- Моделирование численности вакансий на рынке труда Алтайского края

Содержание
- 2. . 1. Введение. Информационной базой данного исследования являются данные Федеральной службы государственной статистики за 2009–2013 гг.
- 3. Проверим исследуемый нами временной ряд на стационарность. Для этого проведем тест Дики-Фуллера на наличие единичных корней
- 4. При анализе результатов сделаны следующие выводы: для первых разностей на 5%-ном уровне значимости отклоняем нулевую гипотезу
- 5. Далее необходимо определить вид нашей моде- ли из предложенных AR, MA, ARMA. Для этого построим коррелограму
- 6. Поскольку наша коррелограма показывает, что и автокорреляционная функция, и частная автокорреляционная функция имеют убывающий и зубчатый
- 7. Так как в нашей ситуации пара значений ав- токорреляционной функции и частной автокорре- ляционной функции выпадают
- 8. При построении будем учитывать значимость коэффициентов уравнения регрессии, изменение информационных критериев и статистических ха- рактеристик. Таким
- 9. 1. Случайный характер остатков модели. Анализ графика остатков не выявил тенден- ций их изменений. 2. Нулевое
- 10. 3. Наличие гомоскедастичности. Для проверки применим тест Уайта. Для выбранной квадратичной зависимости, зна- чение вероятности нарушения
- 11. 4. Отсутствие автокорреляции остатков. Явление автокорреляции по поведению остат- ков можно выявить с помощью теста Бреуша-
- 12. 5. Подчинение остатков нормальному закону распределения. Гипотезу проверим, сравнивая рассчитанное значение статистики Жарге-Бера с крити- ческим
- 13. 3. Модель нечеткого временного ряда (НВР). Другим подходом к исследованию вре- менного ряда является использование нечетких
- 14. Для построения модели была разработана про- грамма в пакете MatLab, реализующая представ- ленный ниже алгоритм: 1.
- 15. 4. Сравнение результатов моделирова- ния и прогнозирование. Для модели ARMA получаем следующие ре- зультаты (табл. 5).
- 16. Для модели (НВР) функции принадлежности прогнозных значений для 3-го (верхний рисунок) и 4-го (нижний рисунок) кварталов
- 17. Для модели НВР ошибки еще менее значи- тельны, что указывает на адекватность получен- ной модели. Функции
- 18. Спрогнозируем численность требуемых работ- ников на 2014 г., используя построенные модели (табл. 7).
- 19. 5. Заключение. Определение потребности в рабочей силе представляет собой начальный этап кадрового планирования. Не зная, какая
- 21. Скачать презентацию
.
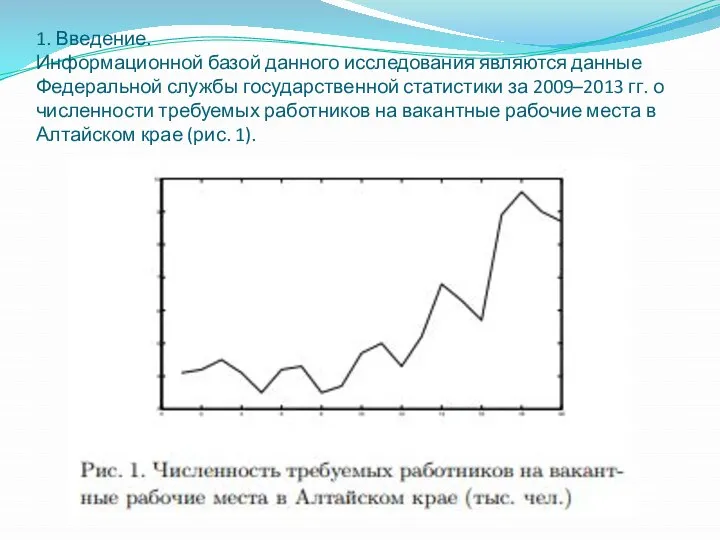
1. Введение.
Информационной базой данного исследования являются данные Федеральной службы государственной
. 1. Введение. Информационной базой данного исследования являются данные Федеральной службы государственной
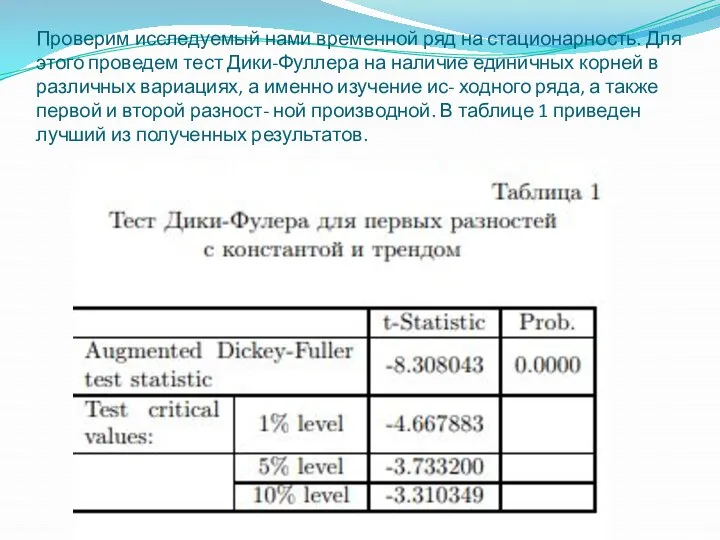
Проверим исследуемый нами временной ряд на стационарность. Для этого проведем тест
Проверим исследуемый нами временной ряд на стационарность. Для этого проведем тест

При анализе результатов сделаны следующие выводы: для первых разностей на 5%-ном
При анализе результатов сделаны следующие выводы: для первых разностей на 5%-ном
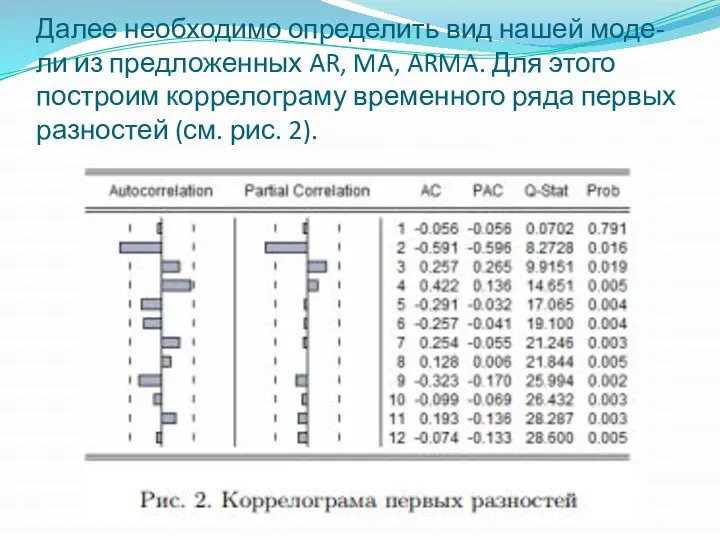
Далее необходимо определить вид нашей моде- ли из предложенных AR, MA,
Далее необходимо определить вид нашей моде- ли из предложенных AR, MA,

Поскольку наша коррелограма показывает, что и автокорреляционная функция, и частная автокорреляционная
Поскольку наша коррелограма показывает, что и автокорреляционная функция, и частная автокорреляционная

Так как в нашей ситуации пара значений ав- токорреляционной функции и
Так как в нашей ситуации пара значений ав- токорреляционной функции и
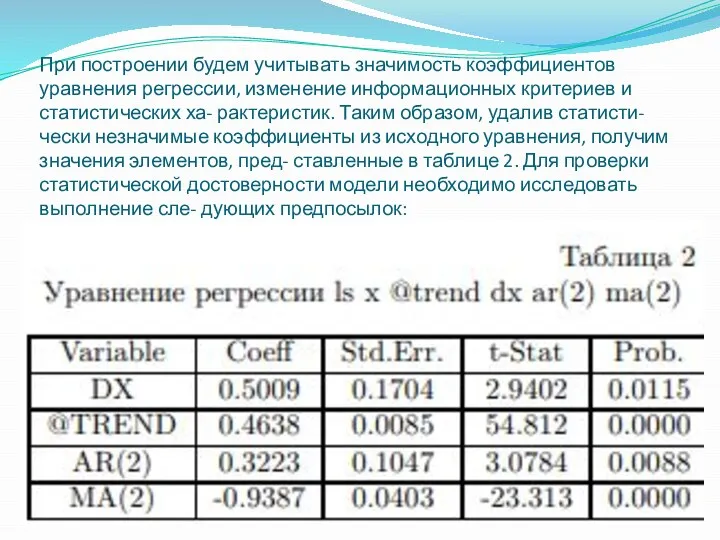
При построении будем учитывать значимость коэффициентов уравнения регрессии, изменение информационных критериев
При построении будем учитывать значимость коэффициентов уравнения регрессии, изменение информационных критериев

1. Случайный характер остатков модели. Анализ графика остатков не выявил тенден-
1. Случайный характер остатков модели. Анализ графика остатков не выявил тенден-
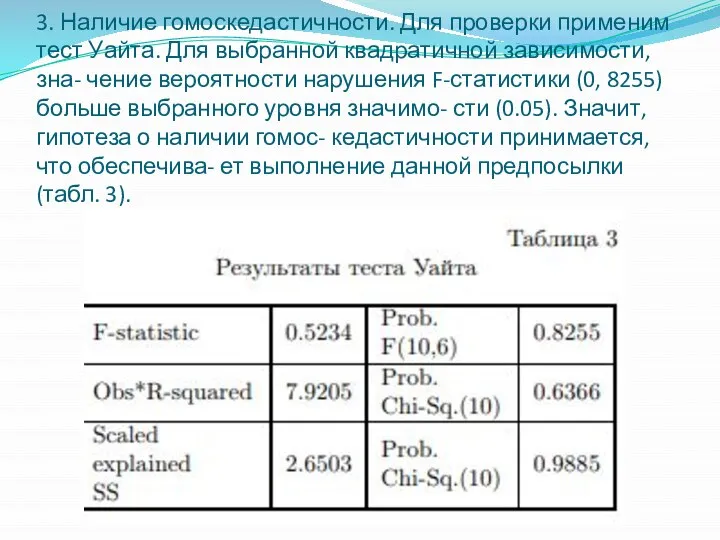
3. Наличие гомоскедастичности. Для проверки применим тест Уайта. Для выбранной квадратичной
3. Наличие гомоскедастичности. Для проверки применим тест Уайта. Для выбранной квадратичной
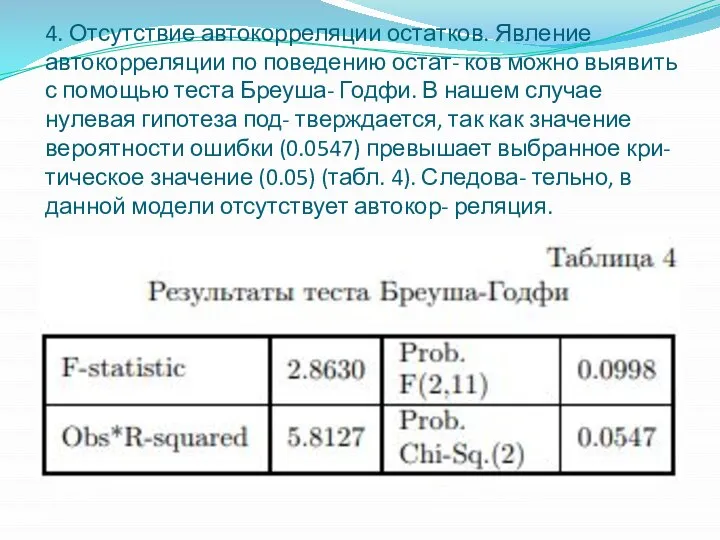
4. Отсутствие автокорреляции остатков. Явление автокорреляции по поведению остат- ков можно
4. Отсутствие автокорреляции остатков. Явление автокорреляции по поведению остат- ков можно

5. Подчинение остатков нормальному закону распределения. Гипотезу проверим, сравнивая рассчитанное значение
5. Подчинение остатков нормальному закону распределения. Гипотезу проверим, сравнивая рассчитанное значение

3. Модель нечеткого временного ряда (НВР).
Другим подходом к исследованию вре- менного
3. Модель нечеткого временного ряда (НВР).
Другим подходом к исследованию вре- менного

Для построения модели была разработана про- грамма в пакете MatLab, реализующая
Для построения модели была разработана про- грамма в пакете MatLab, реализующая
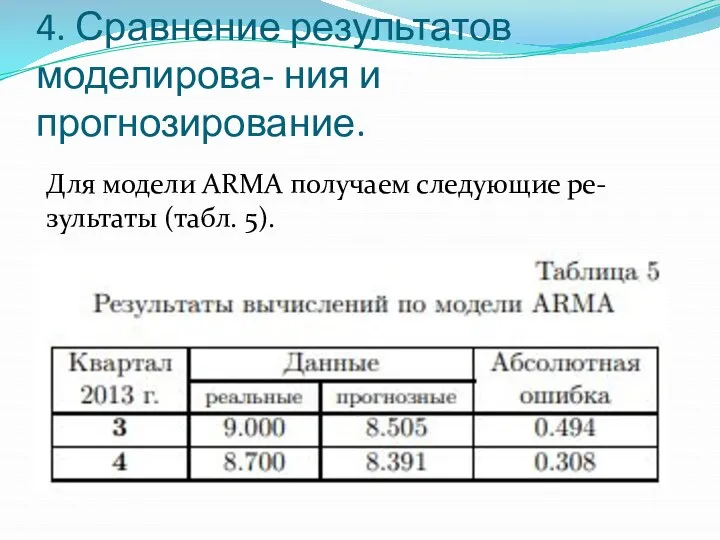
4. Сравнение результатов моделирова- ния и прогнозирование.
Для модели ARMA получаем
4. Сравнение результатов моделирова- ния и прогнозирование.
Для модели ARMA получаем

Для модели (НВР) функции принадлежности прогнозных значений для 3-го (верхний рисунок)
Для модели (НВР) функции принадлежности прогнозных значений для 3-го (верхний рисунок)
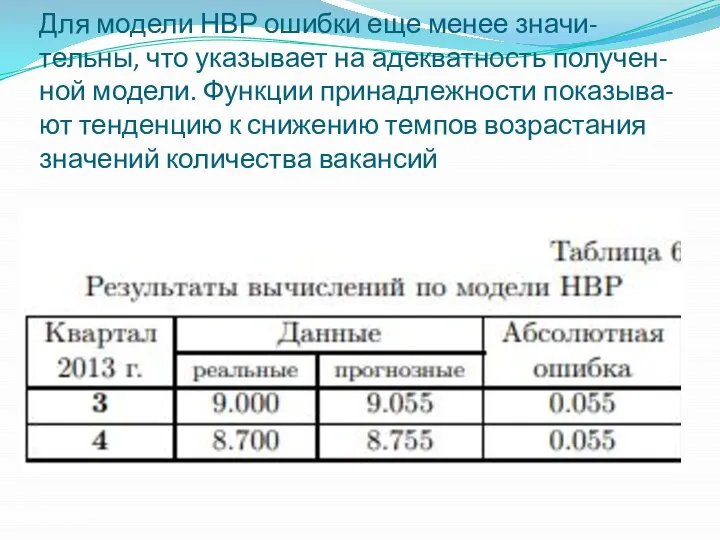
Для модели НВР ошибки еще менее значи- тельны, что указывает на
Для модели НВР ошибки еще менее значи- тельны, что указывает на
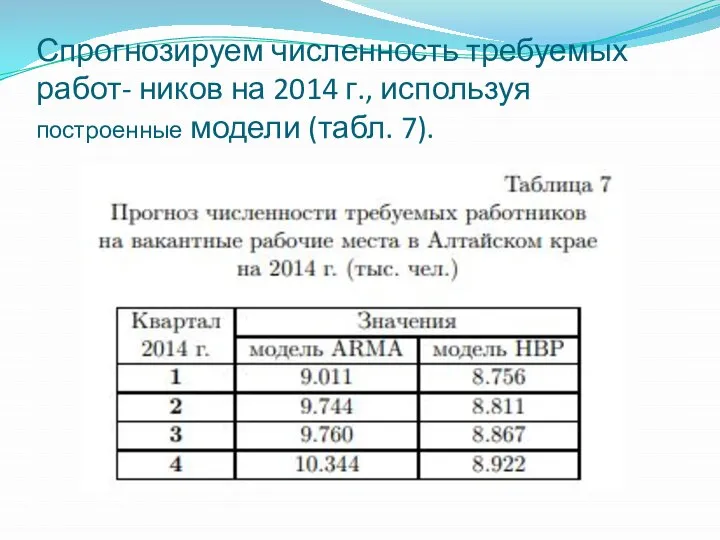
Спрогнозируем численность требуемых работ- ников на 2014 г., используя построенные модели
Спрогнозируем численность требуемых работ- ников на 2014 г., используя построенные модели

5. Заключение.
Определение потребности в рабочей силе представляет собой начальный этап
5. Заключение.
Определение потребности в рабочей силе представляет собой начальный этап
 Инфляция. Темп инфляции
Инфляция. Темп инфляции Закон спроса. Закон предложения
Закон спроса. Закон предложения Инфляция. Причины. Виды
Инфляция. Причины. Виды Engineering economics
Engineering economics Малиновский район міста Одеси. Слайды
Малиновский район міста Одеси. Слайды Автоматизированное решение для создания городских парковок
Автоматизированное решение для создания городских парковок Экономическая культура
Экономическая культура Экономика ЕС
Экономика ЕС Заң жобасын әзірлеу негіздемесі
Заң жобасын әзірлеу негіздемесі Потребление, сбережение и инвестиции
Потребление, сбережение и инвестиции Метод относительных разниц в экономических исследованиях
Метод относительных разниц в экономических исследованиях Невское перо. Открытый ежегодный конкурс по журналистике
Невское перо. Открытый ежегодный конкурс по журналистике Внешнеторговый контракт и пакет сопроводительных документов
Внешнеторговый контракт и пакет сопроводительных документов Ущерб от загрязнения окружающей природной среды
Ущерб от загрязнения окружающей природной среды Стратегия социально-экономического развития Красноперекопска до 2030 года
Стратегия социально-экономического развития Красноперекопска до 2030 года Потоковые процессы в современной экономике
Потоковые процессы в современной экономике Стратегическое планирование (коммуникационная стратегия/ бриф)
Стратегическое планирование (коммуникационная стратегия/ бриф) Экономика домашнего хозяйства. (8 класс)
Экономика домашнего хозяйства. (8 класс) Теория потребительского выбора: возможности, предпочтения, выбор. Тема 7
Теория потребительского выбора: возможности, предпочтения, выбор. Тема 7 Еколого-економічне обґрунтування структури угідь та організації сівозмін фермерського господарства
Еколого-економічне обґрунтування структури угідь та організації сівозмін фермерського господарства Финансы. Бюджет. Налоги
Финансы. Бюджет. Налоги Франчайзинг, как форма ведения бизнеса
Франчайзинг, как форма ведения бизнеса Экономическая политика в условиях реформирования рынка электрической энергии и мощности
Экономическая политика в условиях реформирования рынка электрической энергии и мощности European Union: enlargement, symbols
European Union: enlargement, symbols Организация предпринимательских сделок. Лекция 7
Организация предпринимательских сделок. Лекция 7 Инвестиционный паспорт Татищевского муниципального района Саратовской области
Инвестиционный паспорт Татищевского муниципального района Саратовской области Гендерная асимметрия на рынке труда
Гендерная асимметрия на рынке труда Презентация по экономике Финансы и кредит Денежная система
Презентация по экономике Финансы и кредит Денежная система