- Извлечение знаний из Web — Web Mining

Содержание
- 2. Содержание 4 ОПРЕДЕЛЕНИЕ WEB MINING и DATA MINING 1 2 3 КАТЕГОРИИ WEB MINING ЗАДАЧИ WEB
- 3. Поиск информации 3 Библиотеки и архивы Data mining WEB mining
- 4. Web Mining и Web Analytics В конце 90-х годов европейскими учеными были предложены термины Web Mining
- 5. Понятие Data Mining Data Mining - технология, предназначенная для поиска в больших объемах данных неочевидных, объективных
- 6. Этапы аналитики в соответствии со стандартом CRISP-DM Постановка задачи Достаточно ли данных для решения задачи Процесс
- 7. Задачи Data Mining Классификация Кластеризация Прогнозирование Ассоциация Обнаружение и анализ и отклонений Оценивание Анализ связей Визуализация
- 8. Data Mining и Web Mining Web Mining отличается от Data Mining масштабом, способом доступа и структурой
- 9. Определение Web Mining — это использование методов интеллектуального анализа данных для автоматического обнаружения веб-документов и услуг,
- 10. Web Mining — технология, использующая методы Data Mining для исследования и извлечения информации из Web-документов и
- 11. Поиск значимой информации Из предыдущей лекции ясно, что информационным поиск (information retrieval, IR) с помощью обычных
- 12. Поиск значимой информации Современный поиск выходит далеко за рамки индексирования. Самая жестокая конкурентная борьба среди фирм,
- 13. В бизнес-аналитике Web Mining решает следующие задачи: описание посетителей сайта (кластеризация, классификация); описание посетителей, которые совершают
- 14. Этапы Web Mining Входной этап (input stage) — получение «сырых» данных из источников (логи серверов, тексты
- 15. Направления Web Mining
- 16. Направления Web Mining
- 17. Категории Web Mining В области Web Mining выделяют следующие направления анализа: Извлечение Web-контента (Web Content Mining);
- 18. Направления Web Mining: Характеристика
- 19. Web Content Mining
- 20. Web Content Mining Web Content Mining (Извлечение веб-контента) — процесс извлечения знаний из контента документов или
- 21. Web Content Mining Web Content Mining (WCM) имеет общие черты с DM и Text Mining (TM):
- 22. Web Content Mining В WCM необходимо решать ряд специфических задач: извлечение структурированных данных из веб-страниц с
- 23. В WCM для каждого из трех типов данных (структурированные, неструктурированные и квазиструктурированные) используются собственные методы обработки,
- 24. Первые технологии data scraping применялись сначала на мэйнфреймах и позже на миникомпьютерах. Много лет спустя эта
- 25. Диапазон технологий, используемых для Web Scraping, чрезвычайно широк, но в ряде случаев невозможно обойтись без вмешательства
- 26. Создание упаковщиков — непростая задача, решаемая в человеко-машинном режиме, что требует больших трудозатрат на первичную разметку
- 27. Для работы со слабоструктурированными данными предложены специальные языки класса Web Data Extraction Language, такие как, например,
- 28. Использует методы TM в приложении к специфике WWW и призван облегчить восприятие пользователем больших массивов текстов.
- 29. Около дюжины компаний производят сегодня инструменты для WCM в виде традиционных загружаемых коммерческих и свободно-распространяемых программ
- 30. По мере наполнения World Wide Web растет необходимость в средствах для доступа к данным. И хотя
- 31. Web Structure Mining
- 32. Web Structure Mining Web Structure Mining (Извлечение веб-структур) — процесс обнаружения структурной информации в Интернете. Данное
- 33. Основное предназначение WSM для подхода Web Graph Mining состоит в обнаружении взаимосвязи между веб-страницами и формировании
- 34. К результатам WSM можно применить алгоритмы ранжирования PageRank или HITS (Hyperlink Induced Topic Search), позволяющие найти
- 35. Web Usage Mining
- 36. Web Usage Mining Паутина становится важным инструментом привлечения клиентов, что делает актуальной оценку качества работы сайта,
- 37. Web Usage Mining
- 38. Разнообразные пользовательские данные собираются на серверной и пользовательской сторонах, а также в прокси-серверах. Веб-сервер собирает запросы
- 39. На этапе обработки с помощью разнообразных эвристических алгоритмов выполняется последовательность операций над журналами с целью преобразования
- 40. Затем происходит идентификация пользователя (User Identification), в простейшем случае она осуществляется по IP или UID, но
- 41. Распознавание образов и анализ Это самый наукоемкий этап WUM, и чаще всего для анализа сессий и
- 42. Кластерный анализ служит для объединения объектов с общими признаками для сегментации посетителей сайтов и страниц по
- 43. Категории Web Mining (задачи)
- 44. Категории Web Mining (подклассы) Гиперссылки вне документа
- 45. Таблица 1 . Классификация задач Web Mining
- 46. ВЫВОДЫ: Web Mining включает в себя этапы: поиск ресурсов, извлечение информации, обобщение и анализ; Различают следующие
- 47. Web SCRAPING
- 48. Web-scrapping Веб-скрейпинг*) тесно связан с понятиями веб-индексация (web indexing) и веб-сканер (web crawler). Компонент веб-скрейпер использует
- 49. Классификация способов извлечения информации из WEB-источников
- 50. Классификация способов извлечения информации из WEB-источников
- 51. Web-scrapping
- 52. Web-scrapping (шаги) *(также называют Web harvesting или Web data extraction) Connect : Соединение с удаленным сайтом
- 53. Задачи Web-scrapping Извлеченные с помощью веб-скрейпинга данные могут использоваться для выполнения следующих задач: онлайн сравнение цен;
- 54. Инструмены Web-scrapping
- 55. Существующие веб-скрейпинг компоненты работают по месту назначения, узконаправленно, зачастую только относительно того веб-сайта для которого были
- 56. Инструменты Web-scrapping На данный момент имеется несколько решений для веб-скрейпинга. Некоторые из них преобразуют формат HTML
- 57. Инструменты Web-scrapping Имеется еще два инструмента с открытым исходным кодом для веб-скрейпинга: pjscrape для JavaScript и
- 58. Классификация методов [8]
- 59. Manual | Supervised | Semi-supervised | Un-supervised Manual Классификация методов [8]
- 60. Manual | Supervised | Semi-supervised | Un-supervised Supervised Labeled Web Pages Классификация методов [8]
- 61. Manual | Supervised | Semi-supervised | Un-supervised Semi-supervised Классификация методов [8]
- 62. Manual | Supervised | Semi-supervised | Un-supervised Unsupervised Классификация методов [8]
- 63. Существующие подходы
- 64. Задание 2: Web-scrapping Используя любой из приведенных либо найденных вами способов извлечения информации с web страниц,
- 65. Группа «Manual»: Инструменты http://web-harvest.sourceforge.net/
- 66. WebHarvest: Easy Web Scraping from Java Ах, вот ты какой, рукописный wrapper …
- 67. Manual. Инструменты http://web-harvest.sourceforge.net/ http://scrapy.org/
- 68. Группы «Supervised» и «Semi-supervised» Инструменты http://www.visualwebripper.com/ http://www.lixto.com/ http://www.denodo.com http://digitalcommons.wayne.edu/cgi/viewcontent.cgi?article=1192&context=oa_dissertations Ahmed, Emdad, "Post Processing Wrapper Generated Tables
- 69. Литература Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И.
- 71. Скачать презентацию
Содержание
4
ОПРЕДЕЛЕНИЕ WEB MINING и DATA MINING
1
2
3
КАТЕГОРИИ WEB MINING
ЗАДАЧИ WEB MINING
ЭТАПЫ WEB
Содержание
4
ОПРЕДЕЛЕНИЕ WEB MINING и DATA MINING
1
2
3
КАТЕГОРИИ WEB MINING
ЗАДАЧИ WEB MINING
ЭТАПЫ WEB

Поиск информации
3
Библиотеки и архивы
Data mining
WEB mining
Поиск информации
3
Библиотеки и архивы
Data mining
WEB mining

Web Mining и Web Analytics
В конце 90-х годов европейскими учеными были
Web Mining и Web Analytics
В конце 90-х годов европейскими учеными были

Понятие Data Mining
Data Mining - технология, предназначенная для поиска в больших
Понятие Data Mining
Data Mining - технология, предназначенная для поиска в больших

Этапы аналитики в соответствии со стандартом CRISP-DM
Постановка задачи
Достаточно ли данных для
Этапы аналитики в соответствии со стандартом CRISP-DM
Постановка задачи
Достаточно ли данных для

Задачи Data Mining
Классификация
Кластеризация
Прогнозирование
Ассоциация
Обнаружение и анализ и отклонений
Оценивание
Анализ связей
Визуализация
Подведение итогов
Задачи Data Mining
Классификация
Кластеризация
Прогнозирование
Ассоциация
Обнаружение и анализ и отклонений
Оценивание
Анализ связей
Визуализация
Подведение итогов

Data Mining и Web Mining
Web Mining отличается от Data Mining
Data Mining и Web Mining
Web Mining отличается от Data Mining

Определение
Web Mining — это использование методов интеллектуального анализа данных для автоматического
Определение
Web Mining — это использование методов интеллектуального анализа данных для автоматического

Web Mining — технология, использующая методы Data Mining для исследования и
Web Mining — технология, использующая методы Data Mining для исследования и

Поиск значимой информации
Из предыдущей лекции ясно, что информационным поиск (information retrieval,
Поиск значимой информации
Из предыдущей лекции ясно, что информационным поиск (information retrieval,

Поиск значимой информации
Современный поиск выходит далеко за рамки индексирования. Самая жестокая
Поиск значимой информации
Современный поиск выходит далеко за рамки индексирования. Самая жестокая

В бизнес-аналитике Web Mining решает следующие задачи:
описание посетителей сайта (кластеризация, классификация);
описание
В бизнес-аналитике Web Mining решает следующие задачи:
описание посетителей сайта (кластеризация, классификация);
описание

Этапы Web Mining
Входной этап (input stage) — получение «сырых» данных из
Этапы Web Mining
Входной этап (input stage) — получение «сырых» данных из

Направления Web Mining
Направления Web Mining

Направления Web Mining
Направления Web Mining

Категории Web Mining
В области Web Mining выделяют следующие направления анализа:
Извлечение Web-контента
Категории Web Mining
В области Web Mining выделяют следующие направления анализа:
Извлечение Web-контента

Направления Web Mining: Характеристика
Направления Web Mining: Характеристика

Web Content Mining
Web Content Mining

Web Content Mining
Web Content Mining (Извлечение веб-контента) — процесс извлечения знаний
Web Content Mining
Web Content Mining (Извлечение веб-контента) — процесс извлечения знаний

Web Content Mining
Web Content Mining (WCM) имеет общие черты с DM и
Web Content Mining
Web Content Mining (WCM) имеет общие черты с DM и

Web Content Mining
В WCM необходимо решать ряд специфических задач:
извлечение структурированных
Web Content Mining
В WCM необходимо решать ряд специфических задач:
извлечение структурированных

В WCM для каждого из трех типов данных (структурированные, неструктурированные и
В WCM для каждого из трех типов данных (структурированные, неструктурированные и

Первые технологии data scraping применялись сначала на мэйнфреймах и позже на
Первые технологии data scraping применялись сначала на мэйнфреймах и позже на

Диапазон технологий, используемых для Web Scraping, чрезвычайно широк, но в ряде случаев
Диапазон технологий, используемых для Web Scraping, чрезвычайно широк, но в ряде случаев

Создание упаковщиков — непростая задача, решаемая в человеко-машинном режиме, что требует
Создание упаковщиков — непростая задача, решаемая в человеко-машинном режиме, что требует

Для работы со слабоструктурированными данными предложены специальные языки класса Web Data
Для работы со слабоструктурированными данными предложены специальные языки класса Web Data

Использует методы TM в приложении к специфике WWW и призван облегчить
Использует методы TM в приложении к специфике WWW и призван облегчить

Около дюжины компаний производят сегодня инструменты для WCM в виде традиционных
Около дюжины компаний производят сегодня инструменты для WCM в виде традиционных

По мере наполнения World Wide Web растет необходимость в средствах для
По мере наполнения World Wide Web растет необходимость в средствах для

Web Structure Mining
Web Structure Mining

Web Structure Mining
Web Structure Mining (Извлечение веб-структур) — процесс обнаружения структурной
Web Structure Mining
Web Structure Mining (Извлечение веб-структур) — процесс обнаружения структурной

Основное предназначение WSM для подхода Web Graph Mining состоит в обнаружении взаимосвязи
Основное предназначение WSM для подхода Web Graph Mining состоит в обнаружении взаимосвязи

К результатам WSM можно применить алгоритмы ранжирования PageRank или HITS (Hyperlink
К результатам WSM можно применить алгоритмы ранжирования PageRank или HITS (Hyperlink

Web Usage Mining
Web Usage Mining

Web Usage Mining
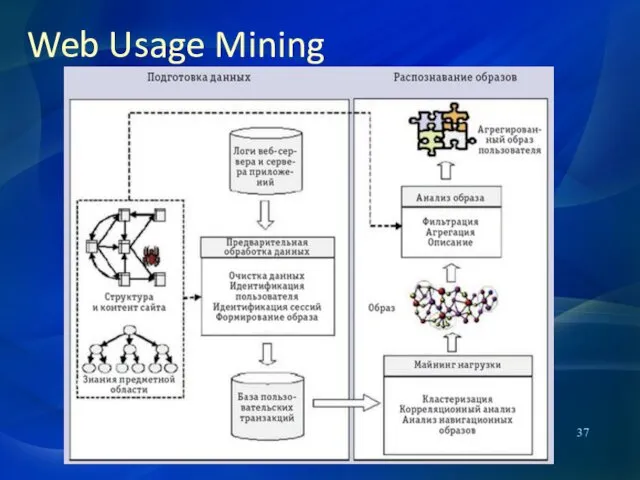
Паутина становится важным инструментом привлечения клиентов, что делает актуальной
Web Usage Mining
Паутина становится важным инструментом привлечения клиентов, что делает актуальной
Web Usage Mining
Web Usage Mining

Разнообразные пользовательские данные собираются на серверной и пользовательской сторонах, а также
Разнообразные пользовательские данные собираются на серверной и пользовательской сторонах, а также

На этапе обработки с помощью разнообразных эвристических алгоритмов выполняется последовательность операций
На этапе обработки с помощью разнообразных эвристических алгоритмов выполняется последовательность операций

Затем происходит идентификация пользователя (User Identification), в простейшем случае она осуществляется
Затем происходит идентификация пользователя (User Identification), в простейшем случае она осуществляется

Распознавание образов и анализ
Это самый наукоемкий этап WUM, и чаще всего
Распознавание образов и анализ
Это самый наукоемкий этап WUM, и чаще всего

Кластерный анализ служит для объединения объектов с общими признаками для сегментации
Кластерный анализ служит для объединения объектов с общими признаками для сегментации

Категории Web Mining (задачи)
Категории Web Mining (задачи)

Категории Web Mining (подклассы)
Гиперссылки вне документа
Категории Web Mining (подклассы)
Гиперссылки вне документа
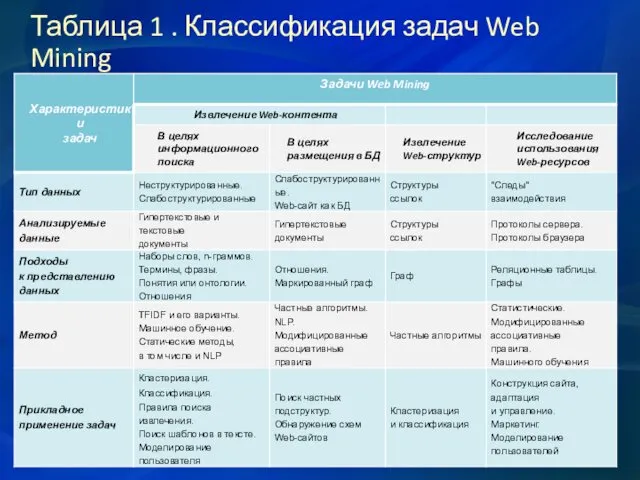
Таблица 1 . Классификация задач Web Mining
Таблица 1 . Классификация задач Web Mining

ВЫВОДЫ:
Web Mining включает в себя этапы: поиск ресурсов, извлечение информации, обобщение
ВЫВОДЫ:
Web Mining включает в себя этапы: поиск ресурсов, извлечение информации, обобщение

Web SCRAPING
Web SCRAPING

Web-scrapping
Веб-скрейпинг*) тесно связан с понятиями веб-индексация (web indexing) и веб-сканер (web
Web-scrapping
Веб-скрейпинг*) тесно связан с понятиями веб-индексация (web indexing) и веб-сканер (web
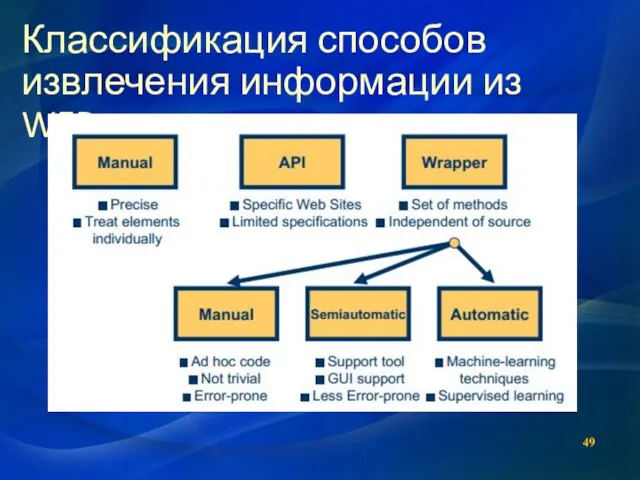
Классификация способов извлечения информации из WEB-источников
Классификация способов извлечения информации из WEB-источников
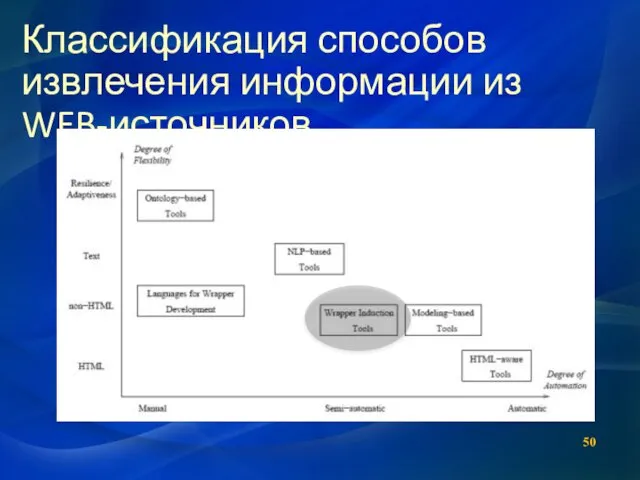
Классификация способов извлечения информации из WEB-источников
Классификация способов извлечения информации из WEB-источников

Web-scrapping
Web-scrapping
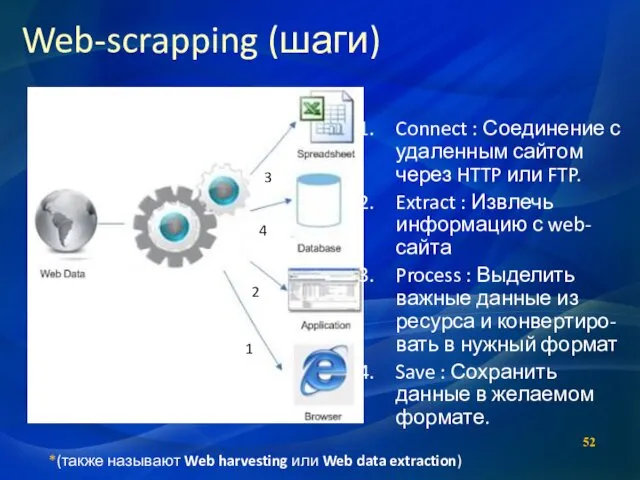
Web-scrapping (шаги)
*(также называют Web harvesting или Web data extraction)
Connect : Соединение
Web-scrapping (шаги)
*(также называют Web harvesting или Web data extraction)
Connect : Соединение

Задачи Web-scrapping
Извлеченные с помощью веб-скрейпинга данные могут использоваться для выполнения следующих
Задачи Web-scrapping
Извлеченные с помощью веб-скрейпинга данные могут использоваться для выполнения следующих

Инструмены Web-scrapping
Инструмены Web-scrapping

Существующие веб-скрейпинг компоненты работают по месту назначения, узконаправленно, зачастую только относительно
Существующие веб-скрейпинг компоненты работают по месту назначения, узконаправленно, зачастую только относительно

Инструменты Web-scrapping
На данный момент имеется несколько решений для веб-скрейпинга.
Некоторые из
Инструменты Web-scrapping
На данный момент имеется несколько решений для веб-скрейпинга.
Некоторые из

Инструменты Web-scrapping
Имеется еще два инструмента с открытым исходным кодом для веб-скрейпинга:
Инструменты Web-scrapping
Имеется еще два инструмента с открытым исходным кодом для веб-скрейпинга:
![Классификация методов [8]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/481584/slide-57.jpg)
Классификация методов [8]
Классификация методов [8]
![Manual | Supervised | Semi-supervised | Un-supervised Manual Классификация методов [8]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/481584/slide-58.jpg)
Manual | Supervised | Semi-supervised | Un-supervised
Manual
Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervised
Manual
Классификация методов [8]
![Manual | Supervised | Semi-supervised | Un-supervised Supervised Labeled Web Pages Классификация методов [8]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/481584/slide-59.jpg)
Manual | Supervised | Semi-supervised | Un-supervised
Supervised
Labeled Web Pages
Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervised
Supervised
Labeled Web Pages
Классификация методов [8]
![Manual | Supervised | Semi-supervised | Un-supervised Semi-supervised Классификация методов [8]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/481584/slide-60.jpg)
Manual | Supervised | Semi-supervised | Un-supervised
Semi-supervised
Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervised
Semi-supervised
Классификация методов [8]
![Manual | Supervised | Semi-supervised | Un-supervised Unsupervised Классификация методов [8]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/481584/slide-61.jpg)
Manual | Supervised | Semi-supervised | Un-supervised
Unsupervised
Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervised
Unsupervised
Классификация методов [8]

Существующие подходы
Существующие подходы

Задание 2: Web-scrapping
Используя любой из приведенных либо найденных вами способов извлечения
Задание 2: Web-scrapping
Используя любой из приведенных либо найденных вами способов извлечения

Группа «Manual»: Инструменты
http://web-harvest.sourceforge.net/
Группа «Manual»: Инструменты
http://web-harvest.sourceforge.net/

WebHarvest: Easy Web Scraping from Java
Ах, вот ты какой,
рукописный wrapper
WebHarvest: Easy Web Scraping from Java
Ах, вот ты какой,
рукописный wrapper

Manual. Инструменты
http://web-harvest.sourceforge.net/
http://scrapy.org/
Manual. Инструменты
http://web-harvest.sourceforge.net/
http://scrapy.org/

Группы «Supervised» и «Semi-supervised» Инструменты
http://www.visualwebripper.com/
http://www.lixto.com/
http://www.denodo.com
http://digitalcommons.wayne.edu/cgi/viewcontent.cgi?article=1192&context=oa_dissertations
Ahmed, Emdad, "Post Processing Wrapper Generated Tables
Группы «Supervised» и «Semi-supervised» Инструменты
http://www.visualwebripper.com/
http://www.lixto.com/
http://www.denodo.com
http://digitalcommons.wayne.edu/cgi/viewcontent.cgi?article=1192&context=oa_dissertations
Ahmed, Emdad, "Post Processing Wrapper Generated Tables

Литература
Анализ данных и процессов: учеб. пособие / А. А. Барсегян,
Литература
Анализ данных и процессов: учеб. пособие / А. А. Барсегян,
 Многокоординатная обработка
Многокоординатная обработка Электронные таблицы MS Excel
Электронные таблицы MS Excel Эволюционирующая операционная система андроид
Эволюционирующая операционная система андроид The Internet of Things
The Internet of Things Прикладная информатика. (Лекция 1)
Прикладная информатика. (Лекция 1) Стандартный контейнер Vector.Стандартный контейнер Deque
Стандартный контейнер Vector.Стандартный контейнер Deque Презентация "СОЗДАНИЕ КРОССВОРДОВ В MS WORD" - скачать презентации по Информатике
Презентация "СОЗДАНИЕ КРОССВОРДОВ В MS WORD" - скачать презентации по Информатике Сети ЭВМ и средства коммуникации
Сети ЭВМ и средства коммуникации Сетевые черви. Работу выполнила: Ученица 11 класса Иванова Ксения.
Сетевые черви. Работу выполнила: Ученица 11 класса Иванова Ксения. Компьютерные вирусы и антивирусы
Компьютерные вирусы и антивирусы Методы трансляции. Общая модель компилятора. Фазы компиляции
Методы трансляции. Общая модель компилятора. Фазы компиляции Виды долговременной памяти. 7 класс
Виды долговременной памяти. 7 класс Репортаж – это жанр информационной журналистики
Репортаж – это жанр информационной журналистики Основы логики
Основы логики  Интеллектуальные информационные системы Лекция 1
Интеллектуальные информационные системы Лекция 1  Жизненный цикл заказа. Автоматизация обработки заказа (1С:Битрикс)
Жизненный цикл заказа. Автоматизация обработки заказа (1С:Битрикс) Пять лучших фильма 2015 года
Пять лучших фильма 2015 года Индивидуальные рамки через Интернет
Индивидуальные рамки через Интернет Начала информационной безопасности Попов Николай Александрович кандидат экономических наук, доцент по кафедре безопасности ин
Начала информационной безопасности Попов Николай Александрович кандидат экономических наук, доцент по кафедре безопасности ин Калькулятор. История и использование
Калькулятор. История и использование Лекция 1. Понятие и структура информационных систем управления предприятием. Архитектура, эволюция и классификация систем
Лекция 1. Понятие и структура информационных систем управления предприятием. Архитектура, эволюция и классификация систем Отношения объектов. (5-7 класс)
Отношения объектов. (5-7 класс) Технические средства диспетчерского и технологического управления
Технические средства диспетчерского и технологического управления Советы по оформлению презентации
Советы по оформлению презентации Бизнес в интернете. Профессиональное обучение для новичков и опытных предпринимателей
Бизнес в интернете. Профессиональное обучение для новичков и опытных предпринимателей Идеальный электронный курс: от мечты к реальности
Идеальный электронный курс: от мечты к реальности Контроллер клавиатуры
Контроллер клавиатуры Блокировки и транзакции в Caché
Блокировки и транзакции в Caché