- Презентация "Кодирование текстовой информации 6 класс" - скачать презентации по Информатике

Содержание
- 2. Текст на внешних носителях сохраняется в виде файла. Преимущества компьютерного документа: Компактное размещение Легко удалить Легко
- 3. Любая информация кодируется в компьютере с помощью последовательностей двух цифр - 0 и 1. Он хранит
- 4. Обработкой текстовой информации на компьютере начали заниматься с 60 – х годов 20 века. Первоначально в
- 5. В 1964 году появились мощные ЭВМ IBM-360, в которых окончательно байт стал равен восьми битам, так
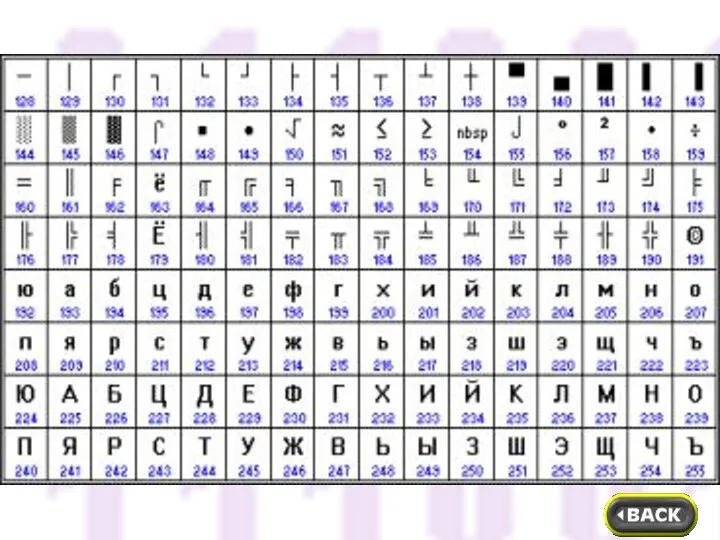
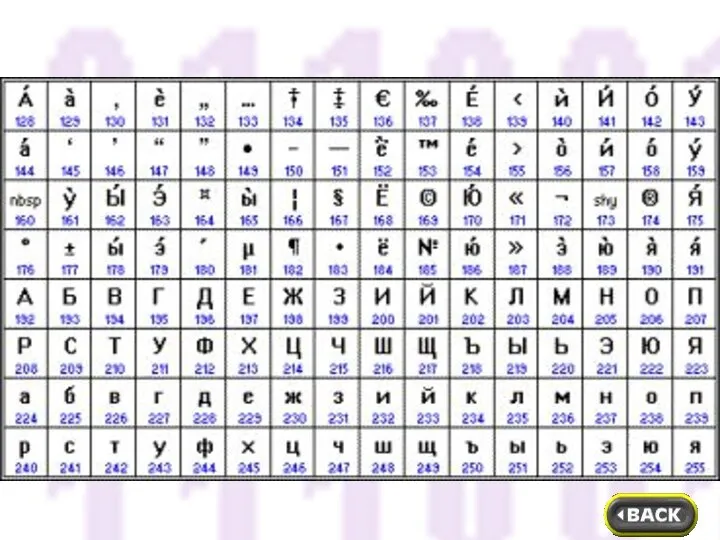
- 6. Компьютер различает символы по кодам. В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code
- 7. Коды со 128 по 255 являются национальными, т. е. в национальных кодировках одному и тому же
- 11. Скачать презентацию

Текст на внешних носителях сохраняется в виде файла.
Преимущества компьютерного
Текст на внешних носителях сохраняется в виде файла.
Преимущества компьютерного

Любая информация кодируется в компьютере с помощью последовательностей двух цифр -
Любая информация кодируется в компьютере с помощью последовательностей двух цифр -

Обработкой текстовой информации на компьютере начали заниматься с 60 – х
Обработкой текстовой информации на компьютере начали заниматься с 60 – х

В 1964 году появились мощные ЭВМ IBM-360, в которых окончательно байт
В 1964 году появились мощные ЭВМ IBM-360, в которых окончательно байт

Компьютер различает символы по кодам. В качестве международного стандарта принята кодовая
Компьютер различает символы по кодам. В качестве международного стандарта принята кодовая

Коды со 128 по 255 являются национальными, т. е. в национальных
Коды со 128 по 255 являются национальными, т. е. в национальных
 Способы записи алгоритмов
Способы записи алгоритмов Оперативные преимущества инновационной системы Questel ORBIT
Оперативные преимущества инновационной системы Questel ORBIT Профессия Журналист
Профессия Журналист Использование компьютерных технологий в учебном процессе
Использование компьютерных технологий в учебном процессе Машинная арифметика и относительные единицы
Машинная арифметика и относительные единицы Знакомство с компьютером
Знакомство с компьютером Проект. Национальная электронная библиотека
Проект. Национальная электронная библиотека Вікіпедія на пальцях
Вікіпедія на пальцях Хайрулина А.В., учитель информатики, МОУ СОШ №10, г.Кандалакша, Мурманской области
Хайрулина А.В., учитель информатики, МОУ СОШ №10, г.Кандалакша, Мурманской области  Microsoft Excel 2007 – новые возможности. Стандартные функции и работа с ними
Microsoft Excel 2007 – новые возможности. Стандартные функции и работа с ними Введение в базы данных
Введение в базы данных Презентация "MSC.Dytran - 11" - скачать презентации по Информатике
Презентация "MSC.Dytran - 11" - скачать презентации по Информатике Методы и организационные подходы построения ИС
Методы и организационные подходы построения ИС Типи даних. Лекція 1-3
Типи даних. Лекція 1-3 Исторические шифры
Исторические шифры Интеллектуальная игра по информатике
Интеллектуальная игра по информатике Первые компьютеры
Первые компьютеры Кэш-память
Кэш-память Презентация Характеристика объекта (информатика, 3 класс)
Презентация Характеристика объекта (информатика, 3 класс)  Разработка Web-сайтов с использованием языка разметки гипертекста HTML
Разработка Web-сайтов с использованием языка разметки гипертекста HTML Локальные и глобальные компьютерные сети
Локальные и глобальные компьютерные сети С и C++ — универсальные алгоритмические языки. С / С++. Тема 01
С и C++ — универсальные алгоритмические языки. С / С++. Тема 01 Обучение программированию в базовом курсе информатики Цели обучения и место в базовом курсе Содержание обучения Методические
Обучение программированию в базовом курсе информатики Цели обучения и место в базовом курсе Содержание обучения Методические  Временные таблицы и пакетные запросы
Временные таблицы и пакетные запросы Общие сведения. Назначение и применение JavaScript
Общие сведения. Назначение и применение JavaScript Презентация "Измерение информации" - скачать презентации по Информатике_
Презентация "Измерение информации" - скачать презентации по Информатике_ Если вы хотите устроиться на работу
Если вы хотите устроиться на работу Тестирование программного обеспечения
Тестирование программного обеспечения