- Хеш-таблицы. Хеш-функции

Содержание
- 2. Введение Задача: Реализовать динамическое множество (key-value storage) со стандартными операциями вставки элемента (Insert), удаления элемента (Delete),
- 3. Таблицы с прямой адресацией Пусть требуется реализовать динамическое множество, где каждый элемент имеет ключ из совокупности
- 4. Таблицы с прямой адресацией Пусть требуется реализовать динамическое множество, где каждый элемент имеет ключ из совокупности
- 5. Таблицы с прямой адресацией. Иллюстрация. U – множество всех возможных ключей Введение Таблицы с прямой адресацией
- 6. Таблицы с прямой адресацией. Иллюстрация. K – множество всех реальных ключей (имеются объекты с ключами из
- 7. Таблицы с прямой адресацией. Иллюстрация. T – таблица с прямой адресацией (массив) размера |U| Таблица может
- 8. Таблицы с прямой адресацией. Иллюстрация. Ключи используются для того, чтобы уникально определять каждый объект. Введение Таблицы
- 9. Таблицы с прямой адресацией. Иллюстрация. В i-ой ячейке содержится указатель на элемент с ключом i. Каждый
- 10. Таблицы с прямой адресацией. Операции. Реализация операций тривиальна. Direct-Address-Search(T,k) // T[] – массив, k – ключ
- 11. Таблицы с прямой адресацией. Вариации. Если нет необходимости в дополнительных полях объектов динамического множества, сами элементы
- 12. Таблицы с прямой адресацией. Вариации. В объекте можно не хранить информацию о значении ключа, т.к. индекс
- 13. Таблицы с прямой адресацией. Недостатки. Если совокупность ключей велика, то хранение таблицы T размером |U| непрактично
- 14. Хеш-таблицы Когда используются хеш-таблицы: множество K реально сохраненных ключей мало по сравнению с |U|. Требования к
- 15. Хеш-таблицы. Иллюстрация. Объект с ключом ki сохраняется в таблицу по индексу h(ki). Введение Таблицы с прямой
- 16. Хеш-таблицы. Иллюстрация. Возможна ситуация, когда разным ключам соответствуют одинаковые хеш-значения. Введение Таблицы с прямой адресацией Хеш-таблицы
- 17. Хеш-таблицы. Коллизии. Опр. Коллизией называется ситуация, когда два ключа имеют одно и то же хеш-значение, а
- 18. Хеш-таблицы. Коллизии. Методы разрешения коллизий: Метод разрешения с помощью цепочек Метод открытой адресации Введение Таблицы с
- 19. Особенности использования хэш-функций Найти хэш-функцию, которая минимизирует коллизии Хорошая хэш функция должна использовать всю информацию, которая
- 20. Метод разрешения с помощью цепочек
- 21. Разрешение коллизий с помощью цепочек Суть метода: все элементы, хешированные в одну и ту же ячейку,
- 22. Разрешение коллизий с помощью цепочек. Иллюстрация Каждая ячейка T[j] хеш-таблицы содержит указатель на связный список всех
- 23. Разрешение коллизий с помощью цепочек. Операции Реализация операций работы с таблицей: Суть метода Операции Метод деления
- 24. Разрешение коллизий с помощью цепочек. Операции Реализация операций работы с таблицей: Суть метода Операции Метод деления
- 25. Разрешение коллизий с помощью цепочек. Операции Реализация операций работы с таблицей: Суть метода Операции Метод деления
- 26. Разрешение коллизий с помощью цепочек Пусть n элементов хранятся в хеш-таблице T с m ячейками. Будем
- 27. Разрешение коллизий с помощью цепочек В худшем случае: все n ключей имеют одинаковое хеш-значение и попадают
- 28. Разрешение коллизий с помощью цепочек Обозначим длины списков T[j] для j=0,1,…,m-1 как nj, так что n0
- 29. Разрешение коллизий с помощью цепочек Примечание. Если количество элементов n пропорционально количеству ячеек m в хэш-таблице,
- 30. Разрешение коллизий с помощью цепочек. Важно Для качественной хеш-функции должно выполняться предположение простого равномерного хеширования. Помещаемые
- 31. Разрешение коллизий с помощью цепочек. Строковые ключи Метод преобразования ключей строкового типа в числовой: Пусть есть
- 32. Разрешение коллизий с помощью цепочек. Методы вычисления хеш-значения по ключу: Метод деления Метод умножения Универсальное хеширование
- 33. Хеш-функции. Метод деления. Суть метода: Хеш-значение ключа k определяется как остаток от деления на количество ячеек
- 34. Хеш-функции. Метод умножения. Построение хеш-функции выполняется в 2 этапа: Выбираем константу 0 Полученное в п.1 число
- 35. Хеш-функции. Метод умножения. Рекомендация для технической оптимизации: m перестает быть критичным обычно m выбирается равной степени
- 36. Хеш-функции. Метод умножения. Вычисление функции h(k): Умножаем k на w–битовое целое число s=A*2w Результат умножения –
- 37. Хеш-функции. Метод умножения. Вычисление функции h(k): Умножаем k на w–битовое целое число s=A*2w Результат умножения –
- 38. Хеш-функции. Метод умножения. Вычисление функции h(k): Умножаем k на w–битовое целое число s=A*2w Результат умножения –
- 39. Хеш-функции. Метод умножения. Вычисление функции h(k): Умножаем k на w–битовое целое число s=A*2w Результат умножения –
- 40. Метод умножения. Пример. Кнут в своей книге рекомендует в качестве константы Пример. Пусть k = 123456,
- 41. Хеш-функции. Универсальное хеширование. Предположим есть недоброжелатель, знающий, какая именно хеш-функция используется и умышленно выбирающий ключи так,
- 42. Пример универсального хеширования. Простой пример класса хеш-функций для универсального хеширования: Выберем простое число p достаточно большое,
- 43. Пример универсального хеширования. Получили семейство хеш-функций Hpm={hab: a∈ Zp* и b∈ Zp}. Причем размер m выходного
- 44. Метод открытой адресации
- 45. Хэш-функции. Метод открытой адресации Суть метода: В ячейке хеш-таблицы хранится либо элемент динамического множества, либо NULL
- 46. Метод открытой адресации. Исследование таблицы Поиск элемента в таблице – это исследование ячеек в определенной последовательности.
- 47. Хэш-функции. Метод открытой адресации Последовательность исследований для каждого ключа k есть перестановка на множестве {0,1,…,m-1} .
- 48. Хэш-функции. Метод открытой адресации Последовательность исследований для каждого ключа k есть перестановка на множестве {0,1,…,m-1} .
- 49. Хэш-функции. Метод открытой адресации Последовательность исследований для каждого ключа k есть перестановка на множестве {0,1,…,m-1} .
- 50. Хэш-функции. Метод открытой адресации Последовательность исследований для каждого ключа k есть перестановка на множестве {0,1,…,m-1} .
- 51. Хэш-функции. Метод открытой адресации Реализация функции поиска: Прим. Не забываем предположение о равномерном хешировании: для каждого
- 52. Хэш-функции. Метод открытой адресации Реализация функции поиска: Прим. Не забываем предположение о равномерном хешировании: для каждого
- 53. Метод открытой адресации. Линейное исследование. Используется вспомогательная хэш-функция h`: U → {0,1,…,m-1} Для вычисления последовательности исследований
- 54. Метод открытой адресации. Линейное исследование. Проблема метода: первичная кластеризация. Пример: добавим в хеш-таблицу размера m=10 с
- 55. Метод открытой адресации. Квадратичное исследование. Используется хэш-функция где h` - вспомогательная хэш-функция, c1 и c2 –
- 56. Метод открытой адресации. Двойное хеширование. Используется хеш-функция где h1, h2 - вспомогательные хеш-функции, i = 0,1,…,m-1.
- 58. Скачать презентацию

Введение
Задача:
Реализовать динамическое множество (key-value storage) со стандартными операциями вставки элемента (Insert),
Введение
Задача:
Реализовать динамическое множество (key-value storage) со стандартными операциями вставки элемента (Insert),

Таблицы с прямой адресацией
Пусть требуется реализовать динамическое множество, где каждый элемент
Таблицы с прямой адресацией
Пусть требуется реализовать динамическое множество, где каждый элемент

Таблицы с прямой адресацией
Пусть требуется реализовать динамическое множество, где каждый элемент
Таблицы с прямой адресацией
Пусть требуется реализовать динамическое множество, где каждый элемент
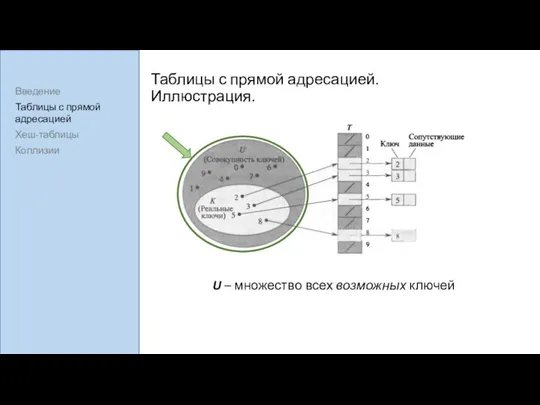
Таблицы с прямой адресацией. Иллюстрация.
U – множество всех возможных ключей
Введение
Таблицы с
Таблицы с прямой адресацией. Иллюстрация.
U – множество всех возможных ключей
Введение
Таблицы с

Таблицы с прямой адресацией. Иллюстрация.
K – множество всех реальных ключей (имеются
Таблицы с прямой адресацией. Иллюстрация.
K – множество всех реальных ключей (имеются
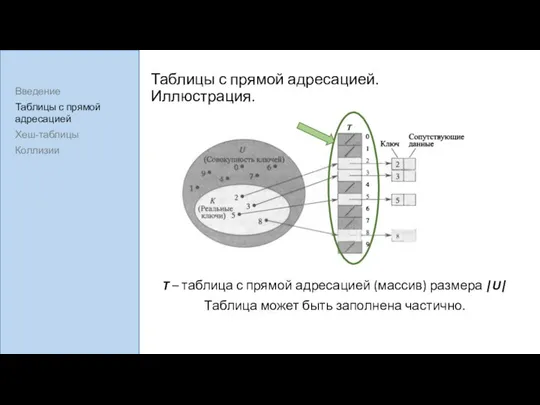
Таблицы с прямой адресацией. Иллюстрация.
T – таблица с прямой адресацией (массив)
Таблицы с прямой адресацией. Иллюстрация.
T – таблица с прямой адресацией (массив)

Таблицы с прямой адресацией. Иллюстрация.
Ключи используются для того,
чтобы уникально определять
Таблицы с прямой адресацией. Иллюстрация.
Ключи используются для того,
чтобы уникально определять

Таблицы с прямой адресацией. Иллюстрация.
В i-ой ячейке содержится указатель на элемент
Таблицы с прямой адресацией. Иллюстрация.
В i-ой ячейке содержится указатель на элемент
![Таблицы с прямой адресацией. Операции. Реализация операций тривиальна. Direct-Address-Search(T,k) // T[]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/713728/slide-9.jpg)
Таблицы с прямой адресацией. Операции.
Реализация операций тривиальна.
Direct-Address-Search(T,k) // T[] – массив,
Таблицы с прямой адресацией. Операции.
Реализация операций тривиальна.
Direct-Address-Search(T,k) // T[] – массив,

Таблицы с прямой адресацией. Вариации.
Если нет необходимости в дополнительных полях объектов
Таблицы с прямой адресацией. Вариации.
Если нет необходимости в дополнительных полях объектов

Таблицы с прямой адресацией. Вариации.
В объекте можно не хранить информацию о
Таблицы с прямой адресацией. Вариации.
В объекте можно не хранить информацию о

Таблицы с прямой адресацией. Недостатки.
Если совокупность ключей велика, то хранение таблицы
Таблицы с прямой адресацией. Недостатки.
Если совокупность ключей велика, то хранение таблицы

Хеш-таблицы
Когда используются хеш-таблицы:
множество K реально сохраненных ключей мало по сравнению с
Хеш-таблицы
Когда используются хеш-таблицы:
множество K реально сохраненных ключей мало по сравнению с

Хеш-таблицы. Иллюстрация.
Объект с ключом ki сохраняется в таблицу по индексу h(ki).
Введение
Таблицы
Хеш-таблицы. Иллюстрация.
Объект с ключом ki сохраняется в таблицу по индексу h(ki).
Введение
Таблицы

Хеш-таблицы. Иллюстрация.
Возможна ситуация, когда разным ключам соответствуют
одинаковые хеш-значения.
Введение
Таблицы с прямой
Хеш-таблицы. Иллюстрация.
Возможна ситуация, когда разным ключам соответствуют
одинаковые хеш-значения.
Введение
Таблицы с прямой

Хеш-таблицы. Коллизии.
Опр. Коллизией называется ситуация, когда два ключа имеют одно и
Хеш-таблицы. Коллизии.
Опр. Коллизией называется ситуация, когда два ключа имеют одно и

Хеш-таблицы. Коллизии.
Методы разрешения коллизий:
Метод разрешения с помощью цепочек
Метод открытой адресации
Введение
Таблицы с
Хеш-таблицы. Коллизии.
Методы разрешения коллизий:
Метод разрешения с помощью цепочек
Метод открытой адресации
Введение
Таблицы с

Особенности использования хэш-функций
Найти хэш-функцию, которая минимизирует коллизии
Хорошая хэш функция должна использовать
Особенности использования хэш-функций
Найти хэш-функцию, которая минимизирует коллизии
Хорошая хэш функция должна использовать

Метод разрешения с помощью цепочек
Метод разрешения с помощью цепочек

Разрешение коллизий с помощью цепочек
Суть метода:
все элементы, хешированные в одну и
Разрешение коллизий с помощью цепочек
Суть метода:
все элементы, хешированные в одну и
![Разрешение коллизий с помощью цепочек. Иллюстрация Каждая ячейка T[j] хеш-таблицы содержит](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/713728/slide-21.jpg)
Разрешение коллизий с помощью цепочек. Иллюстрация
Каждая ячейка T[j] хеш-таблицы содержит указатель
Разрешение коллизий с помощью цепочек. Иллюстрация
Каждая ячейка T[j] хеш-таблицы содержит указатель

Разрешение коллизий с помощью цепочек. Операции
Реализация операций работы с таблицей:
Суть метода
Операции
Метод
Разрешение коллизий с помощью цепочек. Операции
Реализация операций работы с таблицей:
Суть метода
Операции
Метод

Разрешение коллизий с помощью цепочек. Операции
Реализация операций работы с таблицей:
Суть метода
Операции
Метод
Разрешение коллизий с помощью цепочек. Операции
Реализация операций работы с таблицей:
Суть метода
Операции
Метод

Разрешение коллизий с помощью цепочек. Операции
Реализация операций работы с таблицей:
Суть метода
Операции
Метод
Разрешение коллизий с помощью цепочек. Операции
Реализация операций работы с таблицей:
Суть метода
Операции
Метод

Разрешение коллизий с помощью цепочек
Пусть n элементов хранятся в хеш-таблице T
Разрешение коллизий с помощью цепочек
Пусть n элементов хранятся в хеш-таблице T

Разрешение коллизий с помощью цепочек
В худшем случае: все n ключей имеют
Разрешение коллизий с помощью цепочек
В худшем случае: все n ключей имеют
![Разрешение коллизий с помощью цепочек Обозначим длины списков T[j] для j=0,1,…,m-1](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/713728/slide-27.jpg)
Разрешение коллизий с помощью цепочек
Обозначим длины списков T[j] для j=0,1,…,m-1 как
Разрешение коллизий с помощью цепочек
Обозначим длины списков T[j] для j=0,1,…,m-1 как

Разрешение коллизий с помощью цепочек
Примечание.
Если количество элементов n пропорционально количеству ячеек
Разрешение коллизий с помощью цепочек
Примечание.
Если количество элементов n пропорционально количеству ячеек

Разрешение коллизий с помощью цепочек. Важно
Для качественной хеш-функции должно выполняться предположение
Разрешение коллизий с помощью цепочек. Важно
Для качественной хеш-функции должно выполняться предположение
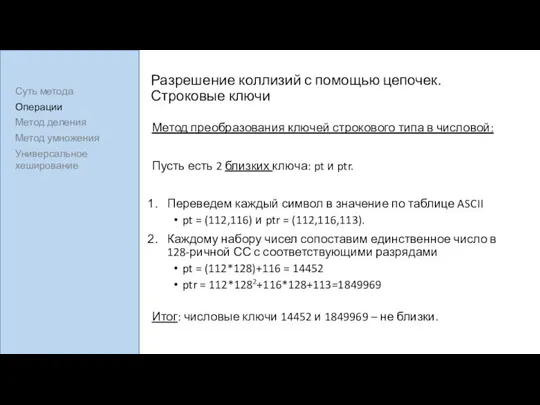
Разрешение коллизий с помощью цепочек. Строковые ключи
Метод преобразования ключей строкового типа
Разрешение коллизий с помощью цепочек. Строковые ключи
Метод преобразования ключей строкового типа

Разрешение коллизий с помощью цепочек.
Методы вычисления хеш-значения по ключу:
Метод деления
Метод
Разрешение коллизий с помощью цепочек.
Методы вычисления хеш-значения по ключу:
Метод деления
Метод

Хеш-функции. Метод деления.
Суть метода:
Хеш-значение ключа k определяется как остаток от деления
Хеш-функции. Метод деления.
Суть метода:
Хеш-значение ключа k определяется как остаток от деления

Хеш-функции. Метод умножения.
Построение хеш-функции выполняется в 2 этапа:
Выбираем константу 0 <
Хеш-функции. Метод умножения.
Построение хеш-функции выполняется в 2 этапа:
Выбираем константу 0 <

Хеш-функции. Метод умножения.
Рекомендация для технической оптимизации:
m перестает быть критичным
обычно m
Хеш-функции. Метод умножения.
Рекомендация для технической оптимизации:
m перестает быть критичным
обычно m
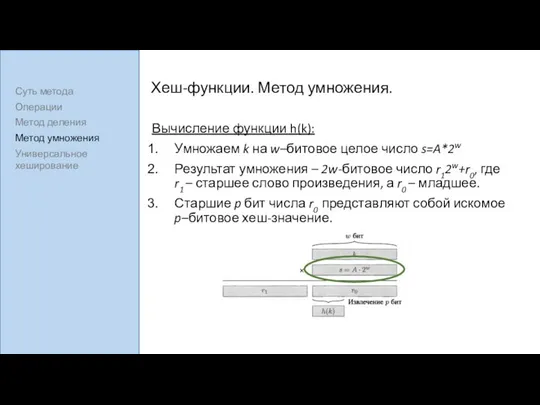
Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат
Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат
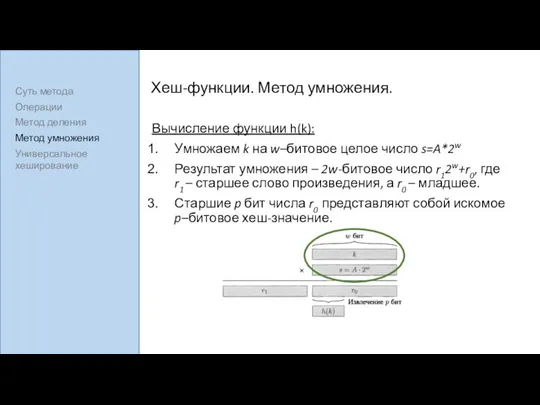
Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат
Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат

Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат
Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат

Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат
Хеш-функции. Метод умножения.
Вычисление функции h(k):
Умножаем k на w–битовое целое число s=A*2w
Результат

Метод умножения. Пример.
Кнут в своей книге рекомендует в качестве константы
Пример.
Пусть k
Метод умножения. Пример.
Кнут в своей книге рекомендует в качестве константы
Пример.
Пусть k
Хеш-функции. Универсальное хеширование.
Предположим есть недоброжелатель, знающий, какая именно хеш-функция используется и
Хеш-функции. Универсальное хеширование.
Предположим есть недоброжелатель, знающий, какая именно хеш-функция используется и

Пример универсального хеширования.
Простой пример класса хеш-функций для универсального хеширования:
Выберем простое число
Пример универсального хеширования.
Простой пример класса хеш-функций для универсального хеширования:
Выберем простое число
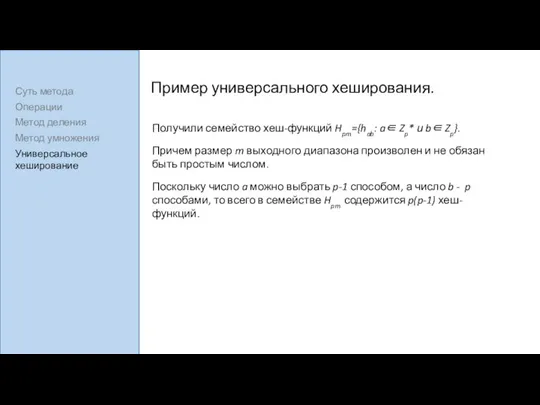
Пример универсального хеширования.
Получили семейство хеш-функций Hpm={hab: a∈ Zp* и b∈ Zp}.
Причем
Пример универсального хеширования.
Получили семейство хеш-функций Hpm={hab: a∈ Zp* и b∈ Zp}.
Причем

Метод открытой адресации
Метод открытой адресации

Хэш-функции. Метод открытой адресации
Суть метода:
В ячейке хеш-таблицы хранится либо элемент динамического
Хэш-функции. Метод открытой адресации
Суть метода:
В ячейке хеш-таблицы хранится либо элемент динамического

Метод открытой адресации. Исследование таблицы
Поиск элемента в таблице – это исследование
Метод открытой адресации. Исследование таблицы
Поиск элемента в таблице – это исследование

Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на
Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на

Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на
Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на

Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на
Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на

Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на
Хэш-функции. Метод открытой адресации
Последовательность исследований для каждого ключа k
есть перестановка на

Хэш-функции. Метод открытой адресации
Реализация функции поиска:
Прим. Не забываем предположение о равномерном
Хэш-функции. Метод открытой адресации
Реализация функции поиска:
Прим. Не забываем предположение о равномерном
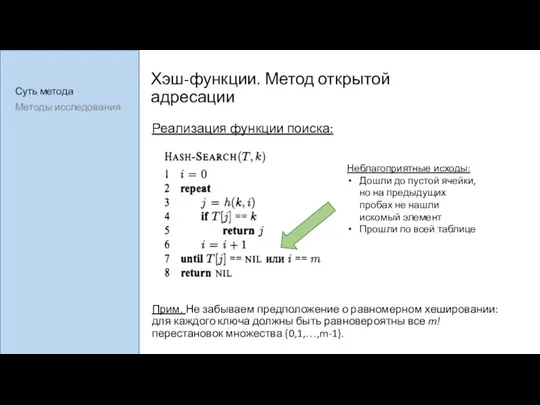
Хэш-функции. Метод открытой адресации
Реализация функции поиска:
Прим. Не забываем предположение о равномерном
Хэш-функции. Метод открытой адресации
Реализация функции поиска:
Прим. Не забываем предположение о равномерном

Метод открытой адресации. Линейное исследование.
Используется вспомогательная хэш-функция h`: U → {0,1,…,m-1}
Для
Метод открытой адресации. Линейное исследование.
Используется вспомогательная хэш-функция h`: U → {0,1,…,m-1}
Для

Метод открытой адресации. Линейное исследование.
Проблема метода: первичная кластеризация.
Пример: добавим в хеш-таблицу
Метод открытой адресации. Линейное исследование.
Проблема метода: первичная кластеризация.
Пример: добавим в хеш-таблицу

Метод открытой адресации. Квадратичное исследование.
Используется хэш-функция
где h` - вспомогательная хэш-функция, c1
Метод открытой адресации. Квадратичное исследование.
Используется хэш-функция
где h` - вспомогательная хэш-функция, c1

Метод открытой адресации. Двойное хеширование.
Используется хеш-функция
где h1, h2 - вспомогательные хеш-функции,
Метод открытой адресации. Двойное хеширование.
Используется хеш-функция
где h1, h2 - вспомогательные хеш-функции,
 Компьютерный сленг
Компьютерный сленг Презентация на тему Вставка музыки в презентацию
Презентация на тему Вставка музыки в презентацию Основы цифровой электроники
Основы цифровой электроники Условная функция и логические выражения в табличном процессоре Excel
Условная функция и логические выражения в табличном процессоре Excel Схемы
Схемы Представление информации в различных системах счисления
Представление информации в различных системах счисления Macromedia Flash 8, первое знакомство
Macromedia Flash 8, первое знакомство Wi-FIT PROJECT
Wi-FIT PROJECT Управление объектами файловой структуры с помощью операционной оболочки
Управление объектами файловой структуры с помощью операционной оболочки Основы информатики
Основы информатики Вычислительные системы, сети и телекоммуникации. Эволюция вычислительных систем
Вычислительные системы, сети и телекоммуникации. Эволюция вычислительных систем Компьютерные сети Телекоммуникационные технологии
Компьютерные сети Телекоммуникационные технологии Разработка методов цифровой стеганографии, на основе самомодифицирующегося кода, для защиты программного обеспечения
Разработка методов цифровой стеганографии, на основе самомодифицирующегося кода, для защиты программного обеспечения Файловый ввод-вывод данных в Pascalе Средства обработки файлов 11 класс
Файловый ввод-вывод данных в Pascalе Средства обработки файлов 11 класс Презентация "Графы. Поиск путей в графе" - скачать презентации по Информатике
Презентация "Графы. Поиск путей в графе" - скачать презентации по Информатике Стандартная библиотека классов. Generics.
Стандартная библиотека классов. Generics.  Моделирование и формализация. Информация и информационные процессы
Моделирование и формализация. Информация и информационные процессы Технологии распределенных вычислений. Распределенные базы данных. Технологии и модели "клиент-сервер"
Технологии распределенных вычислений. Распределенные базы данных. Технологии и модели "клиент-сервер" Одномерные массивы
Одномерные массивы Кодування символів. Особливості двійкового кодування
Кодування символів. Особливості двійкового кодування Технические основы создания и ведения интернет-бизнеса. Сервисы рассылок в Смартреспондере, Ждазклике, Экомтулсе
Технические основы создания и ведения интернет-бизнеса. Сервисы рассылок в Смартреспондере, Ждазклике, Экомтулсе Системы счисления
Системы счисления Размещение данных 1С:Предприятия 8
Размещение данных 1С:Предприятия 8 Кодирование информации. Язык и алфавит. Дискретность. Алфавитный подход кизмерению количества информации
Кодирование информации. Язык и алфавит. Дискретность. Алфавитный подход кизмерению количества информации Работа с текстовой информацией (4 класс)
Работа с текстовой информацией (4 класс) Презентация "Файл подкачки" - скачать презентации по Информатике
Презентация "Файл подкачки" - скачать презентации по Информатике Основные понятия PHP
Основные понятия PHP Разработка и бизнес-администрирования проекта по созданию веб-приложения для оказания образовательных услуг
Разработка и бизнес-администрирования проекта по созданию веб-приложения для оказания образовательных услуг