- Модели и задачи Data Mining

Содержание
- 2. Кластерный анализ 1. Кластерный анализ предназначен для разбиения данных на поддающиеся интерпретации группы (1), таким образом,
- 4. В факторном анализе группируются столбцы, т.е. цель –анализ структуры множества признаков и выявление обобщенных факторов. В
- 5. Как очертить границу кластеров? Сколько их следует выделить?
- 6. Кластеры могут быть непересекающимися (non-overlapping), и пересекающимися (overlapping). Могут быть получены кластеры различной формы: длинными "цепочками",
- 11. Выделяют четыре основных метода анализа Big Data [1]: Описательная аналитика (descriptive analytics) — отвечает на вопрос
- 12. Диагностическая аналитика Диагностическая (diagnostic) аналитика — форма расширенной аналитики, которая строится на основе описательной и анализирует
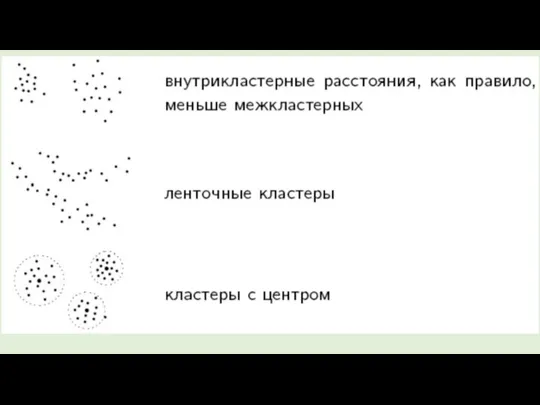
- 13. Меры сходства Евклидово расстояние: расстояние(x,y) = {∑i (xi - yi)2 }1/2 Квадрат евклидова расстояния чтобы придать
- 14. Мера близости вычисленная как евклидово расстояние между двумя точками i и j на плоскости, когда известны
- 15. Когда осей (измерений) больше, чем две, расстояние рассчитывается как: сумма квадратов разницы координат из стольких слагаемых,
- 16. При неоднородности единиц измерения признаков становится невозможно корректно рассчитать расстояния между точками. Существуют различные способы нормирования
- 17. Результат зависит от нормировки признаков
- 18. Расстояние между кластерами Метод ближнего соседа. Расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими
- 19. Методы кластеризации: иерархические Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или разделении
- 20. Иерархические методы кластерного анализа используются при небольших объемах наборов данных. Преимуществом иерархических методов кластеризации является их
- 22. Существует проблема определения числа кластеров. Иногда можно априорно определить это число. Однако в большинстве случаев число
- 24. Итеративные методы. Алгоритм k-средних (k-means) Наиболее распространен среди неиерархических методов алгоритм k-средних, также называемый быстрым кластерным
- 25. K-средних Выбор начальных центроидов может осуществляться следующим образом: выбор k-наблюдений для максимизации начального расстояния; случайный выбор
- 26. Достоинства алгоритма k-средних: • простота использования; • быстрота использования; • понятность и прозрачность. Недостатки алгоритма k-средних:
- 27. Проверка качества кластеризации После получений результатов кластерного анализа методом k-средних следует проверить правильность кластеризации (т.е. оценить,
- 28. Алrоритм g-means Недостаток k-means - отсутствие ясного критерия для выбора оптимального числа кластеров. G-means - популярный
- 29. Нормальное распределение Для нормального распределения количество значений, отличающиеся от среднего на число, меньшее чем одно стандартное
- 30. Ирисы Фишера
- 34. Максимальное ожидание EM-алгоритм EM (Expectation maximization - максимальное правдоподобие) – популярный алгоритм кластеризации. В основе идеи
- 35. Главным достоинством EM-алгоритма является простота исполнения. Алгоритм может оптимизировать не только параметры модели, но и делать
- 37. Кластеризации больших массивов категорийных данных Алгоритмы, основанные на парном вычислении расстояний (k-means и аналоги) эффективны в
- 38. Требований к алгоритмам кластеризации номинальных (качественных) данных Минимально возможное количество «сканирований» таблицы базы данных; Работа в
- 39. Алгоритм CLOPE (кластеризация с наклоном) CLOPE (Clustering with sLOPE) предложен в 2002 году группой китайских ученых.
- 40. Математическое описание алгоритма
- 41. При использовании метода CLOPE количество кластеров подбирается автоматически и зависит от коэффициента отталкивания — параметра, определяющего
- 42. ЗАКЛЮЧЕНИЕ В этой статье предлагается новый алгоритм категориальной кластеризации данных, называемый CLOPE, основанный на интуитивной идее
- 44. Скачать презентацию

Кластерный анализ
1. Кластерный анализ предназначен для разбиения данных на поддающиеся интерпретации
Кластерный анализ
1. Кластерный анализ предназначен для разбиения данных на поддающиеся интерпретации


В факторном анализе группируются столбцы, т.е. цель –анализ структуры множества признаков
В факторном анализе группируются столбцы, т.е. цель –анализ структуры множества признаков
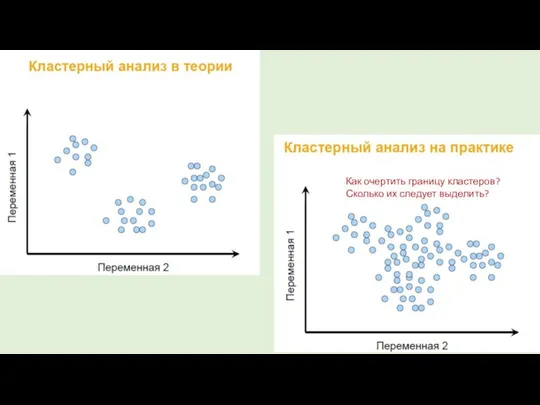
Как очертить границу кластеров?
Сколько их следует выделить?
Как очертить границу кластеров?
Сколько их следует выделить?
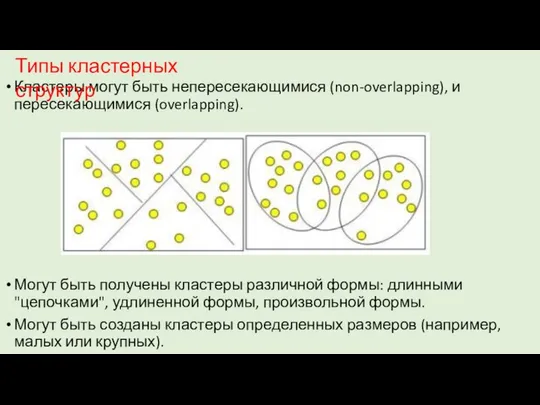
Кластеры могут быть непересекающимися (non-overlapping), и пересекающимися (overlapping).
Могут быть получены кластеры
Кластеры могут быть непересекающимися (non-overlapping), и пересекающимися (overlapping).
Могут быть получены кластеры



![Выделяют четыре основных метода анализа Big Data [1]: Описательная аналитика (descriptive](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/668251/slide-10.jpg)
Выделяют четыре основных метода анализа Big Data [1]:
Описательная аналитика (descriptive analytics)
Выделяют четыре основных метода анализа Big Data [1]:
Описательная аналитика (descriptive analytics)

Диагностическая аналитика
Диагностическая (diagnostic) аналитика — форма расширенной аналитики, которая строится на
Диагностическая аналитика
Диагностическая (diagnostic) аналитика — форма расширенной аналитики, которая строится на

Меры сходства
Евклидово расстояние: расстояние(x,y) = {∑i (xi - yi)2 }1/2
Квадрат евклидова
Меры сходства
Евклидово расстояние: расстояние(x,y) = {∑i (xi - yi)2 }1/2
Квадрат евклидова

Мера близости вычисленная как евклидово расстояние между
двумя точками i и
Мера близости вычисленная как евклидово расстояние между
двумя точками i и

Когда осей (измерений) больше, чем две, расстояние рассчитывается как: сумма квадратов
Когда осей (измерений) больше, чем две, расстояние рассчитывается как: сумма квадратов
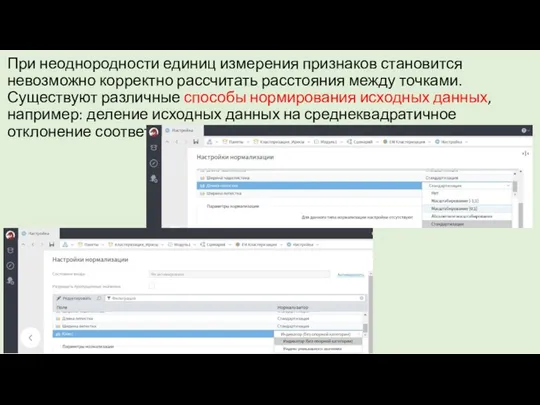
При неоднородности единиц измерения признаков становится невозможно корректно рассчитать расстояния между
При неоднородности единиц измерения признаков становится невозможно корректно рассчитать расстояния между
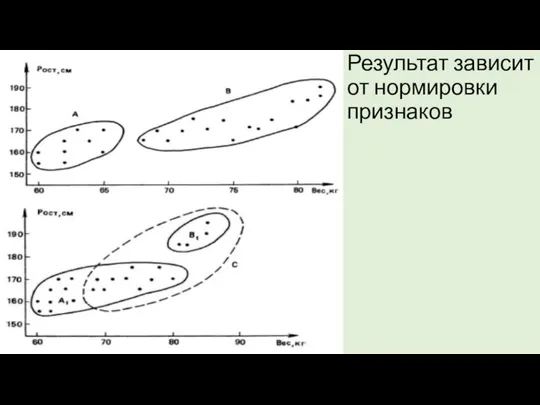
Результат зависит от нормировки признаков
Результат зависит от нормировки признаков

Расстояние между кластерами
Метод ближнего соседа. Расстояние между двумя кластерами определяется расстоянием
Расстояние между кластерами
Метод ближнего соседа. Расстояние между двумя кластерами определяется расстоянием

Методы кластеризации: иерархические
Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров
Методы кластеризации: иерархические
Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров

Иерархические методы кластерного анализа используются при небольших объемах наборов данных.
Преимуществом
Иерархические методы кластерного анализа используются при небольших объемах наборов данных.
Преимуществом


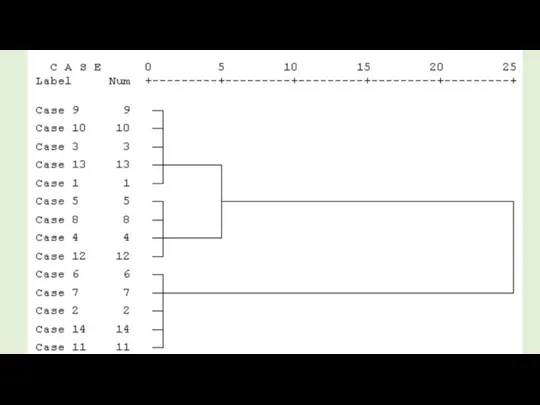
Существует проблема определения числа кластеров. Иногда можно априорно определить это число.
Существует проблема определения числа кластеров. Иногда можно априорно определить это число.

Итеративные методы. Алгоритм k-средних (k-means)
Наиболее распространен среди неиерархических методов алгоритм k-средних,
Итеративные методы. Алгоритм k-средних (k-means)
Наиболее распространен среди неиерархических методов алгоритм k-средних,

K-средних
Выбор начальных центроидов может осуществляться следующим образом:
выбор k-наблюдений для максимизации начального
K-средних
Выбор начальных центроидов может осуществляться следующим образом:
выбор k-наблюдений для максимизации начального

Достоинства алгоритма k-средних:
• простота использования;
• быстрота использования;
• понятность
Достоинства алгоритма k-средних:
• простота использования;
• быстрота использования;
• понятность

Проверка качества кластеризации
После получений результатов кластерного анализа методом k-средних следует
Проверка качества кластеризации
После получений результатов кластерного анализа методом k-средних следует

Алrоритм g-means
Недостаток k-means - отсутствие ясного критерия для выбора оптимального числа
Алrоритм g-means
Недостаток k-means - отсутствие ясного критерия для выбора оптимального числа
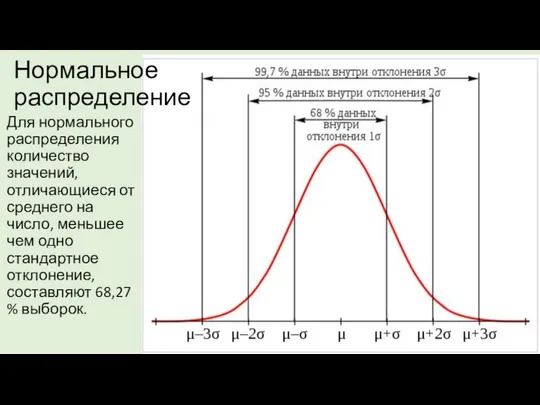
Нормальное распределение
Для нормального распределения количество значений, отличающиеся от среднего на число,
Нормальное распределение
Для нормального распределения количество значений, отличающиеся от среднего на число,
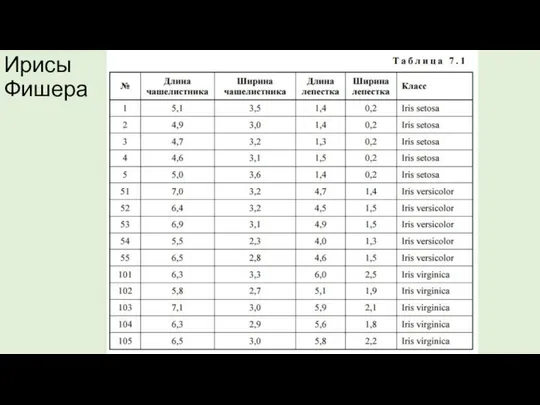
Ирисы Фишера
Ирисы Фишера




Максимальное ожидание EM-алгоритм
EM (Expectation maximization - максимальное правдоподобие) – популярный алгоритм
Максимальное ожидание EM-алгоритм
EM (Expectation maximization - максимальное правдоподобие) – популярный алгоритм

Главным достоинством EM-алгоритма является простота исполнения.
Алгоритм может оптимизировать не только
Главным достоинством EM-алгоритма является простота исполнения.
Алгоритм может оптимизировать не только


Кластеризации больших массивов категорийных данных
Алгоритмы, основанные на парном вычислении расстояний
Кластеризации больших массивов категорийных данных
Алгоритмы, основанные на парном вычислении расстояний

Требований к алгоритмам кластеризации номинальных (качественных) данных
Минимально возможное количество «сканирований» таблицы
Требований к алгоритмам кластеризации номинальных (качественных) данных
Минимально возможное количество «сканирований» таблицы

Алгоритм CLOPE (кластеризация с наклоном)
CLOPE (Clustering with sLOPE) предложен в 2002
Алгоритм CLOPE (кластеризация с наклоном)
CLOPE (Clustering with sLOPE) предложен в 2002

Математическое описание алгоритма
Математическое описание алгоритма

При использовании метода CLOPE количество кластеров подбирается автоматически и зависит от
При использовании метода CLOPE количество кластеров подбирается автоматически и зависит от

ЗАКЛЮЧЕНИЕ В этой статье предлагается новый алгоритм категориальной кластеризации данных, называемый
ЗАКЛЮЧЕНИЕ В этой статье предлагается новый алгоритм категориальной кластеризации данных, называемый
 Новые медиа как продукт
Новые медиа как продукт Контроль и защита информации в автоматизированных системах
Контроль и защита информации в автоматизированных системах Электронный учет питания
Электронный учет питания О применении контрольно-кассовой техники
О применении контрольно-кассовой техники Microsoft PowerPoint
Microsoft PowerPoint Firebase. Quickly development of high-quality app
Firebase. Quickly development of high-quality app Киберпреступность: понятие, виды, уголовно-правовые виды борьбы
Киберпреступность: понятие, виды, уголовно-правовые виды борьбы Защита от несанкционированного доступа к информации. 11 клас
Защита от несанкционированного доступа к информации. 11 клас Ревизия архитектуры хранения данных подсистемы обеспечения
Ревизия архитектуры хранения данных подсистемы обеспечения Автоматизированная информационная система на платформе 1С:Предприятие 7.7
Автоматизированная информационная система на платформе 1С:Предприятие 7.7 Основы современных операционных систем Лекция 30 Сафонов Владимир Олегович
Основы современных операционных систем Лекция 30 Сафонов Владимир Олегович  Разветвляющийся алгоритм, с полной и неполной формами ветвления
Разветвляющийся алгоритм, с полной и неполной формами ветвления Презентация "Переменная и кванторы" - скачать презентации по Информатике
Презентация "Переменная и кванторы" - скачать презентации по Информатике Разработка через тестирование. Примеры
Разработка через тестирование. Примеры Логотипы популярных социальных сетей
Логотипы популярных социальных сетей Управление процессами
Управление процессами Программирование на языке Паскаль. Часть II
Программирование на языке Паскаль. Часть II Лист электронной книги
Лист электронной книги Управление целостностью данных. (Лекция 5)
Управление целостностью данных. (Лекция 5) Представление числовой информации в компьютере
Представление числовой информации в компьютере Пространственный анализ
Пространственный анализ Основные этапы проектирования реляционной БД
Основные этапы проектирования реляционной БД Информационные технологии в жизни человека
Информационные технологии в жизни человека Технологии программирования. Курс на базе Microsoft Solutions Framework Семинар 1. Повтор принципов объектно-ориентированного подхода
Технологии программирования. Курс на базе Microsoft Solutions Framework Семинар 1. Повтор принципов объектно-ориентированного подхода  Ithub-2
Ithub-2 Ментальные карты: общее назначение, существующие интернет- ресурсы и по, использование ментальных карт в учебной деятельности
Ментальные карты: общее назначение, существующие интернет- ресурсы и по, использование ментальных карт в учебной деятельности Базы данных. Система управления базами данных
Базы данных. Система управления базами данных Кодирование информации. Дискретное кодирование
Кодирование информации. Дискретное кодирование