-
Кодирование текстовой информации

Содержание
- 2. - процесс представления информации в виде последовательности условных обозначений Код – множество слов –последовательность символов из
- 3. Способ кодирования зависит от назначения кода Если код предназначен для передачи текста по технической системе связи,
- 4. Во второй половине XX века появляются компьютеры. Для компьютерной обработки текстов потребовалось создать стандарт кодирования. Первый
- 5. ASCII - это семиразрядный двоичный код. Общее количество символов 128, из них 32 символа – управляющие,
- 6. Коды символов могут быть двоичными, десятичными и шестнадцатеричными
- 8. Символы в ASСII кодируются семью битами, но в памяти компьютера под каждый символ отводится ровно 1
- 9. Вопрос. Почему сдвиг, с помощью которого по коду пропиской английской буквы можно получить код соответствующей строчной,
- 10. В чем главный недостаток ASСII?
- 11. Впоследствии стали разрабатывать расширения ASСII, в которых применялись однобайтовые коды символов, первые 128 совпадали с кодировкой
- 12. КОИ8 (koi-8r) (Код обмена информацией, 8-битный, ОС Unix). Для представления букв других языков СССР использовался блок
- 13. CP1251 ("Code Page", «кодовая страница» или Windows-1251) Эта кодировка использовалась и используется до сих пор в
- 14. Кодировка CP866 используется в ОС MS DOS). К особенностям данной кодировки можно отнести наличие псевдографики, которая
- 15. Задание. Какое слово отобразится в кодировках CP-866, Windows-1251, если в кодировке КОИ-8 набрано слово «ДИСК»
- 16. В начале 90-ых годов появился новый международный стандарт Unicode, в котором на кодирование символов отводится 31
- 17. Ответьте на вопрос: Что такое стандарт ASCII. Принцип кодирования. Задание. 1.Представьте в форме шестнадцатеричного кода слово
- 18. Вопрос. Почему сдвиг, с помощью которого по коду пропиской английской буквы можно получить код соответствующей строчной,
- 19. Ответ1 Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц: КОИ8-Р: 252
- 20. Ответ2 INFORMATION TECHNOLOGY
- 22. Кодирование равномерное неравномерное при равномерном кодировании все символы кодируются кодами равной длины; при неравномерном кодировании разные
- 23. Однозначное декодирование закодированное сообщение можно однозначно декодировать с начала, если выполняется условие Фано: никакое кодовое слово
- 24. Однозначное декодирование Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили
- 26. Скачать презентацию
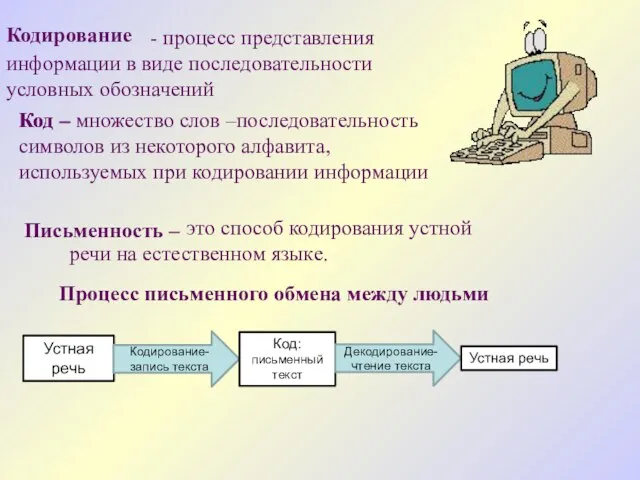
- процесс представления информации в виде последовательности условных обозначений
Код –
- процесс представления информации в виде последовательности условных обозначений
Код –
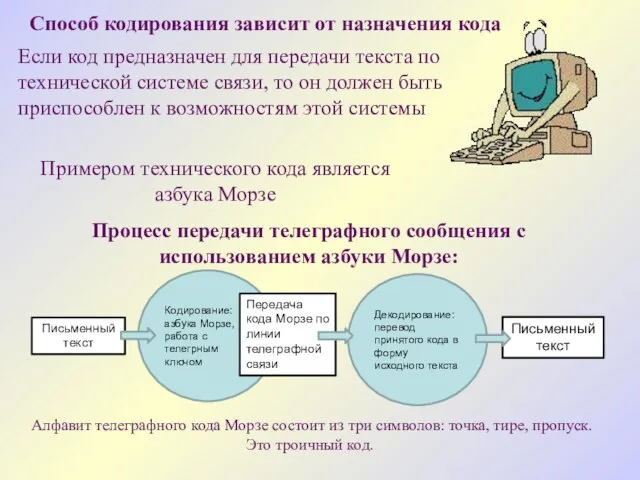
Способ кодирования зависит от назначения кода
Если код предназначен для передачи текста
Способ кодирования зависит от назначения кода
Если код предназначен для передачи текста

Во второй половине XX века появляются компьютеры. Для компьютерной обработки текстов
Во второй половине XX века появляются компьютеры. Для компьютерной обработки текстов

ASCII - это семиразрядный двоичный код.
Общее количество символов 128, из них
ASCII - это семиразрядный двоичный код.
Общее количество символов 128, из них
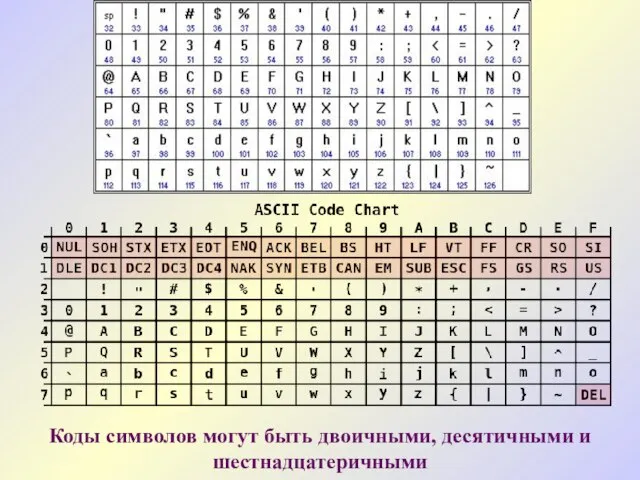
Коды символов могут быть двоичными, десятичными и шестнадцатеричными
Коды символов могут быть двоичными, десятичными и шестнадцатеричными
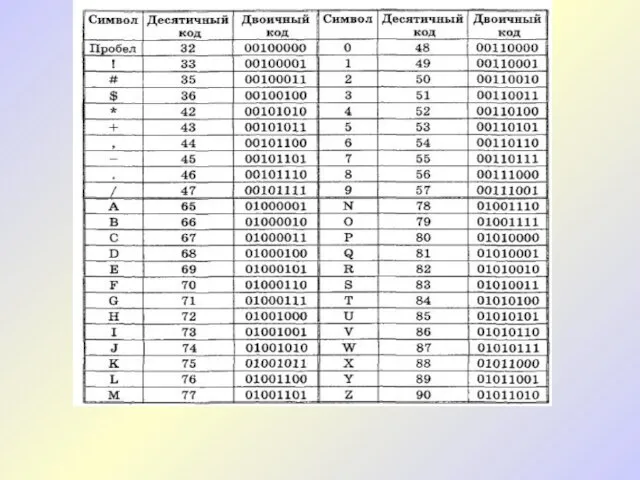
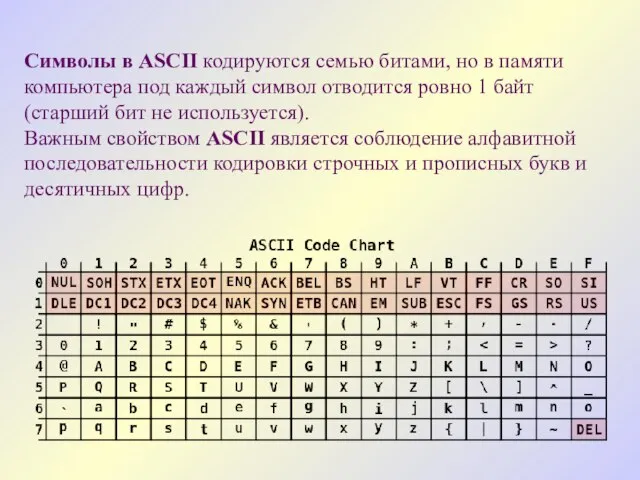
Символы в ASСII кодируются семью битами, но в памяти компьютера под
Символы в ASСII кодируются семью битами, но в памяти компьютера под
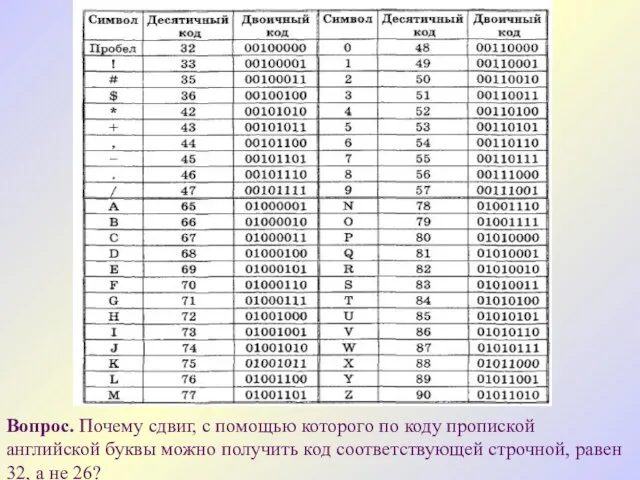
Вопрос. Почему сдвиг, с помощью которого по коду пропиской английской буквы
Вопрос. Почему сдвиг, с помощью которого по коду пропиской английской буквы

В чем главный недостаток ASСII?
В чем главный недостаток ASСII?

Впоследствии стали разрабатывать расширения ASСII, в которых применялись однобайтовые коды символов,
Впоследствии стали разрабатывать расширения ASСII, в которых применялись однобайтовые коды символов,

КОИ8 (koi-8r)
(Код обмена информацией, 8-битный, ОС Unix).
Для представления букв других языков
КОИ8 (koi-8r)
(Код обмена информацией, 8-битный, ОС Unix).
Для представления букв других языков

CP1251 ("Code Page", «кодовая страница»
или Windows-1251)
Эта кодировка использовалась и используется до
CP1251 ("Code Page", «кодовая страница»
или Windows-1251)
Эта кодировка использовалась и используется до

Кодировка CP866 используется
в ОС MS DOS).
К особенностям данной кодировки можно
Кодировка CP866 используется
в ОС MS DOS).
К особенностям данной кодировки можно

Задание. Какое слово отобразится в кодировках CP-866, Windows-1251, если в кодировке
Задание. Какое слово отобразится в кодировках CP-866, Windows-1251, если в кодировке

В начале 90-ых годов появился новый международный стандарт Unicode, в котором
В начале 90-ых годов появился новый международный стандарт Unicode, в котором

Ответьте на вопрос:
Что такое стандарт ASCII. Принцип кодирования.
Задание.
1.Представьте в форме шестнадцатеричного
Ответьте на вопрос: Что такое стандарт ASCII. Принцип кодирования. Задание. 1.Представьте в форме шестнадцатеричного
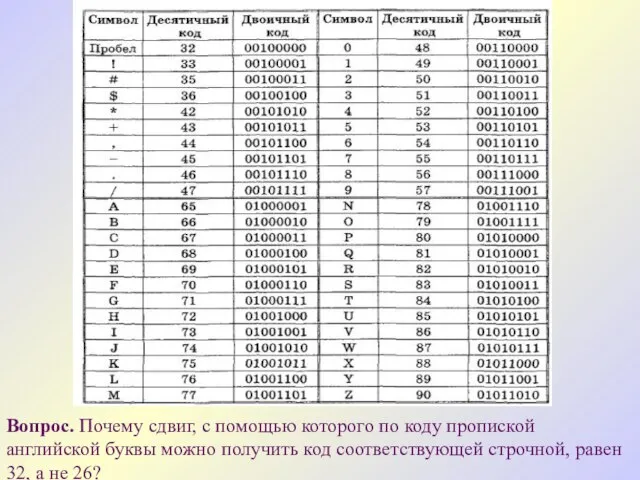
Вопрос. Почему сдвиг, с помощью которого по коду пропиской английской буквы
Вопрос. Почему сдвиг, с помощью которого по коду пропиской английской буквы

Ответ1
Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на
Ответ1
Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на

Ответ2
INFORMATION TECHNOLOGY
Ответ2
INFORMATION TECHNOLOGY


Кодирование
равномерное неравномерное
при равномерном кодировании все символы кодируются кодами равной длины;
при
Кодирование
равномерное неравномерное
при равномерном кодировании все символы кодируются кодами равной длины;
при

Однозначное декодирование
закодированное сообщение можно однозначно декодировать с начала, если выполняется
условие
Однозначное декодирование
закодированное сообщение можно однозначно декодировать с начала, если выполняется условие

Однозначное декодирование
Для кодирования некоторой последовательности, состоящей из букв А, Б, В,
Однозначное декодирование
Для кодирования некоторой последовательности, состоящей из букв А, Б, В,
 Некоторые понятия алгебры логики, логические элементы компьютера
Некоторые понятия алгебры логики, логические элементы компьютера « Банковские операции: начисление простых и сложных процентов»
« Банковские операции: начисление простых и сложных процентов» Users \ Groups Folders \ Files permissions
Users \ Groups Folders \ Files permissions Объектно-ориентированное программирование в С++. Классы
Объектно-ориентированное программирование в С++. Классы Количество информации в сообщении о неравновероятном событии
Количество информации в сообщении о неравновероятном событии TypeScript In-Depth: Types Basics
TypeScript In-Depth: Types Basics Маркированные и нумерованные списки
Маркированные и нумерованные списки V областной конкурс IT-проектов В единстве – наша сила! Своя игра ПДД для детей
V областной конкурс IT-проектов В единстве – наша сила! Своя игра ПДД для детей Історія створення Інтернету
Історія створення Інтернету Этапы развития информационного общества
Этапы развития информационного общества Базы данных Института научной информации по общественным наукам ИНИОН РАН
Базы данных Института научной информации по общественным наукам ИНИОН РАН Обучающий тренинг для операторов удаленного доступа
Обучающий тренинг для операторов удаленного доступа Инфоград. Устройства ввода
Инфоград. Устройства ввода Навигатор УрФУ
Навигатор УрФУ Презентация "Алгоритмы на графах. Топологическая сортировка отсечением вершин" - скачать презентации по Информатике
Презентация "Алгоритмы на графах. Топологическая сортировка отсечением вершин" - скачать презентации по Информатике Хранение информации и её носители. Запись информации на носители
Хранение информации и её носители. Запись информации на носители Презентация "Понятие и типы информационных систем" - скачать презентации по Информатике
Презентация "Понятие и типы информационных систем" - скачать презентации по Информатике Работа с электронной почтой
Работа с электронной почтой Презентация на тему "Компьютерные вирусы и антивирусные программы"
Презентация на тему "Компьютерные вирусы и антивирусные программы" Осуществление интеграции программных модулей
Осуществление интеграции программных модулей Введение в дисциплину. Алгоритмы и структуры данных. Лекция 1
Введение в дисциплину. Алгоритмы и структуры данных. Лекция 1 Фундаментальные типы данных (тема 1 - 4)
Фундаментальные типы данных (тема 1 - 4) Рекурсия. Рекурсивная функция
Рекурсия. Рекурсивная функция Многоуровневые списки. 7 класс
Многоуровневые списки. 7 класс компьютерный кружок Февраль 2010
компьютерный кружок Февраль 2010 Защита web-сайта Моё электронное портфолио
Защита web-сайта Моё электронное портфолио Презентация "Рекламные и шпионские программы и защита от них" - скачать презентации по Информатике
Презентация "Рекламные и шпионские программы и защита от них" - скачать презентации по Информатике Разработка базы данных Магазин канцелярских товаров в УБД MS ACCESS
Разработка базы данных Магазин канцелярских товаров в УБД MS ACCESS