- Parallel Architecture Intro

Содержание
- 2. More Logistics Projects: simulation-based, creative, be prepared to spend time towards end of semester – more
- 3. Parallel Architecture Trends Source: Mark Hill, Ravi Rajwar
- 4. CMP/SMT Papers CMP/SMT/Multiprocessor papers in recent conferences: 2001 2002 2003 2004 2005 2006 2007 ISCA: 3
- 5. Bottomline Can’t escape multi-cores today: it is the baseline architecture Performance stagnates unless we learn to
- 6. Symmetric Multiprocessors (SMP) A collection of processors, a collection of memory: both are connected through some
- 7. Distributed Memory Multiprocessors Each processor has local memory that is accessible through a fast interconnect The
- 8. Shared Memory Architectures Key differentiating feature: the address space is shared, i.e., any processor can directly
- 9. Shared Address Space Shared Private Private Private Process P1 Process P2 Process P3 Shared Shared Shared
- 10. Message Passing Programming model that can apply to clusters of workstations, SMPs, and even a uniprocessor
- 11. Models for SEND and RECEIVE Synchronous: SEND returns control back to the program only when the
- 12. Deterministic Execution Need synch after every anti-diagonal Potential load imbalance Shared-memory vs. message passing Function of
- 13. Cache Coherence A multiprocessor system is cache coherent if a value written by a processor is
- 14. Cache Coherence Protocols Directory-based: A single location (directory) keeps track of the sharing status of a
- 16. Скачать презентацию

More Logistics
Projects: simulation-based, creative, be prepared to
spend time towards
More Logistics
Projects: simulation-based, creative, be prepared to
spend time towards
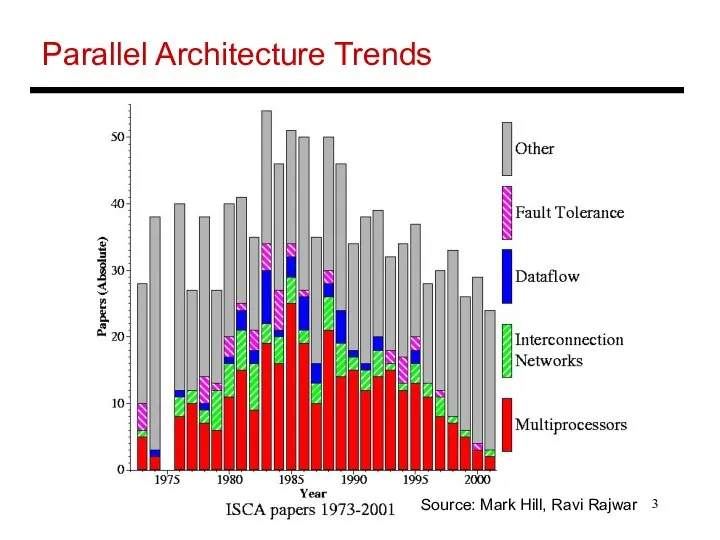
Parallel Architecture Trends
Source: Mark Hill, Ravi Rajwar
Parallel Architecture Trends
Source: Mark Hill, Ravi Rajwar

CMP/SMT Papers
CMP/SMT/Multiprocessor papers in recent conferences:
2001 2002 2003 2004
CMP/SMT Papers
CMP/SMT/Multiprocessor papers in recent conferences:
2001 2002 2003 2004

Bottomline
Can’t escape multi-cores today: it is the baseline
architecture
Performance
Bottomline
Can’t escape multi-cores today: it is the baseline
architecture
Performance
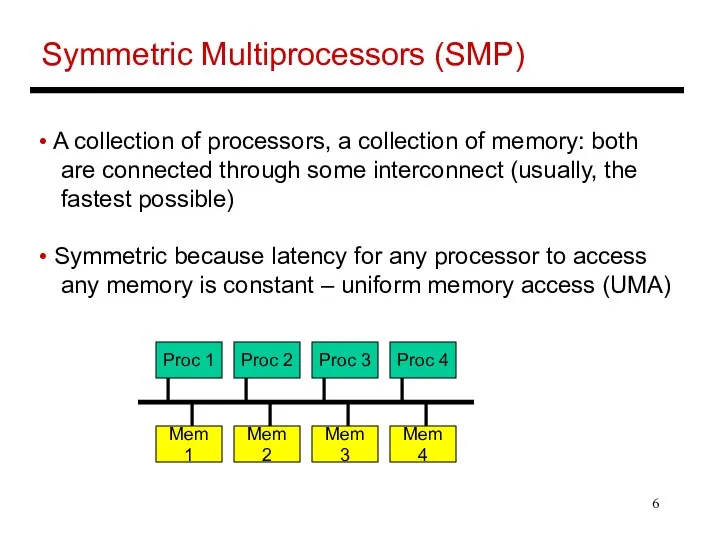
Symmetric Multiprocessors (SMP)
A collection of processors, a collection of memory:
Symmetric Multiprocessors (SMP)
A collection of processors, a collection of memory:
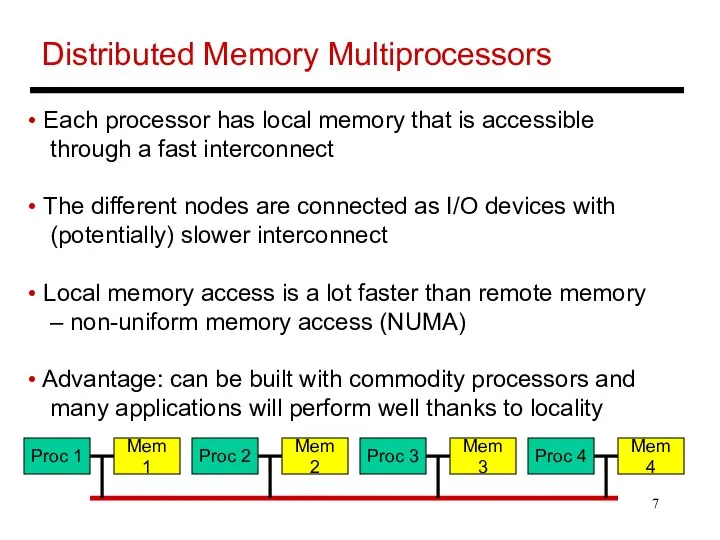
Distributed Memory Multiprocessors
Each processor has local memory that is accessible
Distributed Memory Multiprocessors
Each processor has local memory that is accessible

Shared Memory Architectures
Key differentiating feature: the address space is shared,
Shared Memory Architectures
Key differentiating feature: the address space is shared,
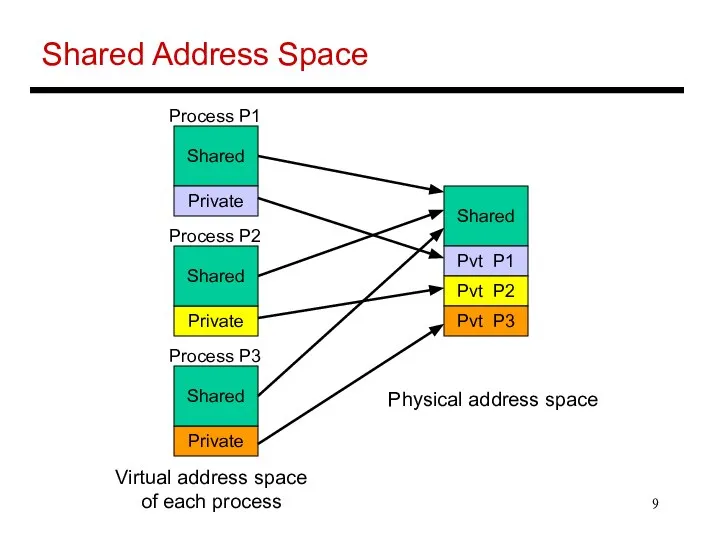
Shared Address Space
Shared
Private
Private
Private
Process P1
Process P2
Process P3
Shared
Shared
Shared
Pvt P1
Pvt P2
Pvt P3
Virtual address space
of
Shared Address Space
Shared
Private
Private
Private
Process P1
Process P2
Process P3
Shared
Shared
Shared
Pvt P1
Pvt P2
Pvt P3
Virtual address space
of

Message Passing
Programming model that can apply to clusters of workstations,
Message Passing
Programming model that can apply to clusters of workstations,

Models for SEND and RECEIVE
Synchronous: SEND returns control back to
Models for SEND and RECEIVE
Synchronous: SEND returns control back to
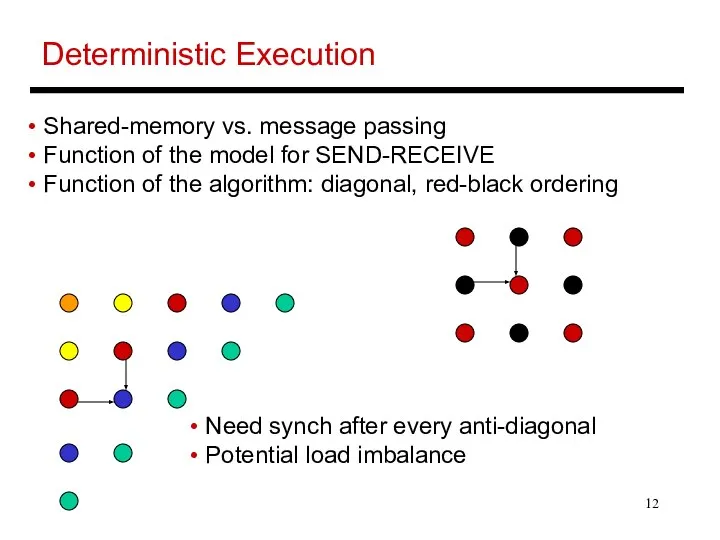
Deterministic Execution
Need synch after every anti-diagonal
Potential load imbalance
Shared-memory
Deterministic Execution
Need synch after every anti-diagonal
Potential load imbalance
Shared-memory

Cache Coherence
A multiprocessor system is cache coherent if
a value written
Cache Coherence
A multiprocessor system is cache coherent if
a value written

Cache Coherence Protocols
Directory-based: A single location (directory) keeps track
of
Cache Coherence Protocols
Directory-based: A single location (directory) keeps track
of
 Ручная набойка на ткани
Ручная набойка на ткани Задачи по теме: «Обыкновенные дроби» 5 класс Учитель математики Артамонова Л.В., МКОУ «Москаленский лицей»
Задачи по теме: «Обыкновенные дроби» 5 класс Учитель математики Артамонова Л.В., МКОУ «Москаленский лицей»  Разработка комплекса маркетинга товара
Разработка комплекса маркетинга товара Дискретное преобразование Фурье Обратное пространство. Фурье-преобразование. Быстрое фурье-преобразование
Дискретное преобразование Фурье Обратное пространство. Фурье-преобразование. Быстрое фурье-преобразование MS Access vs MS Excel. Құжат типін анықтау
MS Access vs MS Excel. Құжат типін анықтау Рисунок головы
Рисунок головы Основы оказания первой помощи на поиске, юридические аспекты, базовые алгоритмы. ПО «Лиза Алерт»
Основы оказания первой помощи на поиске, юридические аспекты, базовые алгоритмы. ПО «Лиза Алерт» Начертательная геометрия
Начертательная геометрия Политическая система общества
Политическая система общества Презентация "Светлая Пасхальная Седмица: традиции и обычаи" - скачать презентации по МХК
Презентация "Светлая Пасхальная Седмица: традиции и обычаи" - скачать презентации по МХК Выставочнй зал "Романтичное Болдино". Парк "Четыре времени года"
Выставочнй зал "Романтичное Болдино". Парк "Четыре времени года" Общие сведения о деталях машин
Общие сведения о деталях машин Системы менеджмента качества
Системы менеджмента качества Конный завод «Ахалтекинец»
Конный завод «Ахалтекинец» Содержание права собственности на землю Выполнили студентки группы Ю-103 Пустовая Анастасия и Мятлик Елена.
Содержание права собственности на землю Выполнили студентки группы Ю-103 Пустовая Анастасия и Мятлик Елена. Особенности празднования Нового Года
Особенности празднования Нового Года Преимущества и недостатки объектно-ориентированного программирования (ООП)
Преимущества и недостатки объектно-ориентированного программирования (ООП) Қазақстан Республикасының ішкі саясаты
Қазақстан Республикасының ішкі саясаты вывеска
вывеска Проект реконструкции сервисного центра по обслуживанию автовладельцев г. Великий Новгород. Разработка услуги по тюнингу салона
Проект реконструкции сервисного центра по обслуживанию автовладельцев г. Великий Новгород. Разработка услуги по тюнингу салона Женщина и карьера
Женщина и карьера Общие сведения о TCP/IP
Общие сведения о TCP/IP Презентация "Декоративно-прикладное искусство" - скачать презентации по МХК_
Презентация "Декоративно-прикладное искусство" - скачать презентации по МХК_ Городская культура Токио
Городская культура Токио Предварительная подготовка к выезду
Предварительная подготовка к выезду Зонты Выполнила: Митюшова, Александра Реклама, 303 группа
Зонты Выполнила: Митюшова, Александра Реклама, 303 группа ЛЕКЦИЯ № 3 ТЕМА: АНТРОПОЛОГИЧЕСКИЕ ПРИЗНАКИ ЧЕЛОВЕКА
ЛЕКЦИЯ № 3 ТЕМА: АНТРОПОЛОГИЧЕСКИЕ ПРИЗНАКИ ЧЕЛОВЕКА  ОРГАНИЗАЦИЯ ВОСПИТАТЕЛЬНОГО ПРОСТРАНСТВА В ШКОЛЕ-ИНТЕРНАТЕ
ОРГАНИЗАЦИЯ ВОСПИТАТЕЛЬНОГО ПРОСТРАНСТВА В ШКОЛЕ-ИНТЕРНАТЕ