- Увеличения точности прогнозирования событий на Титанике

Содержание
- 2. Блок импорта библиотек В исследуемом коде были выбраны основные библиотеки Данную часть кода оставляем без изменений
- 3. Блок импорта данных В данном блоке импортируются файлы для обучения и тестирования системы, а также эти
- 4. Представление данных Отобразим данные при помощи команды head(), и определим количество заполненных ячеек в столбцах при
- 5. Заполнение столбца AGE При помощи команды fillna() в строке возраста заполняем пустые строки (NaN) средневзвешенным значением:
- 6. Проверка заполнения столбца места отправления «Embarked»
- 7. Проверка зависимости места отправки от пола Наиболее распространённое место отправки для женщин и мужчин является «S»
- 8. Заполнение пустых ячеек в столбце Места отправки Заполняем место отправки самым распространенным
- 9. Проверка заполнения столбца пассажирской оплаты «Fare» И заполняем средним значением по 3 Pclass’у для нашего пустого
- 10. Проверка пустых ячеек
- 11. Исключаем из фрейма данных столбцы которые не имеют информативности
- 12. Для повышения эффективности прогноза представим столбцы Пола и места отправки в виде 0 и 1 в
- 13. Проведем корреляционный анализ Определяем что столбцы "Pclass", "Fare", "Sex_female", "Sex_male", "Embarked_C", "Embarked_Q", "Embarked_S” имеют зависимость с
- 14. Производим выбор столбцов для обучения и тестирования системы В примере не был произведен корреляционный анализ и
- 15. Проводим проверку метрики при помощи различных алгоритмов машинного обучения Разница в наилучшем результате более 7 процентов
- 16. Производим выбор наилучшего алгоритма для прогноза и получаем выходной файл с прогнозом В примере был выбран
- 18. Скачать презентацию

Блок импорта библиотек
В исследуемом коде были выбраны основные библиотеки
Данную часть
Блок импорта библиотек
В исследуемом коде были выбраны основные библиотеки
Данную часть

Блок импорта данных
В данном блоке импортируются файлы для обучения и тестирования
Блок импорта данных
В данном блоке импортируются файлы для обучения и тестирования

Представление данных
Отобразим данные при помощи команды head(), и определим количество заполненных
Представление данных
Отобразим данные при помощи команды head(), и определим количество заполненных

Заполнение столбца AGE
При помощи команды fillna() в строке возраста заполняем пустые
Заполнение столбца AGE
При помощи команды fillna() в строке возраста заполняем пустые
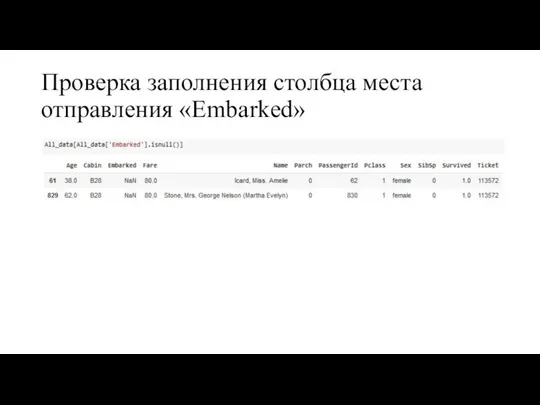
Проверка заполнения столбца места отправления «Embarked»
Проверка заполнения столбца места отправления «Embarked»

Проверка зависимости места отправки от пола
Наиболее распространённое место отправки для женщин
Проверка зависимости места отправки от пола
Наиболее распространённое место отправки для женщин
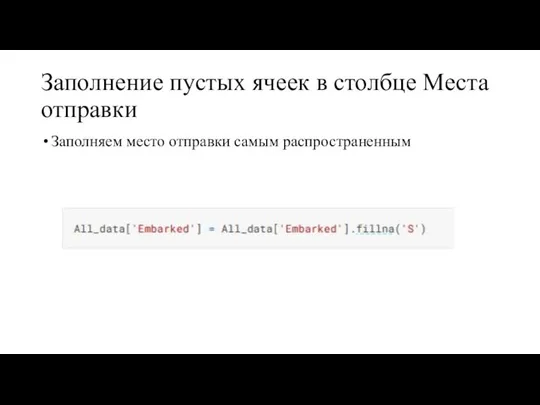
Заполнение пустых ячеек в столбце Места отправки
Заполняем место отправки самым
Заполнение пустых ячеек в столбце Места отправки
Заполняем место отправки самым
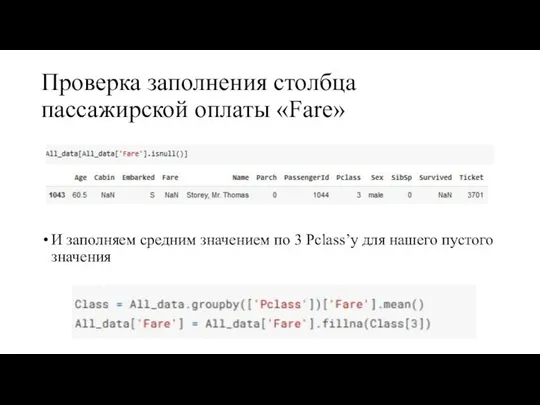
Проверка заполнения столбца пассажирской оплаты «Fare»
И заполняем средним значением по 3
Проверка заполнения столбца пассажирской оплаты «Fare»
И заполняем средним значением по 3

Проверка пустых ячеек
Проверка пустых ячеек

Исключаем из фрейма данных столбцы которые не имеют информативности
Исключаем из фрейма данных столбцы которые не имеют информативности

Для повышения эффективности прогноза представим столбцы Пола и места отправки в
Для повышения эффективности прогноза представим столбцы Пола и места отправки в

Проведем корреляционный анализ
Определяем что столбцы "Pclass", "Fare", "Sex_female", "Sex_male", "Embarked_C",
Проведем корреляционный анализ
Определяем что столбцы "Pclass", "Fare", "Sex_female", "Sex_male", "Embarked_C",
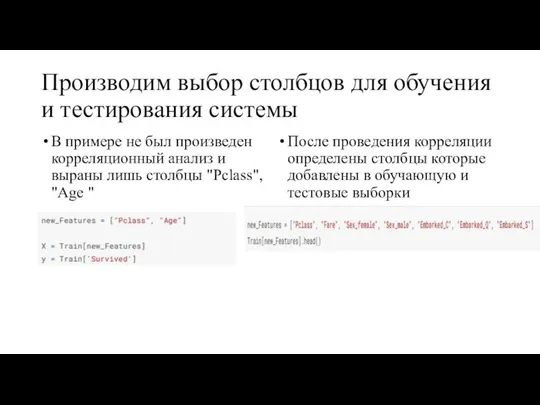
Производим выбор столбцов для обучения и тестирования системы
В примере не был
Производим выбор столбцов для обучения и тестирования системы
В примере не был
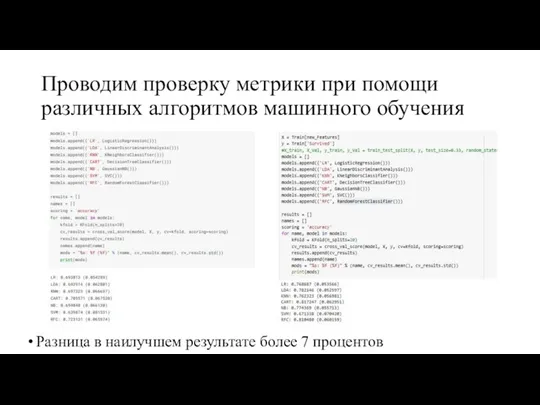
Проводим проверку метрики при помощи различных алгоритмов машинного обучения
Разница в наилучшем
Проводим проверку метрики при помощи различных алгоритмов машинного обучения
Разница в наилучшем
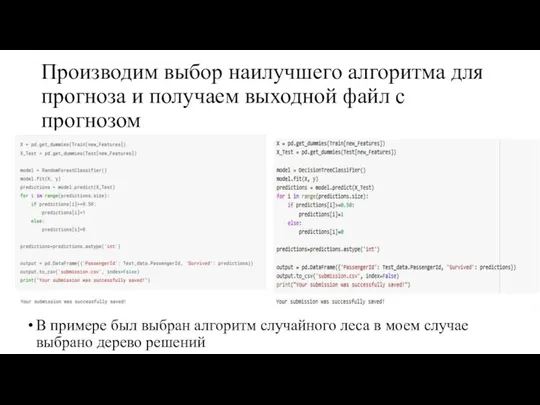
Производим выбор наилучшего алгоритма для прогноза и получаем выходной файл с
Производим выбор наилучшего алгоритма для прогноза и получаем выходной файл с
 Интелектуалды жүйелер
Интелектуалды жүйелер Основы алгоритмики. Библиотеки функций. Раздел 1. Общие правила
Основы алгоритмики. Библиотеки функций. Раздел 1. Общие правила Руководство по бронированию посещения Посольства через 24-часовую консульскую службу (для подачи на визы гражданами РФ)
Руководство по бронированию посещения Посольства через 24-часовую консульскую службу (для подачи на визы гражданами РФ) Теория компиляторов. Часть II. Лекция 3. Общие методы распараллеливания кода
Теория компиляторов. Часть II. Лекция 3. Общие методы распараллеливания кода Производственная практика. ADO.NET и COM при работе с MS ACCESS и MS EXCEL в десктопном приложении
Производственная практика. ADO.NET и COM при работе с MS ACCESS и MS EXCEL в десктопном приложении Snowflake game
Snowflake game Компьютерная графика. Основные понятия
Компьютерная графика. Основные понятия Поняття нових медіа
Поняття нових медіа Табличные базы данных
Табличные базы данных Современные технологии продвижения ресторана в Интернет
Современные технологии продвижения ресторана в Интернет ЭОР - Электронные образовательные ресурсы
ЭОР - Электронные образовательные ресурсы Операции над высказываниями
Операции над высказываниями Администрирование БД. Репликация баз данных.
Администрирование БД. Репликация баз данных. Алгоритм работы с научной электронной библиотекой elibrary.ru и информационно-аналитической системой РИНЦ
Алгоритм работы с научной электронной библиотекой elibrary.ru и информационно-аналитической системой РИНЦ Современные лингвистические корпусы
Современные лингвистические корпусы Dynamic management objects. Аргументы поиска (SARG). Денормализация БД. Лекция 6
Dynamic management objects. Аргументы поиска (SARG). Денормализация БД. Лекция 6 Работа с графикой
Работа с графикой Компьютерная графика
Компьютерная графика Типы алгоритмов
Типы алгоритмов Внешние устройства ПК
Внешние устройства ПК Защита информации
Защита информации CQRS in a nutshell
CQRS in a nutshell Уровни системы формирования информационной безопасности
Уровни системы формирования информационной безопасности Представление информации в различных системах счисления
Представление информации в различных системах счисления Презентация "Социальные сети" - скачать презентации по Информатике
Презентация "Социальные сети" - скачать презентации по Информатике Разбор задач 3-го этапа республиканской олимпиады по информатике 2018 года
Разбор задач 3-го этапа республиканской олимпиады по информатике 2018 года Проектирование баз данных. Анализ стоимости операций
Проектирование баз данных. Анализ стоимости операций Конкурс: Интерактивная мозаика Организатор: Pedsovet.su Автор: Бирбраер Аркадий Викторович Место работы, должность: МАОУ «Лицей №
Конкурс: Интерактивная мозаика Организатор: Pedsovet.su Автор: Бирбраер Аркадий Викторович Место работы, должность: МАОУ «Лицей №