- Параллельные методы решения задач линейной алгебры

Содержание
- 2. Принципы распараллеливания В методах матричных вычислений повторяются одинаковые действия для разных элементов матриц Это параллелизм по
- 3. Способы разбиения матриц Ленточное разбиение – каждому процессору выделяется подмножество строк или столбцов Всего строк (столбцов)
- 4. Постановка задачи Матрица А размерности m x n умножается на вектор b (n элементов), результат –
- 5. Пример разбиения – ленточное по строкам Дополнительная задача разбиения: дублировать или разбивать векторы b и с?
- 6. Схема информационного взаимодействия подзадач
- 7. Распределение подзадач по процессорам Количество вычислительных операций одинаково для всех подзадач. Если p Распределение объединенных подзадач
- 8. Анализ эффективности параллельных вычислений Упрощенный подход: m = n Не учитывается коммуникационная трудоемкость Время выполнения всех
- 9. Анализ эффективности параллельных вычислений Учет коммуникационной трудоемкости модель Хокни - оценка времени передачи сообщения m байт
- 10. Программная реализация (MPI) – порядок по логике вызовов! int ProcNum = 0;//число процессов int ProcRank =
- 11. if (ProcRank == 0) { printf ("Parallel matrix-vector multiplication program\n"); } ProcessInitialization(pMatrix, pVector, pResult, pProcRows, pProcResult,
- 12. void ProcessInitialization (double* &pMatrix, double* &pVector, double* &pResult, double* &pProcRows, double* &pProcResult, int &Size, int &RowNum)
- 13. // осталось распределить между процессами Size строк матрицы А RestRows = Size; for (i=0; i {
- 14. void RandomDataInitialization(double* pMatrix, double* pVector, int Size) { int i, j; srand(unsigned(clock()));// инициализация датчика случайных чисел
- 15. void DataDistribution(double* pMatrix, double* pProcRows, double* pVector, int Size, int RowNum) { int *pSendNum;//число элементов, отправляемых
- 16. for (int i=1; i { RestRows = RestRows - RowNum; RowNum = RestRows/(ProcNum-i);// нужно если нет
- 17. Функция MPI_Scatterv int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype
- 18. // будет выполняться каждым процессом void ParallelResultCalculation(double* pProcRows, double* pVector, double* pProcResult, int Size, int RowNum)
- 19. // будет выполняться каждым процессом для сбора результата void ResultReplication(double* pProcResult, double* pResult, int Size, int
- 20. for (i=1; i { RestRows = RestRows - pReceiveNum[i-1]; pReceiveNum[i] = RestRows/(ProcNum-i); pReceiveInd[i] = pReceiveInd[i-1]+pReceiveNum[i-1]; }
- 21. Функция MPI_Allgatherv int MPI_Allgatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount,MPI_Datatype recvtype, MPI_Comm comm)
- 22. // проверка результатов void TestDistribution(double* pMatrix, double* pVector, double* pProcRows, int Size, int RowNum, double* pResult,
- 23. // вывод результатов с других процессов for (int i=1; i { if (ProcRank == i) {
- 24. // освобождение памяти на всех процессах void ProcessTermination (double* pMatrix, double* pVector, double* pResult, double* pProcRows,
- 26. Скачать презентацию

Принципы распараллеливания
В методах матричных вычислений повторяются одинаковые действия для разных элементов
Принципы распараллеливания
В методах матричных вычислений повторяются одинаковые действия для разных элементов

Способы разбиения матриц
Ленточное разбиение – каждому процессору выделяется подмножество строк
Способы разбиения матриц
Ленточное разбиение – каждому процессору выделяется подмножество строк

Постановка задачи
Матрица А размерности m x n умножается на вектор b
Постановка задачи
Матрица А размерности m x n умножается на вектор b

Пример разбиения – ленточное по строкам
Дополнительная задача разбиения:
дублировать или разбивать
Пример разбиения – ленточное по строкам
Дополнительная задача разбиения: дублировать или разбивать

Схема информационного взаимодействия подзадач
Схема информационного взаимодействия подзадач

Распределение подзадач по процессорам
Количество вычислительных операций одинаково для всех подзадач.
Если p
Распределение подзадач по процессорам
Количество вычислительных операций одинаково для всех подзадач.
Если p

Анализ эффективности параллельных вычислений
Упрощенный подход:
m = n
Не учитывается коммуникационная трудоемкость
Время выполнения
Анализ эффективности параллельных вычислений
Упрощенный подход:
m = n
Не учитывается коммуникационная трудоемкость
Время выполнения

Анализ эффективности параллельных вычислений
Учет коммуникационной трудоемкости
модель Хокни - оценка времени передачи
Анализ эффективности параллельных вычислений
Учет коммуникационной трудоемкости модель Хокни - оценка времени передачи

Программная реализация (MPI) – порядок по логике вызовов!
int ProcNum = 0;//число
Программная реализация (MPI) – порядок по логике вызовов!
int ProcNum = 0;//число

if (ProcRank == 0)
{
printf ("Parallel matrix-vector multiplication
if (ProcRank == 0)
{
printf ("Parallel matrix-vector multiplication

void ProcessInitialization (double* &pMatrix, double* &pVector,
double* &pResult, double* &pProcRows,
void ProcessInitialization (double* &pMatrix, double* &pVector,
double* &pResult, double* &pProcRows,
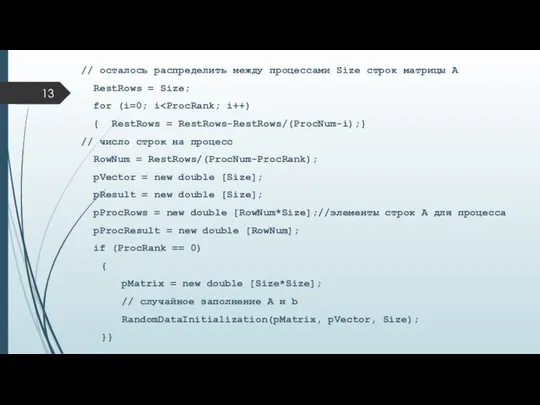
// осталось распределить между процессами Size строк матрицы А
RestRows
// осталось распределить между процессами Size строк матрицы А
RestRows

void RandomDataInitialization(double* pMatrix, double* pVector, int Size)
{
int i, j;
void RandomDataInitialization(double* pMatrix, double* pVector, int Size)
{
int i, j;

void DataDistribution(double* pMatrix, double* pProcRows, double* pVector,
int Size, int RowNum)
void DataDistribution(double* pMatrix, double* pProcRows, double* pVector,
int Size, int RowNum)

for (int i=1; i{
RestRows = RestRows - RowNum;
for (int i=1; i
RestRows = RestRows - RowNum;

Функция MPI_Scatterv
int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs,
MPI_Datatype sendtype, void* recvbuf,
Функция MPI_Scatterv
int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs,
MPI_Datatype sendtype, void* recvbuf,

// будет выполняться каждым процессом
void ParallelResultCalculation(double* pProcRows, double* pVector, double* pProcResult,
// будет выполняться каждым процессом
void ParallelResultCalculation(double* pProcRows, double* pVector, double* pProcResult,

// будет выполняться каждым процессом для сбора результата
void ResultReplication(double* pProcResult, double*
// будет выполняться каждым процессом для сбора результата
void ResultReplication(double* pProcResult, double*
![for (i=1; i { RestRows = RestRows - pReceiveNum[i-1]; pReceiveNum[i] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308382/slide-19.jpg)
for (i=1; i{
RestRows = RestRows - pReceiveNum[i-1];
pReceiveNum[i]
for (i=1; i
RestRows = RestRows - pReceiveNum[i-1];
pReceiveNum[i]

Функция MPI_Allgatherv
int MPI_Allgatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int
Функция MPI_Allgatherv
int MPI_Allgatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int
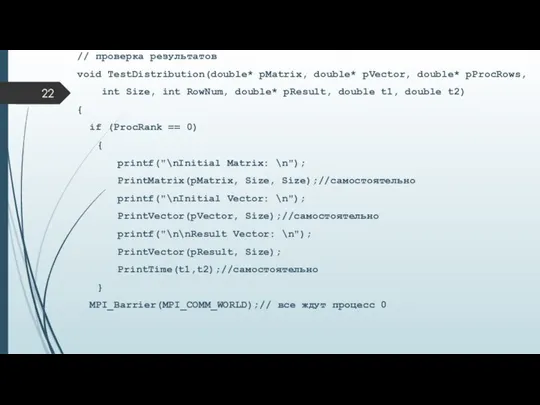
// проверка результатов
void TestDistribution(double* pMatrix, double* pVector, double* pProcRows,
int Size,
// проверка результатов
void TestDistribution(double* pMatrix, double* pVector, double* pProcRows,
int Size,

// вывод результатов с других процессов
for (int i=1; i{
// вывод результатов с других процессов
for (int i=1; i

// освобождение памяти на всех процессах
void ProcessTermination (double* pMatrix, double* pVector,
// освобождение памяти на всех процессах
void ProcessTermination (double* pMatrix, double* pVector,
 Генеральная Ассамблея ООН Подготовила: студентка Группы Ю092 Виноградская Екатерина
Генеральная Ассамблея ООН Подготовила: студентка Группы Ю092 Виноградская Екатерина Г.Песталоцци: педагогические идеи
Г.Песталоцци: педагогические идеи Футуризм и футуристы
Футуризм и футуристы Славянские имена –зеркало славянского народа
Славянские имена –зеркало славянского народа 7 занятие.ppt
7 занятие.ppt Сравнение скансенов
Сравнение скансенов Основные виды и принципы природопользования Выполнили: студентки 3 курса юридического факультета, группа ю-092 Ганеева М., Виноград
Основные виды и принципы природопользования Выполнили: студентки 3 курса юридического факультета, группа ю-092 Ганеева М., Виноград Логические величины, операции, выражения
Логические величины, операции, выражения Вторичный сектор Отрасли промышленности
Вторичный сектор Отрасли промышленности Модификация алгоритма Viola-Jones на основе детектирования цвета кожи
Модификация алгоритма Viola-Jones на основе детектирования цвета кожи Организация подземного пространства зданий и сооружений
Организация подземного пространства зданий и сооружений Линейная функция
Линейная функция  Биполярные транзисторы
Биполярные транзисторы ПРЕСТУПЛЕНИЯ В СФЕРЕ ОБОРОТА НАРКОТИЧЕСКИХ СРЕДСТВ
ПРЕСТУПЛЕНИЯ В СФЕРЕ ОБОРОТА НАРКОТИЧЕСКИХ СРЕДСТВ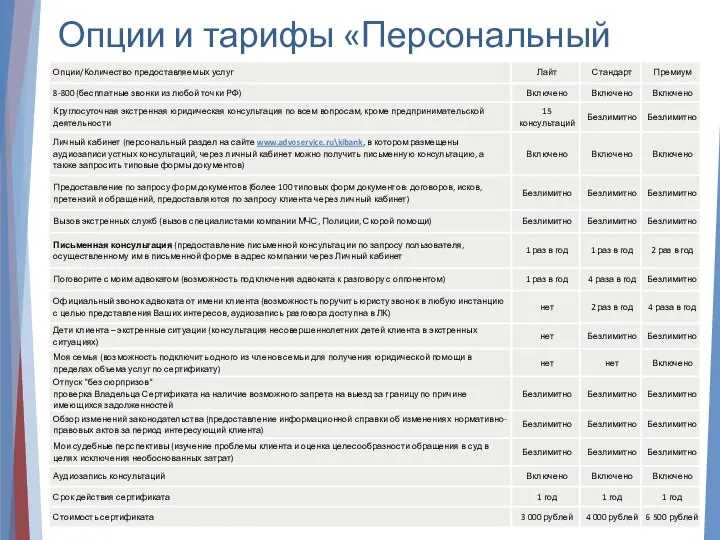 Опции и тарифы «Персональный юрист»
Опции и тарифы «Персональный юрист» Возникновение и развитие египтологии
Возникновение и развитие египтологии  Презентация "Гоголь и театр" - скачать презентации по МХК
Презентация "Гоголь и театр" - скачать презентации по МХК Ключевые события
Ключевые события Трудовое право
Трудовое право Динамика развития современной электроники
Динамика развития современной электроники Ферродинамические приборы
Ферродинамические приборы Пантеон - храм всех богов
Пантеон - храм всех богов Потребность в сне и отдыхе Презентация по дисциплине: «Основы Сестринского Дела» Автор: Филатова А.С. Практическое занятие
Потребность в сне и отдыхе Презентация по дисциплине: «Основы Сестринского Дела» Автор: Филатова А.С. Практическое занятие Sensors. Angular sensor – Resolver sensor
Sensors. Angular sensor – Resolver sensor Müssen
Müssen Телевидение - пространство культуры. Мир на экране
Телевидение - пространство культуры. Мир на экране Правила проведения Миссионерских вестей
Правила проведения Миссионерских вестей Иррациональные уравнения Урок алгебры и начал анализа 11 класс
Иррациональные уравнения Урок алгебры и начал анализа 11 класс