- Эффективное кодирование

Содержание
- 2. Эффективное кодирование решает задачу более компактной записи сообщений, вырабатываемых источником за счет их перекодировки. Применяется практически
- 3. Сжатие в большее число раз Применяется, если же не требуется восстановление информации «бит в бит» Например,
- 4. Кодирование – в широком смысле слова – это представление сообщений в форме, удобной для передачи по
- 5. ИИ – источник информации КИ – кодер источника КК –кодер канала М – модулятор ЛС –линия
- 6. Сообщению X на выходе источника информации (ИИ) необходимо поставить в соответствие определенный сигнал. Дискретные сообщения складываются
- 7. 1. Преобразовать информацию в такую систему символов (код), чтобы он обеспечивал.: простоту аппаратуры различения отдельных символов;
- 8. 2. Второй целью кодирования является на основании теорем Шеннона – согласование свойств источника сообщений со свойствами
- 9. в канале эффективное кодирование позволяет преобразовать входную информацию в последовательность символов, наилучшим образом подготовленную для дальнейшего
- 10. имеет целью обеспечить заданную достоверность при передаче или хранении информации путем дополнительного внесения избыточности, но уже
- 11. Если избыточность источника сообщений (ИС) и помехи в канале связи практически отсутствуют, то введение как КИ,
- 12. кодированный сигнал поступает в устройство кодирования символов сигналами – модулятор М. Получаемый на выходе модулятора сигнал
- 13. Устройство декодирования помехоустойчивого кода декодер канала ДК и устройство декодирования сообщений (декодер источника ДИ) выдают декодированное
- 14. При кодировании каждая буква исходного алфавита представляется различными последовательностями, состоящими из кодовых букв (цифр). Если исходный
- 15. достаточно пронумеровать буквы исходного алфавита и записать их коды как q - разрядные числа в k-ичной
- 16. Кроме двоичных кодов, наибольшее распространение получили восьмеричные коды. Например, необходимо закодировать алфавит, состоящий из 64 букв.
- 17. В любом реальном сигнале всегда присутствуют помехи. Однако, если их уровень настолько мал, что вероятность искажения
- 18. В этом случае среднее количество информации, переносимое одним символом, можно считать: J(Z; Y) = Hапр(Z) –
- 19. следовательно, пропускная способность дискретного канала без помех в единицах информации за единицу времени равна: Cy =
- 20. Если источник информации создает поток информации , Такой что, производительность источника информации равна пропускной способности канала
- 21. Согласно сформулированной теореме существует метод кодирования, позволяющий при: H(x) ≤ C – передавать всю информацию, вырабатываемую
- 22. если источник информации имеет энтропию H(X), то сообщения можно закодировать так, чтобы средняя длина кода lср
- 23. то есть при а = 2 (бит) и My = 2 {0; 1} имеем: где pi
- 24. Это следует из равенства: . Таким образом, lср выступает критерием эффективности кодирования. Чем ближе lср к
- 25. Это следует из равенства: (Производительность ист.=попускн.сп .к=макс.ск. Канала без помех=произ макс. скорости передачи сообщения на ср
- 26. Из этого же критерия следует, что если буквы имеют равномерное распределение вероятностей их употребления, то H(x)
- 27. В большинстве случаев буквы сообщений преобразуются в последовательности двоичных символов. Учитывая статистические свойства источника сообщений, можно
- 28. Шеннон доказал, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных
- 29. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся — кодом
- 30. Символы первичного алфавита m1 выписывают по убыванию вероятностей. Символы полученного алфавита делят на две части, суммарные
- 31. Наибольший эффект сжатия получается в случае, когда вероятности букв представляют собой целочисленные отрицательные степени двойки. Среднее
- 32. Методика Шеннона-Фэно Пример: В равномерном коде длина сообщения n=3 Среднее число двоичных символов кода Шеннона-Фано, приходящихся
- 33. Методика Шеннона-Фэно В равномерном коде длина сообщения n=3 22 Среднее число двоичных символов кода Шеннона-Фано, приходящихся
- 34. Условие эффективного кодирования: max H(Z): log2 m ≥ lср ≥ H(Z) + ε, но H(Z) Следовательно,
- 35. Рассмотрим сообщения, образованные с помощью алфавита, состоящего из 2-х букв Z1 и Z2 с вероятностями появления
- 36. В этом случае средняя длина кодового слова составляет: с =1,81 бит. На один символ алфавита источника
- 37. От указанного недостатка свободна методика Хаффмена. МХ гарантирует однозначное построение кода с наименьшей для данного распределения
- 38. Расположить символы исходного алфавита А в порядке убывания вероятности. Два наименее вероятных символа алфавита А будем
- 39. Припишем символам последнего алфавита кодовые обозначения 0 (например - верхнему) и 1 (в нашем примере –
- 40. Методика Хаффмена пример 1
- 41. Методика Хаффмена пример2
- 42. Методика Хаффмена пример 2
- 44. Скачать презентацию

Эффективное кодирование решает задачу более компактной записи сообщений, вырабатываемых источником за
Эффективное кодирование решает задачу более компактной записи сообщений, вырабатываемых источником за

Сжатие в большее число раз
Применяется, если же не требуется восстановление
Сжатие в большее число раз
Применяется, если же не требуется восстановление

Кодирование – в широком смысле слова – это представление сообщений в форме,
Кодирование – в широком смысле слова – это представление сообщений в форме,
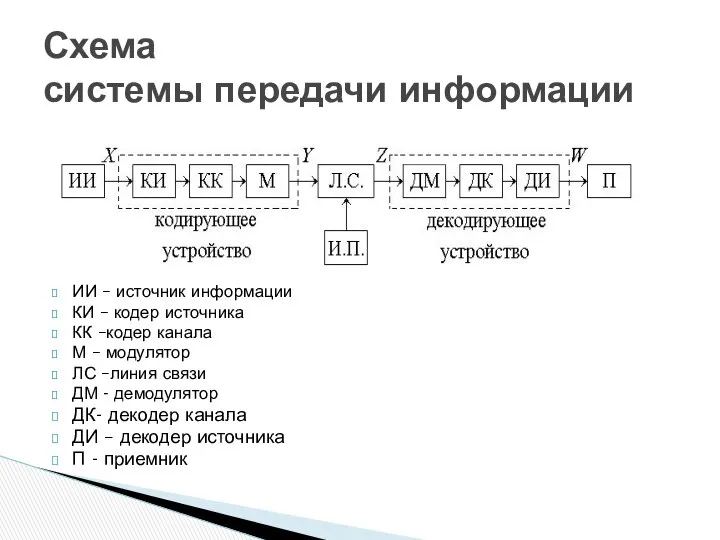
ИИ – источник информации
КИ – кодер источника
КК –кодер канала
М – модулятор
ЛС
ИИ – источник информации
КИ – кодер источника
КК –кодер канала
М – модулятор
ЛС

Сообщению X на выходе источника информации (ИИ) необходимо поставить в соответствие определенный сигнал.
Сообщению X на выходе источника информации (ИИ) необходимо поставить в соответствие определенный сигнал.

1. Преобразовать информацию в такую систему символов (код), чтобы он обеспечивал.:
простоту
1. Преобразовать информацию в такую систему символов (код), чтобы он обеспечивал.:
простоту

2. Второй целью кодирования является на основании теорем Шеннона – согласование
2. Второй целью кодирования является на основании теорем Шеннона – согласование

в канале эффективное кодирование позволяет преобразовать входную информацию в последовательность символов,
в канале эффективное кодирование позволяет преобразовать входную информацию в последовательность символов,

имеет целью обеспечить заданную достоверность при передаче или хранении информации путем
имеет целью обеспечить заданную достоверность при передаче или хранении информации путем

Если избыточность источника сообщений (ИС) и помехи в канале связи практически
Если избыточность источника сообщений (ИС) и помехи в канале связи практически

кодированный сигнал поступает в устройство кодирования символов сигналами – модулятор М.
кодированный сигнал поступает в устройство кодирования символов сигналами – модулятор М.

Устройство декодирования помехоустойчивого кода декодер канала ДК и
устройство декодирования сообщений
Устройство декодирования помехоустойчивого кода декодер канала ДК и
устройство декодирования сообщений

При кодировании каждая буква исходного алфавита представляется различными последовательностями, состоящими из
При кодировании каждая буква исходного алфавита представляется различными последовательностями, состоящими из

достаточно пронумеровать буквы исходного алфавита и записать их коды как q
достаточно пронумеровать буквы исходного алфавита и записать их коды как q

Кроме двоичных кодов, наибольшее распространение получили восьмеричные коды.
Например, необходимо закодировать
Кроме двоичных кодов, наибольшее распространение получили восьмеричные коды.
Например, необходимо закодировать

В любом реальном сигнале всегда присутствуют помехи.
Однако, если их уровень
Однако, если их уровень

В этом случае среднее количество информации, переносимое одним символом, можно считать:
J(Z; Y)
В этом случае среднее количество информации, переносимое одним символом, можно считать:
J(Z; Y)

следовательно, пропускная способность дискретного канала без помех в единицах информации за
следовательно, пропускная способность дискретного канала без помех в единицах информации за

Если источник информации создает поток информации
,
Такой что, производительность источника информации равна
Если источник информации создает поток информации
,
Такой что, производительность источника информации равна

Согласно сформулированной теореме существует метод кодирования, позволяющий при:
H(x) ≤ C – передавать всю
Согласно сформулированной теореме существует метод кодирования, позволяющий при:
H(x) ≤ C – передавать всю

если источник информации имеет энтропию H(X),
то сообщения можно закодировать так, чтобы
если источник информации имеет энтропию H(X),
то сообщения можно закодировать так, чтобы

то есть при а = 2 (бит) и My = 2 {0; 1} имеем:
где pi – вероятность
где pi – вероятность

Это следует из равенства:
.
Таким образом, lср выступает критерием эффективности кодирования. Чем ближе lср к H(x), тем
Это следует из равенства:
.
Таким образом, lср выступает критерием эффективности кодирования. Чем ближе lср к H(x), тем

Это следует из равенства:
(Производительность ист.=попускн.сп .к=макс.ск. Канала без помех=произ макс. скорости
Это следует из равенства:
(Производительность ист.=попускн.сп .к=макс.ск. Канала без помех=произ макс. скорости

Из этого же критерия следует, что если буквы имеют равномерное распределение
Из этого же критерия следует, что если буквы имеют равномерное распределение

В большинстве случаев буквы сообщений преобразуются в последовательности двоичных символов.
Учитывая статистические
В большинстве случаев буквы сообщений преобразуются в последовательности двоичных символов.
Учитывая статистические

Шеннон доказал, что сообщения, составленные из букв некоторого алфавита, можно закодировать
Шеннон доказал, что сообщения, составленные из букв некоторого алфавита, можно закодировать

Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей
Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей

Символы первичного алфавита m1 выписывают по убыванию вероятностей.
Символы полученного алфавита делят на
Символы первичного алфавита m1 выписывают по убыванию вероятностей.
Символы полученного алфавита делят на

Наибольший эффект сжатия получается в случае, когда вероятности букв представляют собой
Наибольший эффект сжатия получается в случае, когда вероятности букв представляют собой

Методика Шеннона-Фэно
Пример:
В равномерном коде длина сообщения n=3
Среднее число двоичных символов кода
Методика Шеннона-Фэно
Пример:
В равномерном коде длина сообщения n=3
Среднее число двоичных символов кода

Методика Шеннона-Фэно
В равномерном коде длина сообщения n=3
22<6<23,
Среднее число двоичных символов кода
Методика Шеннона-Фэно
В равномерном коде длина сообщения n=3
22<6<23,
Среднее число двоичных символов кода

Условие эффективного кодирования:
max H(Z): log2 m ≥ lср ≥ H(Z) + ε,
но H(Z) < lср.
Следовательно, некоторая избыточность в
Условие эффективного кодирования:
max H(Z): log2 m ≥ lср ≥ H(Z) + ε,
но H(Z) < lср.
Следовательно, некоторая избыточность в

Рассмотрим сообщения, образованные с помощью алфавита, состоящего из 2-х букв Z1 и Z2
с вероятностями
Рассмотрим сообщения, образованные с помощью алфавита, состоящего из 2-х букв Z1 и Z2
с вероятностями

В этом случае средняя длина кодового слова составляет:
с =1,81 бит.
В этом случае средняя длина кодового слова составляет:
с =1,81 бит.

От указанного недостатка свободна методика Хаффмена.
МХ гарантирует однозначное построение кода
От указанного недостатка свободна методика Хаффмена.
МХ гарантирует однозначное построение кода

Расположить символы исходного алфавита А в порядке убывания вероятности.
Два
Расположить символы исходного алфавита А в порядке убывания вероятности.
Два

Припишем символам последнего алфавита кодовые обозначения 0 (например - верхнему) и
Припишем символам последнего алфавита кодовые обозначения 0 (например - верхнему) и

Методика Хаффмена
пример 1
Методика Хаффмена
пример 1
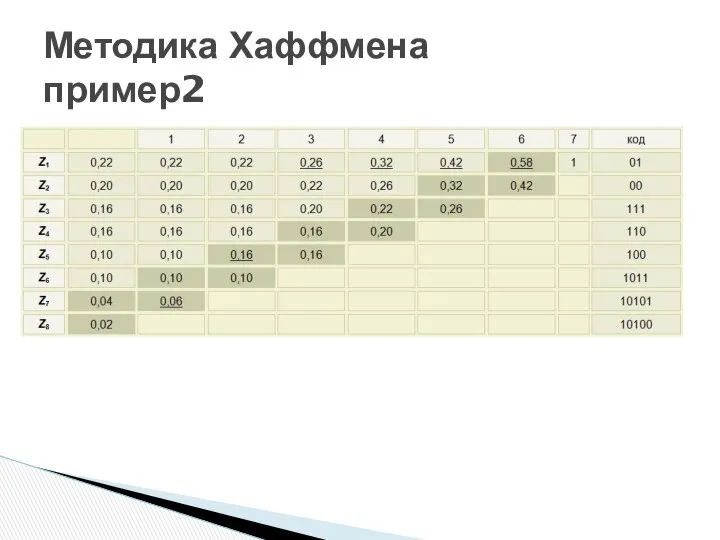
Методика Хаффмена
пример2
Методика Хаффмена
пример2
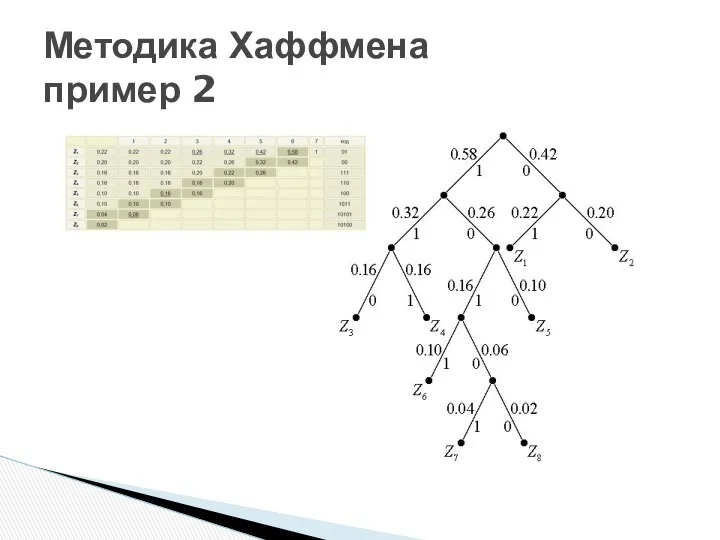
Методика Хаффмена
пример 2
Методика Хаффмена
пример 2
 Амосова Елена Сергеевна учитель начальных классов
Амосова Елена Сергеевна учитель начальных классов ИГА-2006 (Хирургическая стоматология)
ИГА-2006 (Хирургическая стоматология) Федор Иванович Буслаев
Федор Иванович Буслаев Методы оптимизации
Методы оптимизации Основные понятия о взаимозаменяемости и точности в машиностроении
Основные понятия о взаимозаменяемости и точности в машиностроении Тест по фонетике № 2. Введение в языкознание
Тест по фонетике № 2. Введение в языкознание Оценка качества управления
Оценка качества управления  Moderne kommunikations mittel
Moderne kommunikations mittel Principalele relaţii care se stabilesc între serviciile publice. (Capitolul 3)
Principalele relaţii care se stabilesc între serviciile publice. (Capitolul 3) Presentation on the topic. My idol in volleyball
Presentation on the topic. My idol in volleyball Открытая правовая школа при факультете права НИУ ВШЭ: адвокатура, нотариат, чоп, частные детективы. Тема 6
Открытая правовая школа при факультете права НИУ ВШЭ: адвокатура, нотариат, чоп, частные детективы. Тема 6 Методика развития двигательных качеств футболистов
Методика развития двигательных качеств футболистов Анализ судебной практики в сфере бюджетно-финансового регулирования
Анализ судебной практики в сфере бюджетно-финансового регулирования Культура епохи Відродження
Культура епохи Відродження Профайлинг. Камбоджа
Профайлинг. Камбоджа Производственная (учебно-организационная) практика
Производственная (учебно-организационная) практика Общие сведения о зубчатых передачах
Общие сведения о зубчатых передачах Презентация "Основные тренды на рынке производства печатной продукции" - скачать презентации по Экономике
Презентация "Основные тренды на рынке производства печатной продукции" - скачать презентации по Экономике Корейский. 길 찾기
Корейский. 길 찾기 МЕХАНИЗМЫ РЕГУЛЯЦИИ ДЫХАНИЯ
МЕХАНИЗМЫ РЕГУЛЯЦИИ ДЫХАНИЯ Информационная безопасность России в условиях глобального информационного общества. Законодательная база
Информационная безопасность России в условиях глобального информационного общества. Законодательная база Дом моды Зайцева
Дом моды Зайцева Стрепетов Григорий Михайловичгвардии лейтенант, командир роты 222 –го гвардейского стрелкового полка
Стрепетов Григорий Михайловичгвардии лейтенант, командир роты 222 –го гвардейского стрелкового полка Машинные команды
Машинные команды  Презентация на тему "Сахарный Диабет II типа" - скачать презентации по Медицине
Презентация на тему "Сахарный Диабет II типа" - скачать презентации по Медицине Празднование «Пасхи» в народных традициях, сохранённых российскими немцами из Евангелическо-лютеранской общины города Ухта
Празднование «Пасхи» в народных традициях, сохранённых российскими немцами из Евангелическо-лютеранской общины города Ухта Двигательная система, сенсорный отдел
Двигательная система, сенсорный отдел Классификация стен
Классификация стен