- Кодирование текстовой информации. Ключевые слова

Содержание
- 2. Ключевые слова текстовая информация кодирование кодовые таблицы
- 3. … 64 65 66 67 68 … 01000000 01000001 01000010 01000011 01000100 Компьютерное представление текстовой информации
- 4. Кодировка ASCII American Standard Code for Information Interchange – американский стандартный код для обмена информацией, разработанный
- 5. Расширение кодировки ASCII Стандартная часть кода (0 … 127) Расширение ASCII (128 … 255) (буквы национального
- 6. Расширение кодировки ASCII
- 7. Стандарт Unicode Unicode — это «уникальный код для любого символа, независимо от платформы, независимо от программы,
- 8. Клавиатуры некоторых стран мира
- 9. Кодировки стандарта Unicode Для представления символов в памяти компьютера в стандарте Unicode имеется несколько кодировок. Кодировка
- 10. Информационный объем сообщения Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт, мегабайт и т. д.),
- 11. Вопросы и задания В Советском энциклопедическом словаре (1983 года издания) 1600 страниц. На одной странице размещается
- 12. Самое главное Текстовая информация по своей природе дискретна, так как представляется последовательностью отдельных символов. В памяти
- 13. Самое главное В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий
- 14. Вопросы и задания Задание 1. Представьте в кодировке ASCII текст Happy New Year! а) шестнадцатеричным кодом
- 15. Windows-1251 Подходы к расположению русских букв в различных кодировках Задание 2. Сравните подходы к расположению русских
- 16. Вопросы и задания Задание 3. В 15-м издании энциклопедии Britannica 32 тома, в каждом из которых
- 18. Скачать презентацию

Ключевые слова
текстовая информация
кодирование
кодовые таблицы
Ключевые слова
текстовая информация
кодирование
кодовые таблицы
…
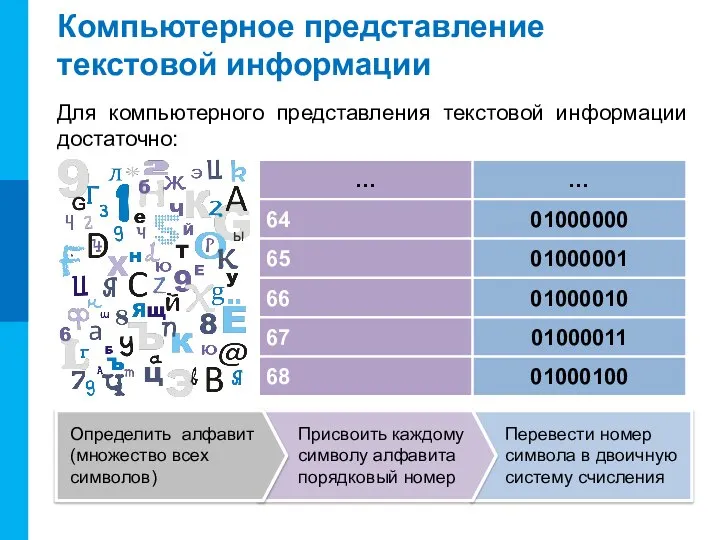
64
65
66
67
68
…
01000000
01000001
01000010
01000011
01000100
Компьютерное представление текстовой информации
Для компьютерного представления текстовой информации достаточно:
…
64
65
66
67
68
…
01000000
01000001
01000010
01000011
01000100
Компьютерное представление текстовой информации
Для компьютерного представления текстовой информации достаточно:
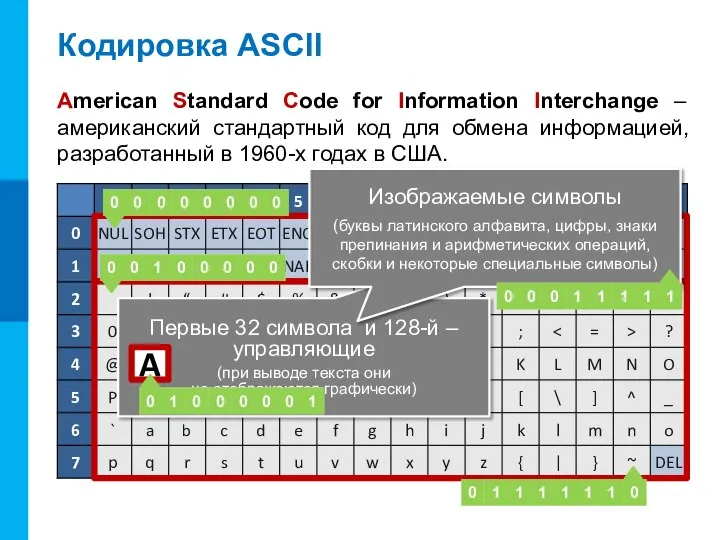
Кодировка ASCII
American Standard Code for Information Interchange – американский стандартный код
Кодировка ASCII
American Standard Code for Information Interchange – американский стандартный код
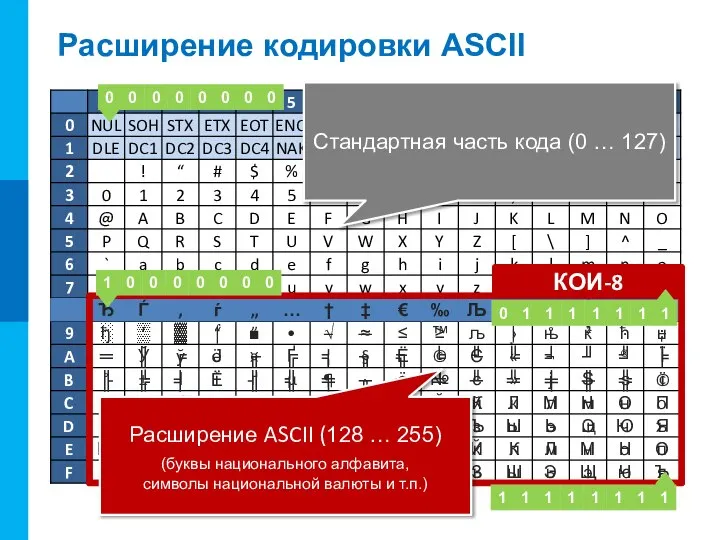
Расширение кодировки ASCII
Стандартная часть кода (0 … 127)
Расширение ASCII (128 …
Расширение кодировки ASCII
Стандартная часть кода (0 … 127)
Расширение ASCII (128 …
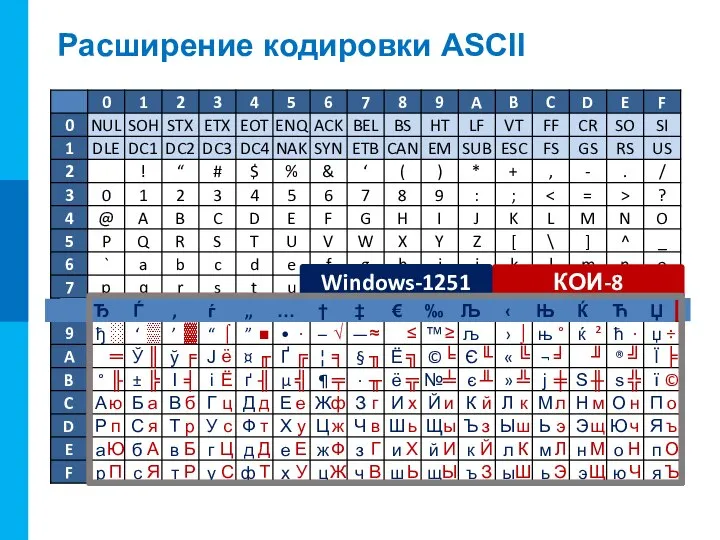
Расширение кодировки ASCII
Расширение кодировки ASCII

Стандарт Unicode
Unicode — это «уникальный код для любого символа, независимо от
Стандарт Unicode
Unicode — это «уникальный код для любого символа, независимо от

Клавиатуры некоторых стран мира
Клавиатуры некоторых стран мира
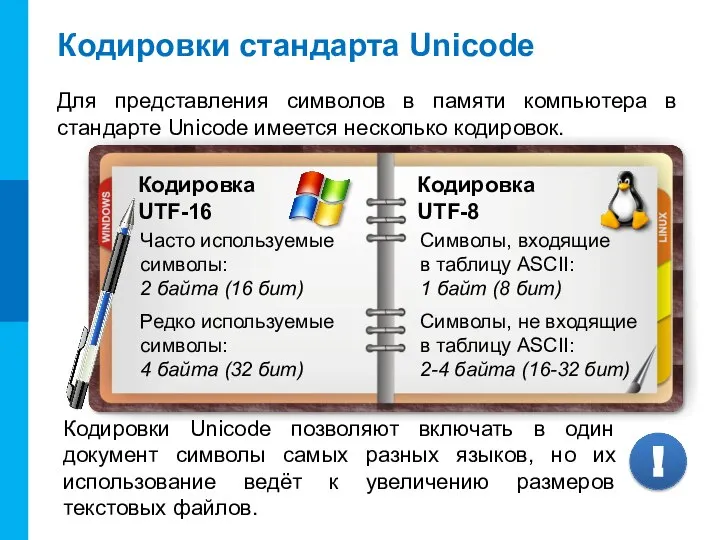
Кодировки стандарта Unicode
Для представления символов в памяти компьютера в стандарте Unicode
Кодировки стандарта Unicode
Для представления символов в памяти компьютера в стандарте Unicode

Информационный объем сообщения
Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт,
Информационный объем сообщения
Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт,

Вопросы и задания
В Советском энциклопедическом словаре (1983 года издания) 1600 страниц.
Вопросы и задания
В Советском энциклопедическом словаре (1983 года издания) 1600 страниц.

Самое главное
Текстовая информация по своей природе дискретна, так как представляется последовательностью
Самое главное
Текстовая информация по своей природе дискретна, так как представляется последовательностью

Самое главное
В 1991 году был разработан новый стандарт кодирования символов, получивший
Самое главное
В 1991 году был разработан новый стандарт кодирования символов, получивший
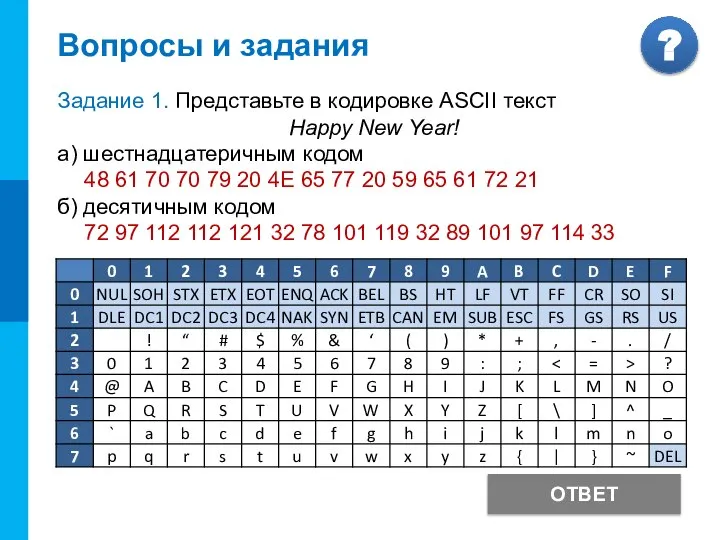
Вопросы и задания
Задание 1. Представьте в кодировке ASCII текст
Happy New Year!
а)
Вопросы и задания
Задание 1. Представьте в кодировке ASCII текст
Happy New Year!
а)
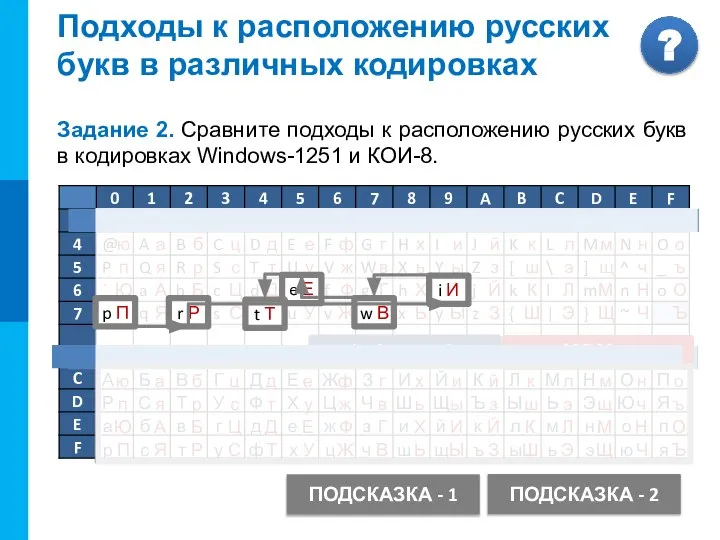
Windows-1251
Подходы к расположению русских
букв в различных кодировках
Задание 2. Сравните подходы
Windows-1251
Подходы к расположению русских
букв в различных кодировках
Задание 2. Сравните подходы

Вопросы и задания
Задание 3. В 15-м издании энциклопедии Britannica 32 тома,
Вопросы и задания
Задание 3. В 15-м издании энциклопедии Britannica 32 тома,
 Безопасность в интернете
Безопасность в интернете Средства информационных и коммуникационных технологий. Состав персонального компьютера
Средства информационных и коммуникационных технологий. Состав персонального компьютера AI автомобиля в изменчивом мире на примере Ex Machina
AI автомобиля в изменчивом мире на примере Ex Machina Работа со списками. Колонки. Буквица. Стили.
Работа со списками. Колонки. Буквица. Стили. Основы безопасности в Интернете
Основы безопасности в Интернете Язык разметки гипертекстов HTML
Язык разметки гипертекстов HTML Хищные журналы
Хищные журналы Лекция 4. Ссылочные типы. Операторы цикла.
Лекция 4. Ссылочные типы. Операторы цикла.  HTML5. Мультимедиа. Формы. Элементы ввода данных
HTML5. Мультимедиа. Формы. Элементы ввода данных Логические операции. Построение таблиц истинности
Логические операции. Построение таблиц истинности Операционная система
Операционная система Автоматизация обработки базы данных в MS Excel и MS Access. (Лекция 6)
Автоматизация обработки базы данных в MS Excel и MS Access. (Лекция 6) Вопросы для проверки домашнего задания. Программное обеспечение
Вопросы для проверки домашнего задания. Программное обеспечение Система хранения данных в локальной вычислительной сети компании ООО Колизей
Система хранения данных в локальной вычислительной сети компании ООО Колизей Презентация "Электронная школа на платформе «1С»" - скачать презентации по Информатике
Презентация "Электронная школа на платформе «1С»" - скачать презентации по Информатике Операционные системы
Операционные системы Глобальная компьютерная сеть Интернета и её ресурсы
Глобальная компьютерная сеть Интернета и её ресурсы 5 класс 5 класс Урок 6 Рабочий стол. Управление компьютером с помощью мыши. Практическая работа №2. Освоение мыши Учитель: Фетис
5 класс 5 класс Урок 6 Рабочий стол. Управление компьютером с помощью мыши. Практическая работа №2. Освоение мыши Учитель: Фетис Реляционные системы управления базами данных. Основные концепции
Реляционные системы управления базами данных. Основные концепции Основы С++. Инкапсуляция. Наследование. Полиморфизм
Основы С++. Инкапсуляция. Наследование. Полиморфизм Однострочные функции
Однострочные функции Циклы
Циклы Конкурс творческих проектов на платформе Arduino. Шаблон
Конкурс творческих проектов на платформе Arduino. Шаблон Лекция №4. Основы работы в среде Matlab
Лекция №4. Основы работы в среде Matlab Поколения компьютеров
Поколения компьютеров Слайды. Результаты тестирования
Слайды. Результаты тестирования Базы данных MS Access
Базы данных MS Access Управление виртуализованной ИТ-инфраструктурой предприятия
Управление виртуализованной ИТ-инфраструктурой предприятия