- Сжатие текстовой информации

Содержание
- 2. Сжатие текстовой информации
- 3. Сжатие данных — процедура перекодирования данных, производимая с целью уменьшения их объёма. Декомпрессия - это способ
- 4. Под архиватором понимается программа-архиватор, формат архива и метод сжатия в комплексе. Архиваторы
- 5. Архиваторы ACE, RAR и Squeez имеют близкие результаты с небольшим преимуществом по степени сжатия у RAR,
- 6. Бесплатные программы для обработки аудио- и видеоинформации
- 7. Виды сжатий Возможно восстановление исходных данных без искажений. Форматы файлов: gif, tif, png, pcx, avi, zip,
- 8. Сжатие с потерей качества
- 9. Сжатие без потерь Алгоритм RLE от англ. Run Length Encoding В файле записывается, сколько раз повторяются
- 10. В восьмиразрядной таблице символьной кодировки АSCII каждый символ кодируется восемью битами и, следовательно, занимает в памяти
- 11. Сжатие без потерь Метод упаковки TO BE OR NOT TO BE? 19 символов в предложении: 3*19=57
- 12. Практическая работа
- 13. Практическая работа
- 14. Практическая работа “Частотный анализ букв русского языка” Открыть с помощью Microsoft Office Word документ Skazka.doc. Подсчитать
- 15. Хаффмана АЛГОРИТМ
- 16. Частотный анализ Сказка «Снежная королева»
- 17. Сравнительный частотный анализ «Анна Каренина» оеанитслвркдмупяьыгбчзжйшхэющцфъ 280 тыс. слов Солженицын А.И. oeaинтсвлрлдмпуьяыгбзчйхжшюцщэфъ 86 тыс. слов Новости
- 18. В тексте, написанном на русском языке, в каждой тысяче символов в среднем будет 90 букв "о",
- 19. Оба этих алгоритма используют коды переменной длины: часто встречающийся символ кодируется двоичным кодом меньшей длины, редко
- 20. К.Шеннон и Р.Фано сформулировали алгоритм сжатия, который использует коды переменной длины. Алгоритм Шеннона-Фано
- 21. David Huffman (1925-1999) В 18 лет Дэвид получил степень бакалавра электротехники в уни-верситете штата Огайо. Основную
- 22. Таблица кодов Хаффмана
- 23. Двоичное дерево Двоичным (бинарным) называется дерево, из каждой вершины которого выходят две ветви.
- 24. МОУ СОШ №33 с углубленным изучением математики г.Ярославля Т 001 В 011100 Q 1101000101 корень Дерево
- 25. 00000 11011 110100011 корень Дерево Хаффмана
- 26. Азбука Морзе Сэмюэль Морзе (1791-1872) - американский изобретатель и художник
- 27. Азбука Морзе
- 28. 01000111011011100 корень Дерево Хаффмана С О D E
- 29. Код Хаффмана обладает свойством префиксности, то есть код никакого символа не является началом кода какого-либо другого
- 30. Дерево азбуки Морзе
- 31. Алгоритм Хаффмана двухпроходный: на первом проходе строится частотный словарь и генерируются коды; на втором проходе происходит
- 32. Алгоритм построения дерева Хаффмана Среди символов выбрать два с наименьшими весами (если таких пар несколько, выбирается
- 33. 3 4 4 7 8 9 13 17 30 Построение дерева Хаффмана
- 34. 30 17 13 8 4 9 4 7 3
- 35. Построение дерева Хаффмана
- 36. Кодирование текста НА ДВОРЕ ТРАВА, НА ТРАВЕ ДРОВА 1001001110110010110010110001111101 Н А _ Д В О Р
- 37. Кодирование текста НА ДВОРЕ ТРАВА, НА ТРАВЕ ДРОВА 10010011101100101100101100011111 01101000100001111111001001111101 1010001010001110110101110001000
- 38. Коэффициент сжатия Коэффициентом сжатия называется отношение объема исходного сообщения к объему сжатого. Объем сжатого сообщения: 6*2+4*3+2*4+1*4+2*4+2*4+4*3+2*4+2*4+5*3=95
- 39. Декодирование Восстановить исходный текст: 1 0 0 1 0 0 1 0 1 1 1 0
- 40. 1 0 0 1 0 0 1 0 1 1 1 0 0 0 1 1
- 41. Самостоятельная работа Постройте код Хаффмана для предложения: TO BE OR NOT TO BE? Определите коэффициент сжатия
- 42. 1 0 1 0 1 0 1 0 1 0 1 0 1 0 2*4+1*4+3*3+5*2+4*2+1*4+1*4+2*3=53 бита=7
- 43. 1 0 1 0 1 0 1 0 1 0 1 0 4*2+2*3+2*3+5*2+3*3+1*4+1*5+1*5=53 бита Другое решение
- 44. Книги по теме
- 45. задание Задание №1 Постройте код Хаффмана для фраз: Человек как музыкальный инструмент, как настроишь, так и
- 46. Домашнее задание Задание №2 На языке Си++ напишите программу, реализующую алгоритм RLE для текстовых данных. Исходные
- 47. Кроссворд
- 48. Кроссворд
- 50. Скачать презентацию

Сжатие
текстовой информации
Сжатие
текстовой информации

Сжатие данных — процедура перекодирования данных, производимая
с целью уменьшения их
Сжатие данных — процедура перекодирования данных, производимая с целью уменьшения их
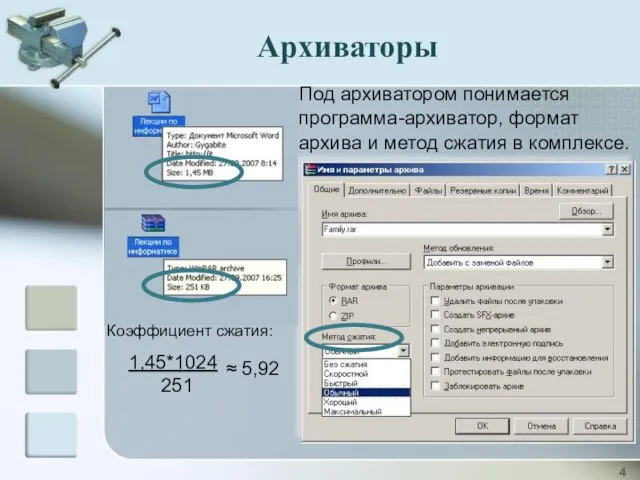
Под архиватором понимается программа-архиватор, формат архива и метод сжатия в комплексе.
Под архиватором понимается программа-архиватор, формат архива и метод сжатия в комплексе.
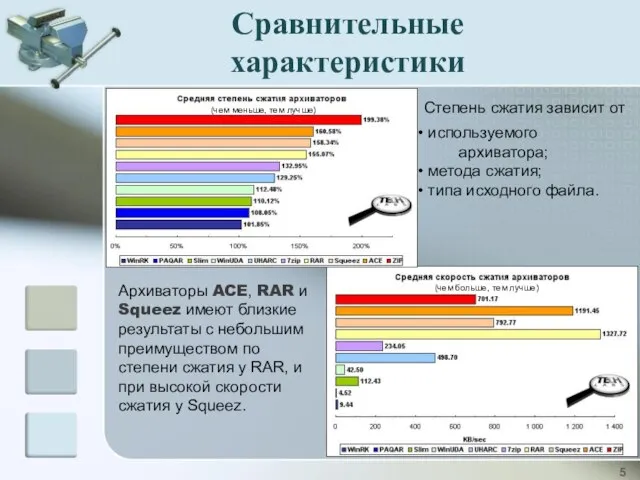
Архиваторы ACE, RAR и Squeez имеют близкие результаты с небольшим преимуществом
Архиваторы ACE, RAR и Squeez имеют близкие результаты с небольшим преимуществом
Бесплатные программы для обработки аудио- и видеоинформации
Бесплатные программы для обработки аудио- и видеоинформации
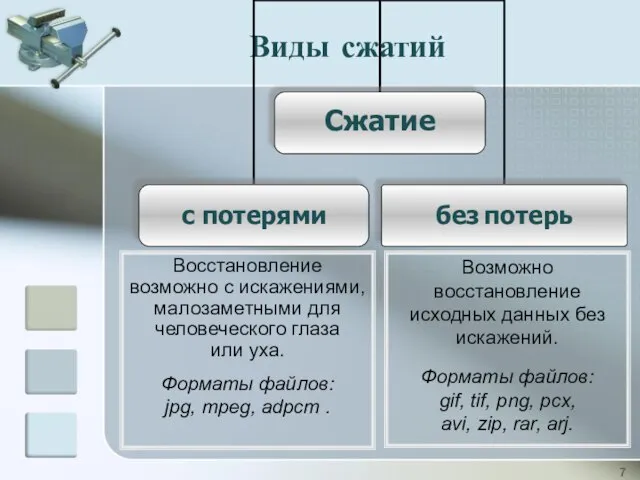
Виды сжатий
Возможно восстановление исходных данных без искажений.
Форматы файлов:
gif, tif, png, pcx,
avi,
Виды сжатий
Возможно восстановление исходных данных без искажений.
Форматы файлов:
gif, tif, png, pcx,
avi,

Сжатие
с потерей качества
Сжатие
с потерей качества

Сжатие без потерь
Алгоритм RLE
от англ. Run Length Encoding
В файле
Сжатие без потерь
Алгоритм RLE
от англ. Run Length Encoding
В файле
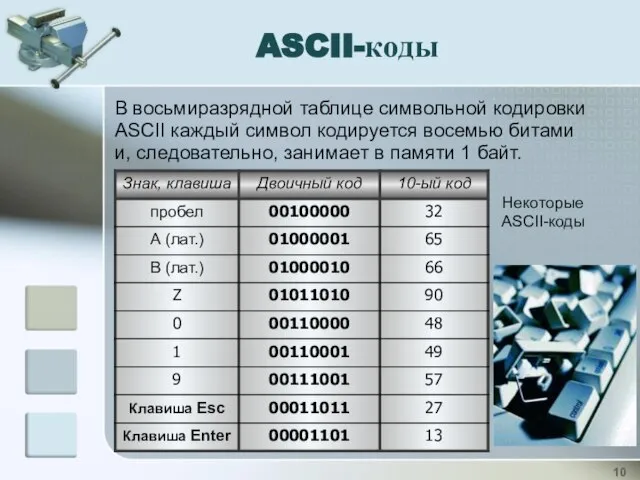
В восьмиразрядной таблице символьной кодировки АSCII каждый символ кодируется восемью битами
В восьмиразрядной таблице символьной кодировки АSCII каждый символ кодируется восемью битами

Сжатие без потерь
Метод упаковки
TO BE OR NOT TO BE?
19 символов в
Сжатие без потерь
Метод упаковки
TO BE OR NOT TO BE?
19 символов в
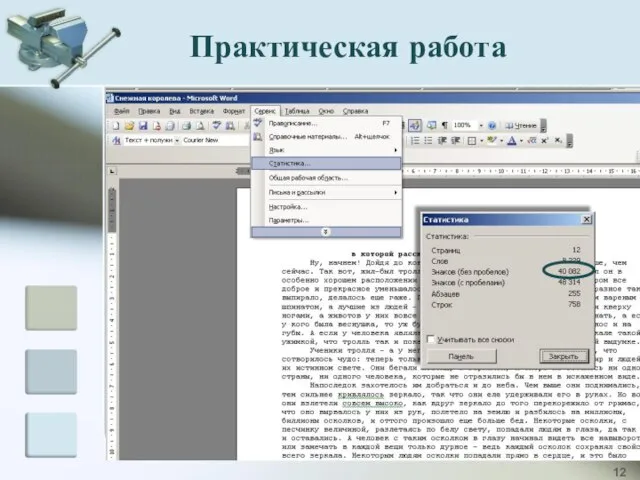
Практическая работа
Практическая работа
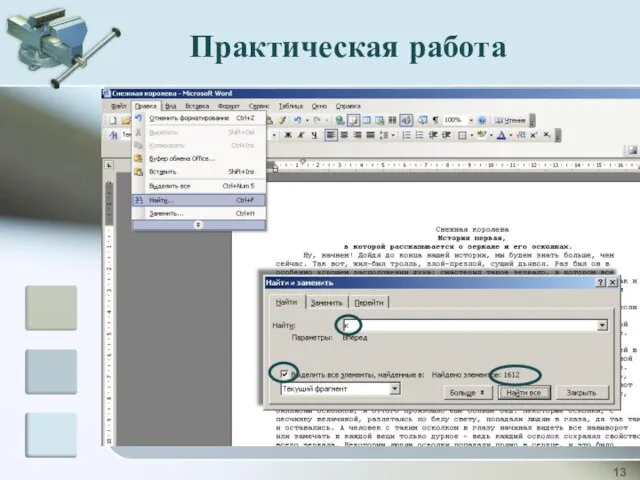
Практическая работа
Практическая работа

Практическая работа
“Частотный анализ букв русского языка”
Открыть с помощью Microsoft Office
Практическая работа
“Частотный анализ букв русского языка”
Открыть с помощью Microsoft Office

Хаффмана
АЛГОРИТМ
Хаффмана
АЛГОРИТМ
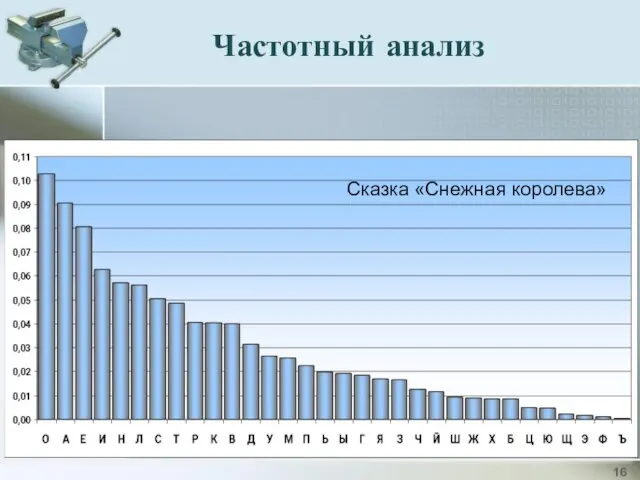
Частотный анализ
Сказка «Снежная королева»
Частотный анализ
Сказка «Снежная королева»
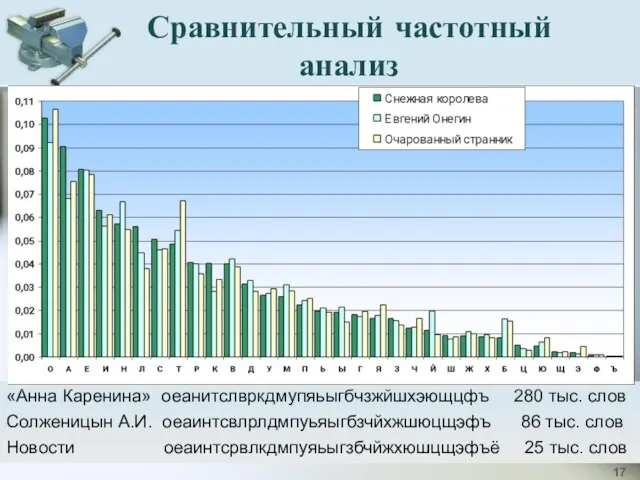
Сравнительный частотный анализ
«Анна Каренина» оеанитслвркдмупяьыгбчзжйшхэющцфъ 280 тыс. слов
Солженицын А.И. oeaинтсвлрлдмпуьяыгбзчйхжшюцщэфъ 86
Сравнительный частотный анализ
«Анна Каренина» оеанитслвркдмупяьыгбчзжйшхэющцфъ 280 тыс. слов
Солженицын А.И. oeaинтсвлрлдмпуьяыгбзчйхжшюцщэфъ 86

В тексте, написанном на русском языке, в каждой тысяче символов в среднем
В тексте, написанном на русском языке, в каждой тысяче символов в среднем

Оба этих алгоритма используют коды переменной длины: часто встречающийся символ кодируется
Оба этих алгоритма используют коды переменной длины: часто встречающийся символ кодируется
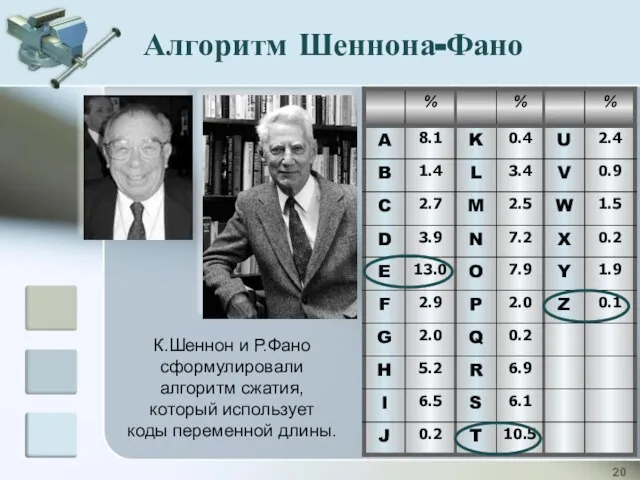
К.Шеннон и Р.Фано сформулировали алгоритм сжатия,
который использует
коды переменной длины.
Алгоритм
К.Шеннон и Р.Фано сформулировали алгоритм сжатия,
который использует
коды переменной длины.
Алгоритм

David Huffman
(1925-1999)
В 18 лет Дэвид получил степень бакалавра электротехники в
David Huffman
(1925-1999)
В 18 лет Дэвид получил степень бакалавра электротехники в
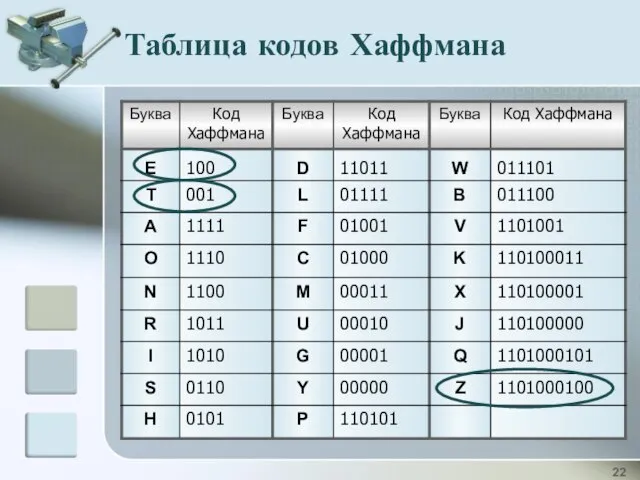
Таблица кодов Хаффмана
Таблица кодов Хаффмана
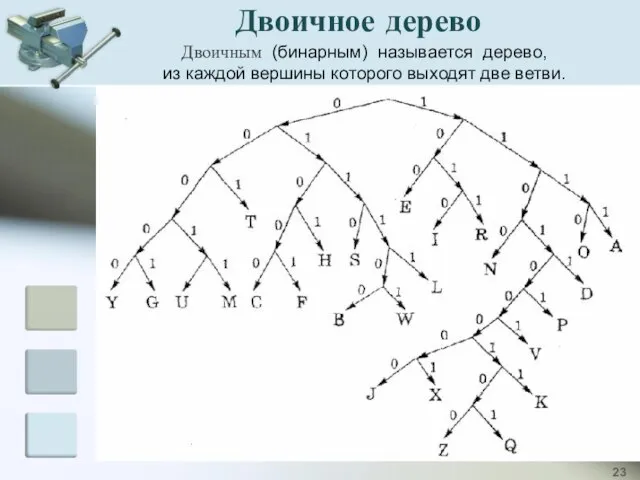
Двоичное дерево
Двоичным (бинарным) называется дерево,
из каждой вершины которого выходят две
Двоичное дерево
Двоичным (бинарным) называется дерево, из каждой вершины которого выходят две
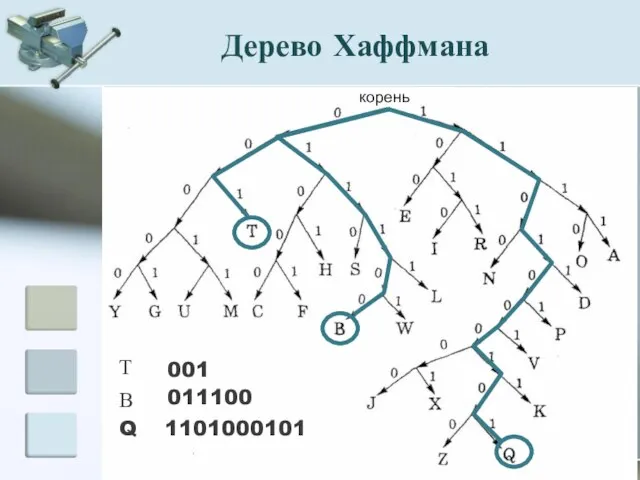
МОУ СОШ №33 с углубленным изучением математики г.Ярославля
Т
001
В
011100
Q
1101000101
корень
Дерево Хаффмана
МОУ СОШ №33 с углубленным изучением математики г.Ярославля
Т
001
В
011100
Q
1101000101
корень
Дерево Хаффмана
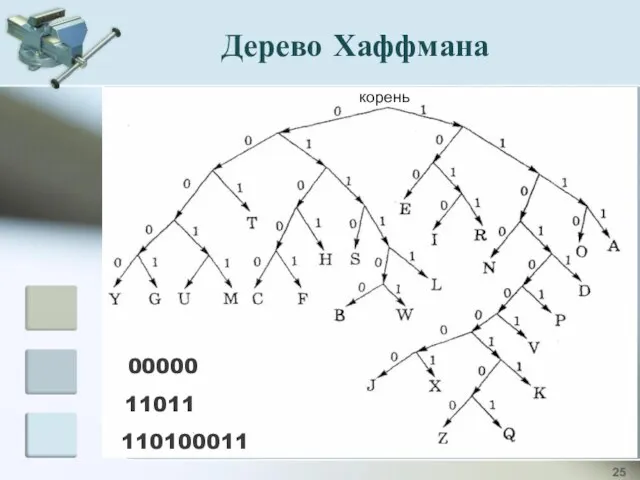
00000
11011
110100011
корень
Дерево Хаффмана
00000
11011
110100011
корень
Дерево Хаффмана

Азбука Морзе
Сэмюэль Морзе
(1791-1872) - американский изобретатель и художник
Азбука Морзе
Сэмюэль Морзе
(1791-1872) - американский изобретатель и художник
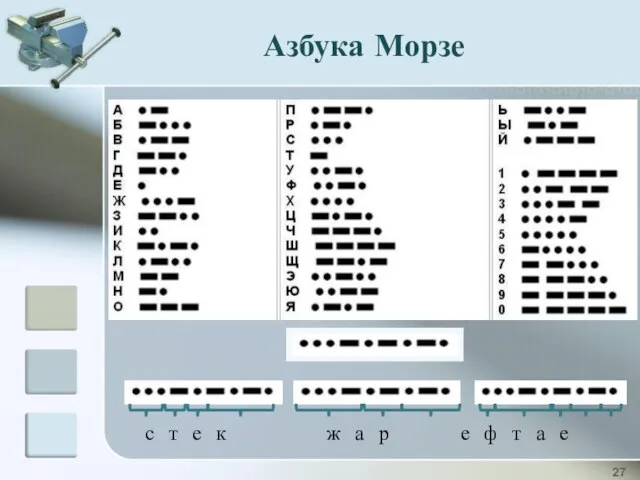
Азбука Морзе
Азбука Морзе
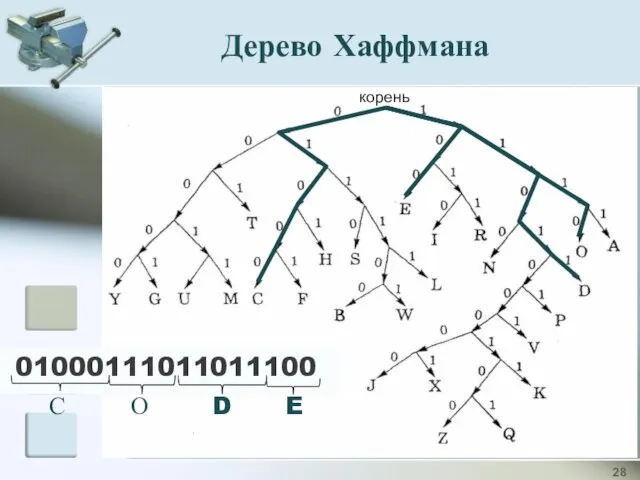
01000111011011100
корень
Дерево Хаффмана
С
О
D
E
01000111011011100
корень
Дерево Хаффмана
С
О
D
E
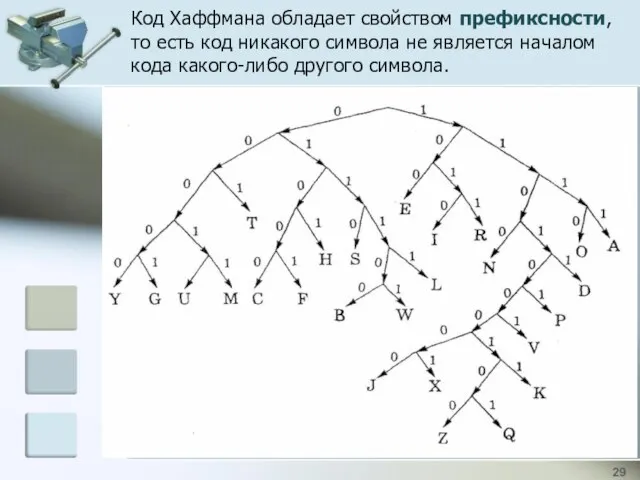
Код Хаффмана обладает свойством префиксности,
то есть код никакого символа не
Код Хаффмана обладает свойством префиксности, то есть код никакого символа не
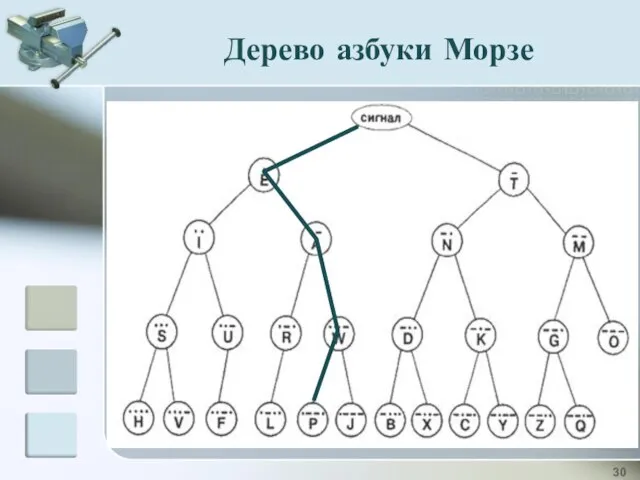
Дерево азбуки Морзе
Дерево азбуки Морзе

Алгоритм Хаффмана двухпроходный: на первом проходе строится частотный словарь и генерируются
Алгоритм Хаффмана двухпроходный: на первом проходе строится частотный словарь и генерируются

Алгоритм построения
дерева Хаффмана
Среди символов выбрать два с наименьшими весами (если таких
Алгоритм построения
дерева Хаффмана
Среди символов выбрать два с наименьшими весами (если таких
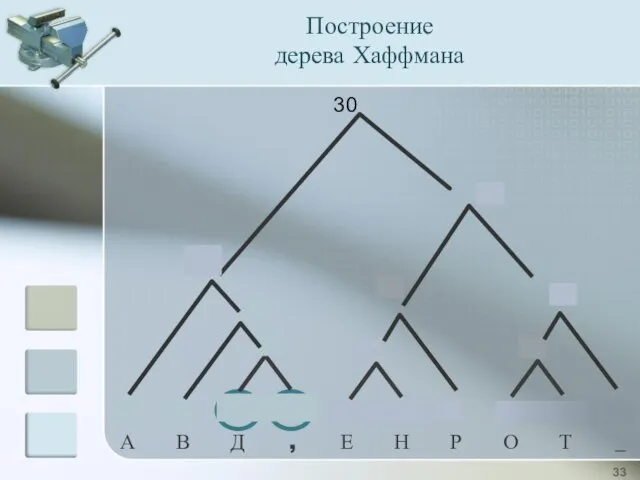
3
4
4
7
8
9
13
17
30
Построение
дерева Хаффмана
3
4
4
7
8
9
13
17
30
Построение
дерева Хаффмана
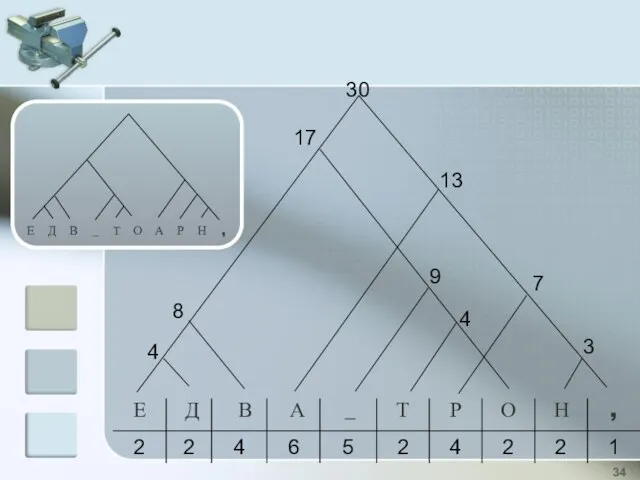
30
17
13
8
4
9
4
7
3
30
17
13
8
4
9
4
7
3
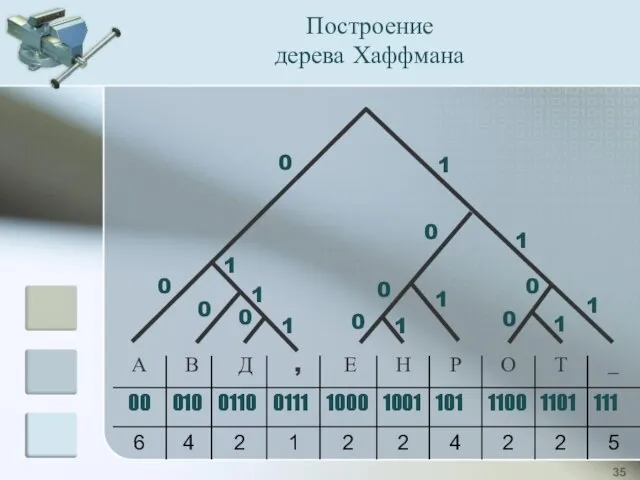
Построение
дерева Хаффмана
Построение
дерева Хаффмана

Кодирование текста
НА ДВОРЕ ТРАВА, НА ТРАВЕ ДРОВА
1001001110110010110010110001111101
Н А _ Д
Кодирование текста
НА ДВОРЕ ТРАВА, НА ТРАВЕ ДРОВА
1001001110110010110010110001111101
Н А _ Д

Кодирование текста
НА ДВОРЕ ТРАВА, НА ТРАВЕ ДРОВА
10010011101100101100101100011111
01101000100001111111001001111101
1010001010001110110101110001000
Кодирование текста
НА ДВОРЕ ТРАВА, НА ТРАВЕ ДРОВА
10010011101100101100101100011111
01101000100001111111001001111101
1010001010001110110101110001000

Коэффициент сжатия
Коэффициентом сжатия называется отношение объема исходного сообщения к объему сжатого.
Объем
Коэффициент сжатия
Коэффициентом сжатия называется отношение объема исходного сообщения к объему сжатого.
Объем

Декодирование
Восстановить исходный текст:
1 0 0 1 0 0 1 0
Декодирование
Восстановить исходный текст:
1 0 0 1 0 0 1 0
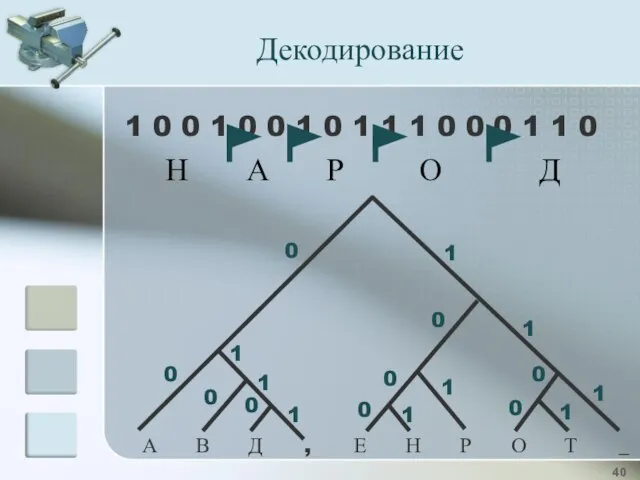
1 0 0 1 0 0 1 0 1 1 1
1 0 0 1 0 0 1 0 1 1 1

Самостоятельная работа
Постройте код Хаффмана для предложения:
TO BE OR NOT TO BE?
Определите
Самостоятельная работа
Постройте код Хаффмана для предложения:
TO BE OR NOT TO BE?
Определите
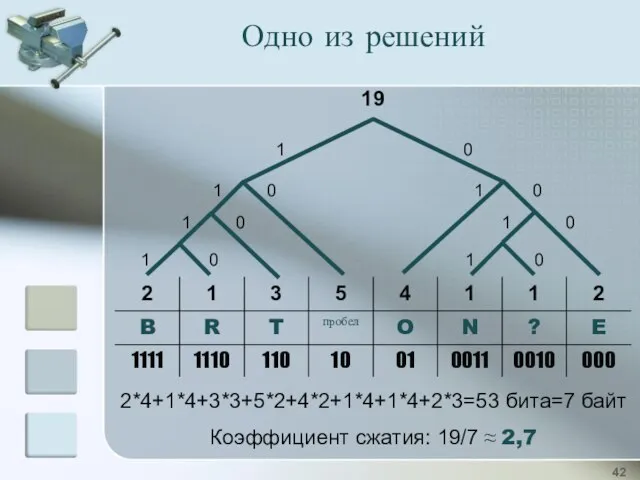
1 0
1 0 1 0
1 0 1 0
1 0 1 0
2*4+1*4+3*3+5*2+4*2+1*4+1*4+2*3=53
1 0
1 0 1 0
1 0 1 0
1 0 1 0
2*4+1*4+3*3+5*2+4*2+1*4+1*4+2*3=53
1 0
1 0
1 0
1 0
1 0
1 0
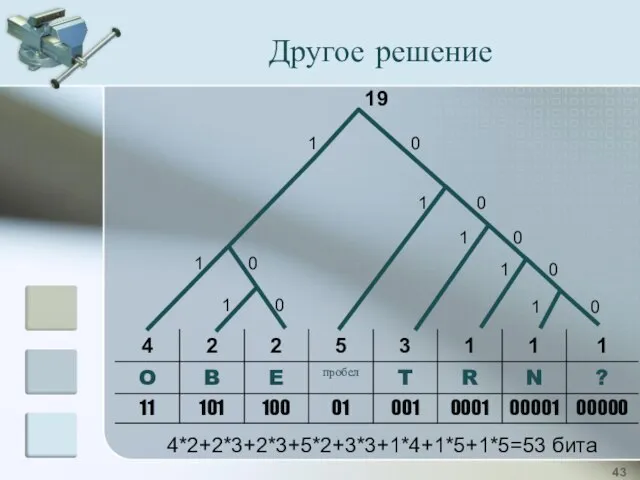
4*2+2*3+2*3+5*2+3*3+1*4+1*5+1*5=53 бита
Другое решение
1 0
1 0
1 0
1 0
1 0
1 0
1 0
4*2+2*3+2*3+5*2+3*3+1*4+1*5+1*5=53 бита
Другое решение
1 0

Книги по теме
Книги по теме

задание
Задание №1
Постройте код Хаффмана для фраз:
Человек как музыкальный инструмент, как
задание
Задание №1
Постройте код Хаффмана для фраз:
Человек как музыкальный инструмент, как

Домашнее задание
Задание №2
На языке Си++ напишите программу, реализующую алгоритм RLE для
Домашнее задание
Задание №2
На языке Си++ напишите программу, реализующую алгоритм RLE для
Кроссворд
Кроссворд
Кроссворд
Кроссворд
 Электронные таблицы и их предназначение.
Электронные таблицы и их предназначение. Лекция 2. Классификация прикладных ИС
Лекция 2. Классификация прикладных ИС Презентация "Программист" - скачать презентации по Информатике
Презентация "Программист" - скачать презентации по Информатике Web-технологии в управлении техническими системами
Web-технологии в управлении техническими системами Моделирование как метод научного познания
Моделирование как метод научного познания Элементы информатики и вычислительной техники на уроках математики Лобанова Галина Павловна, учитель математики УОР №2, Санк
Элементы информатики и вычислительной техники на уроках математики Лобанова Галина Павловна, учитель математики УОР №2, Санк Инструкции для ПВЗ
Инструкции для ПВЗ Системы счисления. Введение
Системы счисления. Введение Защита от несанкционированного доступа к информации. 11 клас
Защита от несанкционированного доступа к информации. 11 клас Системы массового обслуживания
Системы массового обслуживания Игра - Platformer
Игра - Platformer Линейные алгоритмы
Линейные алгоритмы Внедрение CRM на предприятии
Внедрение CRM на предприятии Проектирование локальной вычислительной сети предприятия
Проектирование локальной вычислительной сети предприятия Информатика и информация
Информатика и информация Понятие информации Информатика 10 класс Учитель Соболева Г.В.
Понятие информации Информатика 10 класс Учитель Соболева Г.В. Роботу виконала Нечволода Тетяна учениця 11-Б класу Роботу виконала Нечволода Тетяна учениця 11-Б класу
Роботу виконала Нечволода Тетяна учениця 11-Б класу Роботу виконала Нечволода Тетяна учениця 11-Б класу Анимация
Анимация Протоколы маршрутизации
Протоколы маршрутизации Как устроен компьютер
Как устроен компьютер Компьютер - друг и помощник
Компьютер - друг и помощник Аттестационная работа. Рабочая программа внеурочной деятельности в рамках ФГОС ИКТ, как средства познания окружающего мира
Аттестационная работа. Рабочая программа внеурочной деятельности в рамках ФГОС ИКТ, как средства познания окружающего мира Высокие инновационные технологии. Шаблон
Высокие инновационные технологии. Шаблон Ячейки памяти компьютера
Ячейки памяти компьютера Системно-деятельностный подход в обучении информатики
Системно-деятельностный подход в обучении информатики Информационная безопасность. Общие принципы. Виды безопасности. (Лекция 3)
Информационная безопасность. Общие принципы. Виды безопасности. (Лекция 3) Древнерусская нумерация
Древнерусская нумерация Электронные ресурсы информационного центра (библиотеки) ИГХТУ
Электронные ресурсы информационного центра (библиотеки) ИГХТУ