- Деревья. Бинарные деревья

Содержание
- 2. Деревья T1,T2,…Tm называются поддеревьями данного корня. Строго говоря, приведенное определение относится к специальному случаю дерева, называемому
- 3. Число поддеревьев узла называют его степенью. Узел нулевой степени называют листом. Уровень узла в дереве определяется
- 4. Если в определения дерева имеет значение относительный порядок следования поддеревьев T1,T2,…Tm, то дерево называют упорядоченным. Лес
- 7. Когда говорят о деревьях, часто используют такие термины, как "отец", "сын", "брат", "предок", "потомок". Каждый узел
- 8. Бинарные деревья Бинарное дерево определяется как конечное множество узлов, которое или пусто, или состоит из корня
- 9. Отметим, что деревья на рисунке различны, так как в одном случае пусто левое поддерево, а в
- 10. Обход бинарного дерева Для работы с древовидными структурами имеется множество алгоритмов, и многие из них используют
- 11. Прямой обход. 1. Обработать корень 2. Обойти левое поддерево 3. Обойти правое поддерево Обратный обход. 1.
- 12. На рис. изображены все варианты обхода.
- 13. На рис. изображено бинарное дерево и порядок следования его узлов для различных методов обхода.
- 14. Пример рекурсивной функции, выполняющей обход дерева в прямом порядке. void DirectBypass(NODE *Root){ // Root – указатель
- 15. Идея реализации алгоритма с "ручным" ведения стека (это может потребоваться, если язык не допускает рекурсии) заключается
- 16. const int MAXSTACK=50; void InverseBypass(NODE *Root){ // Нерекурсивный обход бинарного дерева NODE *stack[MAXSTACK]; NODE *s; int
- 17. if(v==0){ // стек пуст return; } // взять узел из стека s=stack[--v]; Обработка(s); // переходим к
- 18. Рассмотрим две конкретные задачи, решаемые с помощью обхода дерева. Задача 1. Копирование бинарного дерева Для решения
- 19. Задача 2. Вычисление значения выражения, заданного деревом. В качестве примера рассмотрим выражение ((2+3)*(7-4))/3. Порядок вычисления выражения
- 20. Узел дерева в поле данных содержит либо число, либо символ операции. Если узел содержит число, то
- 21. Структура узла имеет вид: const int OPERATION=0; // признак: узел содержит операцию const int NUMBER=1; //
- 22. Приведенная ниже функция вычисляет значение выражения, заданного деревом. float TreeValue(UZEL *Root){ float Result; if(Root->Tag==NUMBER) return Root->Number;
- 23. Голова дерева. Дерево, как и линейный список, может иметь голову. В таких случаях, дерево, как правило,
- 24. Прошитые деревья В бинарном дереве, содержащем N узлов, на каждый узел, кроме корня указывает ровно одна
- 25. Прошитые деревья используют место, занимаемое пустыми связями для хранения указателей, упрощающих прохождение дерева. Эти дополнительные связи
- 26. Дерево может быть прошито для обхода в одном из порядков. Рассмотрим дерево, прошитое для обхода в
- 27. const int THREAD=0; const int MAINLINK=1; struct NODE{ ; NODE *Left, *Right; BYTE L,R; };
- 28. На рис. изображено прошитое дерево. Пунктиром изображены нити.
- 29. Преимущество прошитых деревьев заключается в том, что упрощаются алгоритмы обхода. Ниже приведена функция, возвращающая указатель на
- 30. При наличии алгоритма определения последователя отпадает необходимость в стеке (явном или порождаемом механизмом реализации рекурсии). Функция,
- 31. Другие представления бинарных деревьев Подходящий выбор представления дерева в первую очередь определяется видом операций, выполняемым над
- 32. struct NODE{ ; NODE *Right; bool HaveLeftSon; }; Хранится только правая связь. Левый сын узла, если
- 34. Представление деревьев общего вида Рассмотрим два варианта представления дерева общего вида. В первом варианте для хранения
- 35. От этого недостатка свободно представление, когда указатели на сыновей находятся в линейном списке. Такая списочная структура
- 36. Пример такого дерева
- 37. Представление деревьев общего вида бинарными деревьями Всякое дерево можно представить в виде бинарного дерева. При преобразовании
- 38. В дальнейшем деревья ещё будут рассматриваться в связи с их использованием для представления таблиц.
- 40. Скачать презентацию

Деревья T1,T2,…Tm называются поддеревьями данного корня.
Строго говоря, приведенное определение относится
Деревья T1,T2,…Tm называются поддеревьями данного корня.
Строго говоря, приведенное определение относится

Число поддеревьев узла называют его степенью. Узел нулевой степени называют листом.
Число поддеревьев узла называют его степенью. Узел нулевой степени называют листом.

Если в определения дерева имеет значение относительный порядок следования поддеревьев T1,T2,…Tm,
Если в определения дерева имеет значение относительный порядок следования поддеревьев T1,T2,…Tm,

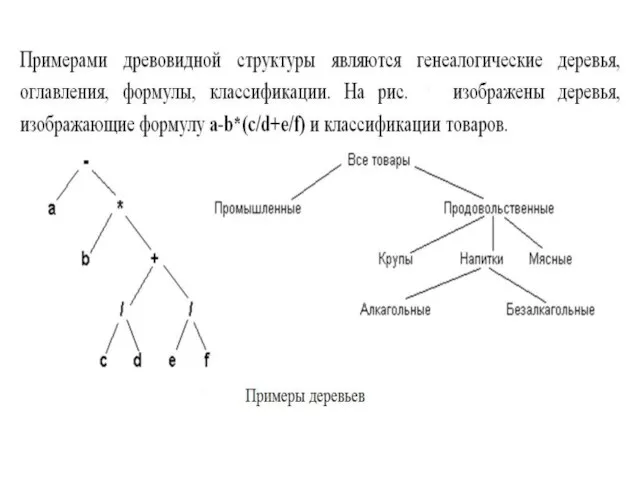

Когда говорят о деревьях, часто используют такие термины, как "отец", "сын",
Когда говорят о деревьях, часто используют такие термины, как "отец", "сын",

Бинарные деревья
Бинарное дерево определяется как конечное множество узлов, которое или пусто,
Бинарные деревья
Бинарное дерево определяется как конечное множество узлов, которое или пусто,
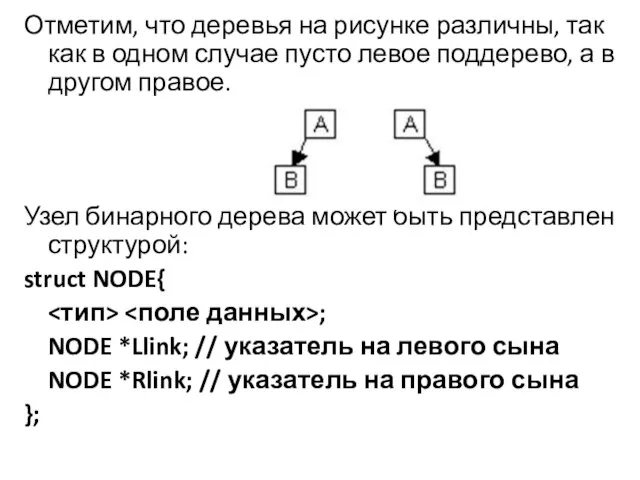
Отметим, что деревья на рисунке различны, так как в одном случае
Отметим, что деревья на рисунке различны, так как в одном случае

Обход бинарного дерева
Для работы с древовидными структурами имеется множество алгоритмов, и
Обход бинарного дерева
Для работы с древовидными структурами имеется множество алгоритмов, и

Прямой обход.
1. Обработать корень
2. Обойти левое поддерево
3. Обойти правое поддерево
Обратный обход.
1.
Прямой обход.
1. Обработать корень
2. Обойти левое поддерево
3. Обойти правое поддерево
Обратный обход.
1.
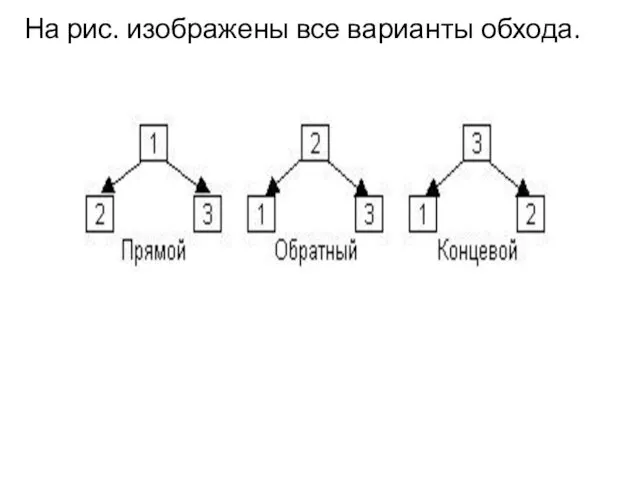
На рис. изображены все варианты обхода.
На рис. изображены все варианты обхода.
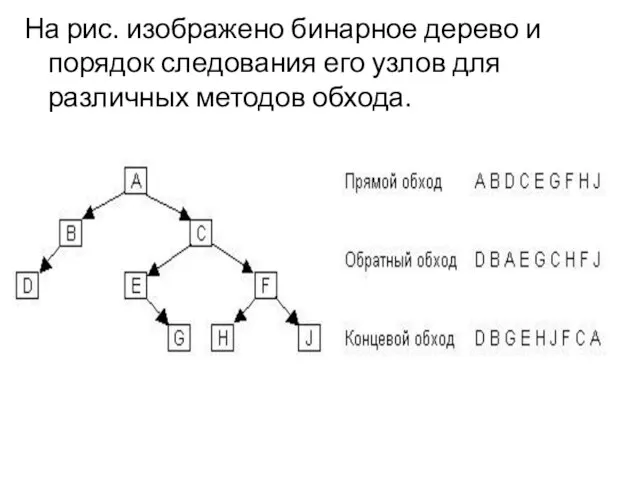
На рис. изображено бинарное дерево и порядок следования его узлов для
На рис. изображено бинарное дерево и порядок следования его узлов для

Пример рекурсивной функции, выполняющей обход дерева в прямом порядке.
void DirectBypass(NODE *Root){
//
Пример рекурсивной функции, выполняющей обход дерева в прямом порядке.
void DirectBypass(NODE *Root){
//

Идея реализации алгоритма с "ручным" ведения стека (это может потребоваться, если
Идея реализации алгоритма с "ручным" ведения стека (это может потребоваться, если

const int MAXSTACK=50;
void InverseBypass(NODE *Root){
// Нерекурсивный обход бинарного дерева
NODE *stack[MAXSTACK];
NODE *s;
int
const int MAXSTACK=50;
void InverseBypass(NODE *Root){
// Нерекурсивный обход бинарного дерева
NODE *stack[MAXSTACK];
NODE *s;
int

if(v==0){ // стек пуст
return;
}
// взять узел из
if(v==0){ // стек пуст
return;
}
// взять узел из

Рассмотрим две конкретные задачи, решаемые с помощью обхода дерева.
Задача 1. Копирование
Рассмотрим две конкретные задачи, решаемые с помощью обхода дерева.
Задача 1. Копирование
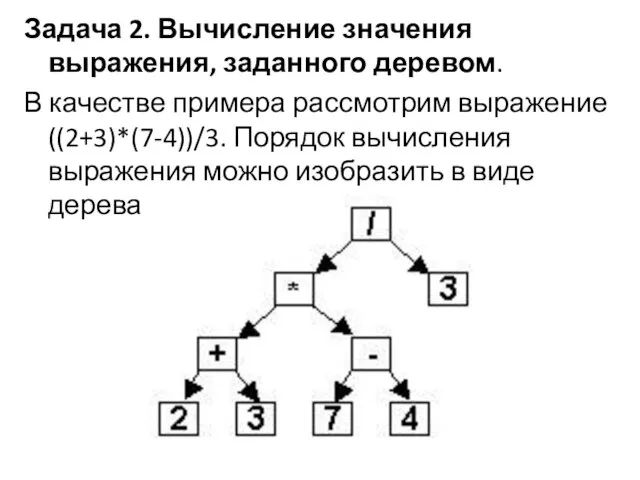
Задача 2. Вычисление значения выражения, заданного деревом.
В качестве примера рассмотрим
Задача 2. Вычисление значения выражения, заданного деревом.
В качестве примера рассмотрим

Узел дерева в поле данных содержит либо число, либо символ операции.
Узел дерева в поле данных содержит либо число, либо символ операции.

Структура узла имеет вид:
const int OPERATION=0; // признак: узел содержит операцию
const
Структура узла имеет вид:
const int OPERATION=0; // признак: узел содержит операцию
const

Приведенная ниже функция вычисляет значение выражения, заданного деревом.
float TreeValue(UZEL *Root){
float Result;
if(Root->Tag==NUMBER)
Приведенная ниже функция вычисляет значение выражения, заданного деревом.
float TreeValue(UZEL *Root){
float Result;
if(Root->Tag==NUMBER)

Голова дерева.
Дерево, как и линейный список, может иметь голову. В таких
Голова дерева.
Дерево, как и линейный список, может иметь голову. В таких

Прошитые деревья
В бинарном дереве, содержащем N узлов, на каждый узел, кроме
Прошитые деревья
В бинарном дереве, содержащем N узлов, на каждый узел, кроме

Прошитые деревья используют место, занимаемое пустыми связями для хранения указателей, упрощающих
Прошитые деревья используют место, занимаемое пустыми связями для хранения указателей, упрощающих

Дерево может быть прошито для обхода в одном из порядков.
Рассмотрим
Дерево может быть прошито для обхода в одном из порядков.
Рассмотрим

const int THREAD=0;
const int MAINLINK=1;
struct NODE{
<поля данных>;
NODE *Left, *Right;
BYTE L,R;
};
const int THREAD=0;
const int MAINLINK=1;
struct NODE{
<поля данных>;
NODE *Left, *Right;
BYTE L,R;
};

На рис. изображено прошитое дерево. Пунктиром изображены нити.
На рис. изображено прошитое дерево. Пунктиром изображены нити.

Преимущество прошитых деревьев заключается в том, что упрощаются алгоритмы обхода. Ниже
Преимущество прошитых деревьев заключается в том, что упрощаются алгоритмы обхода. Ниже

При наличии алгоритма определения последователя отпадает необходимость в стеке (явном или
При наличии алгоритма определения последователя отпадает необходимость в стеке (явном или

Другие представления бинарных деревьев
Подходящий выбор представления дерева в первую очередь определяется
Другие представления бинарных деревьев
Подходящий выбор представления дерева в первую очередь определяется

struct NODE{
<поля данных>;
NODE *Right;
bool HaveLeftSon;
};
Хранится только правая связь. Левый сын узла,
struct NODE{
<поля данных>;
NODE *Right;
bool HaveLeftSon;
};
Хранится только правая связь. Левый сын узла,


Представление деревьев общего вида
Рассмотрим два варианта представления дерева общего вида. В
Представление деревьев общего вида
Рассмотрим два варианта представления дерева общего вида. В

От этого недостатка свободно представление, когда указатели на сыновей находятся в
От этого недостатка свободно представление, когда указатели на сыновей находятся в
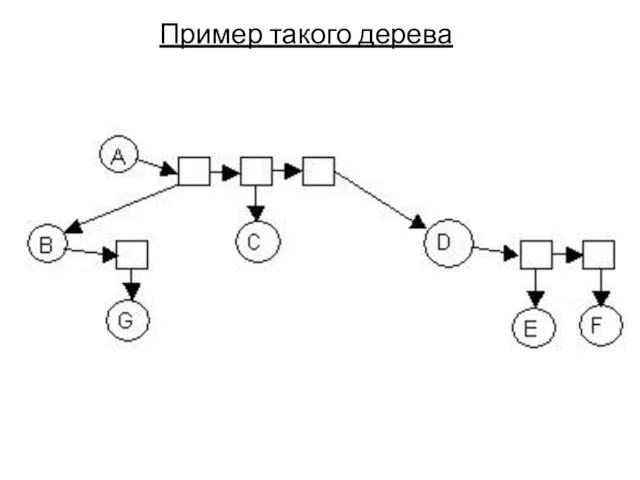
Пример такого дерева
Пример такого дерева
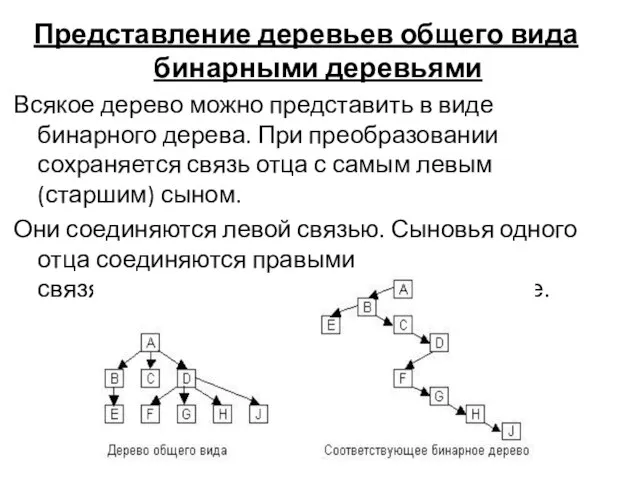
Представление деревьев общего вида бинарными деревьями
Всякое дерево можно представить в виде
Представление деревьев общего вида бинарными деревьями
Всякое дерево можно представить в виде

В дальнейшем деревья ещё будут рассматриваться в связи с их использованием
В дальнейшем деревья ещё будут рассматриваться в связи с их использованием
 Средство работы с музыкой
Средство работы с музыкой Лекция 11. Работа с сетями. Пакет java.net.
Лекция 11. Работа с сетями. Пакет java.net.  Разработка игры на платформе Unreal Engine 4
Разработка игры на платформе Unreal Engine 4 Конкурс Мой Университет
Конкурс Мой Университет Информационные ресурсы здравоохранения
Информационные ресурсы здравоохранения Основы логики
Основы логики Типы алгоритмов
Типы алгоритмов Математическая лингвистика
Математическая лингвистика Триггеры в презентации. Применение. Моя педагогическая инициатива
Триггеры в презентации. Применение. Моя педагогическая инициатива Требования. Основные понятия
Требования. Основные понятия Презентация "Действия с фрагментом текста" - скачать презентации по Информатике
Презентация "Действия с фрагментом текста" - скачать презентации по Информатике Конструирование из кубиков
Конструирование из кубиков Дистанционное обучение через Интернет. Обзор ресурсов. Анализ и классификация. ФЭУТ III – 5 Смирнова Елена Алпатова Татьяна
Дистанционное обучение через Интернет. Обзор ресурсов. Анализ и классификация. ФЭУТ III – 5 Смирнова Елена Алпатова Татьяна ГБОУ СПО «АМТ» преподаватель Струкова Елена Алексеевна
ГБОУ СПО «АМТ» преподаватель Струкова Елена Алексеевна Италия: время реформ и колониальных захватов
Италия: время реформ и колониальных захватов Файлы и файловые структуры
Файлы и файловые структуры Системы управления базами данных
Системы управления базами данных Использование интернет-ресурсов в продвижении имиджевых event-проектов
Использование интернет-ресурсов в продвижении имиджевых event-проектов Сетевые информационные технологии
Сетевые информационные технологии Информатика и ИКТ. Урок 28
Информатика и ИКТ. Урок 28 Информационные системы и базы данных
Информационные системы и базы данных Технические средства реализации информационных процессов. 1. Информатика как наука. Предмет информатики. 2. Краткий исторический
Технические средства реализации информационных процессов. 1. Информатика как наука. Предмет информатики. 2. Краткий исторический Системы счисления. Правила работы с числами в различных системах счисления
Системы счисления. Правила работы с числами в различных системах счисления Концепция программного продукта. Удаленная наладка программного обеспечения и работоспособности ПК
Концепция программного продукта. Удаленная наладка программного обеспечения и работоспособности ПК Процедуры и функции. Заголовок и тело процедур и функций, классификация параметров. Вызов процедур и функций
Процедуры и функции. Заголовок и тело процедур и функций, классификация параметров. Вызов процедур и функций Форматирование текста преподаватель информатики Савельева Людмила Николаевна
Форматирование текста преподаватель информатики Савельева Людмила Николаевна  Этапы развития вычислительной техники измен
Этапы развития вычислительной техники измен SQL. (Лекция 8)
SQL. (Лекция 8)