- Доступ к данным в БД Основные концепции. Особенности СУБД Oracle

Содержание
- 2. Способы доступа к данным в БД Основные способы доступа к данным: Последовательная обработка области БД. Областью
- 3. Индексирование данных Определим индексирование как способ доступа к данным в реляционной таблице с помощью специальной структуры
- 4. Индексирование данных Особенности организации индексов: Индекс обычно хранится в отдельном файле или отдельной области памяти. Пустые
- 5. Индексирование данных Индексы бывают: Первичные (уникальные) и вторичные (неуникальные). Большинство СУБД автоматически строят индекс по первичному
- 6. Индексирование данных: составные индексы Составной индекс включает два или более столбца одной таблицы. Последовательность вхождения столбцов
- 7. Многоуровневые индексы: В-дерево B-дерево строится динамически по мере заполнения базы данными. Оно растёт вверх, и корневая
- 8. Многоуровневые индексы: В-дерево
- 9. Многоуровневые индексы: Oracle
- 10. Многоуровневые индексы: Oracle Перераспределение данных:
- 11. Многоуровневые индексы Структура B-дерева имеет следующие преимущества: B-дерево автоматически поддерживается в сбалансированном виде. Все блоки-листья в
- 12. Использование индексов Синтаксис команды create index следующий: create index on ( [, ,...]) [ ]; Имя
- 13. Использование индексов Выбор столбцов для индекса определяется следующими соображениями: В первую очередь выбираются столбцы, которые часто
- 14. Использование индексов В некоторых случаях использование составного индекса предпочтительнее, чем одиночного, а именно: Если в запросах
- 15. Использование индексов Необходимое условие использования индекса: в запросе есть условие на значение индексируемого поля. Достаточное условие
- 16. Использование индексов в Oracle Рекомендации по созданию эффективных индексов в базе данных Oracle: Индекс имеет смысл,
- 17. Использование индексов в Oracle Рекомендации по созданию эффективных индексов в базе данных Oracle: Индексируйте столбцы, участвующие
- 18. Битовые индексы Oracle Битовые индексы (BITMAP) используют битовые карты для указания значения индексированного столбца. Это идеальный
- 19. Битовые индексы Oracle Для создания битового индекса используется оператор^ CREATE BITMAP INDEX day_ind ON tab(day) TABLESPACE
- 20. Индексы Oracle с реверсированным ключом Индексы с реверсированным ключом – это, по сути, то же самое,
- 21. Индексы Oracle со сжатым ключом Сэкономить пространство хранения индекса вместе с повышением производительности можно за счет
- 22. Индексы Oracle на основе функций Индексы на основе функций предварительно вычисляют значения функций по заданному столбцы
- 23. Невидимые индексы Oracle Невидимый индекс оптимизатором не обнаруживается и не принимается во внимание при создании плана
- 25. Скачать презентацию

Способы доступа к данным в БД
Основные способы доступа к данным:
Последовательная
Способы доступа к данным в БД
Основные способы доступа к данным:
Последовательная

Индексирование данных
Определим индексирование как способ доступа к данным в реляционной таблице
Индексирование данных
Определим индексирование как способ доступа к данным в реляционной таблице

Индексирование данных
Особенности организации индексов:
Индекс обычно хранится в отдельном файле
Индексирование данных
Особенности организации индексов:
Индекс обычно хранится в отдельном файле

Индексирование данных
Индексы бывают:
Первичные (уникальные) и вторичные (неуникальные).
Большинство СУБД автоматически строят
Индексирование данных
Индексы бывают:
Первичные (уникальные) и вторичные (неуникальные).
Большинство СУБД автоматически строят
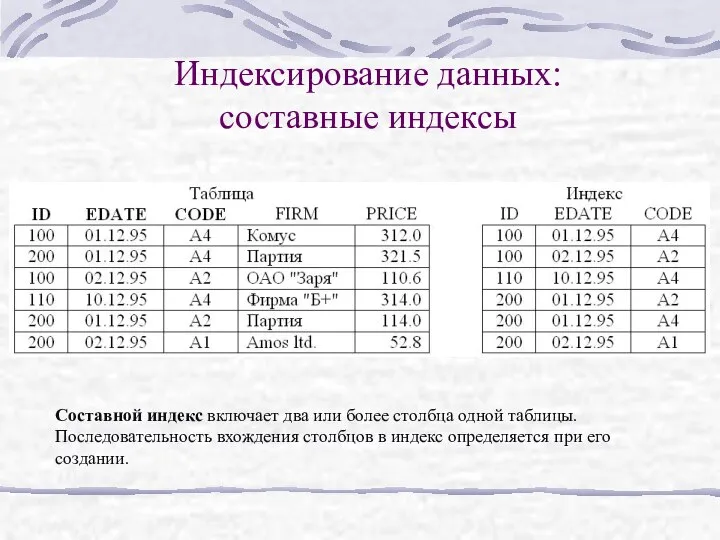
Индексирование данных: составные индексы
Составной индекс включает два или более столбца одной
Индексирование данных: составные индексы
Составной индекс включает два или более столбца одной

Многоуровневые индексы: В-дерево
B-дерево строится динамически по мере заполнения базы данными. Оно
Многоуровневые индексы: В-дерево
B-дерево строится динамически по мере заполнения базы данными. Оно
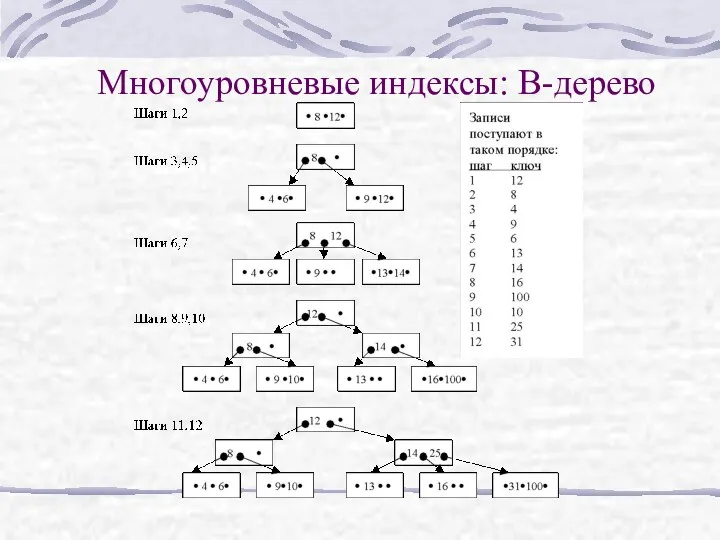
Многоуровневые индексы: В-дерево
Многоуровневые индексы: В-дерево
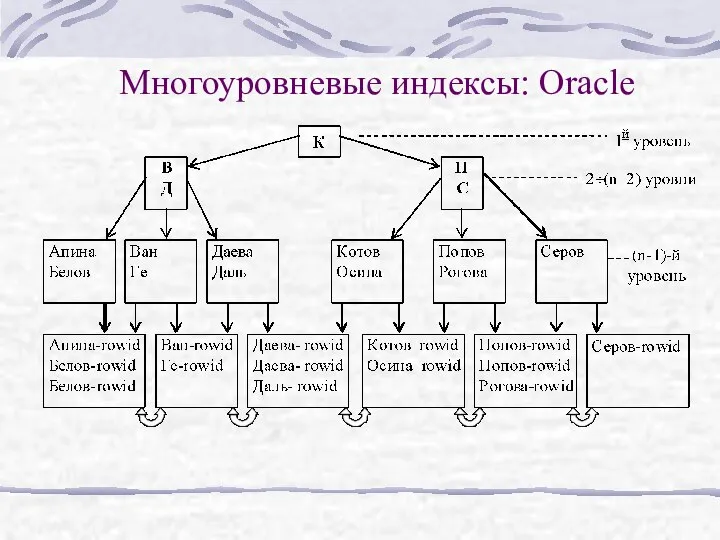
Многоуровневые индексы: Oracle
Многоуровневые индексы: Oracle
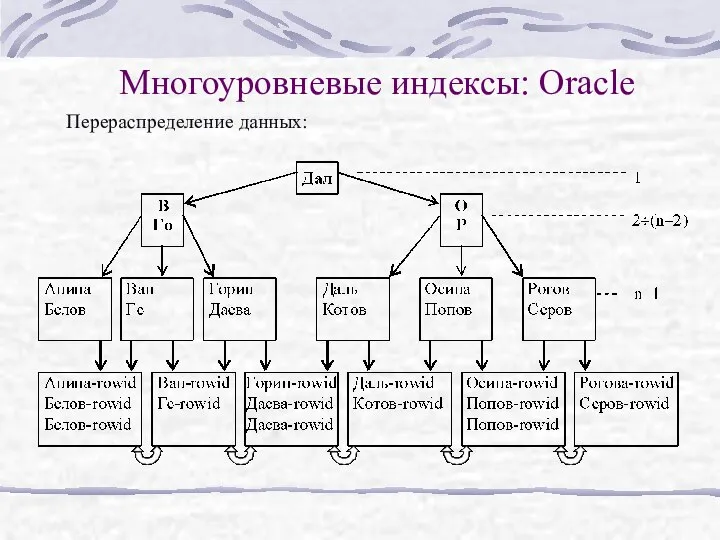
Многоуровневые индексы: Oracle
Перераспределение данных:
Многоуровневые индексы: Oracle
Перераспределение данных:

Многоуровневые индексы
Структура B-дерева имеет следующие преимущества:
B-дерево автоматически поддерживается в сбалансированном виде.
Все
Многоуровневые индексы
Структура B-дерева имеет следующие преимущества:
B-дерево автоматически поддерживается в сбалансированном виде.
Все

Использование индексов
Синтаксис команды create index следующий:
create index <имя_индекса>
on <имя_таблицы>(<поле1> [, <поле2>,...])
[<параметры>];
Имя
Использование индексов
Синтаксис команды create index следующий:
create index <имя_индекса>
on <имя_таблицы>(<поле1> [, <поле2>,...])
[<параметры>];
Имя

Использование индексов
Выбор столбцов для индекса определяется следующими соображениями:
В первую очередь
Использование индексов
Выбор столбцов для индекса определяется следующими соображениями:
В первую очередь

Использование индексов
В некоторых случаях использование составного индекса предпочтительнее, чем одиночного, а
Использование индексов
В некоторых случаях использование составного индекса предпочтительнее, чем одиночного, а

Использование индексов
Необходимое условие использования индекса: в запросе есть условие на значение
Использование индексов
Необходимое условие использования индекса: в запросе есть условие на значение

Использование индексов в Oracle
Рекомендации по созданию эффективных индексов в базе данных
Использование индексов в Oracle
Рекомендации по созданию эффективных индексов в базе данных

Использование индексов в Oracle
Рекомендации по созданию эффективных индексов в базе данных
Использование индексов в Oracle
Рекомендации по созданию эффективных индексов в базе данных
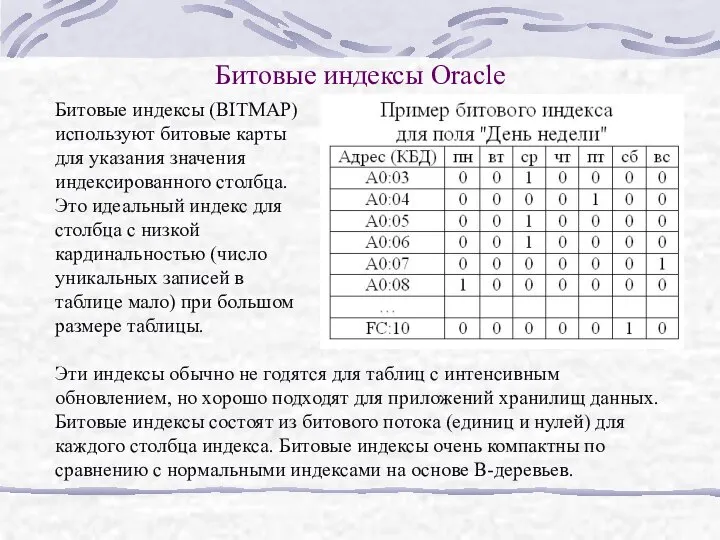
Битовые индексы Oracle
Битовые индексы (BITMAP) используют битовые карты для указания
Битовые индексы Oracle
Битовые индексы (BITMAP) используют битовые карты для указания

Битовые индексы Oracle
Для создания битового индекса используется оператор^
CREATE BITMAP INDEX
Битовые индексы Oracle
Для создания битового индекса используется оператор^ CREATE BITMAP INDEX

Индексы Oracle с реверсированным ключом
Индексы с реверсированным ключом – это, по
Индексы Oracle с реверсированным ключом
Индексы с реверсированным ключом – это, по

Индексы Oracle со сжатым ключом
Сэкономить пространство хранения индекса вместе с повышением
Индексы Oracle со сжатым ключом
Сэкономить пространство хранения индекса вместе с повышением

Индексы Oracle на основе функций
Индексы на основе функций предварительно вычисляют значения
Индексы Oracle на основе функций
Индексы на основе функций предварительно вычисляют значения

Невидимые индексы Oracle
Невидимый индекс оптимизатором не обнаруживается и не принимается во
Невидимые индексы Oracle
Невидимый индекс оптимизатором не обнаруживается и не принимается во
 Фай В.С. ЛААГ. Презентація до лекції № 2
Фай В.С. ЛААГ. Презентація до лекції № 2 Важные шаги к эффективному регулированию банков
Важные шаги к эффективному регулированию банков Вступний корективний курс німецької мови. Місце німецької мови в сім’ї індоєвропейських мов
Вступний корективний курс німецької мови. Місце німецької мови в сім’ї індоєвропейських мов Государственные должности и государственные служащие
Государственные должности и государственные служащие Улучшение условий труда электромонтажника ООО "Стройком" при монтаже электропроводки в стоящемся доме
Улучшение условий труда электромонтажника ООО "Стройком" при монтаже электропроводки в стоящемся доме Правовая охрана изобретений Федина Юля
Правовая охрана изобретений Федина Юля from Cold War to Vietnam
from Cold War to Vietnam Система кровообращения Система кровообращения вместе с нервной системой объединяет все органы в единый организм
Система кровообращения Система кровообращения вместе с нервной системой объединяет все органы в единый организм  Программа для преобразования воксельной модели в полигональную
Программа для преобразования воксельной модели в полигональную ЗАЩИТИ СЕБЯ ОТ ТУБЕРКУЛЕЗА!
ЗАЩИТИ СЕБЯ ОТ ТУБЕРКУЛЕЗА!  ПРЕЗЕНТАЦИЯ К ЛЕКЦИЯМ по курсу ФИНАНСОВЫЙ МЕНЕДЖМЕНТ составитель: доц., к.т.н. Калашникова Т.В.
ПРЕЗЕНТАЦИЯ К ЛЕКЦИЯМ по курсу ФИНАНСОВЫЙ МЕНЕДЖМЕНТ составитель: доц., к.т.н. Калашникова Т.В.  З ЭКОЛОГИЧЕСКИЕ КАТАСТРОФЫ
З ЭКОЛОГИЧЕСКИЕ КАТАСТРОФЫ  Архитектура CPLD MAX3000A фирмы Altera
Архитектура CPLD MAX3000A фирмы Altera Информационный поиск Лидия Михайловна Пивоварова Системы понимания текста
Информационный поиск Лидия Михайловна Пивоварова Системы понимания текста Мемлекеттік тілде іс қағаз жүргізу
Мемлекеттік тілде іс қағаз жүргізу Falco: ganz oder gar nicht
Falco: ganz oder gar nicht HD Body Electrical. BCM's Function Comparison 1
HD Body Electrical. BCM's Function Comparison 1 Механизм газораспределения
Механизм газораспределения царство животных - презентация для начальной школы_
царство животных - презентация для начальной школы_ Очистка сточных вод предприятий. Зачем? 1.Защита окружающей среды 2.Уменьшение неприятного запаха от отходов 3.Уменьшение затрат на
Очистка сточных вод предприятий. Зачем? 1.Защита окружающей среды 2.Уменьшение неприятного запаха от отходов 3.Уменьшение затрат на  Тестирование безопасности компьютерной системы. Назначение тестирования безопасности. Виды уязвимостей
Тестирование безопасности компьютерной системы. Назначение тестирования безопасности. Виды уязвимостей Метрология и радиоизмерения
Метрология и радиоизмерения МОУ Большечерниговская СОШ №1 Есенова Комбатай Нуржаугановна учитель математики
МОУ Большечерниговская СОШ №1 Есенова Комбатай Нуржаугановна учитель математики Прямая. Прямые общего и частного положения
Прямая. Прямые общего и частного положения Профессии Классные часы по профориентации автор: Ширшонкова Елена Николаевна учитель географии МБОУ лицея № 10
Профессии Классные часы по профориентации автор: Ширшонкова Елена Николаевна учитель географии МБОУ лицея № 10  Оперативные данные
Оперативные данные геоинформатика
геоинформатика Основные понятия о точности и взаимозаменяемости
Основные понятия о точности и взаимозаменяемости