- Основы языка SQL

Содержание
- 2. Первый стандарт по языку SQL вышел в США (1986 г.), что способствовало достижению совместимости разных СУБД.
- 3. Подавляющее большинство существующих СУБД поддерживают эти стандарты, однако с разной степенью соответствия. Здесь важно понимать, что
- 4. II. Язык запросов по образцу (QBE) Язык QBE (Query-By-Example) – это визуальное средство, которое помогает непрофессиональным
- 5. III. Возможности современного языка SQL a) Средства определения данных (DDL) b) Средства манипулирования данными (DML) VIEW
- 6. d) Средства административного управления е) Процедурные расширения языка DBAREA – область хранения данных GRANT – предоставить
- 7. IV. Создание таблиц БД с помощью языка SQL В простейшем виде команда CREATE TABLE имеет следующий
- 8. Элемент col_def обозначает определение отдельной колонки таблицы. col_def ::= { col_name data_type } [ DEFAULT const_expr
- 9. Современные СУБД позволяют обрабатывать данные разных типов: INT, SMALLINT — целые числа; NUMERIC, DECIMAL — числа
- 10. Необязательное ключевое слово DEFAULT определяет значение по умолчанию – const_expr. Это значение будет использовано, если при
- 11. а) Обязательные значения Это ограничение применяется в случае, если для некоторого столбца в каждой строке таблицы
- 12. b) Простой первичный ключ Определяется с помощью спецификатора PRIMARY KEY. Например: Object_ID INTEGER PRIMARY KEY При
- 13. c) Простой альтернативный ключ Иногда в дополнение к первичному ключу необходимо иметь альтернативные ключи, которые обеспечивают
- 14. d) Проверочные ограничения С помощью спецификатора CHECK(log_expr) можно задать ограниченный диапазон возможных значений для некоторого столбца.
- 15. e) Простой внешний ключ Объявляется в дочерней (подчиненной) таблице с помощью конструкции [ FOREIGN KEY ]
- 16. Ограничения на уровне всей таблицы В директиве CREATE TABLE такие ограничения объявляются с помощью синтаксического элемента
- 17. Объявление составного первичного или альтернативного ключа: FOREIGN KEY ( col_name [, …] ) REFERENCES ref_tab [
- 18. V. Выборка данных с помощью языка SQL Команда SELECT позволяет извлечь данные из одной или нескольких
- 19. В структуре этой мощной команды, которая имеет достаточно сложный синтаксис, можно выделить несколько основных разделов: SELECT
- 20. 1) Полное отображение таблицы SELECT * FROM 〈 имя_исх_таб 〉 Рассмотрим наиболее распространенные варианты применения команды
- 21. 3) Выборка записей по заданному условию В эти выражения обычно входят константы и названия полей (только
- 22. 4) Сортировка результатов запроса Кроме того, в условии отбора можно: SELECT 〈 список_столбцов 〉 FROM 〈
- 23. 5) Применение агрегатных (итоговых) функций При выборке данных из таблиц БД агрегатные функции позволяют произвести статистическую
- 24. Пример 1. Усреднение значений для заданного столбца: SELECT COUNT(*) FROM 〈 имя_исх_таб 〉 WHERE 〈 условия_отбора
- 25. 6) Запросы с группировкой Часто при анализе табличных данных требуется выполнить их группировку, т.е. сделать так,
- 26. В частности, любой элемент списка столбцов в разделе SELECT должен иметь единственное значение для каждой группы.
- 27. В разделе WHERE оператора SELECT может присутствовать вложенный запрос. Результат выполнения этого внутреннего запроса (подзапроса) передается
- 28. 8) Многотабличные запросы SELECT ФИО, Должность FROM ПРЕПОДАВАТЕЛИ WHERE Зарплата > ( SELECT AVG(Зарплата) FROM ПРЕПОДАВАТЕЛИ
- 29. В этом запросе для сокращенного обозначения таблиц используются их псевдонимы – а и b. Пример 1.
- 30. Эта конструкция применяется для соединения таблиц 〈left_tab〉 и 〈right_tab〉, причем условия 〈join_cond〉 для соединения строк переносятся
- 31. [ INNER ] JOIN — внутреннее соединение (применяется по умолчанию); LEFT [ OUTER ] JOIN —
- 33. Скачать презентацию

Первый стандарт по языку SQL вышел в США (1986 г.), что
Первый стандарт по языку SQL вышел в США (1986 г.), что

Подавляющее большинство существующих СУБД поддерживают эти стандарты, однако с разной степенью
Подавляющее большинство существующих СУБД поддерживают эти стандарты, однако с разной степенью

II. Язык запросов по образцу (QBE)
Язык QBE (Query-By-Example) – это визуальное
II. Язык запросов по образцу (QBE)
Язык QBE (Query-By-Example) – это визуальное

III. Возможности современного языка SQL
a) Средства определения данных (DDL)
b) Средства манипулирования
III. Возможности современного языка SQL
a) Средства определения данных (DDL)
b) Средства манипулирования

d) Средства административного управления
е) Процедурные расширения языка
DBAREA – область хранения данных
GRANT
d) Средства административного управления
е) Процедурные расширения языка
DBAREA – область хранения данных
GRANT
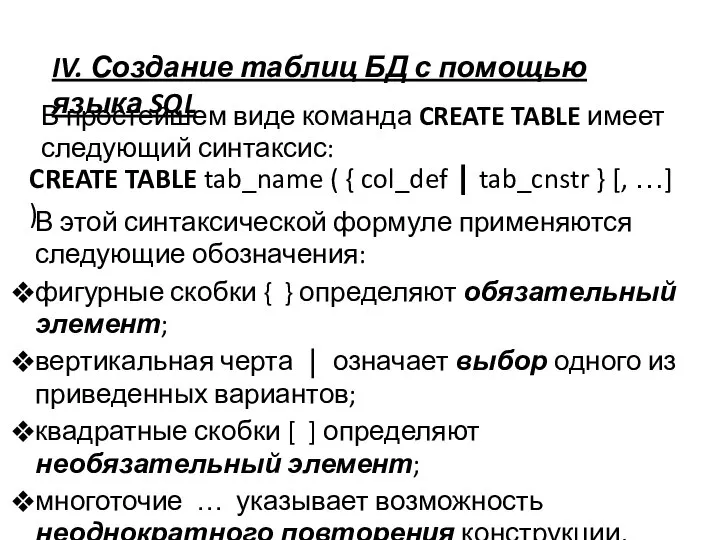
IV. Создание таблиц БД с помощью языка SQL
В простейшем виде команда
IV. Создание таблиц БД с помощью языка SQL
В простейшем виде команда

Элемент col_def обозначает определение отдельной колонки таблицы.
col_def ::= { col_name data_type
Элемент col_def обозначает определение отдельной колонки таблицы.
col_def ::= { col_name data_type

Современные СУБД позволяют обрабатывать данные разных типов:
INT, SMALLINT — целые числа;
NUMERIC,
Современные СУБД позволяют обрабатывать данные разных типов:
INT, SMALLINT — целые числа;
NUMERIC,

Необязательное ключевое слово DEFAULT определяет значение по умолчанию – const_expr.
Это значение
Необязательное ключевое слово DEFAULT определяет значение по умолчанию – const_expr.
Это значение

а) Обязательные значения
Это ограничение применяется в случае, если для некоторого столбца
а) Обязательные значения
Это ограничение применяется в случае, если для некоторого столбца

b) Простой первичный ключ
Определяется с помощью спецификатора PRIMARY KEY. Например:
Object_ID INTEGER
b) Простой первичный ключ
Определяется с помощью спецификатора PRIMARY KEY. Например:
Object_ID INTEGER

c) Простой альтернативный ключ
Иногда в дополнение к первичному ключу необходимо иметь
c) Простой альтернативный ключ
Иногда в дополнение к первичному ключу необходимо иметь

d) Проверочные ограничения
С помощью спецификатора CHECK(log_expr) можно задать ограниченный диапазон возможных
d) Проверочные ограничения
С помощью спецификатора CHECK(log_expr) можно задать ограниченный диапазон возможных

e) Простой внешний ключ
Объявляется в дочерней (подчиненной) таблице с помощью конструкции
[
e) Простой внешний ключ
Объявляется в дочерней (подчиненной) таблице с помощью конструкции
[

Ограничения на уровне всей таблицы
В директиве CREATE TABLE такие ограничения объявляются
Ограничения на уровне всей таблицы
В директиве CREATE TABLE такие ограничения объявляются

Объявление составного первичного или альтернативного ключа:
FOREIGN KEY ( col_name [, …]
Объявление составного первичного или альтернативного ключа:
FOREIGN KEY ( col_name [, …]

V. Выборка данных с помощью языка SQL
Команда SELECT позволяет извлечь данные
V. Выборка данных с помощью языка SQL
Команда SELECT позволяет извлечь данные

В структуре этой мощной команды, которая имеет достаточно сложный синтаксис, можно
В структуре этой мощной команды, которая имеет достаточно сложный синтаксис, можно

1) Полное отображение таблицы
SELECT * FROM 〈 имя_исх_таб 〉
Рассмотрим наиболее распространенные
1) Полное отображение таблицы
SELECT * FROM 〈 имя_исх_таб 〉
Рассмотрим наиболее распространенные

3) Выборка записей по заданному условию
В эти выражения обычно входят константы
3) Выборка записей по заданному условию
В эти выражения обычно входят константы

4) Сортировка результатов запроса
Кроме того, в условии отбора можно:
SELECT 〈 список_столбцов
4) Сортировка результатов запроса
Кроме того, в условии отбора можно:
SELECT 〈 список_столбцов
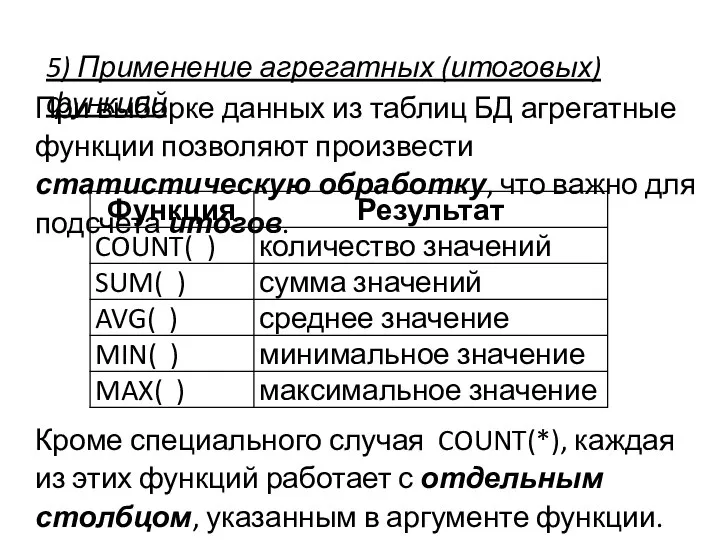
5) Применение агрегатных (итоговых) функций
При выборке данных из таблиц БД агрегатные
5) Применение агрегатных (итоговых) функций
При выборке данных из таблиц БД агрегатные

Пример 1. Усреднение значений для заданного столбца:
SELECT COUNT(*)
FROM 〈 имя_исх_таб 〉
WHERE
Пример 1. Усреднение значений для заданного столбца:
SELECT COUNT(*) FROM 〈 имя_исх_таб 〉 WHERE

6) Запросы с группировкой
Часто при анализе табличных данных требуется выполнить их
6) Запросы с группировкой
Часто при анализе табличных данных требуется выполнить их

В частности, любой элемент списка столбцов в разделе SELECT должен иметь
В частности, любой элемент списка столбцов в разделе SELECT должен иметь

В разделе WHERE оператора SELECT может присутствовать вложенный запрос.
Результат выполнения этого
В разделе WHERE оператора SELECT может присутствовать вложенный запрос.
Результат выполнения этого

8) Многотабличные запросы
SELECT ФИО, Должность
FROM ПРЕПОДАВАТЕЛИ
WHERE Зарплата >
( SELECT AVG(Зарплата)
FROM
8) Многотабличные запросы
SELECT ФИО, Должность
FROM ПРЕПОДАВАТЕЛИ
WHERE Зарплата >
( SELECT AVG(Зарплата)
FROM

В этом запросе для сокращенного обозначения таблиц используются их псевдонимы –
В этом запросе для сокращенного обозначения таблиц используются их псевдонимы –

Эта конструкция применяется для соединения таблиц 〈left_tab〉 и 〈right_tab〉, причем условия
Эта конструкция применяется для соединения таблиц 〈left_tab〉 и 〈right_tab〉, причем условия
![[ INNER ] JOIN — внутреннее соединение (применяется по умолчанию); LEFT](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1298090/slide-30.jpg)
[ INNER ] JOIN — внутреннее соединение (применяется по умолчанию);
LEFT [
[ INNER ] JOIN — внутреннее соединение (применяется по умолчанию);
LEFT [
 Религиозные верования и традиции древних египтян
Религиозные верования и традиции древних египтян Dziesięć przykazań Bożych. Aby człowiek był naprawdę człowiekiem…
Dziesięć przykazań Bożych. Aby człowiek był naprawdę człowiekiem… Внешняя и внутренняя политика Ярослава
Внешняя и внутренняя политика Ярослава Древние образы в народном искусстве
Древние образы в народном искусстве Церковно-певческое дело в Вятке и Вятской губернии
Церковно-певческое дело в Вятке и Вятской губернии Usyk Oleksandr
Usyk Oleksandr Патриотическое воспитание на уроках курса «Основы православной культуры» и во внеурочной деятельности младших школьников Презе
Патриотическое воспитание на уроках курса «Основы православной культуры» и во внеурочной деятельности младших школьников Презе Корпоративная культура организации
Корпоративная культура организации Les mots français en russe
Les mots français en russe Распределение электронной плотности в монозамещенных бензолах
Распределение электронной плотности в монозамещенных бензолах Оценка экономической эффективности проектов совершенствования системы и технологии управления персоналом
Оценка экономической эффективности проектов совершенствования системы и технологии управления персоналом Понятие ,признаки и особенности жилища Подготовили: студенты группы Ю092 Виноградская Екатерина Ганеева Марина
Понятие ,признаки и особенности жилища Подготовили: студенты группы Ю092 Виноградская Екатерина Ганеева Марина Beatniks or The Beats
Beatniks or The Beats В мире добрых слов - презентация для начальной школы_
В мире добрых слов - презентация для начальной школы_ Таможенные платежи
Таможенные платежи Арифметические и логические команды языка Ассемблер. Битовые команды
Арифметические и логические команды языка Ассемблер. Битовые команды Итоговая работа по Минской области. Менеджмент в туризме
Итоговая работа по Минской области. Менеджмент в туризме Прямой изгиб. Лекция 5
Прямой изгиб. Лекция 5 Без названия
Без названия Постройки в нашей жизни. Изображение сказочного домика
Постройки в нашей жизни. Изображение сказочного домика Цивилизация древнего Египта
Цивилизация древнего Египта Разработка системы телеметрического контроля параметров системы электропитания наноспутников
Разработка системы телеметрического контроля параметров системы электропитания наноспутников Какие опасности можно встретить во дворе
Какие опасности можно встретить во дворе  Финансовая среда предпринимательства и предпринимательские риски
Финансовая среда предпринимательства и предпринимательские риски Компьютер. Устройства компьютера
Компьютер. Устройства компьютера Стратегический проект «Торговые узлы Екатеринбурга» итоги и актуализация проекта
Стратегический проект «Торговые узлы Екатеринбурга» итоги и актуализация проекта Отчет о прохождении производственной практики (по профилю специальности)
Отчет о прохождении производственной практики (по профилю специальности) Организационная структура «Зеленый квартал»
Организационная структура «Зеленый квартал»