- Индексация данных

Содержание
- 2. Введение Цель применения индексации состоит в быстром поиске местоположения в большой структуре хранения, как при поиске
- 3. Принцип работы Для того чтобы найти определенный блок информации, сначала необходимо отыскать в индексе его ключ,
- 4. Любой бинарный алгоритм поиска в упорядоченном файле БД можно представить с помощью соответствующего бинарного дерева .Это
- 5. Неплотный индекс Пусть основной файл F упорядочен по полю ключа К. Построим дополнительный файл FD по
- 6. Плотный индекс .Он строится почти так же, как и неплотный индекс. Различие заключается в том, что
- 7. Поиск вначале выполняется в индексе для нахождения адреса блока основного файла, а за тем этот блок
- 8. Полученная структура называется В-деревом порядка т, где т – количество записей в блоке индекса. Такое дерево
- 9. Иногда удобно сконструировать индекс так, чтобы он указывал приблизительное, а не точное местоположение нужной информации. Например,
- 11. Скачать презентацию

Введение
Цель применения индексации состоит в быстром поиске местоположения в большой структуре
Введение
Цель применения индексации состоит в быстром поиске местоположения в большой структуре

Принцип работы
Для того чтобы найти определенный блок информации, сначала необходимо отыскать
Принцип работы
Для того чтобы найти определенный блок информации, сначала необходимо отыскать
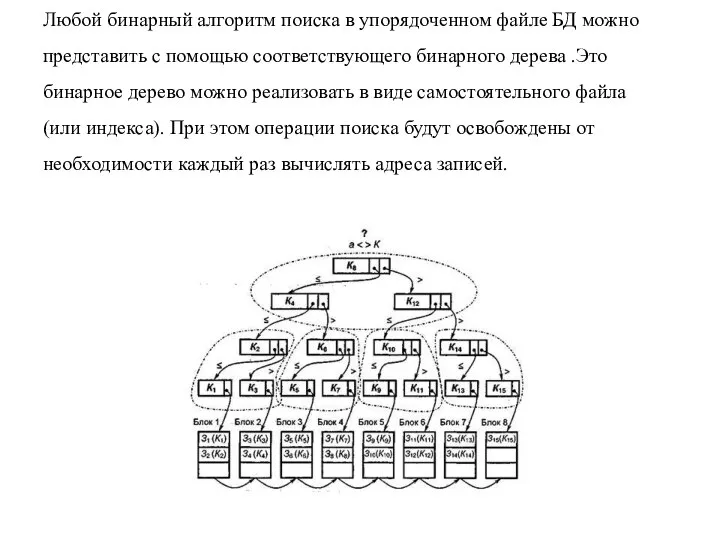
Любой бинарный алгоритм поиска в упорядоченном файле БД можно представить с
Любой бинарный алгоритм поиска в упорядоченном файле БД можно представить с

Неплотный индекс
Пусть основной файл F упорядочен по полю ключа К.
Неплотный индекс Пусть основной файл F упорядочен по полю ключа К.
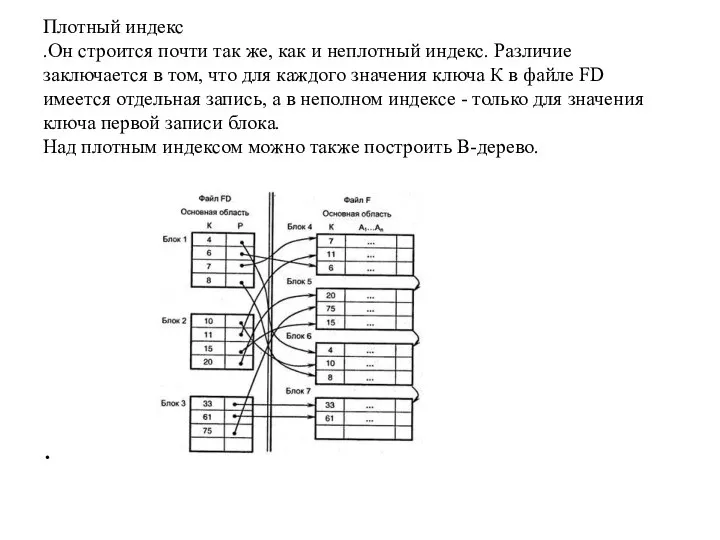
Плотный индекс
.Он строится почти так же, как и неплотный индекс.
Плотный индекс .Он строится почти так же, как и неплотный индекс.
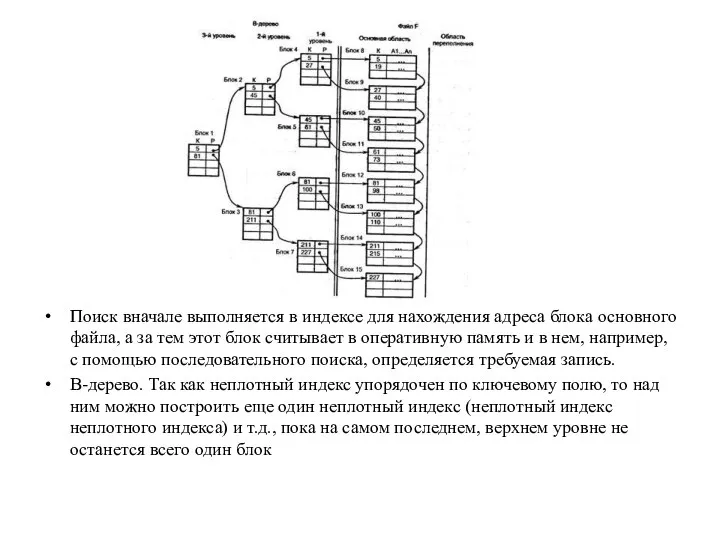
Поиск вначале выполняется в индексе для нахождения адреса блока основного файла,
Поиск вначале выполняется в индексе для нахождения адреса блока основного файла,

Полученная структура называется В-деревом порядка т, где т – количество записей
Полученная структура называется В-деревом порядка т, где т – количество записей
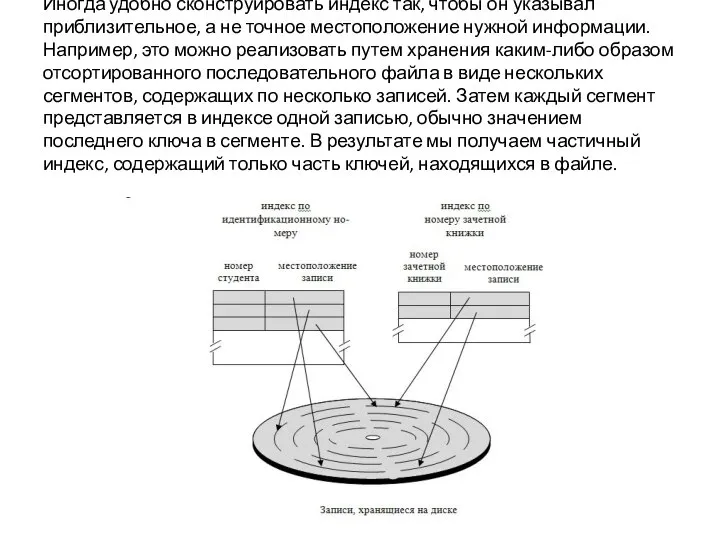
Иногда удобно сконструировать индекс так, чтобы он указывал приблизительное, а не
Иногда удобно сконструировать индекс так, чтобы он указывал приблизительное, а не
 Особенности стандартизации строительных материалов и изделий
Особенности стандартизации строительных материалов и изделий Спуск с горы на лыжах – техника выполнения
Спуск с горы на лыжах – техника выполнения Безопасность распределенных вычислительных систем в Интернет
Безопасность распределенных вычислительных систем в Интернет  . Актуальные вопросы
. Актуальные вопросы Презентация "Мэри Пикфорд" - скачать презентации по МХК
Презентация "Мэри Пикфорд" - скачать презентации по МХК Паразитарные заболевания у детей Гельминтозы
Паразитарные заболевания у детей Гельминтозы  Международная защита прав женщин и детей
Международная защита прав женщин и детей Мастер сухого строительства и штукатурных работ
Мастер сухого строительства и штукатурных работ Религия
Религия Художественная литература и история 1 урок литературы в 8 классе (по программе Г.С.Меркина) Подг
Художественная литература и история 1 урок литературы в 8 классе (по программе Г.С.Меркина) Подг ЯЗЫКОВЫЕ СРЕДСТВА ВЫРАЗИТЕЛЬНОСТИ В ПУБЛИЧНОЙ РЕЧИ
ЯЗЫКОВЫЕ СРЕДСТВА ВЫРАЗИТЕЛЬНОСТИ В ПУБЛИЧНОЙ РЕЧИ Экономическая сфера жизни общества
Экономическая сфера жизни общества  ASN.1 & BER
ASN.1 & BER Управление юридическими конфликтами. Переговоры и медиация
Управление юридическими конфликтами. Переговоры и медиация  Национализм как форма сознания
Национализм как форма сознания Ich habe eine frage
Ich habe eine frage Языки программирования
Языки программирования Балки
Балки ПИСАТЕЛЕ-ПРИРОДОВЕДЫ- ДЕТЯМ
ПИСАТЕЛЕ-ПРИРОДОВЕДЫ- ДЕТЯМ Альбом
Альбом ПУШНО-МЕХОВЫЕ ИЗДЕЛИЯ
ПУШНО-МЕХОВЫЕ ИЗДЕЛИЯ  Свой дом - свой простор
Свой дом - свой простор ВКР: Совершенствование системы управления деятельностью туристской фирмы ООО «Инсайт»
ВКР: Совершенствование системы управления деятельностью туристской фирмы ООО «Инсайт» Презентация "Искусство Индийского танца" - скачать презентации по МХК
Презентация "Искусство Индийского танца" - скачать презентации по МХК Презентация на тему "Медицинские пластыри" - скачать презентации по Медицине
Презентация на тему "Медицинские пластыри" - скачать презентации по Медицине Ökologie und umweltverträglichkeit
Ökologie und umweltverträglichkeit Терроризм. Виды террора
Терроризм. Виды террора Формирование фонетической системы немецкого языка. Лекция 3
Формирование фонетической системы немецкого языка. Лекция 3