- Message Passing Interface

Содержание
- 2. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 3. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 4. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 5. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 6. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 7. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
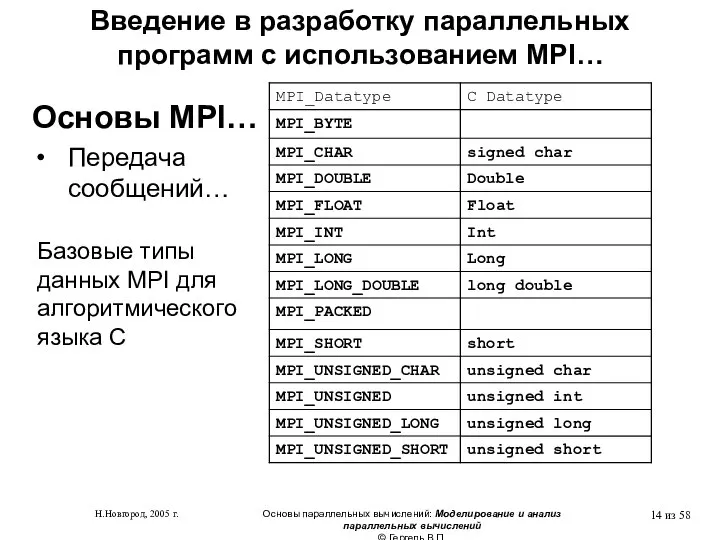
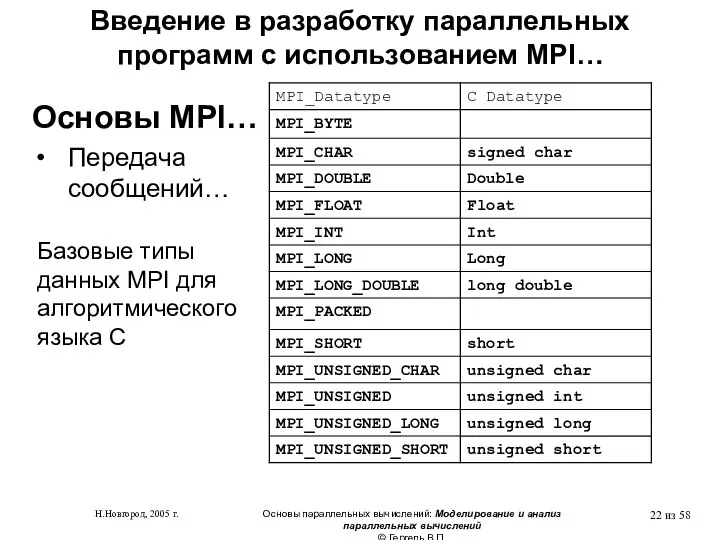
- 8. функции инициализации и закрытия MPI-процессов; функции, реализующие коммуникационные операции типа точка-точка; функции, реализующие коллективные коммуникационные операции;
- 9. Способы выполнения функций MPI Локальная функция – выполняется внутри вызывающего процесса. Ее завершение не требует коммуникаций.
- 10. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 11. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 12. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 13. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 14. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 15. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 16. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 17. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 18. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 19. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 20. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 21. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 22. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 23. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 24. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 25. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 26. Введение в разработку параллельных программ с использованием MPI… Для контроля правильности выполнения все функции MPI возвращают
- 27. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 51
- 28. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 29. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 30. #include "mpi.h " int main(int argc, char* argv[]) { int ProcNum, ProcRank, RecvRank; MPI_Status Status; MPI_Init(&argc,
- 31. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 32. Сумма вектора #include #include #include #include "mpi.h" int main(int argc, char* argv[]){ double x[100], TotalSum, ProcSum
- 33. Сумма вектора // рассылка данных на все процессы if ( ProcRank == 0 ) for (
- 34. Сумма вектора // сборка частичных сумм на процессе с рангом 0 if ( ProcRank == 0
- 35. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 36. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 37. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 38. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 39. Графическая интерпретация операции Bcast
- 40. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 41. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
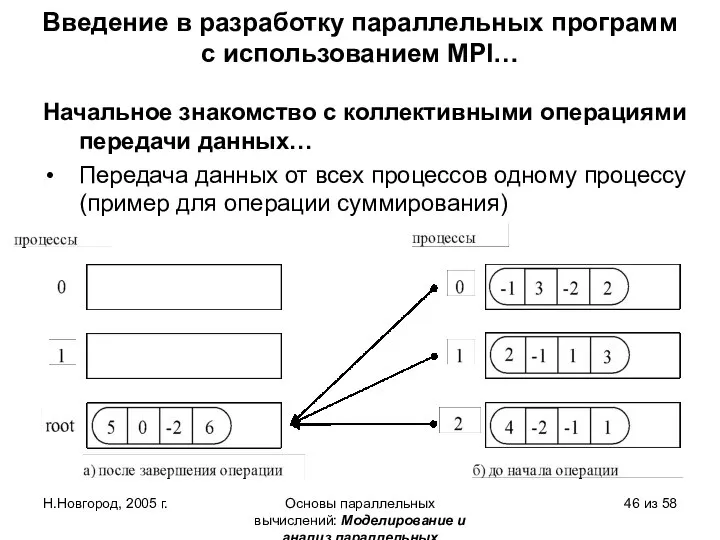
- 42. Графическая интерпретация операции Reduce
- 43. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 44. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 45. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 46. Н.Новгород, 2005 г. Основы параллельных вычислений: Моделирование и анализ параллельных вычислений © Гергель В.П. из 58
- 47. Сумма вектора Использование коллективных функций передачи данных // Использование функции MPI_Reduce // сборка частичных сумм на
- 49. Скачать презентацию

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

функции инициализации и закрытия MPI-процессов;
функции, реализующие коммуникационные операции
функции инициализации и закрытия MPI-процессов;
функции, реализующие коммуникационные операции

Способы выполнения функций MPI
Локальная функция – выполняется внутри вызывающего процесса. Ее
Способы выполнения функций MPI
Локальная функция – выполняется внутри вызывающего процесса. Ее

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Введение в разработку параллельных программ с использованием MPI…
Для контроля правильности выполнения
Введение в разработку параллельных программ с использованием MPI…
Для контроля правильности выполнения

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©
![#include "mpi.h " int main(int argc, char* argv[]) { int ProcNum,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/775719/slide-29.jpg)
#include "mpi.h "
int main(int argc, char* argv[]) {
int
int main(int argc, char* argv[]) {
int

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Сумма вектора
#include
#include
#include
#include "mpi.h"
int main(int argc, char* argv[]){
double x[100],
Сумма вектора
#include
#include
#include
#include "mpi.h"
int main(int argc, char* argv[]){
double x[100],

Сумма вектора
// рассылка данных на все процессы
if ( ProcRank == 0
Сумма вектора
// рассылка данных на все процессы
if ( ProcRank == 0

Сумма вектора
// сборка частичных сумм на процессе с рангом 0
if (
Сумма вектора
// сборка частичных сумм на процессе с рангом 0
if (

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Графическая интерпретация операции Bcast
Графическая интерпретация операции Bcast

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Графическая интерпретация операции Reduce
Графическая интерпретация операции Reduce

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений
©
Н.Новгород, 2005 г.
Основы параллельных вычислений: Моделирование и анализ параллельных вычислений ©

Сумма вектора
Использование коллективных функций передачи данных
// Использование функции MPI_Reduce
// сборка частичных
Сумма вектора
Использование коллективных функций передачи данных
// Использование функции MPI_Reduce
// сборка частичных
 ГБОУ СПО «АМТ» преподаватель Струкова Елена Алексеевна
ГБОУ СПО «АМТ» преподаватель Струкова Елена Алексеевна Жизненный цикл программных систем
Жизненный цикл программных систем Элементы алгебры логики. Математические основы информатики
Элементы алгебры логики. Математические основы информатики Язык Python в школьной информатике
Язык Python в школьной информатике MATLAB: построение двумерных и трехмерных графиков функций одной и многих переменных
MATLAB: построение двумерных и трехмерных графиков функций одной и многих переменных Создание кроссворда средствами Microsoft Word
Создание кроссворда средствами Microsoft Word Мультимедийные технологии
Мультимедийные технологии Программирование на языке Python
Программирование на языке Python Поиск подстрок
Поиск подстрок Процедура подключения к ЭДО (Онбординг)
Процедура подключения к ЭДО (Онбординг) Мы почитаем всех нулями, А единицами себя. А.С. Пушкин
Мы почитаем всех нулями, А единицами себя. А.С. Пушкин Вид с компьютера. Мобильная версия сайта Emerald
Вид с компьютера. Мобильная версия сайта Emerald Analysis and Design of Data Systems. Introduction to Relational Database Design (Lecture 14)
Analysis and Design of Data Systems. Introduction to Relational Database Design (Lecture 14) Полиграфический дизайн текст и изображение
Полиграфический дизайн текст и изображение Архитектура вычислительных систем. (Лекция 4)
Архитектура вычислительных систем. (Лекция 4) Web-конструирование. Представление Web-сайта созданного средствами языка HTML
Web-конструирование. Представление Web-сайта созданного средствами языка HTML Социальная сеть как основа современной социальной структуры
Социальная сеть как основа современной социальной структуры Методика, як наука. Система інтенсивного електронного навчання (СІЕН)
Методика, як наука. Система інтенсивного електронного навчання (СІЕН) Lion Барбершоп
Lion Барбершоп Что такое оптоинформатика
Что такое оптоинформатика Android basic training networking
Android basic training networking Презентация "Экстремальные системы охлаждения" - скачать презентации по Информатике
Презентация "Экстремальные системы охлаждения" - скачать презентации по Информатике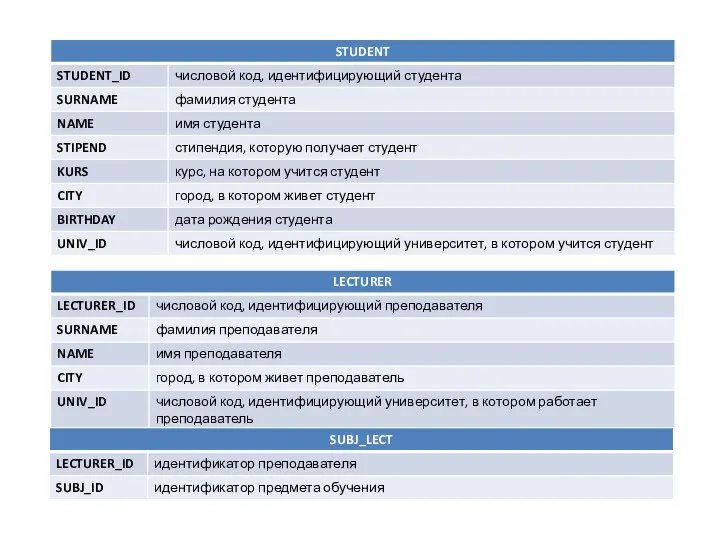 Числовой код, идентифицирующий студента
Числовой код, идентифицирующий студента Алгоритмы управления. Алгоритмизация и программирование
Алгоритмы управления. Алгоритмизация и программирование Информационная архитектура интерфейса (окончание). Прототипирование интерфейса. Лекция № 7
Информационная архитектура интерфейса (окончание). Прототипирование интерфейса. Лекция № 7 Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Теория информации
Теория информации Разработка программного модуля многопользовательской мобильной игры Герои параллельных миров
Разработка программного модуля многопользовательской мобильной игры Герои параллельных миров