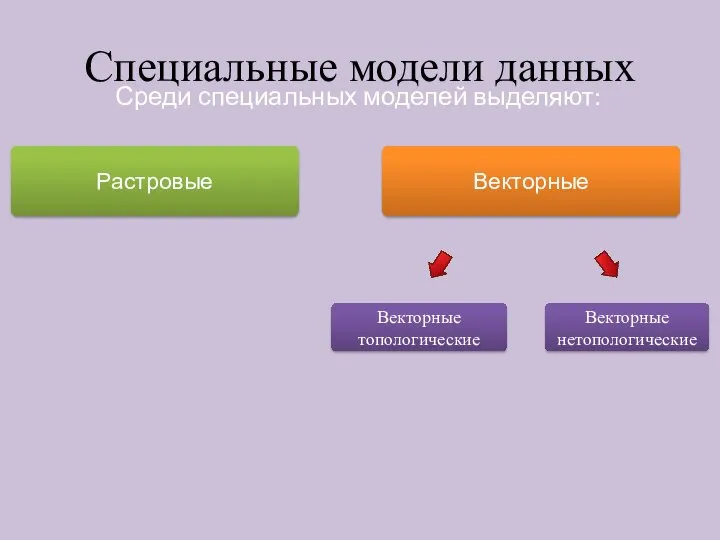
Специальные модели данных
Среди специальных моделей выделяют:
Растровые
Векторные
Векторные топологические
Векторные нетопологические
Специальные модели данных
Среди специальных моделей выделяют:
Растровые
Векторные
Векторные топологические
Векторные нетопологические

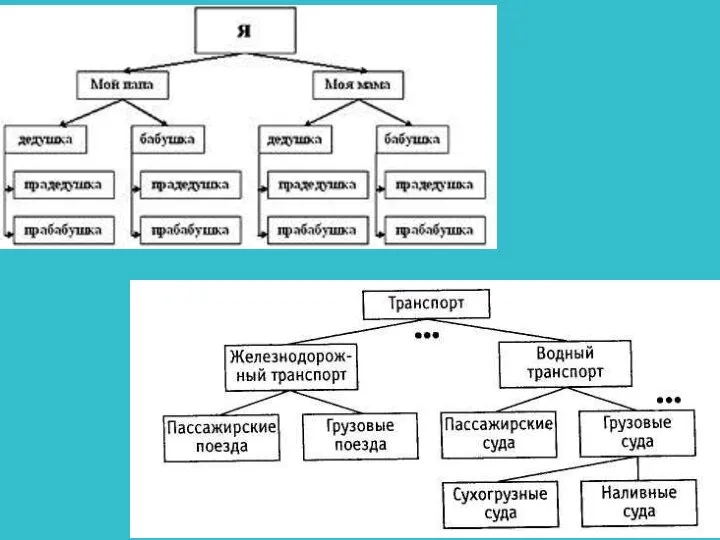
3. Иерархическая модель
Иерархическая модель относится к наиболее простым структурно определенным
3. Иерархическая модель
Иерархическая модель относится к наиболее простым структурно определенным

Иерархическая модель проектирования ГИС
Иерархическая модель проектирования ГИС

В иерархических моделях данных существует два внутренних ограничения:
все типы связей
В иерархических моделях данных существует два внутренних ограничения:
все типы связей

Недостатком иерархической модели является снижение времени доступа при большом числе уровней,
Недостатком иерархической модели является снижение времени доступа при большом числе уровней,

Данная модель имеет множество названий:
- Квадротомическая модель;
- Квадротомическое представление (данных);
Данная модель имеет множество названий: - Квадротомическая модель; - Квадротомическое представление (данных);

Это модель является один из способов представления пространственных объектов в виде
Это модель является один из способов представления пространственных объектов в виде

Квадратомическиое дерево – структура, используемая для накопления и хранения географической информации.
В
Квадратомическиое дерево – структура, используемая для накопления и хранения географической информации.
В

На рисунке показан фрагмент двухмерной области Qt, состоящей из 16 пикселей.
Каждый
На рисунке показан фрагмент двухмерной области Qt, состоящей из 16 пикселей. Каждый
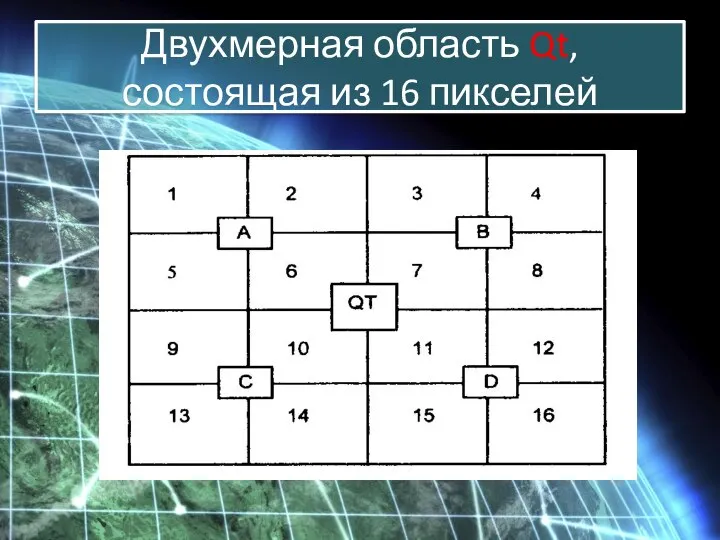
Двухмерная область Qt, состоящая из 16 пикселей
Двухмерная область Qt, состоящая из 16 пикселей
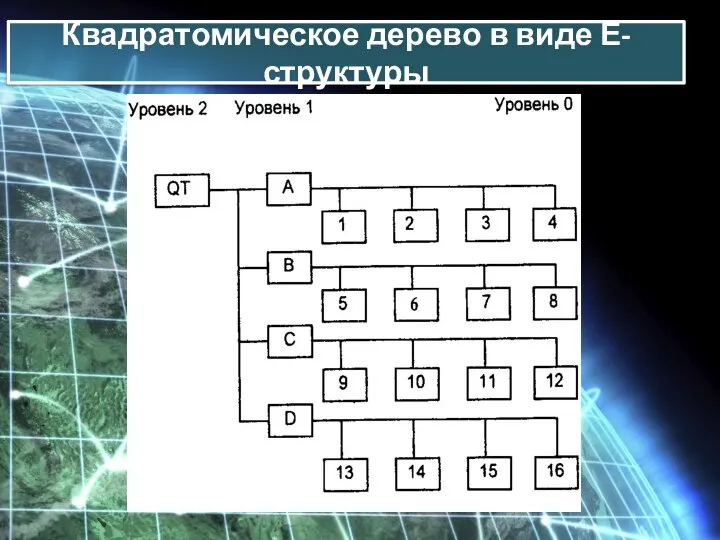
Квадратомическое дерево в виде Е-структуры
Квадратомическое дерево в виде Е-структуры

На этом слайде показано квадратомическое дерево, построенное по данным двухмерной области
На этом слайде показано квадратомическое дерево, построенное по данным двухмерной области

В модели списка можно пользоваться только одним индексным компонентом – номером
В модели списка можно пользоваться только одним индексным компонентом – номером

Модель дерева подобна модели таблицы при следующих отличиях.
Как и в
Модель дерева подобна модели таблицы при следующих отличиях. Как и в
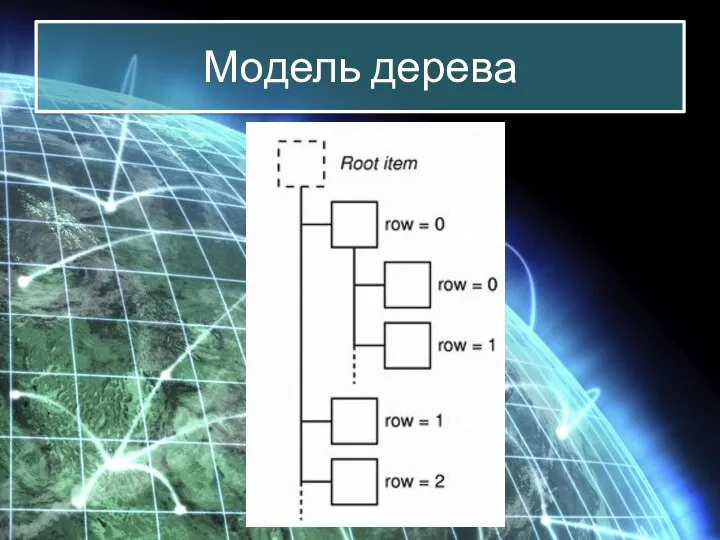
Модель дерева
Модель дерева

Модели, основанные на квадратомических деревьях, обеспечивают расчеты площадей, центроидные определения, распознавание
Модели, основанные на квадратомических деревьях, обеспечивают расчеты площадей, центроидные определения, распознавание
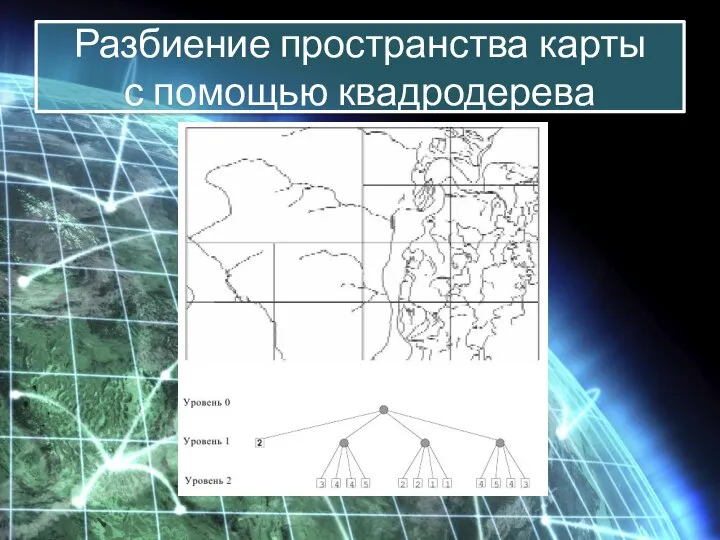
Разбиение пространства карты
с помощью квадродерева
Разбиение пространства карты
с помощью квадродерева
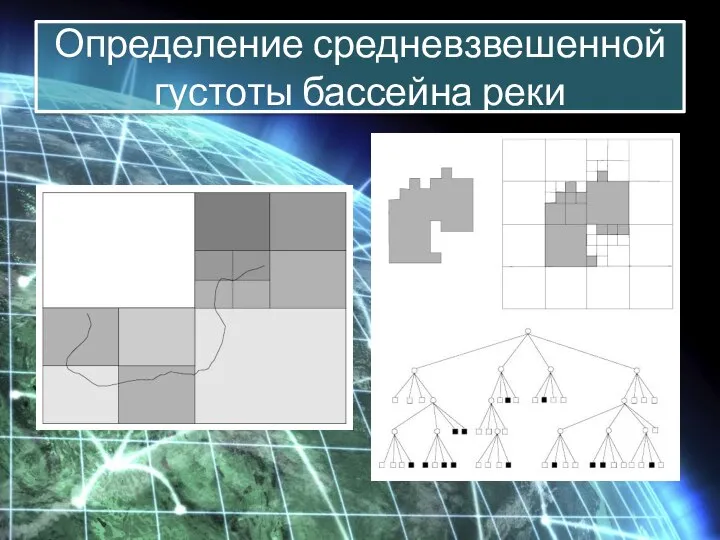
Определение средневзвешенной
густоты бассейна реки
Определение средневзвешенной
густоты бассейна реки
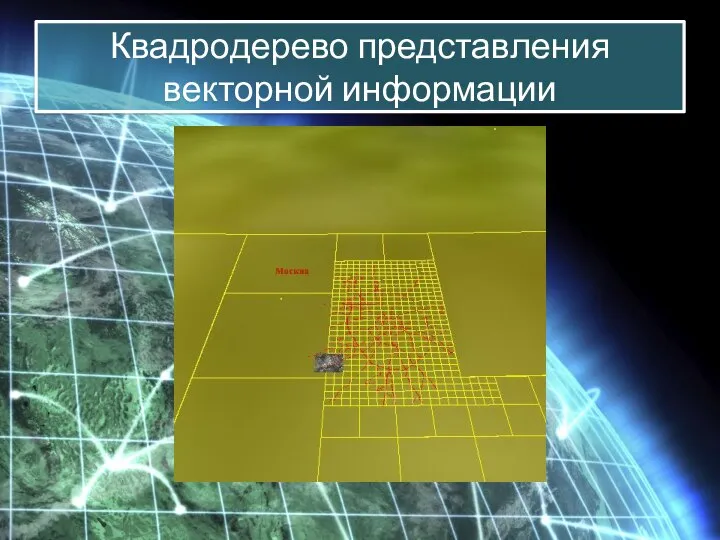
Квадродерево представления векторной информации
Квадродерево представления векторной информации

Примеры визуализации квадродеревьев
Визуализация карты Москвы по принципу квадродерева
Примеры визуализации квадродеревьев
Визуализация карты Москвы по принципу квадродерева

Пример матричного квадродерева
Пример матричного квадродерева

Реляционная модель данных – логическая модель данных. Представляет интерес как наиболее
Реляционная модель данных – логическая модель данных. Представляет интерес как наиболее

ЭДГАР КОДД
(1923-2003)
ЭДГАР КОДД
(1923-2003)

Реляционная модель данных представляет собой хранилище данных, организованных в виде двумерных
Реляционная модель данных представляет собой хранилище данных, организованных в виде двумерных

Основными понятиями реляционной модели являются:
атрибут
кортеж
отношение
Основными понятиями реляционной модели являются:
атрибут
кортеж
отношение

Атрибуты
Это самые простые элементы структуры таблицы. В таблице мы их
Атрибуты
Это самые простые элементы структуры таблицы. В таблице мы их

Атрибуты различаются по типам.
Наиболее известные из них:
числовой;
текстовой;
логический.
Есть и другие типы,
Атрибуты различаются по типам.
Наиболее известные из них:
числовой;
текстовой;
логический.
Есть и другие типы,

Например: в таблице-каталоге скважин могут быть следующие атрибуты:
Номер/индекс скважины ID;
Координаты
Например: в таблице-каталоге скважин могут быть следующие атрибуты:
Номер/индекс скважины ID;
Координаты
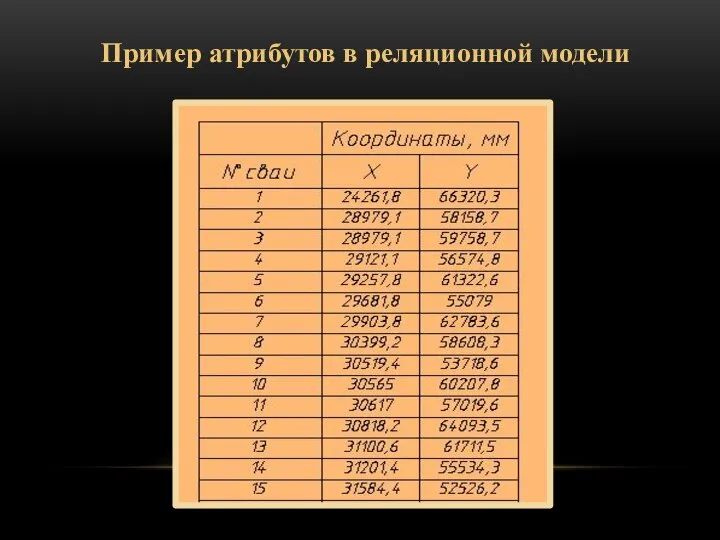
Пример атрибутов в реляционной модели
Пример атрибутов в реляционной модели

Кортежи
Это аналоги строк в таблице.
Каждый кортеж содержит несколько элементов по
Кортежи
Это аналоги строк в таблице.
Каждый кортеж содержит несколько элементов по
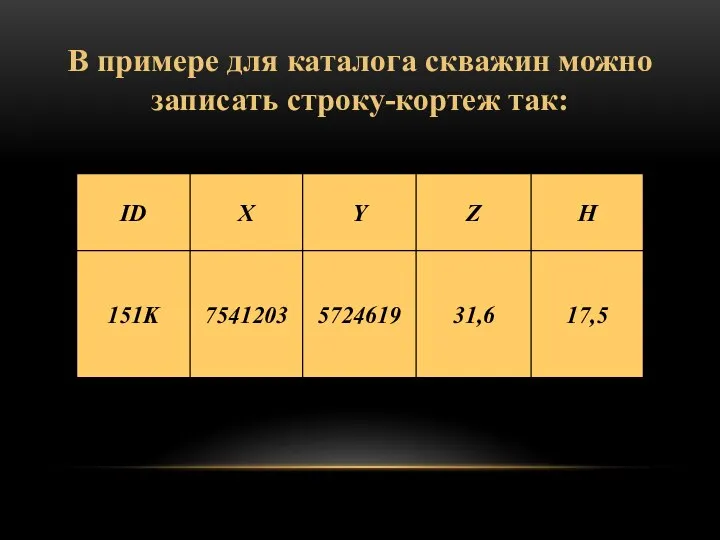
В примере для каталога скважин можно записать строку-кортеж так:
В примере для каталога скважин можно записать строку-кортеж так:

Основные типы данных в реляционной модели те же, что и в
Основные типы данных в реляционной модели те же, что и в

Однако любых математических типов будет недостаточно, чтобы построить целостную базу данных
Однако любых математических типов будет недостаточно, чтобы построить целостную базу данных

Домен это потенциально возможное множество значений. Domain в переводе означает «область»,
Домен это потенциально возможное множество значений. Domain в переводе означает «область»,

Первичный ключ (primary key)
Это очень важное понятие, можно сказать «ключевое».
Первичный ключ (primary key)
Это очень важное понятие, можно сказать «ключевое».
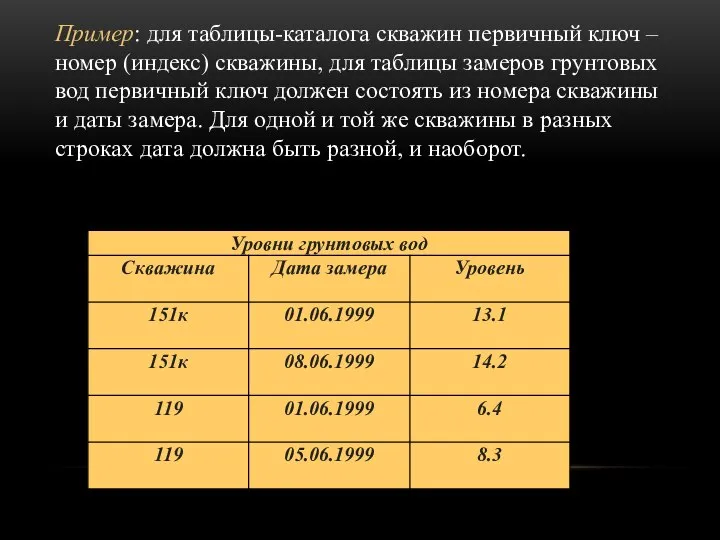
Пример: для таблицы-каталога скважин первичный ключ – номер (индекс) скважины, для
Пример: для таблицы-каталога скважин первичный ключ – номер (индекс) скважины, для

Внешний ключ (Foreign key)
Служит для связи таблиц. Это значения из одной
Внешний ключ (Foreign key)
Служит для связи таблиц. Это значения из одной
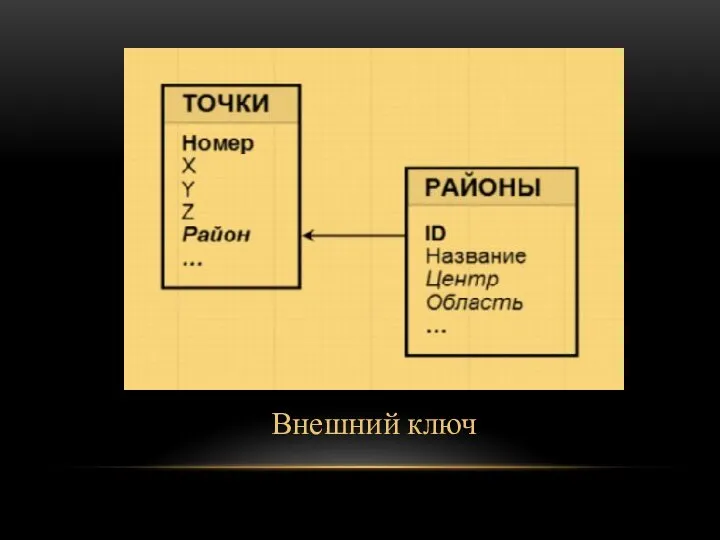
Внешний ключ
Внешний ключ

Внешний ключ должен ссылаться на первичный ключ другой таблицы. В своей
Внешний ключ должен ссылаться на первичный ключ другой таблицы. В своей
ОСНОВНЫЕ КОМПОНЕНТЫ РЕЛЯЦИОННЫХ МОДЕЛЕЙ ДАННЫХ ГИС
ОСНОВНЫЕ КОМПОНЕНТЫ РЕЛЯЦИОННЫХ МОДЕЛЕЙ ДАННЫХ ГИС
ОСНОВНЫЕ МОДЕЛИ РЕЛЯЦИОННЫХ ДАННЫХ ГИС
ОСНОВНЫЕ МОДЕЛИ РЕЛЯЦИОННЫХ ДАННЫХ ГИС

Выделяют три составные части реляционной модели данных:
структурную
манипуляционную
целостную
Выделяют три составные части реляционной модели данных:
структурную
манипуляционную
целостную

Структурная часть модели
Определяет, что единственной структурой данных является нормализованное парное
Структурная часть модели
Определяет, что единственной структурой данных является нормализованное парное

Манипуляционная часть модели
Определяет два фундаментальных механизма манипулирования данными – реляционная
Манипуляционная часть модели
Определяет два фундаментальных механизма манипулирования данными – реляционная

Целостная часть модели
определяет требования целостности сущностей и целостности ссылок.
Первое
Целостная часть модели
определяет требования целостности сущностей и целостности ссылок.
Первое

Недостатки реляционной модели
Недостатки реляционной модели
 Жизненный цикл информационных систем
Жизненный цикл информационных систем Выполнение запросов, создание и редактирование отчета. MS Access
Выполнение запросов, создание и редактирование отчета. MS Access Обработка текстовой информации в компьютере. 4 класс. Учитель информатики: Карпова О.А. МБОУ «Гимназия г.Болхова»
Обработка текстовой информации в компьютере. 4 класс. Учитель информатики: Карпова О.А. МБОУ «Гимназия г.Болхова»  Семинар 2. Знакомство с БД (студверсия)
Семинар 2. Знакомство с БД (студверсия) Этапы моделирования
Этапы моделирования Homework 11
Homework 11 Урок для 6 класса: «Отношения соподчинения, противоречия и противоположности» Подготовила учитель информатики МКОУ СОШ №7 с.В
Урок для 6 класса: «Отношения соподчинения, противоречия и противоположности» Подготовила учитель информатики МКОУ СОШ №7 с.В Профессия веб-дизайнер Профессия веб-дизайнера Профессия дизайнера - появилась уже давно. Понятие "дизайн" применимо к любом
Профессия веб-дизайнер Профессия веб-дизайнера Профессия дизайнера - появилась уже давно. Понятие "дизайн" применимо к любом Тема VBA
Тема VBA Информатика. Краткое введение
Информатика. Краткое введение Инфологическое моделирование баз данных
Инфологическое моделирование баз данных Система ecoPay
Система ecoPay Как монтировать видео и фотографии на телефоне
Как монтировать видео и фотографии на телефоне СИСТЕМЫ СЧИСЛЕНИЯ И АРИФМЕТИЧЕСКИЕ ОСНОВЫ РАБОТЫ ЭВМ МОУ СОШ №1 6Б Герасимов Сергей
СИСТЕМЫ СЧИСЛЕНИЯ И АРИФМЕТИЧЕСКИЕ ОСНОВЫ РАБОТЫ ЭВМ МОУ СОШ №1 6Б Герасимов Сергей Файловая система
Файловая система 1. (3.02.2010) Тема занятий: «Аппаратное обеспечение ПЭВМ» Архитектура ПК Монитор Клавиатура Принтеры Техника безопасности
1. (3.02.2010) Тема занятий: «Аппаратное обеспечение ПЭВМ» Архитектура ПК Монитор Клавиатура Принтеры Техника безопасности Реализация проекта Память объединяет нас
Реализация проекта Память объединяет нас Имитационное моделирование
Имитационное моделирование Графическое представление данных
Графическое представление данных Исследование задач о понижении уровня грунтовых вод под действием системы дренажей
Исследование задач о понижении уровня грунтовых вод под действием системы дренажей Автор: учитель информатики и ИКТ ГБОУ ЦО №1456 ЮЗОУО г.Москвы Кулешова Е.В.
Автор: учитель информатики и ИКТ ГБОУ ЦО №1456 ЮЗОУО г.Москвы Кулешова Е.В.  Инструкция для модераторов
Инструкция для модераторов Программный межсетевой экран
Программный межсетевой экран Презентация "MS EXCEL ОСНОВЫ РАБОТЫ" - скачать презентации по Информатике
Презентация "MS EXCEL ОСНОВЫ РАБОТЫ" - скачать презентации по Информатике Локальные компьютерные сети. Глобальная компьютерная сеть интернет
Локальные компьютерные сети. Глобальная компьютерная сеть интернет Система электропитания
Система электропитания  Понятия «Истина» и «Ложь»
Понятия «Истина» и «Ложь» Презентация Операторы ветвления
Презентация Операторы ветвления