- Информационный поиск Лидия Михайловна Пивоварова Системы понимания текста

Содержание
- 2. Введение Информационный поиск – поиск в большой коллекции документов, удовлетворяющих потребности пользователя, сформулированной в виде короткого
- 3. Содержание Индексирование Модели информационного поиска Оценка информационного поиска Роль автоматической обработки текста в информационном поиске
- 4. Индексирование Поиск по большим коллекциям не может осуществляться в режиме реального времени. Для быстрого поиска коллекция
- 5. Структура индекса
- 6. Процесс индексирования Анализ структуры – выделение заголовков, абзацев и т.п.; удаление html-разметки и т.д; Токенизация –
- 7. Взвешивание В индексе хочется учитывать не только сам факт вхождения слова в документ, но и «вес»,
- 8. Закон Ципфа (Zipf) Произведение частоты термина f на его ранг r остается примерно постоянной величиной f
- 9. Принцип Луна (Luhn) Самые часто встречающиеся слова – не самые значимые!
- 10. Классический метод взвешивания: tf-idf tf – относительная частота слова в документе idf – обратная документальная частота
- 11. Содержание Индексирование Модели информационного поиска Оценка информационного поиска Роль автоматической обработки текста в информационном поиске
- 12. Булева модель Запрос: булево выражение: Ответ: Плюс: простота; минус: отсутствие ранжирование
- 13. Векторная модель Коллекция из n документов и m различных терминов представляется в виде матрицы mxn, где
- 14. Векторная модель Близость запроса к документу: косинусная мера близости
- 15. Вероятность вычисляется на основе теоремы Байеса: P(R) – вероятность того, что случайно выбранный из коллекции документ
- 16. Вероятностные модели Решающее правило заключается в максимизации следующей функции:
- 17. Содержание Индексирование Модели информационного поиска Оценка информационного поиска Роль автоматической обработки текста в информационном поиске
- 18. Оценка информационного поиска Полнота (recall): R = tp / (tp+fn) Точность (presicion): P = tp /
- 19. Содержание Индексирование Модели информационного поиска Оценка информационного поиска Роль автоматической обработки текста в информационном поиске
- 20. Уровни анализа языка Морфологический анализ – признан необходимым для информационного поиска, особенно для флективных языков (например,
- 22. Скачать презентацию

Введение
Информационный поиск – поиск в большой коллекции документов, удовлетворяющих потребности пользователя,
Введение
Информационный поиск – поиск в большой коллекции документов, удовлетворяющих потребности пользователя,

Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске

Индексирование
Поиск по большим коллекциям не может осуществляться в режиме реального времени.
Индексирование
Поиск по большим коллекциям не может осуществляться в режиме реального времени.

Структура индекса
Структура индекса

Процесс индексирования
Анализ структуры – выделение заголовков, абзацев и т.п.; удаление html-разметки
Процесс индексирования
Анализ структуры – выделение заголовков, абзацев и т.п.; удаление html-разметки

Взвешивание
В индексе хочется учитывать не только сам факт вхождения слова в
Взвешивание
В индексе хочется учитывать не только сам факт вхождения слова в
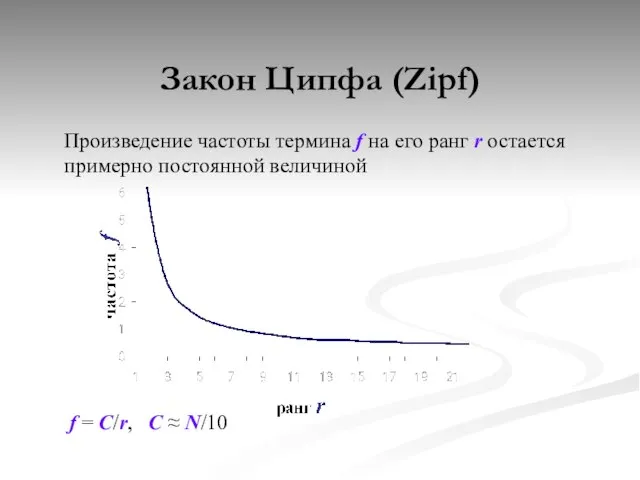
Закон Ципфа (Zipf)
Произведение частоты термина f на его ранг r остается
Закон Ципфа (Zipf)
Произведение частоты термина f на его ранг r остается
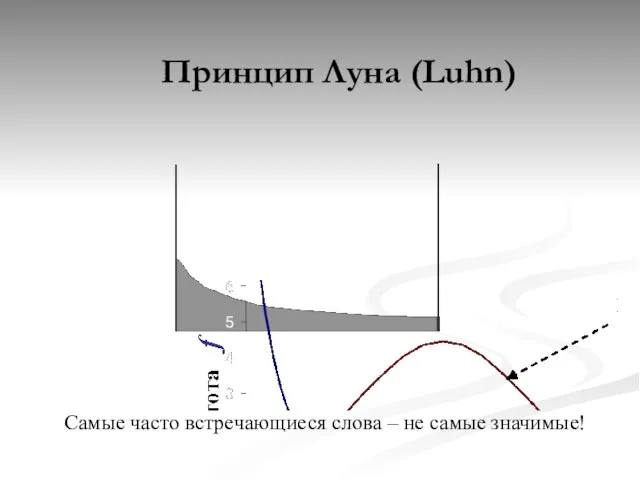
Принцип Луна (Luhn)
Самые часто встречающиеся слова – не самые значимые!
Принцип Луна (Luhn)
Самые часто встречающиеся слова – не самые значимые!

Классический метод взвешивания: tf-idf
tf – относительная частота слова в документе
idf –
Классический метод взвешивания: tf-idf
tf – относительная частота слова в документе
idf –

Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
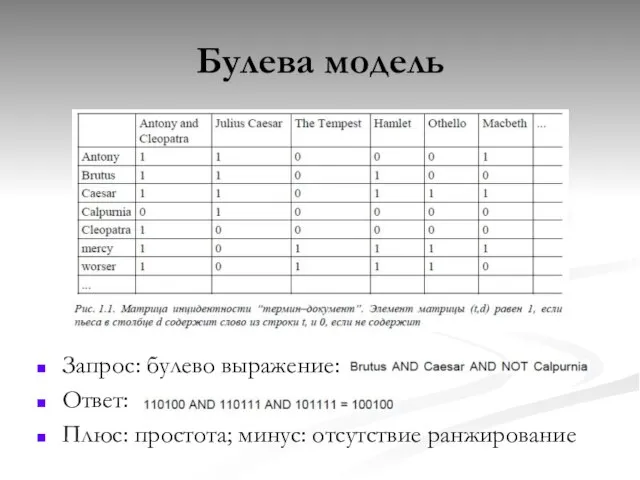
Булева модель
Запрос: булево выражение:
Ответ:
Плюс: простота; минус: отсутствие ранжирование
Булева модель
Запрос: булево выражение:
Ответ:
Плюс: простота; минус: отсутствие ранжирование

Векторная модель
Коллекция из n документов и m различных терминов представляется в
Векторная модель
Коллекция из n документов и m различных терминов представляется в
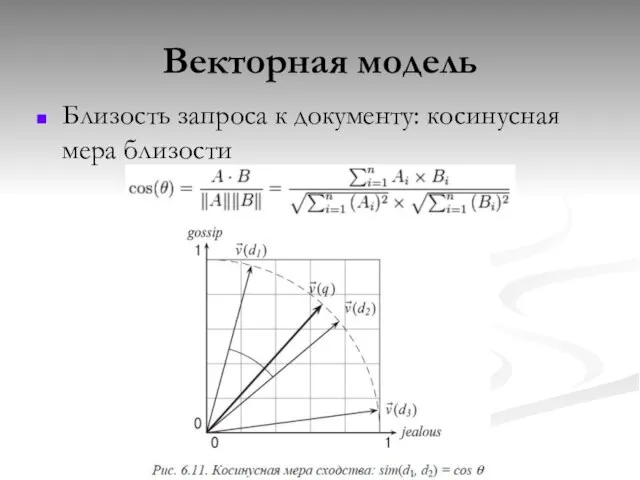
Векторная модель
Близость запроса к документу: косинусная мера близости
Векторная модель
Близость запроса к документу: косинусная мера близости

Вероятность вычисляется на основе теоремы Байеса:
P(R) – вероятность того, что случайно
Вероятность вычисляется на основе теоремы Байеса:
P(R) – вероятность того, что случайно

Вероятностные модели
Решающее правило заключается в максимизации следующей функции:
Вероятностные модели
Решающее правило заключается в максимизации следующей функции:

Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске

Оценка информационного поиска
Полнота (recall):
R = tp / (tp+fn)
Точность (presicion):
P = tp
Оценка информационного поиска
Полнота (recall):
R = tp / (tp+fn)
Точность (presicion):
P = tp

Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске

Уровни анализа языка
Морфологический анализ
– признан необходимым для информационного поиска, особенно
Уровни анализа языка
Морфологический анализ
– признан необходимым для информационного поиска, особенно
 风俗、语言、游戏、美食
风俗、语言、游戏、美食 Разработка технологического процесса механической обработки детали «Ось»
Разработка технологического процесса механической обработки детали «Ось» Проблема вытеснения традиционной культуры массовой Выполнили студенты 1курса ЮФ гр.Юб02\1402 Пацков Артём Голикова Анастасия
Проблема вытеснения традиционной культуры массовой Выполнили студенты 1курса ЮФ гр.Юб02\1402 Пацков Артём Голикова Анастасия  Электронды есептеуіш машиналардың аналогтық және цифрлық. Ақпаратты өңдеудің ақпараттық және бағдарламалық тәсілдері
Электронды есептеуіш машиналардың аналогтық және цифрлық. Ақпаратты өңдеудің ақпараттық және бағдарламалық тәсілдері Автономная некоммерческая организация высшего образования «Институт бизнеса и дизайна» Факультет дизайна и графики Кафед
Автономная некоммерческая организация высшего образования «Институт бизнеса и дизайна» Факультет дизайна и графики Кафед ЛЕКЦИЯ 13 ТЕМА 9 Макроэкономическая нестабильность. Экономические циклы и экономический рост. Лектор – д.э.н., профессор Дегтяре
ЛЕКЦИЯ 13 ТЕМА 9 Макроэкономическая нестабильность. Экономические циклы и экономический рост. Лектор – д.э.н., профессор Дегтяре Золотая осень –И. Левитан - Русская живопись.
Золотая осень –И. Левитан - Русская живопись. Презентация Содержание анализа финансовых инвестиций
Презентация Содержание анализа финансовых инвестиций Урок математики в 1 классе по теме «Число 0. Его получение и обозначение» Составила: учитель начальных классов, МОУ СОШ м-на Вы
Урок математики в 1 классе по теме «Число 0. Его получение и обозначение» Составила: учитель начальных классов, МОУ СОШ м-на Вы Мәңгілік ел ұлттық идея аясындағы болашақ мамандарды тәрбиелеу
Мәңгілік ел ұлттық идея аясындағы болашақ мамандарды тәрбиелеу Категорирование радиоэлектронной техники (РЭТ), проведение доработок и рекламационная работа
Категорирование радиоэлектронной техники (РЭТ), проведение доработок и рекламационная работа Подумаем!
Подумаем! Комбинаторные задачи
Комбинаторные задачи Introduction. Architecture et technologie des ordinateurs
Introduction. Architecture et technologie des ordinateurs Общая характеристика феодального государства и права.
Общая характеристика феодального государства и права. . Орфоэпия
. Орфоэпия Чернение. Чернь. Технологическая последовательность изготовления изделия с чернью. Подготовка изделия к покрытию чернью
Чернение. Чернь. Технологическая последовательность изготовления изделия с чернью. Подготовка изделия к покрытию чернью Стиль кантри. Эклектика
Стиль кантри. Эклектика Буддизм
Буддизм Дню снятия блокады Ленинграда посвящается
Дню снятия блокады Ленинграда посвящается Системы программирования. (Лекция 3)
Системы программирования. (Лекция 3) Военно-спортивная игра «Зарница»
Военно-спортивная игра «Зарница» Электронное декларирование Подготовила студентка 3 курса ФТД Омельченко Марина
Электронное декларирование Подготовила студентка 3 курса ФТД Омельченко Марина Формы и методы информационной войны в современных условиях
Формы и методы информационной войны в современных условиях Требования, предъявляемые к строительным конструкциям
Требования, предъявляемые к строительным конструкциям Введение в YouTube. Вводное занятие
Введение в YouTube. Вводное занятие Расчет погрешностей косвенных измерений
Расчет погрешностей косвенных измерений Презентация на тему: Путешествие в Санкт-Петербург
Презентация на тему: Путешествие в Санкт-Петербург