- Работа с текстовыми данными

Содержание
- 3. Этапы решения задачи классификации текстов Этап 1. Обработка текста Токенизация (разделение исходного текста на токены). Поиск
- 4. Улучшение модели - Искать последовательности символов, которые состоят как минимум из двух букв или цифр и
- 5. Еще один способ, с помощью которого мы можем избавиться от неинформативных слов – исключение слов, которые
- 6. Стоп слова К стоп-словам можно отнести предлоги, причастия, междометия, цифры, частицы и т. п. Общие шумовые
- 7. Тематическое моделирование Тематическое моделирование применяется в задачах кластеризации или классификации текстов. В результате тематического моделирования каждый
- 10. Метод частота термина-обратная частота документа (term frequency-inverse document frequency, tf-idf) вместо исключения несущественных признаков пытается масштабировать
- 11. Значение tf-idf для слова w в документе d вычисляется по формуле: где N – это количество
- 12. Иллюстрация метода кодирования TF-IDF
- 13. Пример работы tf-idf Vectorizer
- 14. Один из главных недостатков представления «мешок слов» заключается в полном игнорировании порядка слов. Таким образом, две
- 15. Эти методы подразумевают идентификацию или объединение всех слов с одной и той же основой. Если этот
- 16. Токенизация и лемматизация
- 17. Технология Word2Vec Word2Vec - группа алгоритмов, предназначенных для получения вещественных векторных представлений слов в пространстве с
- 18. Как это обучается? Создаем обучающую выборку из текстовых данных (скажем, все статьи Википедии) Устанавливаем окно (например,
- 19. Технология Word2Vec W2V методами нейронных сетей решает задачу снижения размерности и выдает на выходе компактные векторные
- 20. Пример группы схожих слов для предоставленного набора данных В качестве меры сходства выступает косинусное расстояние. Косинусное
- 21. Предварительно обученная модели легко доступны в интернете. В Python-проект их можно импортировать с помощью библиотеки gensim.
- 22. Результаты
- 24. Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово. Совместная встречаемость
- 25. https://rusvectores.org/ru/ RusVectores: семантические модели для русского языка
- 26. GloVe (Global Vectors) GloVe - алгоритм обучения без учителя для получения векторных представлений слов. Обучение проводится
- 27. GloVe (Global Vectors) Векторы wi и wk слов i и k подбираются таким образом, чтобы
- 28. Преимущества Простая архитектура без нейронной сети. Модель быстрая, и этого может быть достаточно для простых приложений.
- 29. fastText Созданная в Facebook библиотека fastText – ещё один серьёзный шаг в развитии моделей естественного языка.
- 30. FastText Импортируется модель, например, так: from gensim.models import FastText У модели есть гиперпараметры. Вот описание некоторых
- 32. Скачать презентацию


Этапы решения задачи классификации текстов
Этап 1. Обработка текста
Токенизация (разделение исходного текста
Этапы решения задачи классификации текстов
Этап 1. Обработка текста
Токенизация (разделение исходного текста

Улучшение модели
- Искать последовательности символов, которые состоят как минимум из двух
Улучшение модели
- Искать последовательности символов, которые состоят как минимум из двух

Еще один способ, с помощью которого мы можем избавиться от неинформативных
Еще один способ, с помощью которого мы можем избавиться от неинформативных

Стоп слова
К стоп-словам можно отнести предлоги, причастия, междометия, цифры, частицы и
Стоп слова
К стоп-словам можно отнести предлоги, причастия, междометия, цифры, частицы и

Тематическое моделирование
Тематическое моделирование применяется в задачах кластеризации или классификации текстов.
Тематическое моделирование
Тематическое моделирование применяется в задачах кластеризации или классификации текстов.



Метод частота термина-обратная частота документа (term frequency-inverse document frequency, tf-idf) вместо
Метод частота термина-обратная частота документа (term frequency-inverse document frequency, tf-idf) вместо

Значение tf-idf для слова w в документе d вычисляется по формуле:
где
Значение tf-idf для слова w в документе d вычисляется по формуле:
где
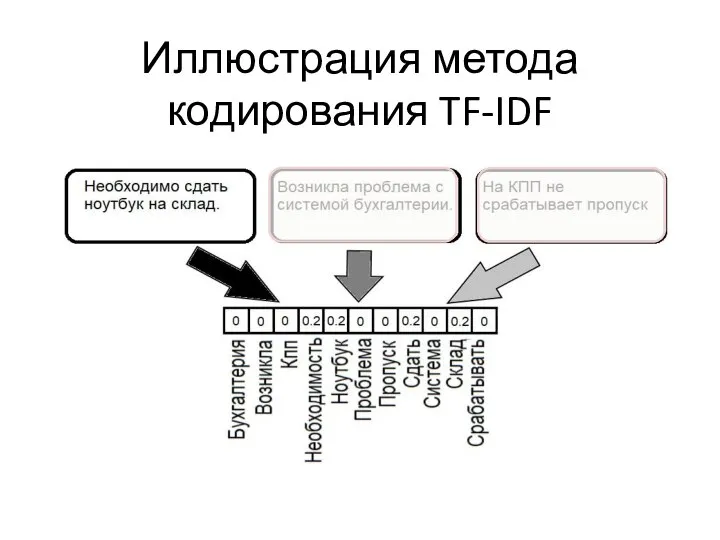
Иллюстрация метода кодирования TF-IDF
Иллюстрация метода кодирования TF-IDF

Пример работы tf-idf Vectorizer
Пример работы tf-idf Vectorizer

Один из главных недостатков представления «мешок слов» заключается в полном игнорировании
Один из главных недостатков представления «мешок слов» заключается в полном игнорировании

Эти методы подразумевают идентификацию или объединение всех слов с одной и
Эти методы подразумевают идентификацию или объединение всех слов с одной и

Токенизация и лемматизация
Токенизация и лемматизация

Технология Word2Vec
Word2Vec - группа алгоритмов, предназначенных для получения вещественных векторных представлений
Технология Word2Vec
Word2Vec - группа алгоритмов, предназначенных для получения вещественных векторных представлений

Как это обучается?
Создаем обучающую выборку из текстовых данных (скажем, все статьи
Как это обучается?
Создаем обучающую выборку из текстовых данных (скажем, все статьи

Технология Word2Vec
W2V методами нейронных сетей решает задачу снижения размерности и выдает
Технология Word2Vec
W2V методами нейронных сетей решает задачу снижения размерности и выдает

Пример группы схожих слов для предоставленного набора данных
В качестве меры сходства
Пример группы схожих слов для предоставленного набора данных
В качестве меры сходства

Предварительно обученная модели легко доступны в интернете. В Python-проект их можно
Предварительно обученная модели легко доступны в интернете. В Python-проект их можно

Результаты
Результаты


Обучение на уровне слов: нет информации о предложении или контексте, в
Обучение на уровне слов: нет информации о предложении или контексте, в
https://rusvectores.org/ru/
RusVectores: семантические модели
для русского языка
https://rusvectores.org/ru/
RusVectores: семантические модели
для русского языка

GloVe (Global Vectors)
GloVe - алгоритм обучения без учителя для получения векторных
GloVe (Global Vectors)
GloVe - алгоритм обучения без учителя для получения векторных

GloVe (Global Vectors)
Векторы wi и wk слов i и k подбираются
GloVe (Global Vectors)
Векторы wi и wk слов i и k подбираются

Преимущества
Простая архитектура без нейронной сети.
Модель быстрая, и этого может быть достаточно
Преимущества
Простая архитектура без нейронной сети.
Модель быстрая, и этого может быть достаточно

fastText
Созданная в Facebook библиотека fastText – ещё один серьёзный шаг в
fastText
Созданная в Facebook библиотека fastText – ещё один серьёзный шаг в

FastText
Импортируется модель, например, так:
from gensim.models import FastText
У модели есть гиперпараметры. Вот
FastText
Импортируется модель, например, так:
from gensim.models import FastText
У модели есть гиперпараметры. Вот
 Информация. Кодирование информации
Информация. Кодирование информации Разработка мер по защите информации в АИС «Сетевой край. Образование»
Разработка мер по защите информации в АИС «Сетевой край. Образование» Технологии программирования
Технологии программирования Программы, используемые при автоматизации салона красоты
Программы, используемые при автоматизации салона красоты Системы управления базами данных. PL/SQL. (Часть 2)
Системы управления базами данных. PL/SQL. (Часть 2) Презентация "Работа с объектами текстового документа" - скачать презентации по Информатике
Презентация "Работа с объектами текстового документа" - скачать презентации по Информатике Разработка элементов фирменного стиля образовательной организации с использованием специализированного программного обеспечения
Разработка элементов фирменного стиля образовательной организации с использованием специализированного программного обеспечения Обеспечение эффективности банковского сектора Юрлова Виктория, МЭ-102
Обеспечение эффективности банковского сектора Юрлова Виктория, МЭ-102 Язык новостной журналистики
Язык новостной журналистики Операционные системы
Операционные системы Триггеры. Триггеры в презентации. Применение. Создание слайдов с триггерами
Триггеры. Триггеры в презентации. Применение. Создание слайдов с триггерами Моделирование как метод познания
Моделирование как метод познания Лекция 2. Основы программной инженерии. Основные этапы разработки программ, их назначение и характеристики
Лекция 2. Основы программной инженерии. Основные этапы разработки программ, их назначение и характеристики Объектная модель Excel
Объектная модель Excel Компьютерная этика
Компьютерная этика Средства защиты информации в ОС Windows
Средства защиты информации в ОС Windows Троянские программы
Троянские программы Бази даних. Система управління базами даних Microsoft Access
Бази даних. Система управління базами даних Microsoft Access Деревья Хаффмана (продолжение)
Деревья Хаффмана (продолжение) Регистрация несовершеннолетних на ЕЦПСЗ
Регистрация несовершеннолетних на ЕЦПСЗ Проектирование трансляторов языков программирования. Схема работы компилятора. (Глава 1)
Проектирование трансляторов языков программирования. Схема работы компилятора. (Глава 1) Презентация на тему Кодирование информации в компьютере
Презентация на тему Кодирование информации в компьютере Областная детско-юношеская библиотека. Культурный статус, устойчивость и значение в развитии региона
Областная детско-юношеская библиотека. Культурный статус, устойчивость и значение в развитии региона Мистецтво написання проекту
Мистецтво написання проекту Двоичная, восьмеричная и шестнадцатеричная системы счисления. 10 класс
Двоичная, восьмеричная и шестнадцатеричная системы счисления. 10 класс Технология REST
Технология REST ИНЖЕНЕРНАЯ ГРАФИКА - ВЧЕРА, СЕГОДНЯ, ЗАВТРА Инженерная графика – профессиональный язык инженеров прошлого и современности.
ИНЖЕНЕРНАЯ ГРАФИКА - ВЧЕРА, СЕГОДНЯ, ЗАВТРА Инженерная графика – профессиональный язык инженеров прошлого и современности. Винни-Пух и пчелы
Винни-Пух и пчелы