- Процессоры. Базовая структура ЭВМ

Содержание
- 2. 2.1. Базовая структура ЭВМ Базовая структура ЭВМ может быть представлена состоя-щей из шести основных частей (Рис.1):
- 3. В данной структуре под средствами ввода подразумеваются клавиатура, мышка, джойстик, сканер; средства ввода звуковой, видео информации
- 4. 2.2. Основные характеристики ЭВМ В качестве основных характеристик ЭВМ обычно рассматривают: быстродействие и производительность емкость памяти,
- 5. Производительность является более универ-сальным показателем, чем быстродействие, пос-кольку явно зависит от порядка прохождения за-дач в ЭВМ
- 6. В список входят самые разнообразные прог-раммы, от игр, компиляторов и приложений баз данных до программ, осуществляющих
- 7. В каждом случае программа компилируется для тестируемого компьютера и измеряется реальное время её выполнения на тестируемом
- 8. Полное тестирование производится по всему списку тестовых приложений, а затем вычисляется среднее геометрическое резуль-татов по отдельным
- 9. На быстродействие и производительность влияет целая масса факторов, таких как тактовая частота процессора, пропускная способность интерфейсов,
- 10. Допустим, что для выполнения одной машинной команды требуется в среднем S шагов, а каждый шаг производится
- 11. Важно отметить, что параметры N, S, и R зависят друг от друга, изменение одного из них
- 12. 2.2. Представление данных Данные, с которыми оперирует ЭВМ – быва-ют следующих типов: числа, символы или строки
- 13. 2.2.1. Числа в форме с фиксированной точкой. Представление правильных дробей и целых чисел показано на рис.
- 14. 2.2.2. Числа в форме с плавающей точкой Форма представления с плавающей точкой, ещё называемая полулогарифмической, обеспе-чивает
- 16. Стандарт IEEE 754 для представления чисел с пла-вающей точкой в 32 – разрядном формате разработан и
- 18. Особенностью представления чисел в формате IEEE является следующее. Порядки смещены в область положительных чисел, могут принимать
- 21. Благодаря этому обеспечивается эффективная ши-рина мантиссы, равная 24 битам для одинарного и 53 битам – для
- 22. 2.2.3. Символы ЭВМ способны обрабатывать не только числа, но и текстовую информацию, состоящую из сим-волов. Под
- 23. Наиболее распространенными являются кодо-вые таблицы, в которых символы кодируются с помощью восьмиразрядных двоичных комби-наций (байтов), позволяющих
- 24. Стандартный код ASCII – 7-разрядный. В более поздней, европейской модификации ASCII (стан-дарт ISO 8859-1) используются все
- 25. 2.2.4. Логические значения Элементом логических данных является логическая (булева) переменная, которая принимает значения: «истина» или «ложь».
- 26. 2.3. Основные концепции функционирования На примере простейшего гипотетического компьютера (Рис.6) рассмотрим его состав и не-которые аспекты
- 28. Цикл процессора Цикл процессора - процесс обработки каждой команды, состоящий из двух этапов: выборка и исполнение.
- 29. Рис. 5.8. Структура цепей выборки команды
- 30. Последовательность выборки команды: • а) копируется адрес следующей команды из СчК в Регистр адреса памяти (РгАП)
- 31. Рис. 5.7. Взаимодействие блоков процессора при выполнении команды СЛОЖЕНИЕ. Исполнение команды Взаимодействие блоков процессора при выполнении
- 32. Для временного хранения машинной команды используется специальный регистр, содержимое которого интерпретируется как команда - Регистр Команды
- 33. • в) устройство управления инициирует чте-ние операнда из ячейки, адрес которой находит-ся в РгАП, и загрузку
- 35. В рассмотренном примере предполагается последовательное исполнение команд и пос-ледовательное исполнение отдельных этапов команд. Это так называемая
- 36. 1. SISD - Single Instruction Single Data (ОКОД - Одиночный поток Команд Одиночный поток Данных); без
- 37. 3. MISD - Multiple Instruction Single Data (МКОД - Множественный поток Команд Одиночный поток Данных); конвейерная
- 39. 2.4. Структуры АЛУ Арифметическая и логическая обработка дан-ных в ЭВМ возлагается на операционный блок, а точнее
- 40. Операционный блок, в свою очередь, может быть построен по схеме с закреплением микро-операций по регистрам либо
- 42. 2.5. CISC и RISC и другие процессоры В зависимости от набора и порядка выполнения команд процессоры
- 43. Перед разработчиками системного програм-много обеспечения и создателями аппаратуры компьютеров всегда стояла проблема определения количества и перечня
- 44. В то же время известно, что наиболее простой способ достижения высокой скорости выполнения программ заключается в
- 45. В итоге список команд типичного компьютера расширился от нескольких десятков до нескольких сотен. Благодаря этому удалось
- 46. Однако для микропроцессоров идеология CISC стала серьезным препятствием в повышении их быстродействия. Наиболее критическим фактором для
- 47. Проведённые в конце 70–х годов исследования были обобщены в виде правила «80/20», которое гласит, что в
- 48. Основные принципы RISC заключаются в следую-щем: 1. Любая операция, вне зависимости от ее типа, должна выполняться
- 49. RISC–процессоры обязательно должны иметь конвейеризованные арифметические устройства. Современные технологические возможности в сфере проектирования и производства БИС
- 50. Основные особенности современных RISC - процессоров: 1. Сокращенный набор команд (от 80 до 150 команд). 2.
- 51. Практически все современные RISC – процессоры • Являются 64-х разрядными и суперскаляр-ными (запускаются не менее 4-х
- 52. Одной из причин появления архитектуры RISC является относительная простота устройства управ-ления процессора. Однако по мере развития
- 53. Другой ветвью развития архитектуры RISC является архитектура VLIW (Very long instruction word, очень длинная машинная команда)
- 54. 2.6. Матричные процессоры Наиболее распространенными из систем, клас-са: один поток команд - множество - потоков данных
- 55. Таким образом, производительность сис-темы оказывается равной сумме производительностей всех процессорных элементов. Однако на практике, чтобы обеспечить
- 56. Рис. 2.1 Структура матричной вычислительной системы "SOLOMON" Одним из первых матричных процессоров был SОLОМОN (60-е годы).
- 57. Система SОLOМОN содержит 1024 процессорных элемента, соединены в виде матрицы: 32х32. Каждый процессорный элемент матрицы включает
- 58. Идея многомодальности заключается в том, что в каждом процессорном элементе имеется специальный регистр на 4 состояния
- 59. В других случаях процессорный элемент не выполняет операцию, но может, в зависимос-ти от кода, пересылать свои
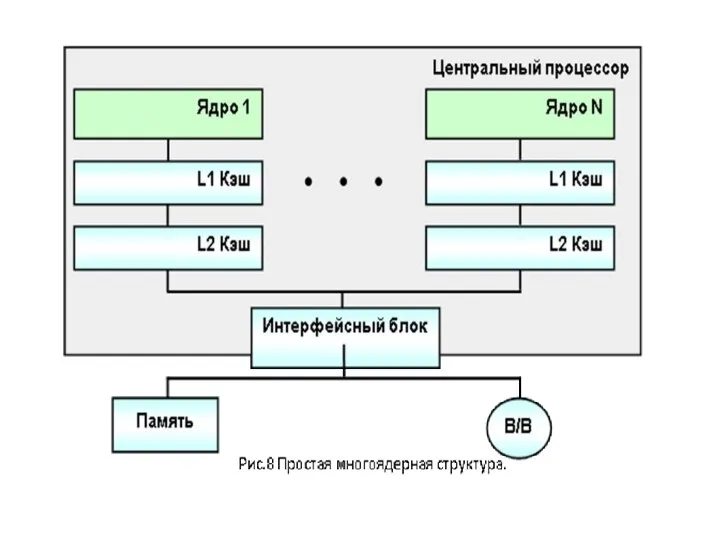
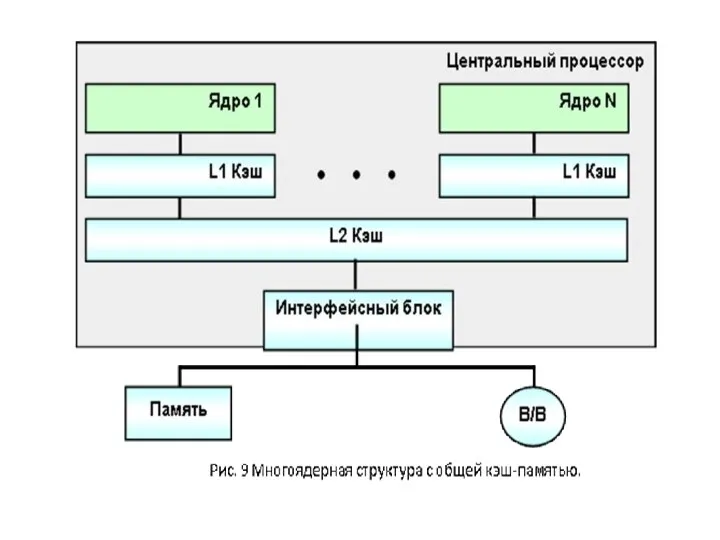
- 60. 2.7. Многоядерные процессоры Общее понятие о ядре процессора Если сам процессор — это мозг компьютера, то
- 61. • Блок декодирования — обрабатывает сигналы команд, определяет, что нужно сделать в данный момент, и нужны
- 65. Скачать презентацию
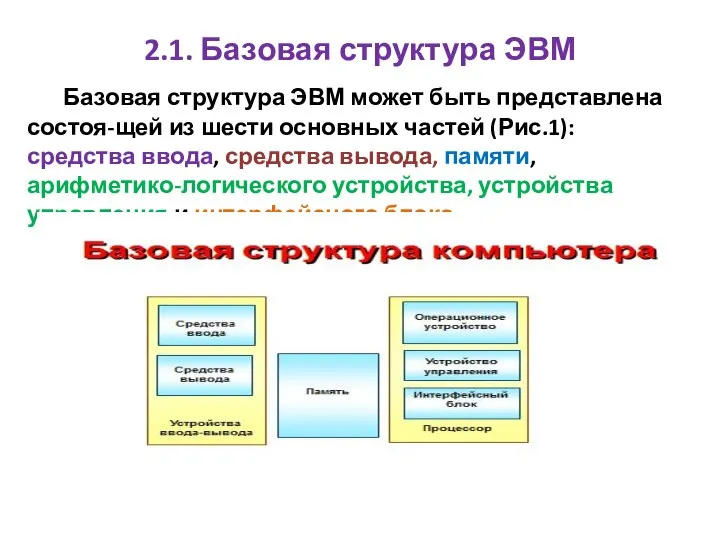
2.1. Базовая структура ЭВМ
Базовая структура ЭВМ может быть представлена состоя-щей
2.1. Базовая структура ЭВМ
Базовая структура ЭВМ может быть представлена состоя-щей

В данной структуре под средствами ввода подразумеваются клавиатура, мышка, джойстик,
В данной структуре под средствами ввода подразумеваются клавиатура, мышка, джойстик,

2.2. Основные характеристики ЭВМ
В качестве основных характеристик ЭВМ обычно рассматривают:
2.2. Основные характеристики ЭВМ
В качестве основных характеристик ЭВМ обычно рассматривают:

Производительность является более универ-сальным показателем, чем быстродействие, пос-кольку явно зависит
Производительность является более универ-сальным показателем, чем быстродействие, пос-кольку явно зависит

В список входят самые разнообразные прог-раммы, от игр, компиляторов и
В список входят самые разнообразные прог-раммы, от игр, компиляторов и

В каждом случае программа компилируется для тестируемого компьютера и измеряется
В каждом случае программа компилируется для тестируемого компьютера и измеряется

Полное тестирование производится по всему списку тестовых приложений, а затем
Полное тестирование производится по всему списку тестовых приложений, а затем

На быстродействие и производительность влияет целая масса факторов, таких как
На быстродействие и производительность влияет целая масса факторов, таких как

Допустим, что для выполнения одной машинной команды требуется в среднем
Допустим, что для выполнения одной машинной команды требуется в среднем

Важно отметить, что параметры N, S, и R зависят друг
Важно отметить, что параметры N, S, и R зависят друг

2.2. Представление данных
Данные, с которыми оперирует ЭВМ – быва-ют следующих
2.2. Представление данных
Данные, с которыми оперирует ЭВМ – быва-ют следующих
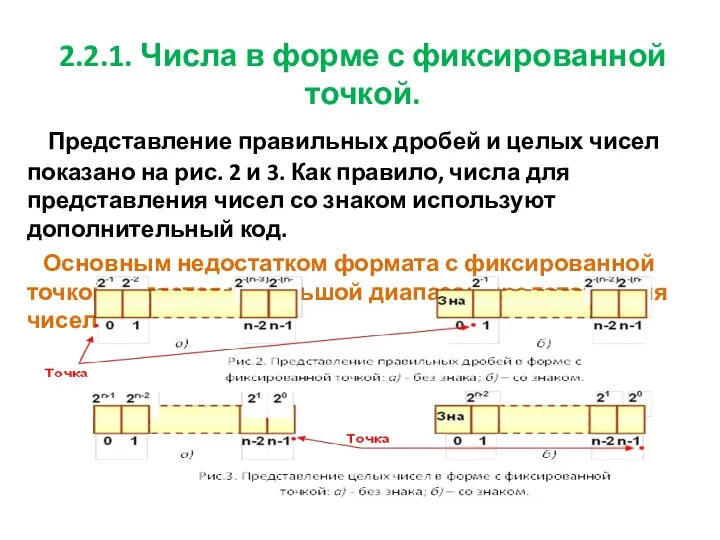
2.2.1. Числа в форме с фиксированной точкой.
Представление правильных дробей и
2.2.1. Числа в форме с фиксированной точкой.
Представление правильных дробей и

2.2.2. Числа в форме с плавающей точкой
Форма представления с плавающей
2.2.2. Числа в форме с плавающей точкой
Форма представления с плавающей
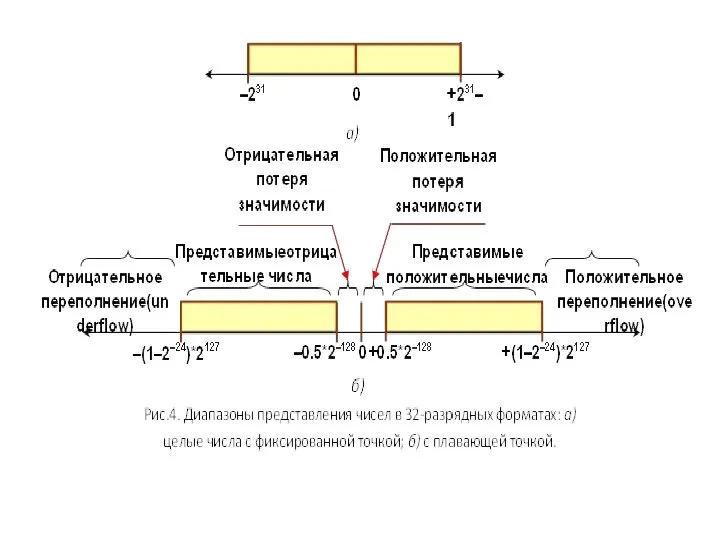

Стандарт IEEE 754 для представления чисел с пла-вающей точкой в
Стандарт IEEE 754 для представления чисел с пла-вающей точкой в
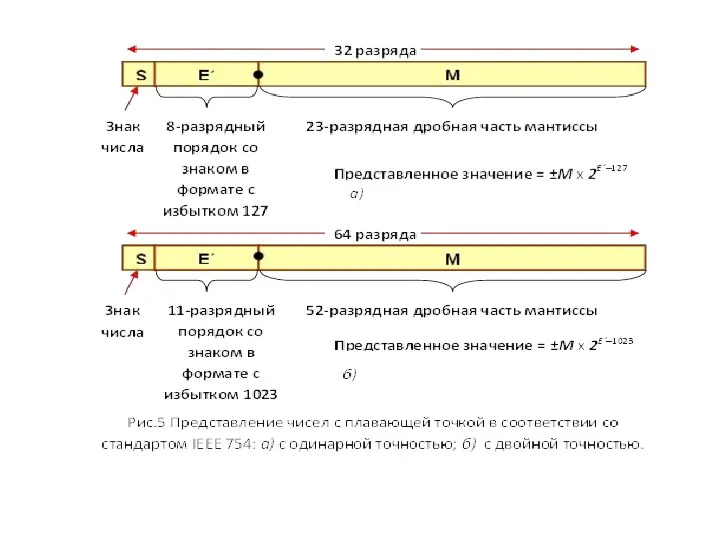

Особенностью представления чисел в формате IEEE является следующее. Порядки смещены
Особенностью представления чисел в формате IEEE является следующее. Порядки смещены
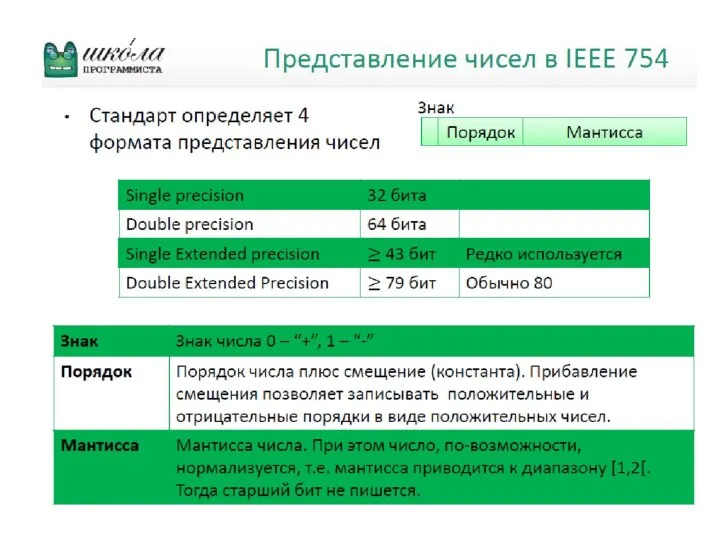
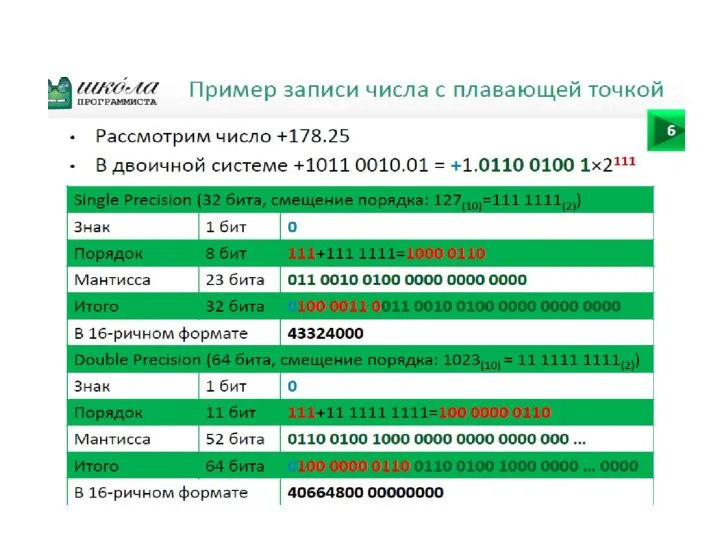

Благодаря этому обеспечивается эффективная ши-рина мантиссы, равная 24 битам для одинарного
Благодаря этому обеспечивается эффективная ши-рина мантиссы, равная 24 битам для одинарного

2.2.3. Символы
ЭВМ способны обрабатывать не только числа, но и текстовую
2.2.3. Символы
ЭВМ способны обрабатывать не только числа, но и текстовую

Наиболее распространенными являются кодо-вые таблицы, в которых символы кодируются с
Наиболее распространенными являются кодо-вые таблицы, в которых символы кодируются с

Стандартный код ASCII – 7-разрядный. В более поздней, европейской модификации
Стандартный код ASCII – 7-разрядный. В более поздней, европейской модификации

2.2.4. Логические значения
Элементом логических данных является логическая (булева) переменная, которая
2.2.4. Логические значения
Элементом логических данных является логическая (булева) переменная, которая

2.3. Основные концепции функционирования
На примере простейшего гипотетического компьютера (Рис.6) рассмотрим
2.3. Основные концепции функционирования
На примере простейшего гипотетического компьютера (Рис.6) рассмотрим

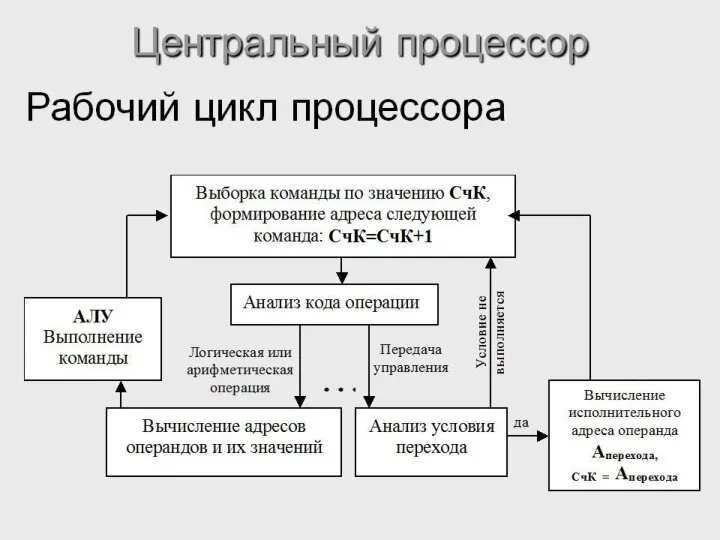
Цикл процессора
Цикл процессора - процесс обработки каждой команды, состоящий из
Цикл процессора
Цикл процессора - процесс обработки каждой команды, состоящий из
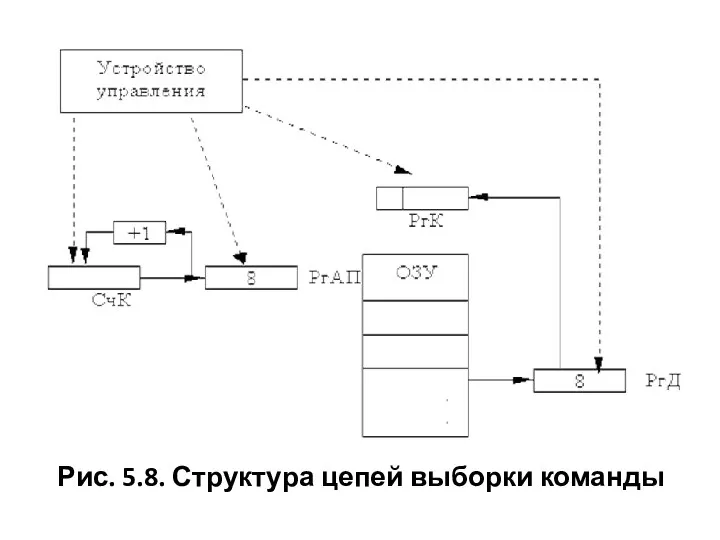
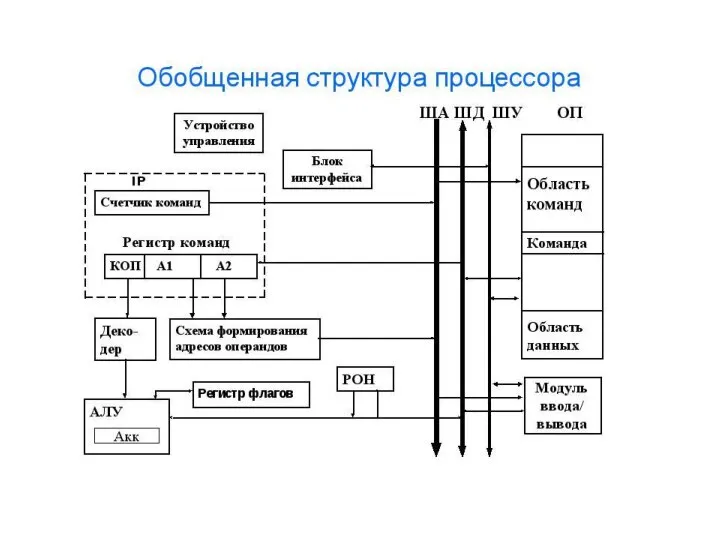
Рис. 5.8. Структура цепей выборки команды
Рис. 5.8. Структура цепей выборки команды

Последовательность выборки команды:
• а) копируется адрес следующей команды из СчК
Последовательность выборки команды:
• а) копируется адрес следующей команды из СчК
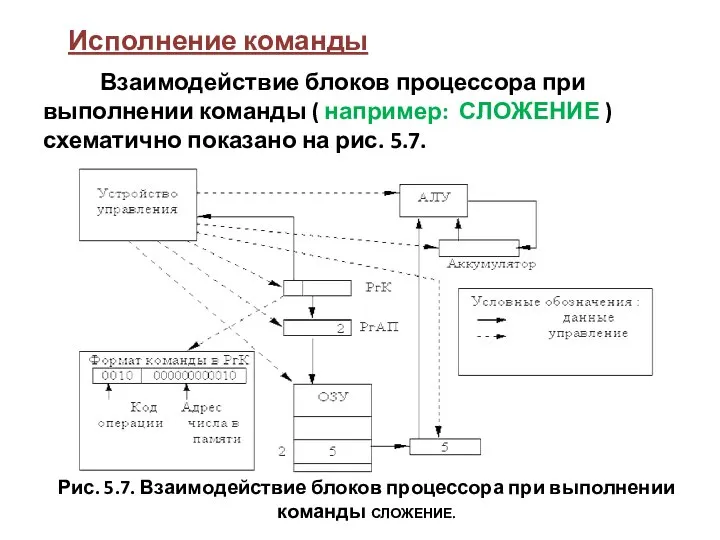
Рис. 5.7. Взаимодействие блоков процессора при выполнении команды СЛОЖЕНИЕ.
Исполнение команды
Рис. 5.7. Взаимодействие блоков процессора при выполнении команды СЛОЖЕНИЕ.
Исполнение команды

Для временного хранения машинной команды используется специальный регистр, содержимое которого
Для временного хранения машинной команды используется специальный регистр, содержимое которого

• в) устройство управления инициирует чте-ние операнда из ячейки, адрес которой
• в) устройство управления инициирует чте-ние операнда из ячейки, адрес которой

В рассмотренном примере предполагается последовательное исполнение команд и пос-ледовательное исполнение
В рассмотренном примере предполагается последовательное исполнение команд и пос-ледовательное исполнение

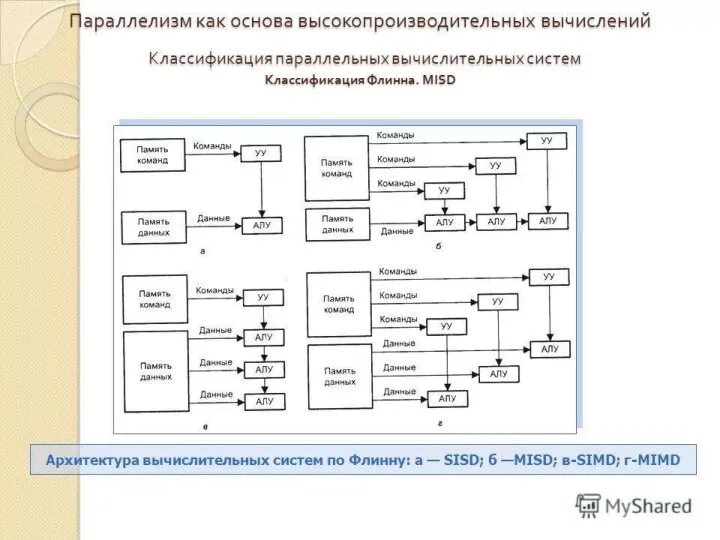
1. SISD - Single Instruction Single Data (ОКОД - Одиночный поток
1. SISD - Single Instruction Single Data (ОКОД - Одиночный поток

3. MISD - Multiple Instruction Single Data (МКОД - Множественный поток
3. MISD - Multiple Instruction Single Data (МКОД - Множественный поток

2.4. Структуры АЛУ
Арифметическая и логическая обработка дан-ных в ЭВМ возлагается
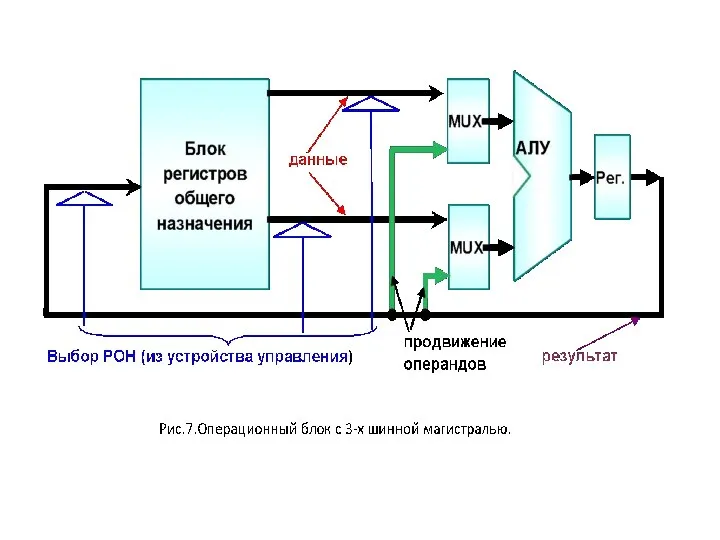
2.4. Структуры АЛУ
Арифметическая и логическая обработка дан-ных в ЭВМ возлагается

Операционный блок, в свою очередь, может быть построен по схеме
Операционный блок, в свою очередь, может быть построен по схеме

2.5. CISC и RISC и другие процессоры
В зависимости от набора
2.5. CISC и RISC и другие процессоры
В зависимости от набора

Перед разработчиками системного програм-много обеспечения и создателями аппаратуры компьютеров всегда
Перед разработчиками системного програм-много обеспечения и создателями аппаратуры компьютеров всегда

В то же время известно, что наиболее простой способ достижения высокой
В то же время известно, что наиболее простой способ достижения высокой

В итоге список команд типичного компьютера расширился от нескольких десятков
В итоге список команд типичного компьютера расширился от нескольких десятков

Однако для микропроцессоров идеология CISC стала серьезным препятствием в повышении
Однако для микропроцессоров идеология CISC стала серьезным препятствием в повышении

Проведённые в конце 70–х годов исследования были обобщены в виде
Проведённые в конце 70–х годов исследования были обобщены в виде

Основные принципы RISC заключаются в следую-щем:
1. Любая операция, вне зависимости от
Основные принципы RISC заключаются в следую-щем:
1. Любая операция, вне зависимости от

RISC–процессоры обязательно должны иметь конвейеризованные арифметические устройства.
Современные технологические возможности
RISC–процессоры обязательно должны иметь конвейеризованные арифметические устройства.
Современные технологические возможности

Основные особенности современных RISC - процессоров:
1. Сокращенный набор команд (от
Основные особенности современных RISC - процессоров:
1. Сокращенный набор команд (от

Практически все современные RISC – процессоры
• Являются 64-х разрядными и
Практически все современные RISC – процессоры
• Являются 64-х разрядными и

Одной из причин появления архитектуры RISC является относительная простота устройства
Одной из причин появления архитектуры RISC является относительная простота устройства

Другой ветвью развития архитектуры RISC является архитектура VLIW (Very long
Другой ветвью развития архитектуры RISC является архитектура VLIW (Very long

2.6. Матричные процессоры
Наиболее распространенными из систем, клас-са: один поток команд
2.6. Матричные процессоры
Наиболее распространенными из систем, клас-са: один поток команд

Таким образом, производительность сис-темы оказывается равной
сумме производительностей всех процессорных
Таким образом, производительность сис-темы оказывается равной
сумме производительностей всех процессорных
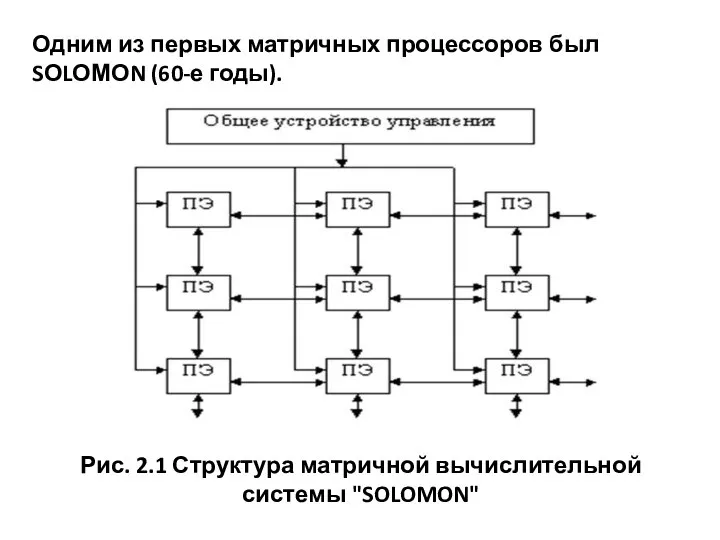
Рис. 2.1 Структура матричной вычислительной системы "SOLOMON"
Одним из первых матричных процессоров
Рис. 2.1 Структура матричной вычислительной системы "SOLOMON"
Одним из первых матричных процессоров

Система SОLOМОN содержит 1024 процессорных элемента, соединены в виде матрицы:
Система SОLOМОN содержит 1024 процессорных элемента, соединены в виде матрицы:

Идея многомодальности заключается в том, что в каждом процессорном элементе
Идея многомодальности заключается в том, что в каждом процессорном элементе

В других случаях процессорный элемент не выполняет операцию, но может,
В других случаях процессорный элемент не выполняет операцию, но может,

2.7. Многоядерные процессоры
Общее понятие о ядре процессора
Если сам процессор —
2.7. Многоядерные процессоры
Общее понятие о ядре процессора
Если сам процессор —

• Блок декодирования — обрабатывает сигналы команд, определяет, что нужно сделать в
• Блок декодирования — обрабатывает сигналы команд, определяет, что нужно сделать в
 Выбор варианта застройки территории с использованием концепции наиболее эффективного использования
Выбор варианта застройки территории с использованием концепции наиболее эффективного использования Основы православной культуры. Христианская семья. Венчание
Основы православной культуры. Христианская семья. Венчание Фотолитография в микроэлектронике при производстве ее основных изделий
Фотолитография в микроэлектронике при производстве ее основных изделий Технология точения древесины на токарном станке
Технология точения древесины на токарном станке POST _call-center_районы
POST _call-center_районы Региональный инжиниринговый центр. Макетирование и прототипирование
Региональный инжиниринговый центр. Макетирование и прототипирование Презентация Microsoft PowerPoint
Презентация Microsoft PowerPoint Проведение капитального ремонта магистрального нефтепровода
Проведение капитального ремонта магистрального нефтепровода МДКП
МДКП Формирование позитивного образа Я у детей старшего дошкольного возраста с помощью игр
Формирование позитивного образа Я у детей старшего дошкольного возраста с помощью игр Презентация Microsoft PowerPoint
Презентация Microsoft PowerPoint Концепция новогоднего оформления Ярославля к новому 2019 году
Концепция новогоднего оформления Ярославля к новому 2019 году С 23 февраля
С 23 февраля Прогнозирование изменения числа абонентов операторов сотовой связи
Прогнозирование изменения числа абонентов операторов сотовой связи Мои домашние животные
Мои домашние животные Сингапур презентация
Сингапур презентация diktant_advansd_6
diktant_advansd_6 Стратегия выживания в старших классах современной школы
Стратегия выживания в старших классах современной школы Кипрский конфликт: истоки возникновения, современное состояние, перспективы разрешения
Кипрский конфликт: истоки возникновения, современное состояние, перспективы разрешения Свойства ткани
Свойства ткани лето 2020
лето 2020 Победим коронавирус вместе. Антикризисное предложение
Победим коронавирус вместе. Антикризисное предложение Концепт празднвания дня гор. Ставрополь_ос по финалу концепта
Концепт празднвания дня гор. Ставрополь_ос по финалу концепта В. И. Даль Пословицы русского народа
В. И. Даль Пословицы русского народа А знаете ли вы? Викторина, посвященная Дню города Мурманска
А знаете ли вы? Викторина, посвященная Дню города Мурманска Святые равноапостольные Кирилл и Мефодий
Святые равноапостольные Кирилл и Мефодий 2 урок немецкий
2 урок немецкий Нарезание наружной и внутренней резьбы. Урок технологии. 7 класс
Нарезание наружной и внутренней резьбы. Урок технологии. 7 класс