- Сетевые информационные технологии. Сжатие без потерь

Содержание
- 2. Сжатие без потерь Cжатие без потерь (lossless compression). Информация не теряется. Распакованные данные идентичны исходным несжатым
- 3. Сжатие без потерь Метод подавления нулей (null suppression): BISYNC IBM 3780 Передатчик сканирует данные в поиске
- 4. Сжатие без потерь Групповое кодирование : Обобщение метода подавления нулей и применяется для сжатия повторяющихся данных
- 5. Сжатие без потерь 0000000000 0000000000 0001111000 0001001000 0001111000 0000001000 0000001000 0001111000 0000000000 0000000000 Длина равна 100
- 6. Сжатие без потерь Факсимильное сжатие: Страница, отсканированная с разрешением 200 пел (белых или черных точек на
- 7. Сжатие без потерь Модифицированный код Хаффмана: W7, В7, W4, В8, W4, В7, W10 ITU-T: 1728 точек
- 8. Сжатие без потерь Арифметическое кодирование. Основная концепция. H(X) - энтропия множества символов X, E[L] – средняя
- 9. Сжатие без потерь Арифметическое кодирование. Основная концепция. Таким образом, существует способ повышения эффективности алгоритма сжатия. Если
- 10. Сжатие без потерь Арифметическое кодирование. Основная концепция.
- 11. Сжатие без потерь Арифметическое кодирование. Основная концепция. Теперь результату каждого сообщения поставлен в соответствие интервал, пропорциональный
- 12. Сжатие без потерь Чистое арифметическое кодирование: БАЗОВЫЙ АЛГОРИТМ: Каждый шаг алгоритма начинается с полуоткрытого интервала [L,
- 13. Сжатие без потерь Арифметическое кодирование : ПРИМЕР1: Пусть имеются два символа, a и b, вероятности которых
- 15. Скачать презентацию

Сжатие без потерь
Cжатие без потерь (lossless compression). Информация не теряется. Распакованные
Сжатие без потерь
Cжатие без потерь (lossless compression). Информация не теряется. Распакованные

Сжатие без потерь
Метод подавления нулей (null suppression):
BISYNC IBM 3780
Передатчик сканирует данные
Сжатие без потерь
Метод подавления нулей (null suppression):
BISYNC IBM 3780
Передатчик сканирует данные

Сжатие без потерь
Групповое кодирование :
Обобщение метода подавления нулей и применяется для
Сжатие без потерь
Групповое кодирование :
Обобщение метода подавления нулей и применяется для
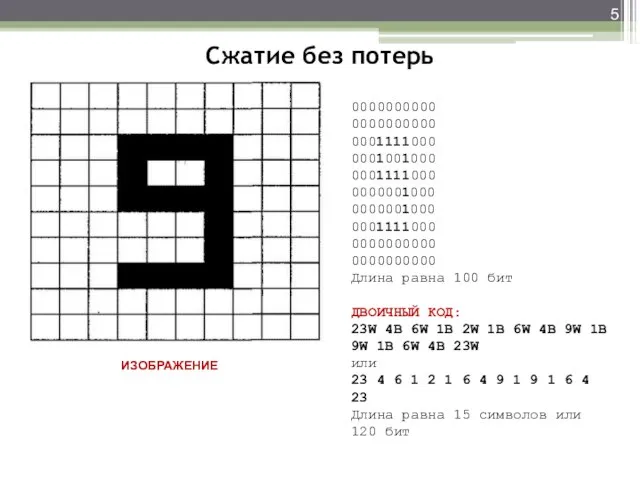
Сжатие без потерь
0000000000
0000000000
0001111000
0001001000
0001111000
0000001000
0000001000
0001111000
0000000000
0000000000
Длина равна 100 бит
ДВОИЧНЫЙ КОД:
23W 4B 6W 1B 2W
Сжатие без потерь
0000000000
0000000000
0001111000
0001001000
0001111000
0000001000
0000001000
0001111000
0000000000
0000000000
Длина равна 100 бит
ДВОИЧНЫЙ КОД:
23W 4B 6W 1B 2W

Сжатие без потерь
Факсимильное сжатие:
Страница, отсканированная с разрешением 200 пел (белых или
Сжатие без потерь
Факсимильное сжатие:
Страница, отсканированная с разрешением 200 пел (белых или

Сжатие без потерь
Модифицированный код Хаффмана:
W7, В7, W4, В8, W4, В7, W10
ITU-T:
Сжатие без потерь
Модифицированный код Хаффмана:
W7, В7, W4, В8, W4, В7, W10
ITU-T:

Сжатие без потерь
Арифметическое кодирование. Основная концепция.
H(X) - энтропия множества символов X,
Сжатие без потерь
Арифметическое кодирование. Основная концепция.
H(X) - энтропия множества символов X,

Сжатие без потерь
Арифметическое кодирование. Основная концепция.
Таким образом, существует способ повышения эффективности
Сжатие без потерь
Арифметическое кодирование. Основная концепция.
Таким образом, существует способ повышения эффективности

Сжатие без потерь
Арифметическое кодирование. Основная концепция.
Сжатие без потерь
Арифметическое кодирование. Основная концепция.
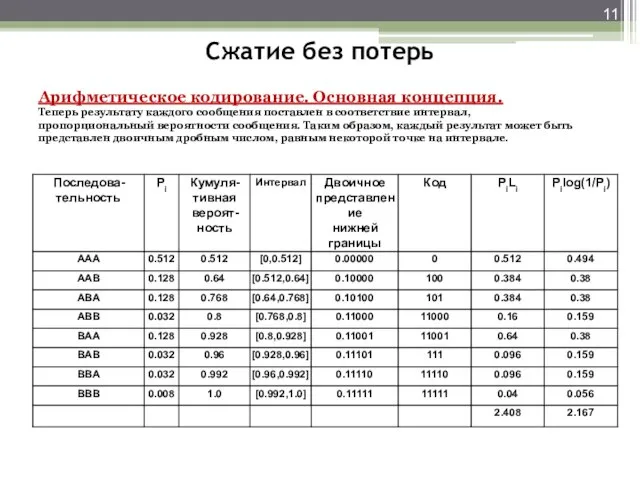
Сжатие без потерь
Арифметическое кодирование. Основная концепция.
Теперь результату каждого сообщения поставлен в
Сжатие без потерь
Арифметическое кодирование. Основная концепция.
Теперь результату каждого сообщения поставлен в

Сжатие без потерь
Чистое арифметическое кодирование:
БАЗОВЫЙ АЛГОРИТМ:
Каждый шаг алгоритма начинается с полуоткрытого
Сжатие без потерь
Чистое арифметическое кодирование:
БАЗОВЫЙ АЛГОРИТМ:
Каждый шаг алгоритма начинается с полуоткрытого

Сжатие без потерь
Арифметическое кодирование :
ПРИМЕР1:
Пусть имеются два символа, a и b,
Сжатие без потерь
Арифметическое кодирование :
ПРИМЕР1:
Пусть имеются два символа, a и b,
 Зарубежные информационные ресурсы негуманитарных отраслей науки и практики. (Тема 4)
Зарубежные информационные ресурсы негуманитарных отраслей науки и практики. (Тема 4) Информационные системы. Данные. Информация. Знания. Базы данных. База знаний. Программное обеспечение
Информационные системы. Данные. Информация. Знания. Базы данных. База знаний. Программное обеспечение Примеры простых программ на Си
Примеры простых программ на Си Возможности использования ИКТ на уроках физической культуры
Возможности использования ИКТ на уроках физической культуры Эпистемическая логика
Эпистемическая логика Программирование на языке Python. Символьные строки
Программирование на языке Python. Символьные строки Модели объектов и их назначение
Модели объектов и их назначение Аптека-56. Программное обеспечение для аптечного бизнеса
Аптека-56. Программное обеспечение для аптечного бизнеса Регламент мастер-класса Мужчина нарасхват
Регламент мастер-класса Мужчина нарасхват Заполнение электронного портфоли
Заполнение электронного портфоли Виды Баз Данных
Виды Баз Данных Разработка web-сайта Интернет-магазин
Разработка web-сайта Интернет-магазин ВКР: Разработка проекта ЛВС для компании ООО Балтик Стайл
ВКР: Разработка проекта ЛВС для компании ООО Балтик Стайл Презентация "Место компьютера в информационно- образовательном пространстве" - скачать презентации по Информатике
Презентация "Место компьютера в информационно- образовательном пространстве" - скачать презентации по Информатике Lektsia1_OP_08_1
Lektsia1_OP_08_1 opoib_1_1x
opoib_1_1x Язык С#. Основы языка. Лекция #1
Язык С#. Основы языка. Лекция #1 Форматы чертежей. Создание и настройка нового чертежа в КОМПАС
Форматы чертежей. Создание и настройка нового чертежа в КОМПАС Хозяйство Беларуси (инфографика)
Хозяйство Беларуси (инфографика) Ведение в предмет информатики
Ведение в предмет информатики Словарная работа по теме Интернет. Информатика и английский. 9 класс
Словарная работа по теме Интернет. Информатика и английский. 9 класс Комплексное решение на базе технологий Smart WiFi и IoT/M2M
Комплексное решение на базе технологий Smart WiFi и IoT/M2M Тестирование и его связь с жизненным циклом ПО
Тестирование и его связь с жизненным циклом ПО Информационные технологии. Лекция 2
Информационные технологии. Лекция 2 Моделирование физических процессов
Моделирование физических процессов Прикладное программное обеспечение информационных систем
Прикладное программное обеспечение информационных систем Программное обеспечение компьютера
Программное обеспечение компьютера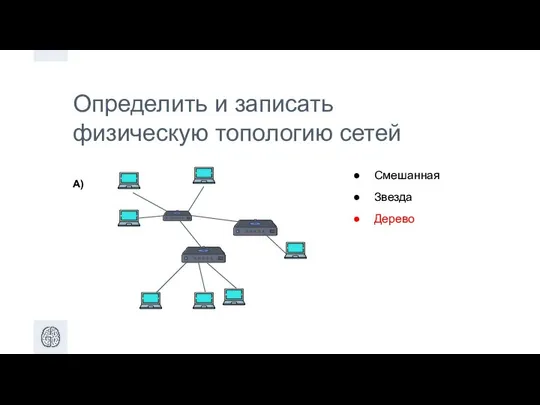 Определить и записать физическую топологию сетей
Определить и записать физическую топологию сетей