- SQL Server - основа информационной системы предприятия или организации.

Содержание
- 2. Технология "клиент-сервер" "Клиент-сервер" - модель взаимодействия компьютеров в сети: компьютер, управляющий ресурсом, называют сервером ресурса, а
- 3. Серверы баз данных Термин «сервер БД» используется для обозначения всей СУБД, основанной на архитектуре клиент-сервер, включая
- 4. Архитектура сервера использует для хранения БД набор файлов операционной системы, при этом для каждой из них
- 5. 1988 —Microsoft и Ashton-Tate анонсировали первую версию SQL Server — РСУБД для локальных вычислительных сетей. Новый
- 6. Стандарты SQL ANSI – Американский национальный институт стандартов, ISO – Международная организация стандартов Стандарт SQL1 был
- 7. Обработка распределенных данных Главная проблема больших систем - организация обработки распределенных данных. Данные находятся на компьютерах
- 8. Технология тиражирования данных Принципиальное отличие технологии тиражирования данных от технологии распределенных БД заключается в отказе от
- 9. Просуммируем очевидные преимущества технологии тиражирования данных: данные всегда расположены там, где они обрабатываются - следовательно, скорость
- 10. Просмотр списка баз SQL Server Просмотр таблиц БД NorthWind Выполним команду Query – Change database и
- 11. Схема БД Northwind Состав таблиц БД: Supplier – поставщик, Products – товар, Order – счет, Customer
- 13. Словарь SQL Два типа запросов: Возвращающий строки: Select SELECT [List of Fields or *] FROM [Table(s)]
- 14. Типы данных Для указания даты используется знак # (в стандарте ANSI – апостроф, т.е. '2/17/94 13:00':
- 15. Примеры оператора LIKE (MS Access использует для указания любого символа знак *, ANSI SQL - %):
- 16. Asterisk ( * ) SELECT authorID, firstName, lastName FROM Authors WHERE lastName LIKE ‘D*’ Question mark
- 17. Оптимизация команды SELECT Не указывайте лишние столбцы в запросе Используйте не перечисление полей, а символ *
- 18. Команда INSERT INSERT INTO таблица (поле, поле) VALUES (значение, значение) Примеры: INSERT INTO authors (Name, Address,
- 19. Выбор внешнего соединения – левое или правое? Внешнее соединение используется для Выявления несовпадений в ключевых полях
- 20. Найти всех авторов без книг: SELECT DISTINCTROW Authors.Au_ID, Authors.Author FROM Authors LEFT JOIN [Title Author] ON
- 21. SELECT Titles.PubID, Titles.[Year Published], Count(Titles.Title) AS Count FROM Titles GROUP BY Titles.PubID, Titles.[Year Published] PubID Year
- 22. Извлечение данных Указание на обращение к таблицам БД может быть указано явно командой USE. Полям таблицы
- 23. Выбор товаров, цена которых или 10 или 18 Для исключения повторов в столбце используется ключ DISTINCT
- 24. Функции Для работы с датами используются функции извлечения года (YEAR), месяца (MONTH), дня (DAY)… Выбрать компании,
- 25. _ один любой символ; [-…] один символ из диапазона: Cравнение со строкой - оператор LIKE со
- 26. Товары, в названии которых есть комбинация букв “gu“, после которых не следует буква “a” Товары, в
- 27. Упорядочение записей, подсчет итогов Упорядочение записей по значению поля (полей) выполняется с помощью оператора ORDER BY.
- 28. Выборка первых N записей с помощью ключа TOP. Отсортировав записи можно выбрать наилучшую (наихудшую) выборку товаров.
- 29. Количество товара, цена которого менее 50 Подсчет статистики по столбцам - функции: Max, Min, SUM, AVG
- 30. Соединение таблиц задается в секции FROM. Условия выборки задаются в конструкции WHERE (при группировке GROUP BY
- 31. Правое соединение – RIGHT OUTER JOIN, левое – LEFT OUTER JOIN, полное – FULL OUTER JOIN.
- 32. Для уникальных полей названия таблиц указывать не обязательно. Можно также использовать псевдонимы таблиц Таблицы Поставщики и
- 33. Покупатели, кому товар еще не доставлен (дата доставки – поле ShippedDate таблицы Orders (счета)).
- 34. Подзапрос - запрос, вложенный во внешний оператор SELECT, INSERT, UPDATE, DELETE. Возвращает одно значение. Подзапросы могут
- 35. Количество элементов в поле Freight таблицы Orders для которых в поле ShipRegion нет пустых значений. SELECT
- 36. Найти сумму цен 5 дешевых товаров (создадим подзапрос, затем в основной запрос включим текст подзапроса): SELECT
- 37. Найти товары, цена за единицу которых больше, чем у продукта “Mishi Kobe Niku” (cоздадим подзапрос, затем
- 38. Ключевые слова ALL и ANY сравнивают скалярное значение с набором значений одного столбца. Ключ ALL применяется
- 39. Ключевое слово EXISTS проверяет наличие атрибута. Оператор WHERE внешнего запроса проверяет, существуют ли строки, соответствующие подзапросу.
- 40. Группировка строк Выбрать 100 категорий тех товаров из запроса Alphabetical list of products, у которых средняя
- 41. Дополнительную фильтрацию выполним с помощью выражения HAVING. SELECT CategoryName, AVG(UnitPrice) AS AVGPrice FROM dbo.[Alphabetical list of
- 42. Названия и цена продуктов, совпадающих по цене с товаром “Chai”. SELECT ProductName, UnitPrice FROM dbo.Products WHERE
- 43. SELECT TOP 3 dbo.Categories. CategoryName, dbo.Products.UnitsInStock FROM dbo.Products INNER JOIN dbo.Categories ON dbo.Products.CategoryID = dbo.Categories.CategoryID WHERE
- 44. Количество продуктов, в названии которых встречается слово ‘Sir’ SELECT COUNT(ProductName) AS Ехрr1 FROM dbo.Products WHERE (ProductName
- 45. Cреднее арифметическое 5-ти самых дорогих товаров. SELECT AVG(UnitPrice) AS Expr1 FROM dbo.Products WHERE (UnitPrice IN (SELECT
- 46. SELECT TOP 5 сотрудник.[Код кафедры], Count(сотрудник.ФИО) AS число_сотрудников FROM сотрудник GROUP BY сотрудник.[Код кафедры] ORDER BY
- 47. SELECT сотрудник.ФИО, сотрудник.оклад FROM сотрудник WHERE (((сотрудник.оклад) Not Between 1000 And 2000)); SELECT сотрудник.ФИО, сотрудник.оклад FROM
- 49. Скачать презентацию

Технология "клиент-сервер"
"Клиент-сервер" - модель взаимодействия компьютеров в сети: компьютер, управляющий ресурсом,
Технология "клиент-сервер"
"Клиент-сервер" - модель взаимодействия компьютеров в сети: компьютер, управляющий ресурсом,

Серверы баз данных
Термин «сервер БД» используется для обозначения всей СУБД, основанной
Серверы баз данных
Термин «сервер БД» используется для обозначения всей СУБД, основанной

Архитектура сервера
использует для хранения БД набор файлов операционной системы, при этом
Архитектура сервера
использует для хранения БД набор файлов операционной системы, при этом

1988 —Microsoft и Ashton-Tate анонсировали первую версию SQL Server — РСУБД
1988 —Microsoft и Ashton-Tate анонсировали первую версию SQL Server — РСУБД

Стандарты SQL
ANSI – Американский национальный институт стандартов, ISO – Международная организация
Стандарты SQL
ANSI – Американский национальный институт стандартов, ISO – Международная организация

Обработка распределенных данных
Главная проблема больших систем - организация обработки распределенных данных.
Обработка распределенных данных
Главная проблема больших систем - организация обработки распределенных данных.

Технология тиражирования данных
Принципиальное отличие технологии тиражирования данных от технологии распределенных БД
Технология тиражирования данных
Принципиальное отличие технологии тиражирования данных от технологии распределенных БД

Просуммируем очевидные преимущества технологии тиражирования данных:
данные всегда расположены там, где они
Просуммируем очевидные преимущества технологии тиражирования данных:
данные всегда расположены там, где они
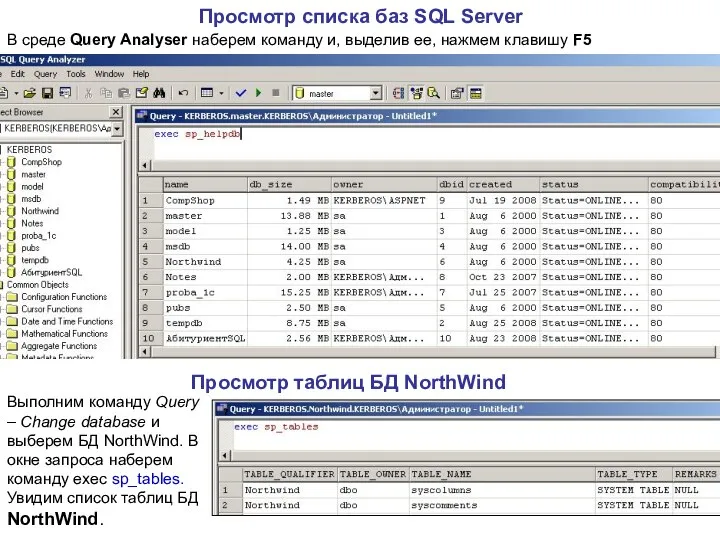
Просмотр списка баз SQL Server
Просмотр таблиц БД NorthWind
Выполним команду Query –
Просмотр списка баз SQL Server
Просмотр таблиц БД NorthWind
Выполним команду Query –
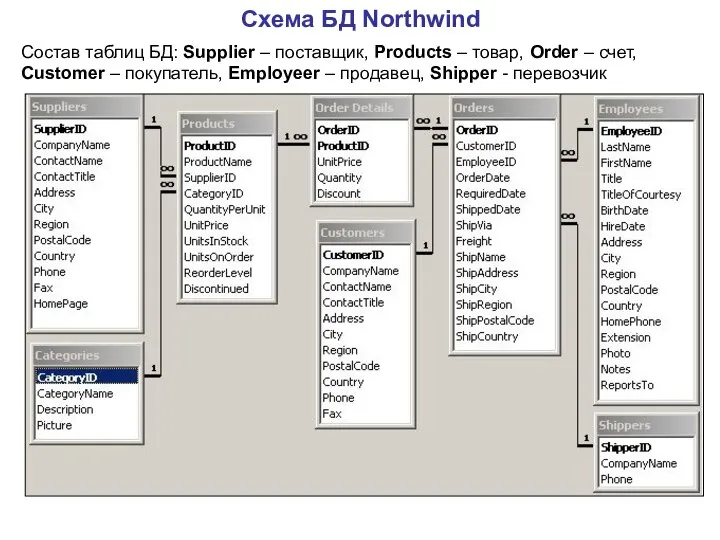
Схема БД Northwind
Состав таблиц БД: Supplier – поставщик, Products – товар,
Схема БД Northwind
Состав таблиц БД: Supplier – поставщик, Products – товар,

Словарь SQL
Два типа запросов:
Возвращающий строки: Select
SELECT [List of Fields or *]
Словарь SQL
Два типа запросов:
Возвращающий строки: Select
SELECT [List of Fields or *]

Типы данных
Для указания даты используется знак # (в стандарте ANSI
Типы данных
Для указания даты используется знак # (в стандарте ANSI

Примеры оператора LIKE
(MS Access использует для указания любого символа знак
Примеры оператора LIKE
(MS Access использует для указания любого символа знак

Asterisk ( * )
SELECT authorID, firstName, lastName FROM Authors
Asterisk ( * )
SELECT authorID, firstName, lastName FROM Authors

Оптимизация команды SELECT
Не указывайте лишние столбцы в запросе
Используйте не перечисление полей,
Оптимизация команды SELECT
Не указывайте лишние столбцы в запросе
Используйте не перечисление полей,

Команда INSERT
INSERT INTO таблица (поле, поле) VALUES (значение, значение)
Примеры:
INSERT INTO authors
Команда INSERT
INSERT INTO таблица (поле, поле) VALUES (значение, значение)
Примеры:
INSERT INTO authors
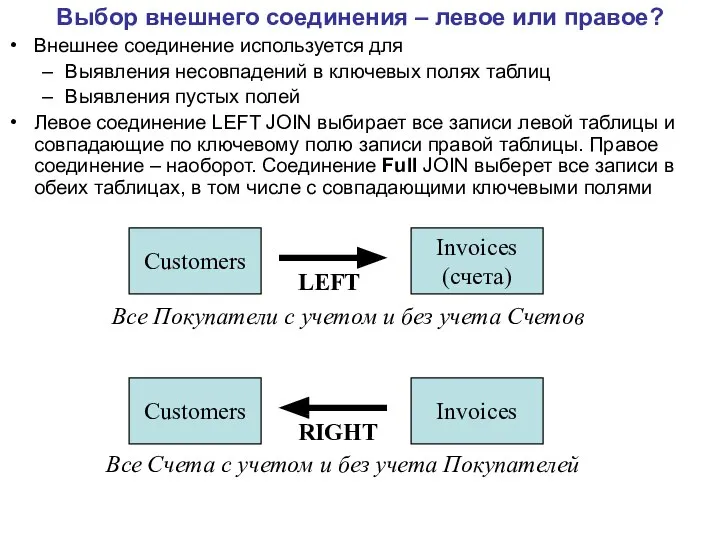
Выбор внешнего соединения – левое или правое?
Внешнее соединение используется для
Выявления
Выбор внешнего соединения – левое или правое?
Внешнее соединение используется для
Выявления

Найти всех авторов без книг:
SELECT DISTINCTROW Authors.Au_ID, Authors.Author
FROM Authors LEFT
Найти всех авторов без книг:
SELECT DISTINCTROW Authors.Au_ID, Authors.Author
FROM Authors LEFT
![SELECT Titles.PubID, Titles.[Year Published], Count(Titles.Title) AS Count FROM Titles GROUP BY](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1303581/slide-20.jpg)
SELECT Titles.PubID, Titles.[Year Published], Count(Titles.Title) AS Count
FROM Titles
GROUP BY Titles.PubID, Titles.[Year
SELECT Titles.PubID, Titles.[Year Published], Count(Titles.Title) AS Count
FROM Titles
GROUP BY Titles.PubID, Titles.[Year
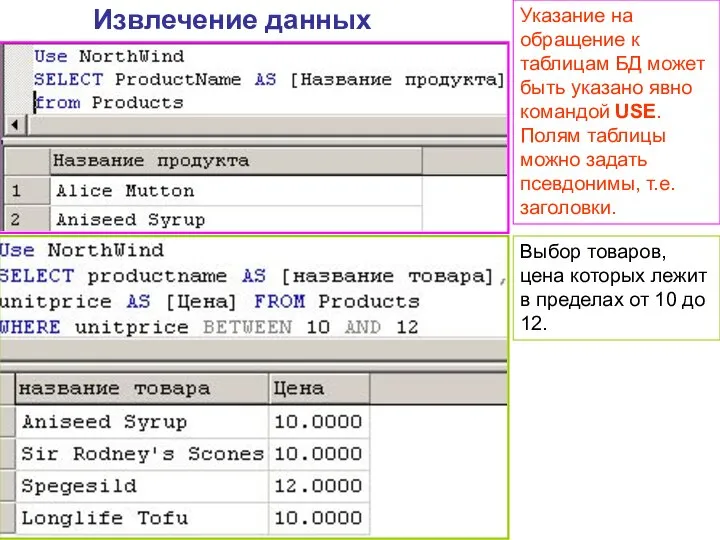
Извлечение данных
Указание на обращение к таблицам БД может быть указано явно
Извлечение данных
Указание на обращение к таблицам БД может быть указано явно
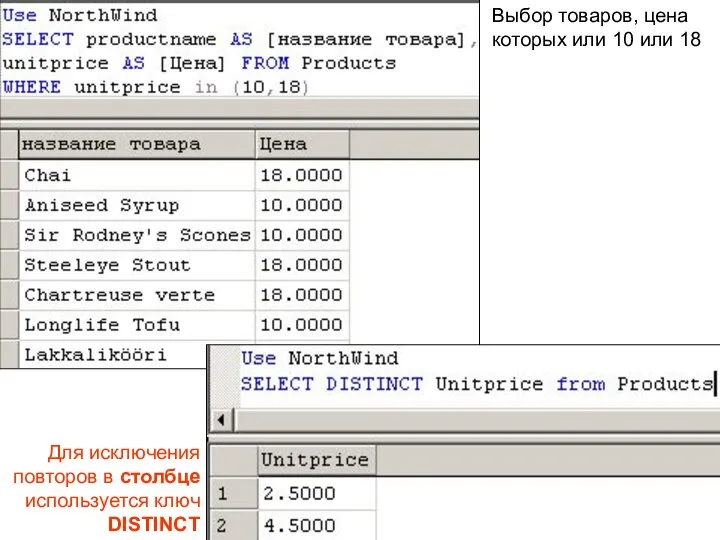
Выбор товаров, цена которых или 10 или 18
Для исключения повторов в
Выбор товаров, цена которых или 10 или 18
Для исключения повторов в
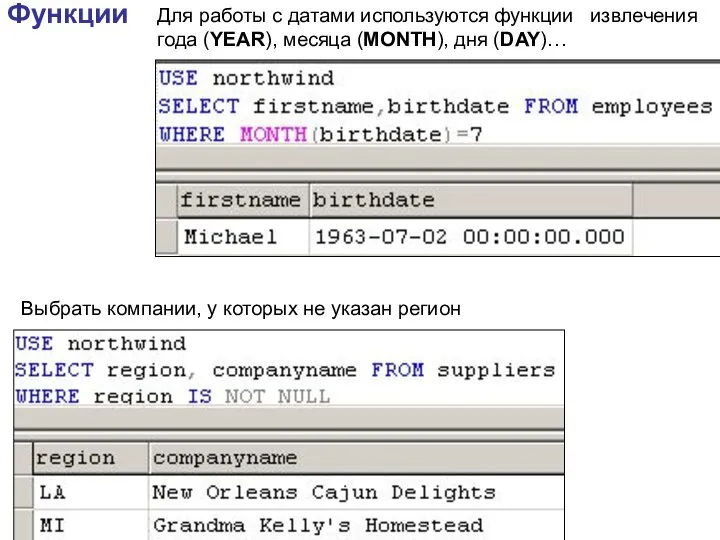
Функции
Для работы с датами используются функции извлечения года (YEAR), месяца (MONTH),
Функции
Для работы с датами используются функции извлечения года (YEAR), месяца (MONTH),
![_ один любой символ; [-…] один символ из диапазона: Cравнение со](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1303581/slide-24.jpg)
_ один любой символ;
[-…] один символ из диапазона:
Cравнение со строкой -
_ один любой символ;
[-…] один символ из диапазона:
Cравнение со строкой -

Товары, в названии которых есть комбинация букв “gu“, после которых не
Товары, в названии которых есть комбинация букв “gu“, после которых не

Упорядочение записей, подсчет итогов
Упорядочение записей по значению поля (полей) выполняется с
Упорядочение записей, подсчет итогов
Упорядочение записей по значению поля (полей) выполняется с
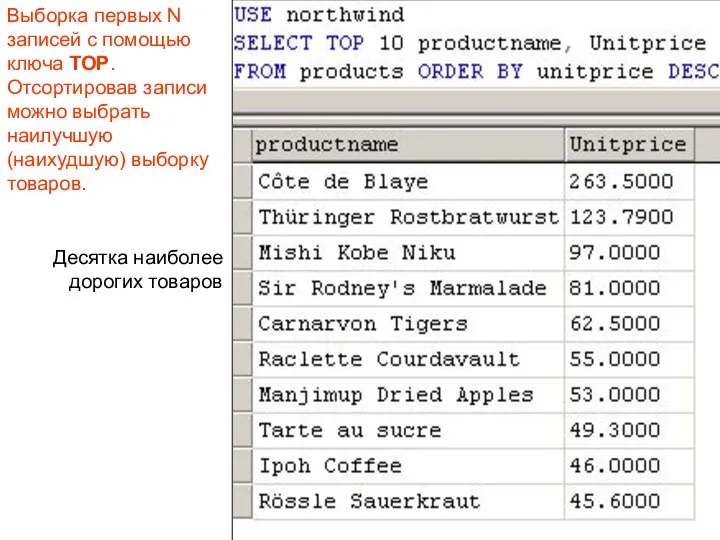
Выборка первых N записей с помощью ключа TOP. Отсортировав записи можно
Выборка первых N записей с помощью ключа TOP. Отсортировав записи можно
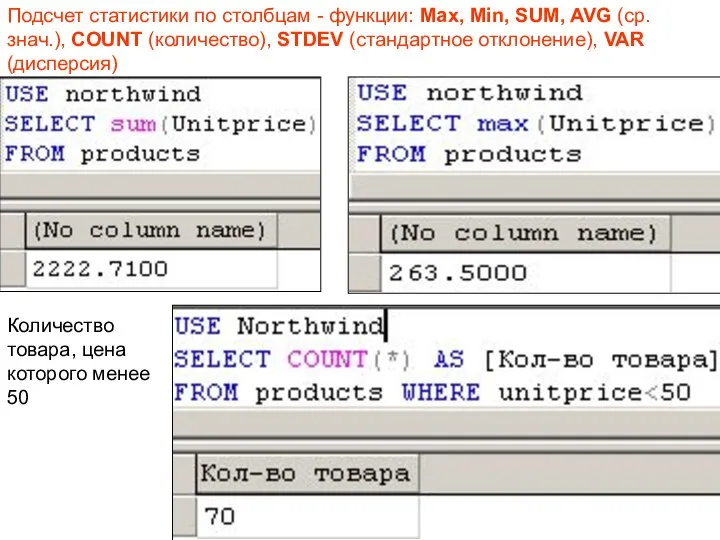
Количество товара, цена которого менее 50
Подсчет статистики по столбцам - функции:
Количество товара, цена которого менее 50
Подсчет статистики по столбцам - функции:
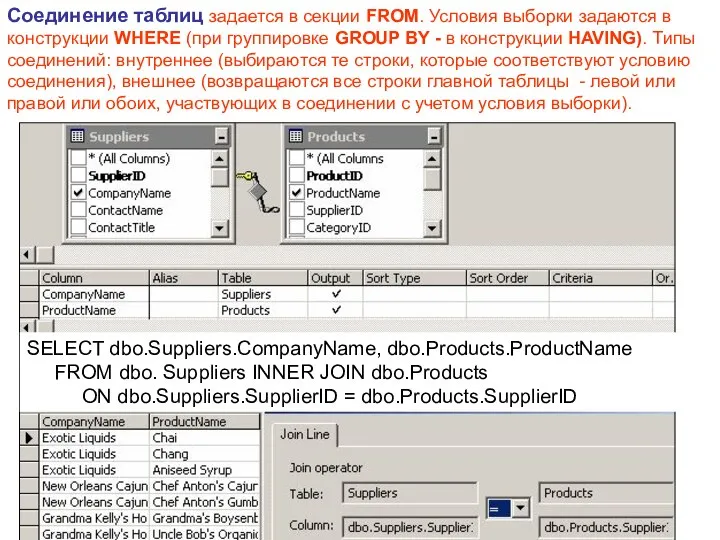
Соединение таблиц задается в секции FROM. Условия выборки задаются в конструкции
Соединение таблиц задается в секции FROM. Условия выборки задаются в конструкции
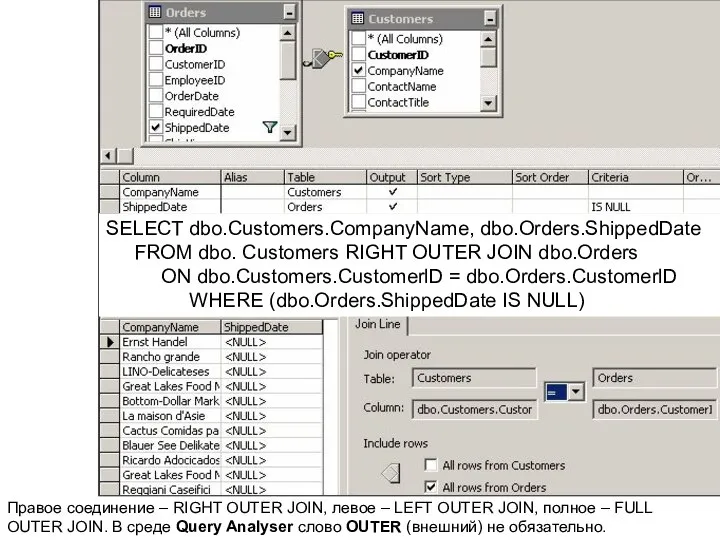
Правое соединение – RIGHT OUTER JOIN, левое – LEFT OUTER JOIN,
Правое соединение – RIGHT OUTER JOIN, левое – LEFT OUTER JOIN,
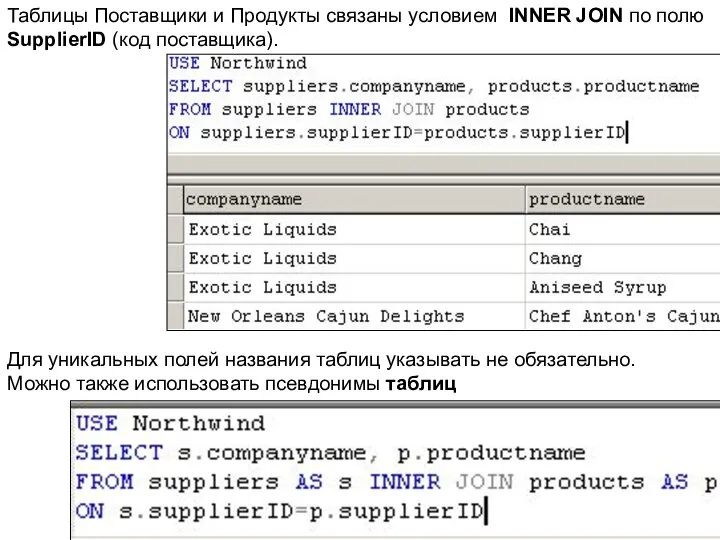
Для уникальных полей названия таблиц указывать не обязательно.
Можно также использовать
Для уникальных полей названия таблиц указывать не обязательно.
Можно также использовать
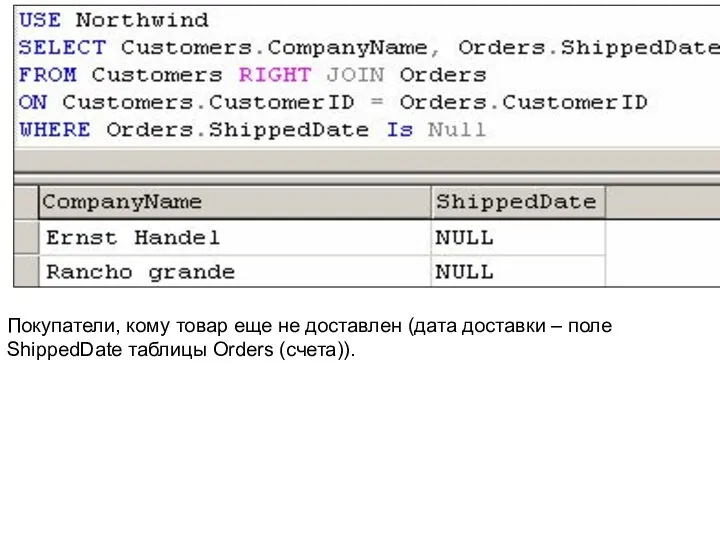
Покупатели, кому товар еще не доставлен (дата доставки – поле ShippedDate
Покупатели, кому товар еще не доставлен (дата доставки – поле ShippedDate
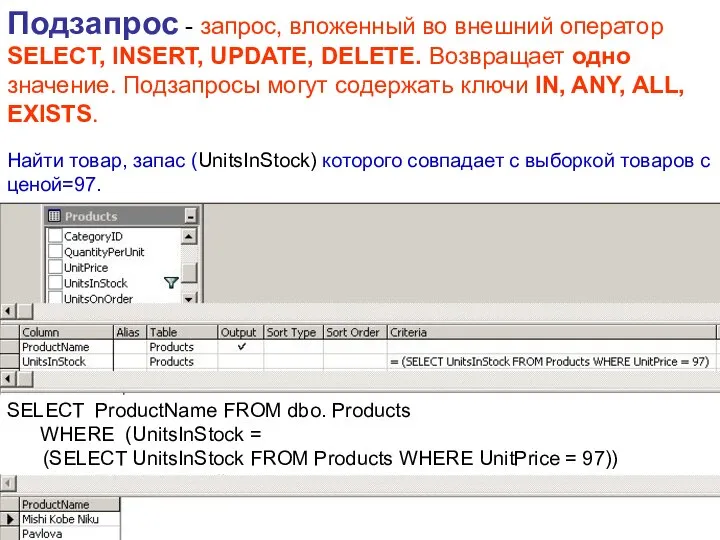
Подзапрос - запрос, вложенный во внешний оператор SELECT, INSERT, UPDATE, DELETE.
Подзапрос - запрос, вложенный во внешний оператор SELECT, INSERT, UPDATE, DELETE.
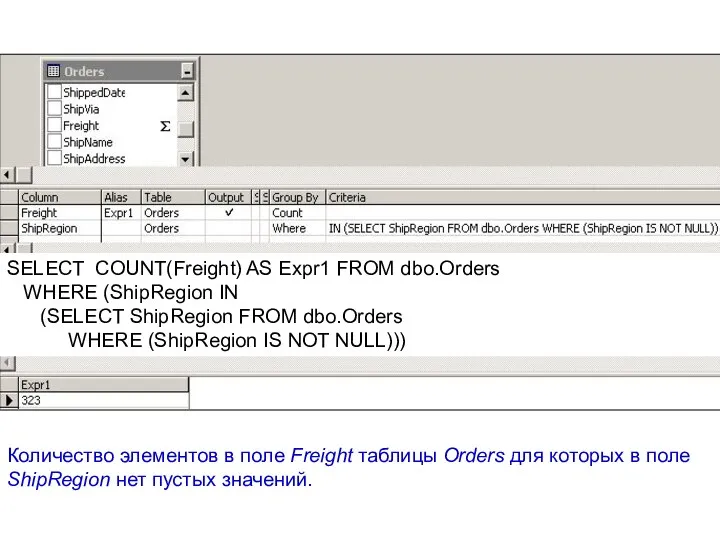
Количество элементов в поле Freight таблицы Orders для которых в поле
Количество элементов в поле Freight таблицы Orders для которых в поле
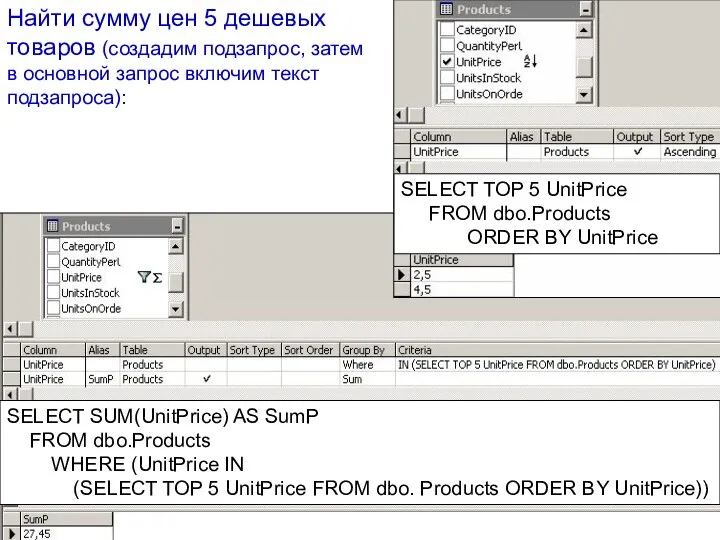
Найти сумму цен 5 дешевых товаров (создадим подзапрос, затем в основной
Найти сумму цен 5 дешевых товаров (создадим подзапрос, затем в основной
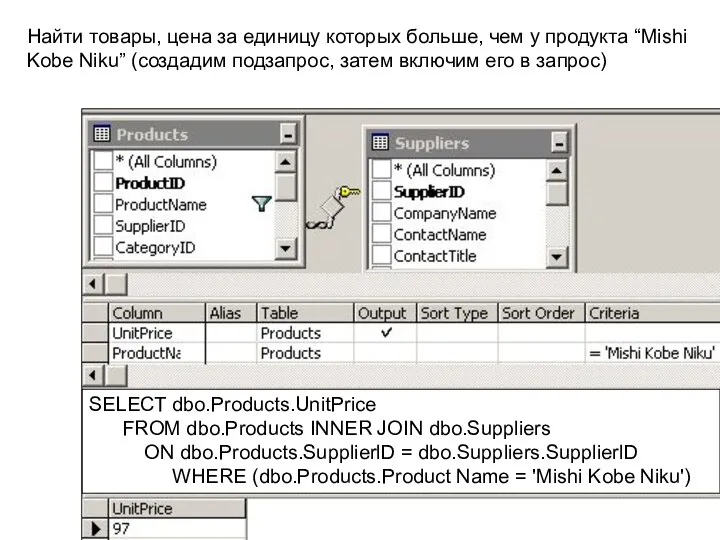
Найти товары, цена за единицу которых больше, чем у продукта “Mishi
Найти товары, цена за единицу которых больше, чем у продукта “Mishi
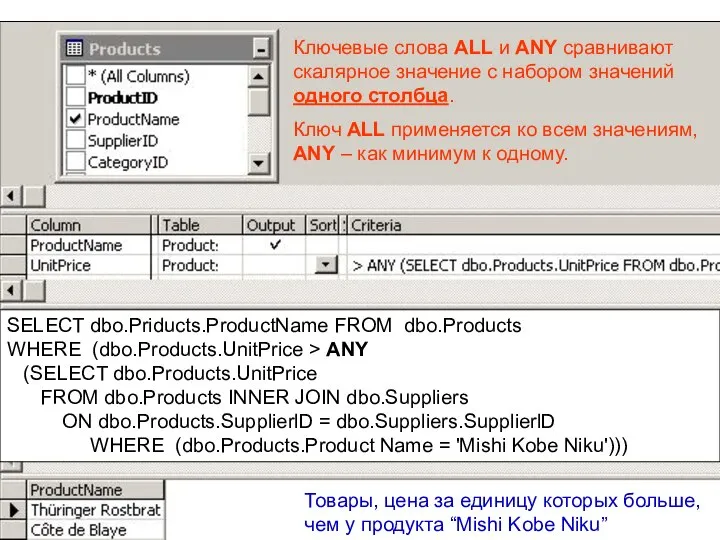
Ключевые слова ALL и ANY сравнивают скалярное значение с набором значений
Ключевые слова ALL и ANY сравнивают скалярное значение с набором значений
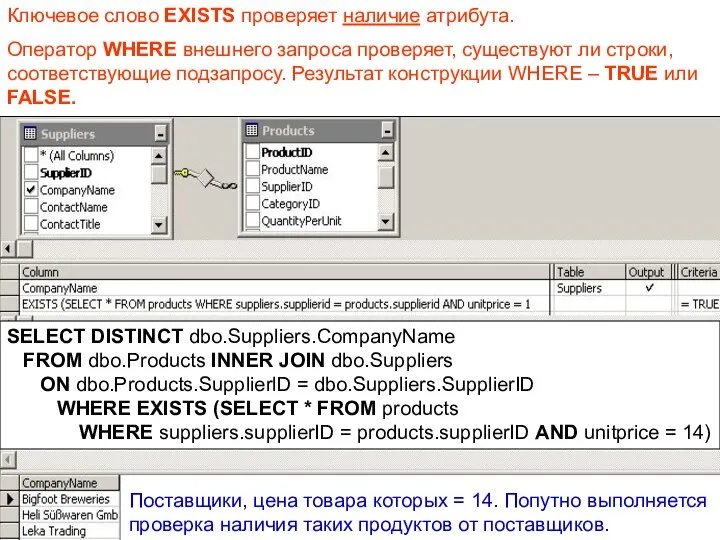
Ключевое слово EXISTS проверяет наличие атрибута.
Оператор WHERE внешнего запроса проверяет,
Ключевое слово EXISTS проверяет наличие атрибута.
Оператор WHERE внешнего запроса проверяет,
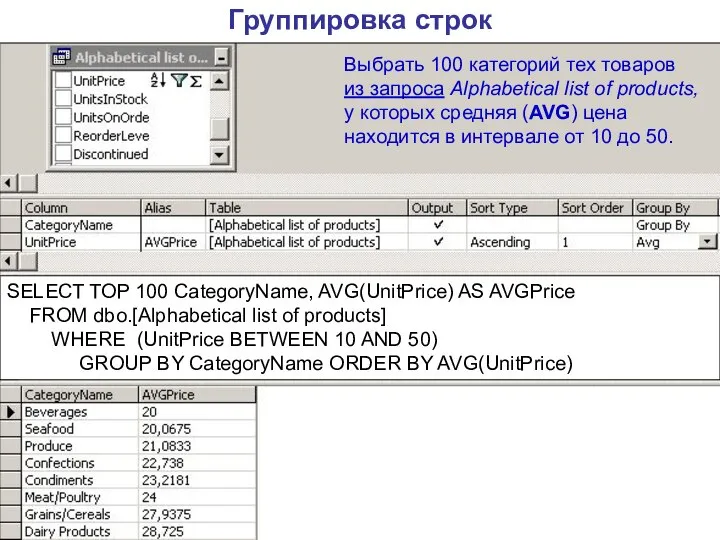
Группировка строк
Выбрать 100 категорий тех товаров
из запроса Alphabetical list of
Группировка строк
Выбрать 100 категорий тех товаров
из запроса Alphabetical list of
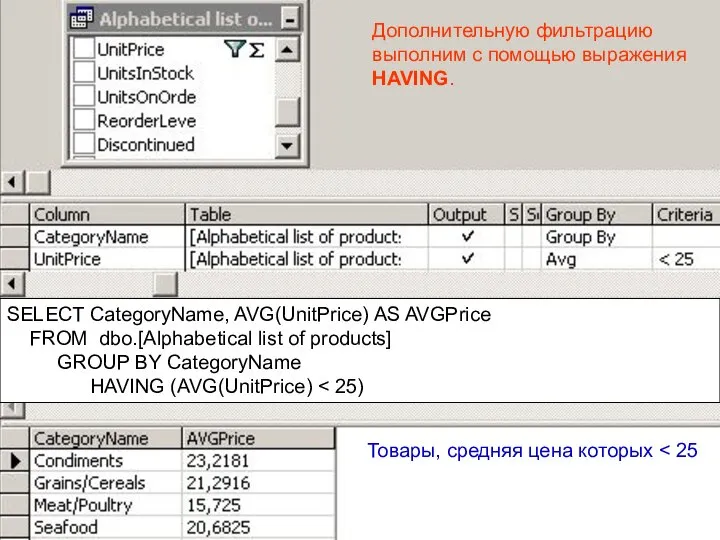
Дополнительную фильтрацию выполним с помощью выражения HAVING.
SELECT CategoryName, AVG(UnitPrice) AS
Дополнительную фильтрацию выполним с помощью выражения HAVING.
SELECT CategoryName, AVG(UnitPrice) AS
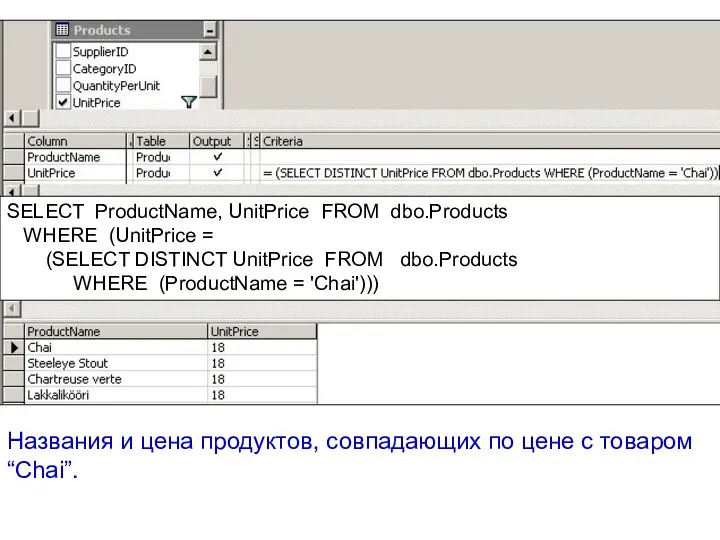
Названия и цена продуктов, совпадающих по цене с товаром “Chai”.
SELECT ProductName,
Названия и цена продуктов, совпадающих по цене с товаром “Chai”.
SELECT ProductName,
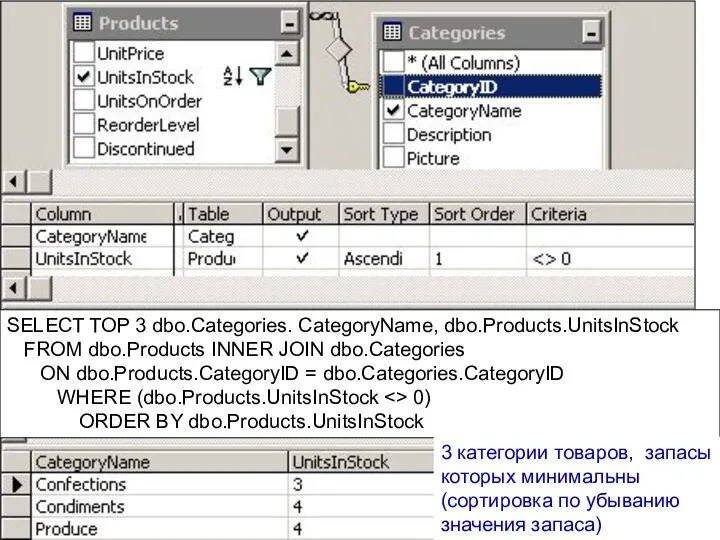
SELECT TOP 3 dbo.Categories. CategoryName, dbo.Products.UnitsInStock
FROM dbo.Products INNER JOIN dbo.Categories
SELECT TOP 3 dbo.Categories. CategoryName, dbo.Products.UnitsInStock
FROM dbo.Products INNER JOIN dbo.Categories
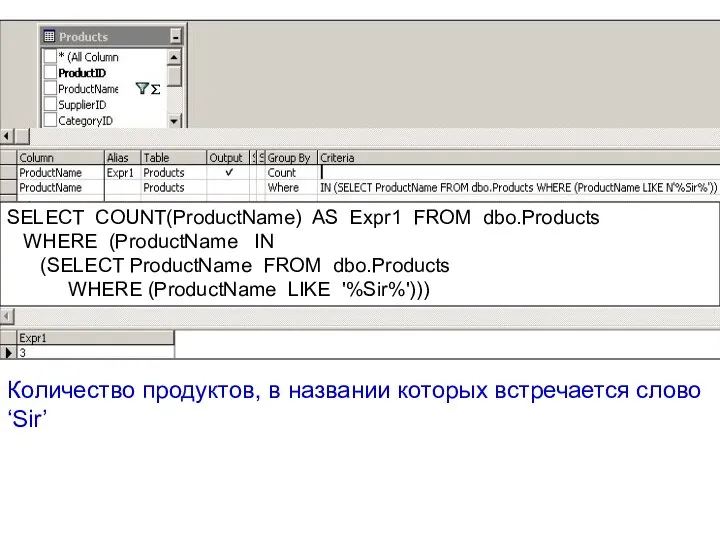
Количество продуктов, в названии которых встречается слово ‘Sir’
SELECT COUNT(ProductName) AS Ехрr1
Количество продуктов, в названии которых встречается слово ‘Sir’
SELECT COUNT(ProductName) AS Ехрr1
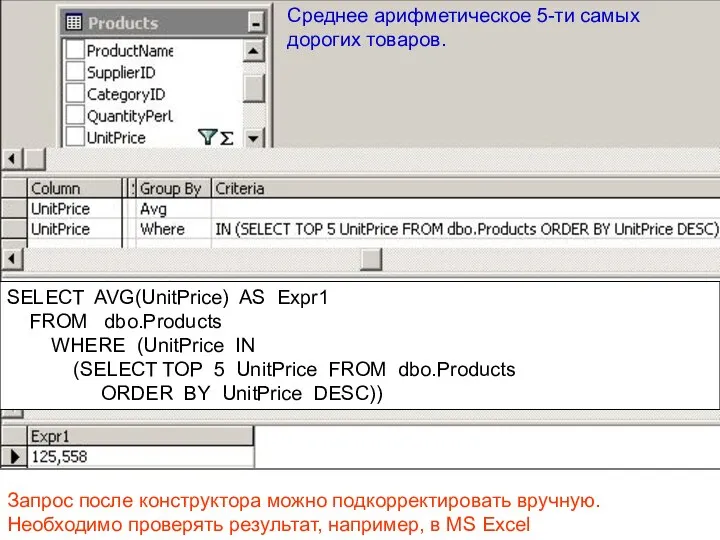
Cреднее арифметическое 5-ти самых дорогих товаров.
SELECT AVG(UnitPrice) AS Expr1
FROM
Cреднее арифметическое 5-ти самых дорогих товаров.
SELECT AVG(UnitPrice) AS Expr1
FROM
![SELECT TOP 5 сотрудник.[Код кафедры], Count(сотрудник.ФИО) AS число_сотрудников FROM сотрудник GROUP](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1303581/slide-45.jpg)
SELECT TOP 5
сотрудник.[Код кафедры], Count(сотрудник.ФИО) AS число_сотрудников
FROM сотрудник
SELECT TOP 5
сотрудник.[Код кафедры], Count(сотрудник.ФИО) AS число_сотрудников
FROM сотрудник

SELECT сотрудник.ФИО, сотрудник.оклад FROM сотрудник
WHERE (((сотрудник.оклад) Not Between 1000 And
SELECT сотрудник.ФИО, сотрудник.оклад FROM сотрудник
WHERE (((сотрудник.оклад) Not Between 1000 And
 Нам в этот день рожден Спаситель
Нам в этот день рожден Спаситель Формулы тригонометрических уравнений
Формулы тригонометрических уравнений Изобразительное искусство 10-20в Проект выполнила ученица 8 класса СОШ №16 г.Балаково Ющенко Юлия Руководитель проекта Солонина Е.
Изобразительное искусство 10-20в Проект выполнила ученица 8 класса СОШ №16 г.Балаково Ющенко Юлия Руководитель проекта Солонина Е. Дестабилизирующие факторы и способы их нейтрализации. Лекция 14
Дестабилизирующие факторы и способы их нейтрализации. Лекция 14 Архитектура средневековья. Готический стиль.
Архитектура средневековья. Готический стиль. Классификация пересечений автомобильных дорог в разных уровнях и требования к ним
Классификация пересечений автомобильных дорог в разных уровнях и требования к ним Тема: Агропромышленный комплекс Российской Федерации, сегодня и завтра. Введение 1.Современная ситуация в агропромышленном к
Тема: Агропромышленный комплекс Российской Федерации, сегодня и завтра. Введение 1.Современная ситуация в агропромышленном к История новогодней ёлки
История новогодней ёлки Презентация на тему "нетрадиционные методы в коррекционной работе" - скачать презентации по Педагогике
Презентация на тему "нетрадиционные методы в коррекционной работе" - скачать презентации по Педагогике умножение и деление на2 - презентация для начальной школы
умножение и деление на2 - презентация для начальной школы Подготовка к сочинению по картине И. Фирсова «Юный живописец»
Подготовка к сочинению по картине И. Фирсова «Юный живописец» Обучение и воспитание успехом Нет детей – есть люди, но с иным масштабом понятий, иными источниками опыта, иными стремлениями,
Обучение и воспитание успехом Нет детей – есть люди, но с иным масштабом понятий, иными источниками опыта, иными стремлениями,  Белорусы - восточнославянский народ
Белорусы - восточнославянский народ Мотиваторы. Вчера в истории
Мотиваторы. Вчера в истории Исламдық сақтандыру такафул
Исламдық сақтандыру такафул Накшатры и брак
Накшатры и брак Вопросы Определение внутренней среды орг-и. Перечислите факторы внутренней среды. Какие цели вы могли бы назвать? Что такое стру
Вопросы Определение внутренней среды орг-и. Перечислите факторы внутренней среды. Какие цели вы могли бы назвать? Что такое стру Презентация Возникновение науки
Презентация Возникновение науки Муфты. Механические муфты
Муфты. Механические муфты Презентация на тему "Подросток и суицыд" - скачать презентации по Педагогике
Презентация на тему "Подросток и суицыд" - скачать презентации по Педагогике День Конституции Российской Федерации. Викторина
День Конституции Российской Федерации. Викторина Цели в образовании Выполнили: Группа 7 Группа 8 Зарипова Ф.А. Елсуфьева С.М. Корнева Л.Н. Ерофеева Н.
Цели в образовании Выполнили: Группа 7 Группа 8 Зарипова Ф.А. Елсуфьева С.М. Корнева Л.Н. Ерофеева Н. Презентация____
Презентация____ Перевод натурального числа из десятичной системы счисления в двоичную
Перевод натурального числа из десятичной системы счисления в двоичную Традиционные религии России
Традиционные религии России Неорганические вяжущие вещества, цемент
Неорганические вяжущие вещества, цемент Метод сопряженного воздействия на уроках физической культуры 10-11 классов в общеобразовательных учреждениях (баскетбол)
Метод сопряженного воздействия на уроках физической культуры 10-11 классов в общеобразовательных учреждениях (баскетбол) Мәңгілік ел ұлттық идея аясындағы болашақ мамандарды тәрбиелеу
Мәңгілік ел ұлттық идея аясындағы болашақ мамандарды тәрбиелеу