Архитектура Tesla. Программно-аппаратный стек CUDA. Лекторы: Боресков А.В. (ВМиК МГУ) Харламов А.А. (NVidia)
- Архитектура Tesla. Программно-аппаратный стек CUDA. Лекторы: Боресков А.В. (ВМиК МГУ) Харламов А.А. (NVidia)

Содержание
- 2. Примеры многоядерных систем На первой лекции мы рассмотрели Intel Core 2 Duo SMP Cell BlueGene/L G80
- 3. Примеры многоядерных систем Мы хотели обратить ваше внимание на следующие особенности: Как правило вычислительный узел –
- 4. Tesla vs GeForce У кого есть вопросы в чем разница?
- 5. План Архитектура Tesla Программная модель CUDA Синтаксические особенности CUDA
- 6. Архитектура Tesla: Мультипроцессор Tesla 8
- 7. Архитектура Tesla Мультипроцессор Tesla 10
- 8. Архитектура Tesla 10 Interconnection Network
- 9. Архитектура Маштабируемость: [+][-] SM внутри TPC [+][-] TPC [+][-] DRAM партиции Схожие архитектуры: Tesla 8: 8800
- 10. Технические детали RTM CUDA Programming Guide Run CUDAHelloWorld Печатает аппаратно зависимые параметры Размер shared памяти Кол-во
- 11. План Архитектура Tesla Синтаксические особенности CUDA Программная модель CUDA
- 12. Программная модель CUDA GPU (device) это вычислительное устройство, которое: Является сопроцессором к CPU (host) Имеет собственную
- 13. Программная модель CUDA Последовательные части кода выполняются на CPU Массивно-параллельные части кода выполняются на GPU как
- 14. Программная модель CUDA Параллельная часть кода выполняется как большое количество нитей Нити группируются в блоки фиксированного
- 15. Программная модель CUDA Десятки тысяч потоков for (int ix = 0; ix { pData[ix] = f(ix);
- 16. Программная модель CUDA Потоки в CUDA объединяются в блоки: Возможна 1D, 2D, 3D топология блока Общее
- 17. Программная модель CUDA Потоки в блоке могут разделять ресурсы со своими соседями float g_Data[gN]; for (int
- 18. Программная модель CUDA Блоки могут использовать shared память Т.к. блок целиком выполняется на одном SM Объем
- 19. Программная модель CUDA Блоки потоков объединяются в сетку (grid) потоков Возможна 1D, 2D топология сетки блоков
- 20. План Архитектура Tesla Синтаксические особенности CUDA Программная модель CUDA
- 21. Синтаксис CUDA CUDA – это расширение языка C [+] спецификаторы для функций и переменных [+] новые
- 22. Синтаксис CUDA Спецификаторы Спецификатор функций Спецификатор переменных
- 23. Синтаксис CUDA Встроенные переменные Сравним CPU код vs CUDA kernel: __global__ void incKernel ( float *
- 24. Синтаксис CUDA Встроенные переменные В любом CUDA kernel’e доступны: dim3 gridDim; uint3 blockIdx; dim3 blockDim; uint3
- 25. Синтаксис CUDA Директивы запуска ядра Как запустить ядро с общим кол-во тредов равным nx? incKernel >>
- 26. Как скомпилировать CUDA код NVCC – компилятор для CUDA Основными опциями команды nvcc являются: -deviceemu -
- 27. Ресуры нашего курса CUDA.CS.MSU.SU Место для вопросов и дискуссий Место для материалов нашего курса Место для
- 29. Скачать презентацию

Примеры многоядерных систем
На первой лекции мы рассмотрели
Intel Core 2 Duo
SMP
Cell
BlueGene/L
G80 /
Примеры многоядерных систем
На первой лекции мы рассмотрели
Intel Core 2 Duo
SMP
Cell
BlueGene/L
G80 /

Примеры многоядерных систем
Мы хотели обратить ваше внимание на следующие особенности:
Как правило
Примеры многоядерных систем
Мы хотели обратить ваше внимание на следующие особенности:
Как правило

Tesla vs GeForce
У кого есть вопросы в чем разница?
Tesla vs GeForce
У кого есть вопросы в чем разница?

План
Архитектура Tesla
Программная модель CUDA
Синтаксические особенности CUDA
План
Архитектура Tesla
Программная модель CUDA
Синтаксические особенности CUDA
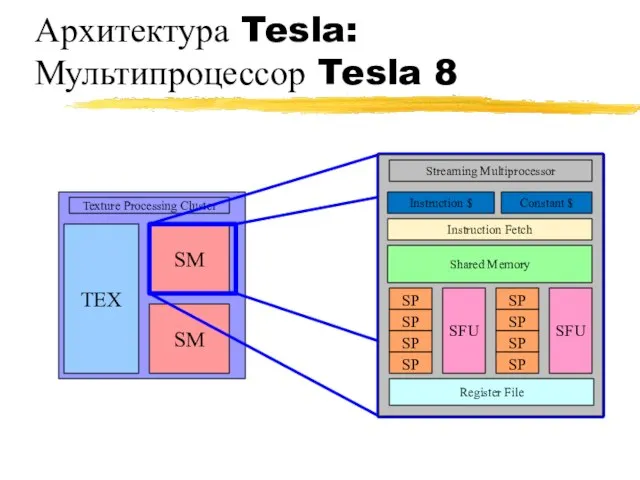
Архитектура Tesla:
Мультипроцессор Tesla 8
Архитектура Tesla:
Мультипроцессор Tesla 8
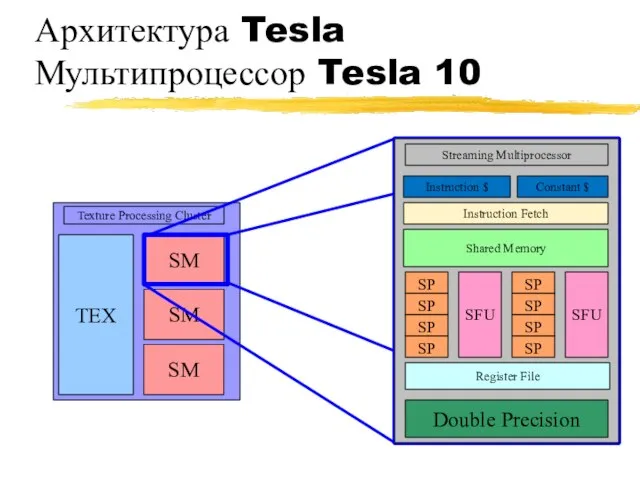
Архитектура Tesla
Мультипроцессор Tesla 10
Архитектура Tesla
Мультипроцессор Tesla 10
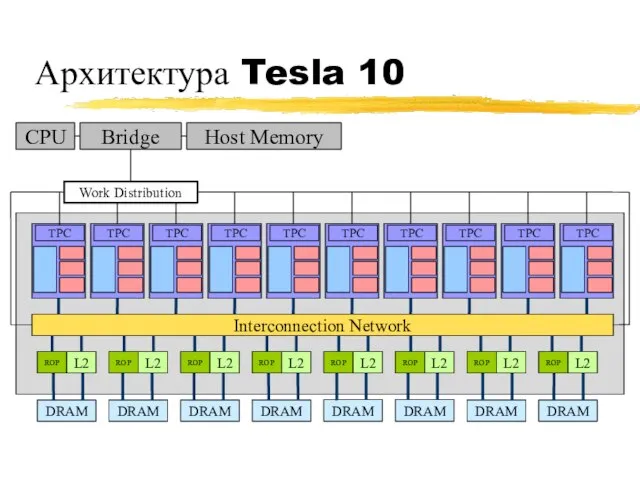
Архитектура Tesla 10
Interconnection Network
Архитектура Tesla 10
Interconnection Network
![Архитектура Маштабируемость: [+][-] SM внутри TPC [+][-] TPC [+][-] DRAM партиции](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1215774/slide-8.jpg)
Архитектура
Маштабируемость:
[+][-] SM внутри TPC
[+][-] TPC
[+][-] DRAM партиции
Схожие архитектуры:
Tesla 8: 8800 GTX
Tesla
Архитектура
Маштабируемость:
[+][-] SM внутри TPC
[+][-] TPC
[+][-] DRAM партиции
Схожие архитектуры:
Tesla 8: 8800 GTX
Tesla

Технические детали
RTM CUDA Programming Guide
Run CUDAHelloWorld
Печатает аппаратно зависимые параметры
Размер shared памяти
Кол-во
Технические детали
RTM CUDA Programming Guide
Run CUDAHelloWorld
Печатает аппаратно зависимые параметры
Размер shared памяти
Кол-во

План
Архитектура Tesla
Синтаксические особенности CUDA
Программная модель CUDA
План
Архитектура Tesla
Синтаксические особенности CUDA
Программная модель CUDA

Программная модель CUDA
GPU (device) это вычислительное устройство, которое:
Является сопроцессором к
Программная модель CUDA
GPU (device) это вычислительное устройство, которое:
Является сопроцессором к

Программная модель CUDA
Последовательные части кода выполняются на CPU
Массивно-параллельные части кода выполняются
Программная модель CUDA
Последовательные части кода выполняются на CPU
Массивно-параллельные части кода выполняются

Программная модель CUDA
Параллельная часть кода выполняется как большое количество нитей
Нити группируются
Программная модель CUDA
Параллельная часть кода выполняется как большое количество нитей
Нити группируются

Программная модель CUDA
Десятки тысяч потоков
for (int ix = 0; ix <
Программная модель CUDA
Десятки тысяч потоков
for (int ix = 0; ix <
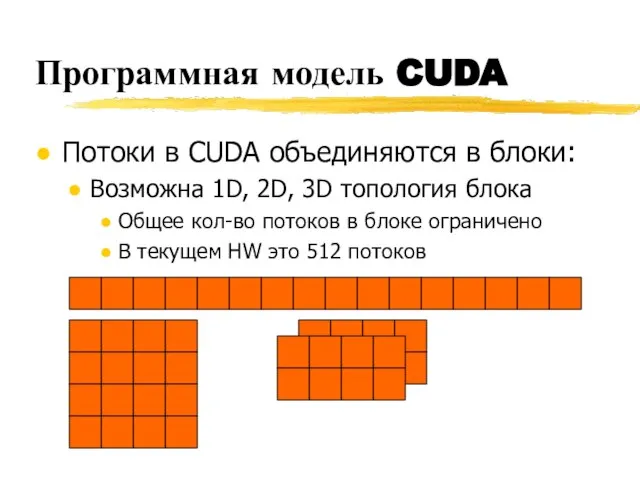
Программная модель CUDA
Потоки в CUDA объединяются в блоки:
Возможна 1D, 2D, 3D
Программная модель CUDA
Потоки в CUDA объединяются в блоки:
Возможна 1D, 2D, 3D

Программная модель CUDA
Потоки в блоке могут разделять ресурсы со своими соседями
float
Программная модель CUDA
Потоки в блоке могут разделять ресурсы со своими соседями
float

Программная модель CUDA
Блоки могут использовать shared память
Т.к. блок целиком выполняется
Программная модель CUDA
Блоки могут использовать shared память
Т.к. блок целиком выполняется
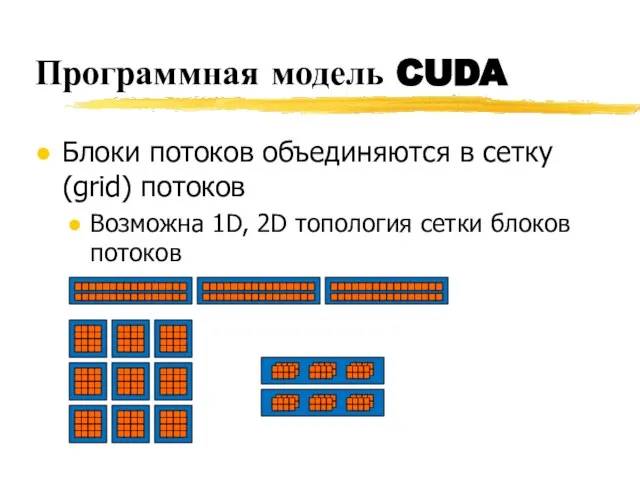
Программная модель CUDA
Блоки потоков объединяются в сетку (grid) потоков
Возможна 1D, 2D
Программная модель CUDA
Блоки потоков объединяются в сетку (grid) потоков
Возможна 1D, 2D

План
Архитектура Tesla
Синтаксические особенности CUDA
Программная модель CUDA
План
Архитектура Tesla
Синтаксические особенности CUDA
Программная модель CUDA
![Синтаксис CUDA CUDA – это расширение языка C [+] спецификаторы для](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1215774/slide-20.jpg)
Синтаксис CUDA
CUDA – это расширение языка C
[+] спецификаторы для
Синтаксис CUDA
CUDA – это расширение языка C
[+] спецификаторы для
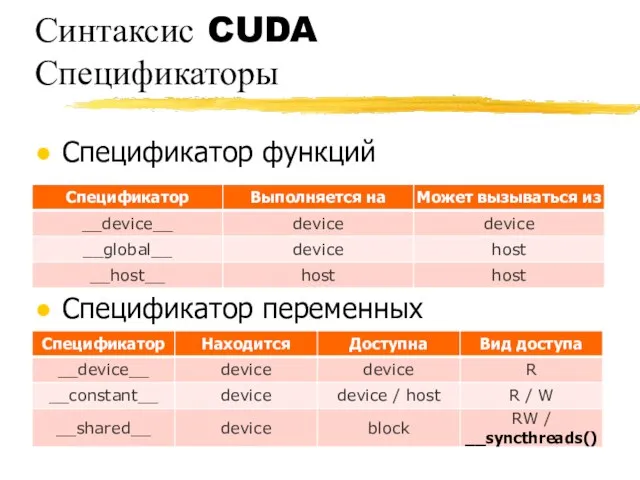
Синтаксис CUDA
Спецификаторы
Спецификатор функций
Спецификатор переменных
Синтаксис CUDA
Спецификаторы
Спецификатор функций
Спецификатор переменных

Синтаксис CUDA
Встроенные переменные
Сравним CPU код vs CUDA kernel:
__global__ void incKernel
Синтаксис CUDA
Встроенные переменные
Сравним CPU код vs CUDA kernel:
__global__ void incKernel

Синтаксис CUDA
Встроенные переменные
В любом CUDA kernel’e доступны:
dim3 gridDim;
uint3 blockIdx;
dim3 blockDim;
uint3 threadIdx;
int
Синтаксис CUDA
Встроенные переменные
В любом CUDA kernel’e доступны:
dim3 gridDim;
uint3 blockIdx;
dim3 blockDim;
uint3 threadIdx;
int

Синтаксис CUDA
Директивы запуска ядра
Как запустить ядро с общим кол-во тредов
Синтаксис CUDA
Директивы запуска ядра
Как запустить ядро с общим кол-во тредов

Как скомпилировать CUDA код
NVCC – компилятор для CUDA
Основными опциями команды nvcc являются:
-deviceemu - компиляция
Как скомпилировать CUDA код
NVCC – компилятор для CUDA
Основными опциями команды nvcc являются:
-deviceemu - компиляция

Ресуры нашего курса
CUDA.CS.MSU.SU
Место для вопросов и дискуссий
Место для материалов нашего курса
Место
Ресуры нашего курса
CUDA.CS.MSU.SU
Место для вопросов и дискуссий
Место для материалов нашего курса
Место
 Визуализация проекта
Визуализация проекта Понятие алгоритма и его свойства. Блок-схема алгоритма
Понятие алгоритма и его свойства. Блок-схема алгоритма  Презентация "РЕШЕНИЕ ЗАДАЧИ ОПТИМАЛЬНОГО ПЛАНИРОВАНИЯ С ПРИМЕНЕНИЕМ ЭЛЕКТРОННЫХ ТАБЛИЦ" - скачать презентации по Информатик
Презентация "РЕШЕНИЕ ЗАДАЧИ ОПТИМАЛЬНОГО ПЛАНИРОВАНИЯ С ПРИМЕНЕНИЕМ ЭЛЕКТРОННЫХ ТАБЛИЦ" - скачать презентации по Информатик Базы данных (БД)
Базы данных (БД) Моделирование документного фонда
Моделирование документного фонда Основные типы данных в Python. Массивы
Основные типы данных в Python. Массивы Формы и отчеты в СУБД Access
Формы и отчеты в СУБД Access Единицы измерения информации
Единицы измерения информации Переменные, типы, операции. JavaScript
Переменные, типы, операции. JavaScript ROFLANRABOTA2.SEMADOG
ROFLANRABOTA2.SEMADOG Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной фо
Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной фо Протоколы и стеки протоколов
Протоколы и стеки протоколов Структуры, перечисления
Структуры, перечисления Технология телевизионных ток-шоу
Технология телевизионных ток-шоу Презентация "Признаки и действия оъекта и его составных частей" - скачать презентации по Информатике
Презентация "Признаки и действия оъекта и его составных частей" - скачать презентации по Информатике ИТ-рынок России для нужд государственного управления
ИТ-рынок России для нужд государственного управления Целевая аудитория сервиса – итоговое определение ЦА
Целевая аудитория сервиса – итоговое определение ЦА Обозначение темы урока: обобщите ваши действия при выполнении контрольной работы
Обозначение темы урока: обобщите ваши действия при выполнении контрольной работы Презентация Операторы ветвления
Презентация Операторы ветвления Презентация "Создание проекта «Анимированная открытка ветерану» в среде ЛогоМиры" - скачать презентации по Информатике
Презентация "Создание проекта «Анимированная открытка ветерану» в среде ЛогоМиры" - скачать презентации по Информатике Рисование в Word и Power Point Векторная графика. Справочный материал
Рисование в Word и Power Point Векторная графика. Справочный материал Проектирование баз данных. (Лекция 8, 9)
Проектирование баз данных. (Лекция 8, 9) Проектирование локальной вычислительной сети по технологии Ethernet на примере администрации
Проектирование локальной вычислительной сети по технологии Ethernet на примере администрации Арт-мэм. Интерпретация искусства в сети
Арт-мэм. Интерпретация искусства в сети Защита данных на телефонах и планшетах на базе Android
Защита данных на телефонах и планшетах на базе Android Теория Информационных Процессов и Систем. Тема №2: Основные понятия
Теория Информационных Процессов и Систем. Тема №2: Основные понятия Структурная схема ГИС
Структурная схема ГИС Тема №2 Устройства управления. Занятие №1/3 Система прерывания программ
Тема №2 Устройства управления. Занятие №1/3 Система прерывания программ