- Методы машинного обучения

Содержание
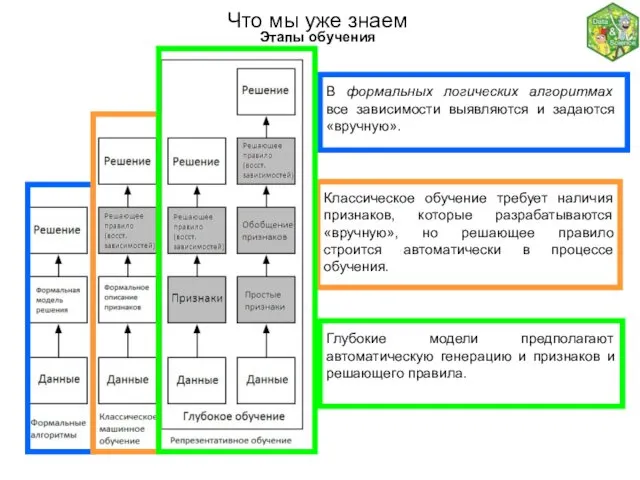
- 2. Что мы уже знаем Этапы обучения В формальных логических алгоритмах все зависимости выявляются и задаются «вручную».
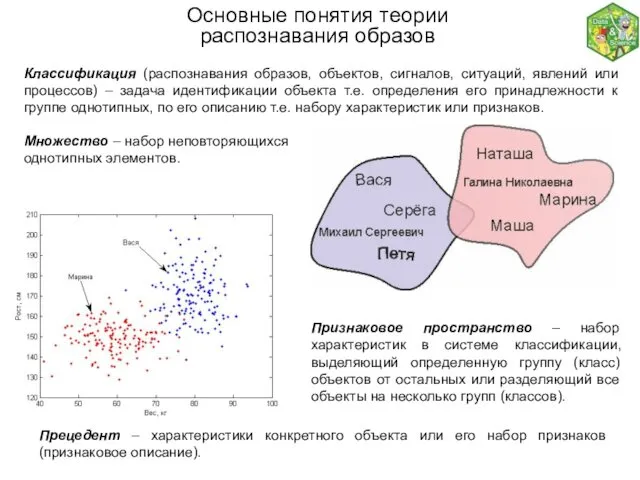
- 3. Основные понятия теории распознавания образов Классификация (распознавания образов, объектов, сигналов, ситуаций, явлений или процессов) – задача
- 4. Решающим правилом (классификатором) называется методика или правило отнесения объекта к какому-либо классу. Обучение – определение по
- 5. Этапы решения задачи распознавания образов: 1 Выбор свойств, характеристик, признаков класса объектов, наилучшим образом отличающих их
- 6. 4 Выбор функционала качества (функции потерь) функционирования алгоритма. Определяется решаемой задачей и используемым алгоритмом. Часто используется
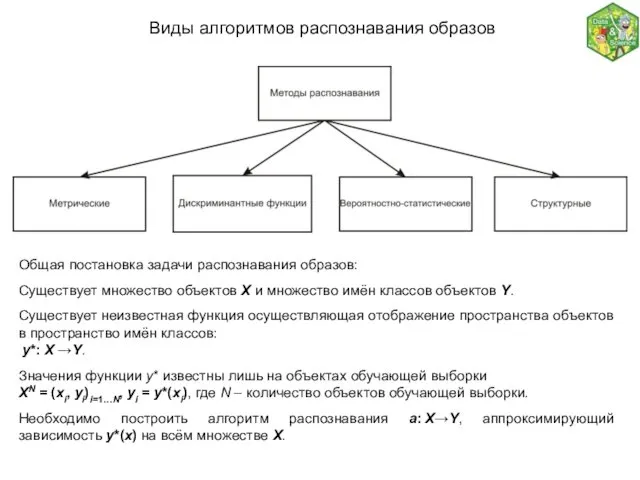
- 7. Виды алгоритмов распознавания образов Общая постановка задачи распознавания образов: Существует множество объектов X и множество имён
- 8. Метрические методы распознавания образов Гипотеза компактности – «близкие объекты, как правило, лежат в одном классе». Формализованным
- 9. Евклидово расстояние: Расстояние Махаланобиса: Взвешенная норма: - вектор признаков объекта xi ; - вектор признаков объекта
- 10. Простейший метрический алгоритм Для каждого объекта x можно вычислить расстояния до всех имеющихся в обучающей выборке
- 11. Преимущества: прост в реализации; решение легко интерпретируется. Недостатки: необходимость хранения всей обучающей выборки; - чувствительность к
- 12. Алгоритм k-ближайших соседей Алгоритм относит объект x к тому классу, к которому относится большее число среди
- 13. Алгоритм k-ближайших соседей k=1 k=10 k=5 k=3
- 14. Алгоритм взвешенных k-ближайших соседей Устранение неоднозначных решений возможно путём введения весов для каждого из обучающих объектов,
- 15. Метод парзеновского окна Веса можно задавать в зависимости не от номера соседа, а от значения расстояния
- 16. Метод парзеновского окна h=1 h=10 h=5 h=3
- 18. Скачать презентацию
Что мы уже знаем
Этапы обучения
В формальных логических алгоритмах все зависимости выявляются
Что мы уже знаем
Этапы обучения
В формальных логических алгоритмах все зависимости выявляются
Основные понятия теории распознавания образов
Классификация (распознавания образов, объектов, сигналов, ситуаций, явлений
Основные понятия теории распознавания образов
Классификация (распознавания образов, объектов, сигналов, ситуаций, явлений
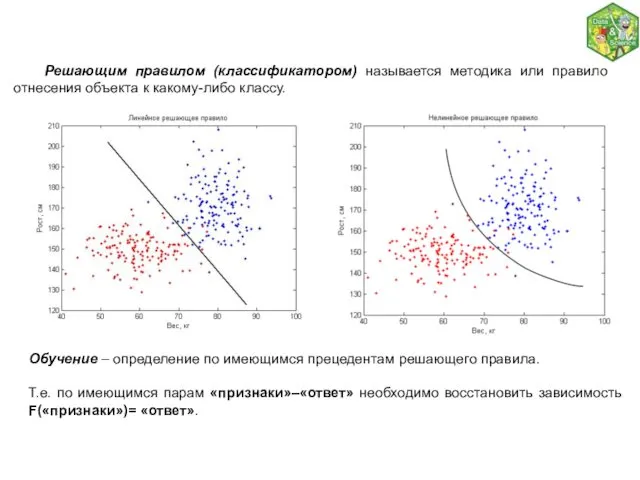
Решающим правилом (классификатором) называется методика или правило отнесения объекта к
Решающим правилом (классификатором) называется методика или правило отнесения объекта к

Этапы решения задачи распознавания образов:
1 Выбор свойств, характеристик, признаков класса
Этапы решения задачи распознавания образов:
1 Выбор свойств, характеристик, признаков класса

4 Выбор функционала качества (функции потерь) функционирования алгоритма. Определяется решаемой задачей
4 Выбор функционала качества (функции потерь) функционирования алгоритма. Определяется решаемой задачей
Виды алгоритмов распознавания образов
Общая постановка задачи распознавания образов:
Существует множество объектов X
Виды алгоритмов распознавания образов
Общая постановка задачи распознавания образов:
Существует множество объектов X
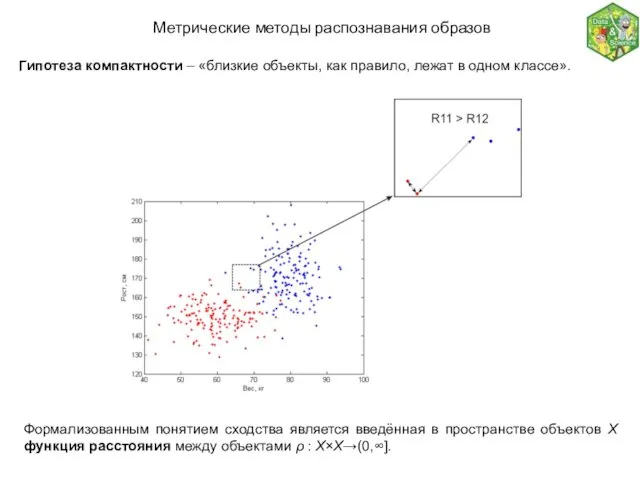
Метрические методы распознавания образов
Гипотеза компактности – «близкие объекты, как правило, лежат
Метрические методы распознавания образов
Гипотеза компактности – «близкие объекты, как правило, лежат

Евклидово расстояние:
Расстояние Махаланобиса:
Взвешенная норма:
- вектор признаков объекта xi ;
- вектор признаков
Евклидово расстояние:
Расстояние Махаланобиса:
Взвешенная норма:
- вектор признаков объекта xi ;
- вектор признаков

Простейший метрический алгоритм
Для каждого объекта x можно вычислить расстояния до
Простейший метрический алгоритм
Для каждого объекта x можно вычислить расстояния до
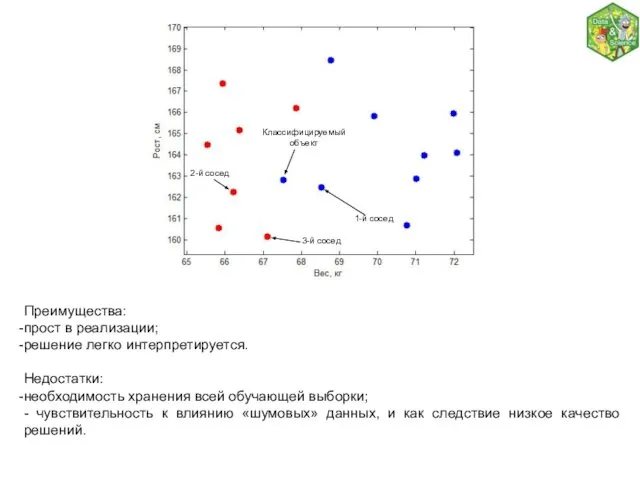
Преимущества:
прост в реализации;
решение легко интерпретируется.
Недостатки:
необходимость хранения всей обучающей выборки;
- чувствительность
Преимущества:
прост в реализации;
решение легко интерпретируется.
Недостатки:
необходимость хранения всей обучающей выборки;
- чувствительность
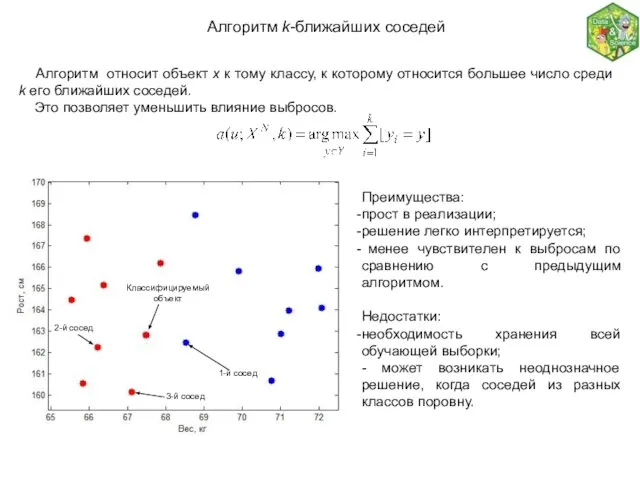
Алгоритм k-ближайших соседей
Алгоритм относит объект x к тому
Алгоритм k-ближайших соседей
Алгоритм относит объект x к тому
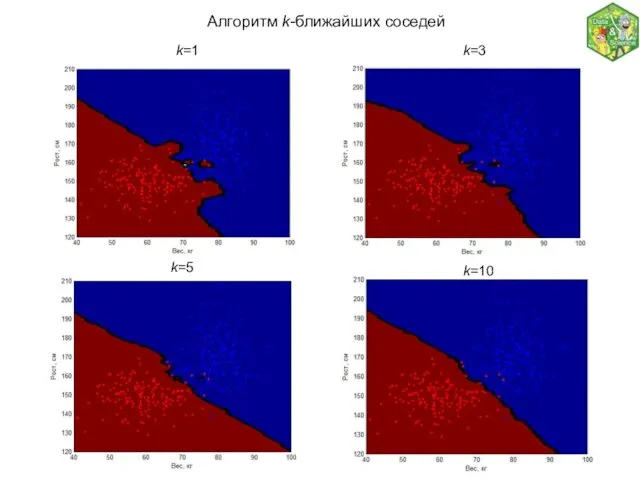
Алгоритм k-ближайших соседей
k=1
k=10
k=5
k=3
Алгоритм k-ближайших соседей
k=1
k=10
k=5
k=3

Алгоритм взвешенных k-ближайших соседей
Устранение неоднозначных решений возможно путём
Алгоритм взвешенных k-ближайших соседей
Устранение неоднозначных решений возможно путём

Метод парзеновского окна
Веса можно задавать в зависимости не от номера
Метод парзеновского окна
Веса можно задавать в зависимости не от номера
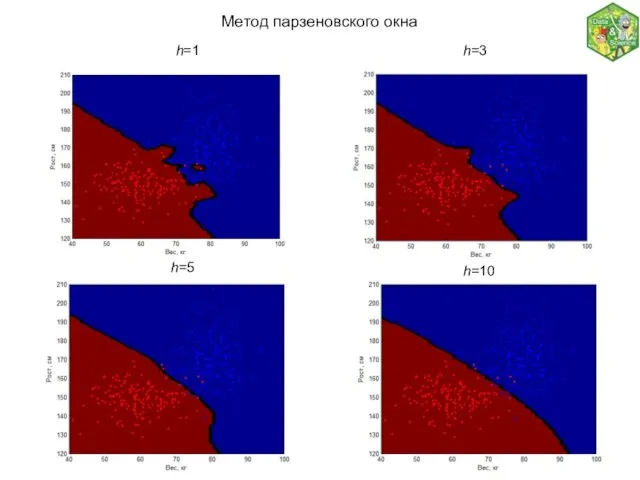
Метод парзеновского окна
h=1
h=10
h=5
h=3
Метод парзеновского окна
h=1
h=10
h=5
h=3
 Программирование (Python)
Программирование (Python) Навигационно-программный комплекс Навигационно-программный комплекс «СитиГИД-Диспетчер»
Навигационно-программный комплекс Навигационно-программный комплекс «СитиГИД-Диспетчер»  Тема 13 Понятие об алгоритме 1. Понятие об алгоритме 2. Способы записи алгоритмов 3. Алгоритмы ветвления 4. Циклические алгоритмы
Тема 13 Понятие об алгоритме 1. Понятие об алгоритме 2. Способы записи алгоритмов 3. Алгоритмы ветвления 4. Циклические алгоритмы Метод координат, как форма представления информации
Метод координат, как форма представления информации Мультимедиа. Аналоговый и цифровой звук. Технические средства мультимедиа Информатика 8 класс. Диденко В.В.
Мультимедиа. Аналоговый и цифровой звук. Технические средства мультимедиа Информатика 8 класс. Диденко В.В. Программирование на языке Python
Программирование на языке Python Знакомство с языком программирования Python. Ввод. Вывод. Оператор присваивания. Математические операции
Знакомство с языком программирования Python. Ввод. Вывод. Оператор присваивания. Математические операции Шаблоны интеграционных взаимодействий
Шаблоны интеграционных взаимодействий Физическая среда передачи данных
Физическая среда передачи данных Этапы разработки базы данных дата проведения: 04.02.09 Провела: Учитель информатики и ВТ Хрусцелевская Н.В. Прослушал: 11 класс
Этапы разработки базы данных дата проведения: 04.02.09 Провела: Учитель информатики и ВТ Хрусцелевская Н.В. Прослушал: 11 класс Разработка алгоритма и программы расчета пропускной способности системы обмена данными
Разработка алгоритма и программы расчета пропускной способности системы обмена данными CMS системы (1 занятие )
CMS системы (1 занятие ) Презентация по информатике Безопасный интернет
Презентация по информатике Безопасный интернет  [EPAM Java Training] Client-Server
[EPAM Java Training] Client-Server Қосымша басқару элементтерін қолдану. Microsoft Web Browser, Calendar, RefEdit басқару элементтері
Қосымша басқару элементтерін қолдану. Microsoft Web Browser, Calendar, RefEdit басқару элементтері Процессоры фирмы AMD до Athlon XP (Thorton/Model 10)
Процессоры фирмы AMD до Athlon XP (Thorton/Model 10)  26 ноября – Всемирный день информации
26 ноября – Всемирный день информации  Как работать сYouTube? Социальный сервис, предоставляющие услуги хостинга любительского видео.
Как работать сYouTube? Социальный сервис, предоставляющие услуги хостинга любительского видео. Программирование на языках высокого уровня
Программирование на языках высокого уровня УМК нового поколения для начальной школы Музыка системы Перспектива
УМК нового поколения для начальной школы Музыка системы Перспектива Видеохостинг нацеленный на Кавказскую тематику
Видеохостинг нацеленный на Кавказскую тематику ПРАВОВАЯ ИНФОРМАТИКА
ПРАВОВАЯ ИНФОРМАТИКА Создание бронирования в GDS Amadeus. (Лекция 1)
Создание бронирования в GDS Amadeus. (Лекция 1) SQL - структурированный язык запросов
SQL - структурированный язык запросов Информационная безопасность при работе со сторонними организациями и информационная безопасность активов организации
Информационная безопасность при работе со сторонними организациями и информационная безопасность активов организации Часы
Часы Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Методы и строки. Часть 3
Методы и строки. Часть 3