- Разработка и заполнение баз данных

Содержание
- 2. Что представляет из себя база данных? – набор информации, имеющей отношение к какому-либо предмету или явлению,
- 3. Демографические и социоэкономические характеристики ВИЧ-инфицированных больных, госпитализированных в конкретный стационар: Совокупность информации, структурированной таким образом, чтобы
- 4. Как собрать хорошие данные? Ключевое условие – хороший дизайн исследования. – Определите цель сбора данных и
- 5. Пилотное исследование Провести такое исследование до начала сбора данных –хорошая идея на любой случай. – Поговорите
- 6. Программное обеспечение, используемое для создания баз данных: Базы данных: MS Access, DBase Двумерные таблицы: MS Excel,
- 7. Базы данных: Позволяют создавать большие массивы данных и гибко управлять ими. – Позволяют работать со ссылками:
- 8. Двумерные таблицы проще, с ними легче работать. – Возможны ограничения по размеру (например, в MS Excel
- 9. Программы для статистической обработки данных: – Имеют общие черты и с базами данных, и с двумерными
- 10. Два основных типа данных: – числовые (количественные); – категориальные (качественные)
- 11. Качественные (категориальные) данные: – Бинарные (жив/мёртв, мужчина/женщина, заболевание развилось/не развилось) – Номинальные (две и более категории,
- 12. Количественные (числовые) данные: – Дискретные: могут принимать только определённые значения в определённом диапазоне (например, индекс качества
- 14. Поля и форматы данных: – Текстовые: текст, комбинация текста и цифр либо цифры, не нуждающиеся в
- 15. Поля и форматы данных: – Поля бинарных данных: в некоторых программах есть формат ячеек, позволяющий хранить
- 16. Практика сбора высококачественных данных: – Будьте последовательны Многие проблемы проистекают от непоследовательности при сборе и оформлении
- 17. Практика сбора высококачественных данных: – Пропуски данных: для многих переменных неизбежны. Придумайте общую стратегию работы с
- 18. Практика сбора высококачественных данных: Простая проверка данных. Хорошая привычка – проводить простую проверку правильности введения данных
- 20. Практика сбора высококачественных данных: При всякой возможности избегайте внесения «просто текста», оставляя его обработку «на потом».
- 21. Практика сбора высококачественных данных: Не смешивайте числа и текст. Например, при заполнении числовых ячеек не пишите
- 22. Практика сбора высококачественных данных: Что делать, если собрано много значений одной переменной для одного и того
- 23. Метод 1 сложнее, но практически не имеет ограничений. Метод 2 проще и требует меньше места, но
- 24. Данные могут храниться в двух форматах: Формат «высокий столбец»: каждая запись для одного пациента, соответствующая определённому
- 25. Оба формата подразумевают уникальные идентификаторы для каждого пациента, ввиду чего легко транспонируются специальными программами в любой
- 26. Если в ходе исследования производится модификация/расширение базы данных, необходимо вести журнал изменений, а также хранить окончательные
- 27. Найдите все ошибки, допущенные при заполнении представленной базы данных ☺
- 35. Резюме Существует ряд правил построения электронных таблиц для обеспечения их максимальной совместимости с программами, выполняющими статистическую
- 36. 5. Значения всех переменных, вносимые в таблицу, должны быть числовыми; символьные значения («да», «нет» и т.п.)
- 37. 8. По возможности следует избегать пустых ячеек на месте отсутствующих данных; в таких случаях лучше использовать
- 39. Скачать презентацию

Что представляет из себя база данных?
– набор информации, имеющей отношение к
Что представляет из себя база данных?
– набор информации, имеющей отношение к
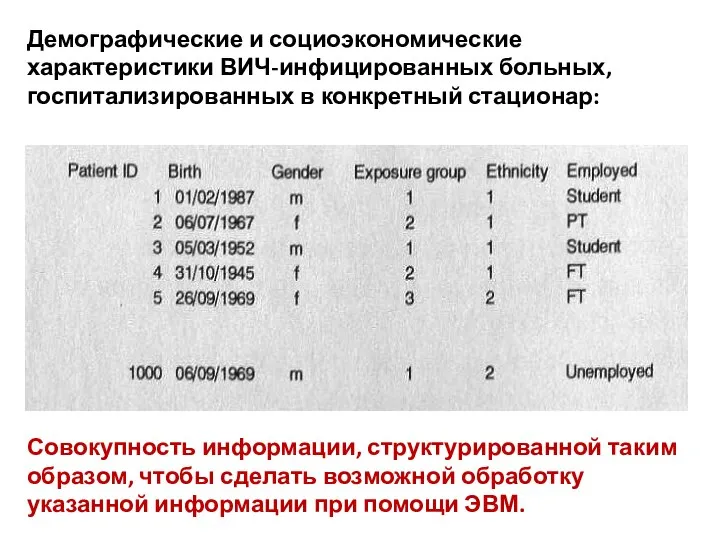
Демографические и социоэкономические характеристики ВИЧ-инфицированных больных, госпитализированных в конкретный стационар:
Совокупность информации,
Демографические и социоэкономические характеристики ВИЧ-инфицированных больных, госпитализированных в конкретный стационар:
Совокупность информации,

Как собрать хорошие данные?
Ключевое условие – хороший дизайн исследования.
– Определите цель
Как собрать хорошие данные?
Ключевое условие – хороший дизайн исследования.
– Определите цель

Пилотное исследование
Провести такое исследование до начала сбора данных –хорошая идея на
Пилотное исследование
Провести такое исследование до начала сбора данных –хорошая идея на

Программное обеспечение, используемое для создания баз данных:
Базы данных: MS Access, DBase
Двумерные
Программное обеспечение, используемое для создания баз данных:
Базы данных: MS Access, DBase
Двумерные

Базы данных:
Позволяют создавать большие массивы данных и гибко управлять ими.
– Позволяют
Базы данных:
Позволяют создавать большие массивы данных и гибко управлять ими.
– Позволяют

Двумерные таблицы проще, с ними легче работать.
– Возможны ограничения по размеру
Двумерные таблицы проще, с ними легче работать.
– Возможны ограничения по размеру

Программы для статистической обработки данных:
– Имеют общие черты и с базами
Программы для статистической обработки данных:
– Имеют общие черты и с базами
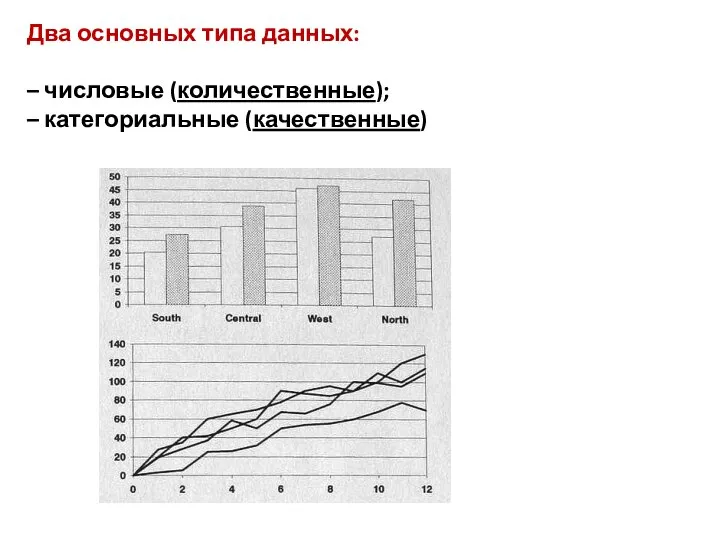
Два основных типа данных:
– числовые (количественные);
– категориальные (качественные)
Два основных типа данных:
– числовые (количественные);
– категориальные (качественные)

Качественные (категориальные) данные:
– Бинарные (жив/мёртв, мужчина/женщина, заболевание развилось/не развилось)
– Номинальные (две
Качественные (категориальные) данные:
– Бинарные (жив/мёртв, мужчина/женщина, заболевание развилось/не развилось)
– Номинальные (две

Количественные (числовые) данные:
– Дискретные: могут принимать только определённые значения в определённом
Количественные (числовые) данные:
– Дискретные: могут принимать только определённые значения в определённом

Поля и форматы данных:
– Текстовые: текст, комбинация текста и цифр либо
Поля и форматы данных:
– Текстовые: текст, комбинация текста и цифр либо

Поля и форматы данных:
– Поля бинарных данных: в некоторых программах есть
Поля и форматы данных:
– Поля бинарных данных: в некоторых программах есть

Практика сбора высококачественных данных:
– Будьте последовательны
Многие проблемы проистекают от непоследовательности при
Практика сбора высококачественных данных:
– Будьте последовательны
Многие проблемы проистекают от непоследовательности при

Практика сбора высококачественных данных:
– Пропуски данных: для многих переменных неизбежны.
Придумайте общую
Практика сбора высококачественных данных:
– Пропуски данных: для многих переменных неизбежны.
Придумайте общую

Практика сбора высококачественных данных:
Простая проверка данных.
Хорошая привычка – проводить простую проверку
Практика сбора высококачественных данных:
Простая проверка данных.
Хорошая привычка – проводить простую проверку

Практика сбора высококачественных данных:
При всякой возможности избегайте внесения «просто текста», оставляя
Практика сбора высококачественных данных:
При всякой возможности избегайте внесения «просто текста», оставляя

Практика сбора высококачественных данных:
Не смешивайте числа и текст.
Например, при заполнении числовых
Практика сбора высококачественных данных:
Не смешивайте числа и текст.
Например, при заполнении числовых

Практика сбора высококачественных данных:
Что делать, если собрано много значений одной переменной
Практика сбора высококачественных данных:
Что делать, если собрано много значений одной переменной

Метод 1 сложнее, но практически не имеет ограничений.
Метод 2 проще и
Метод 1 сложнее, но практически не имеет ограничений.
Метод 2 проще и

Данные могут храниться в двух форматах:
Формат «высокий столбец»: каждая запись для
Данные могут храниться в двух форматах:
Формат «высокий столбец»: каждая запись для

Оба формата подразумевают уникальные идентификаторы для каждого пациента, ввиду чего легко
Оба формата подразумевают уникальные идентификаторы для каждого пациента, ввиду чего легко

Если в ходе исследования производится модификация/расширение базы данных, необходимо вести журнал
Если в ходе исследования производится модификация/расширение базы данных, необходимо вести журнал
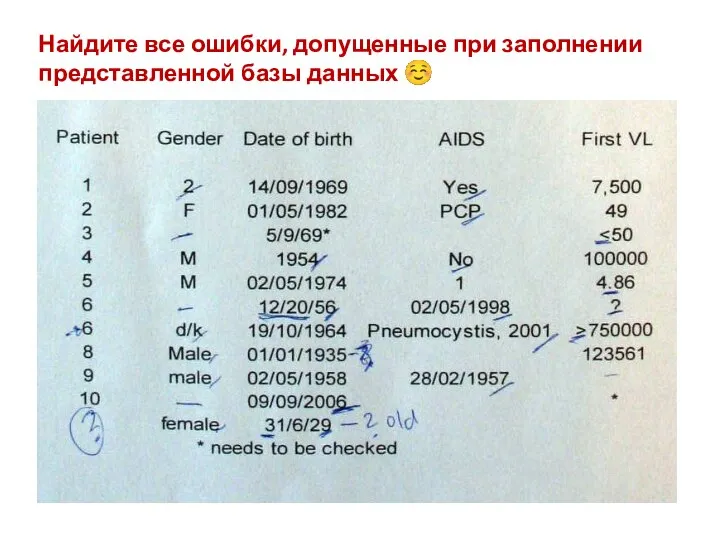
Найдите все ошибки, допущенные при заполнении представленной базы данных ☺
Найдите все ошибки, допущенные при заполнении представленной базы данных ☺





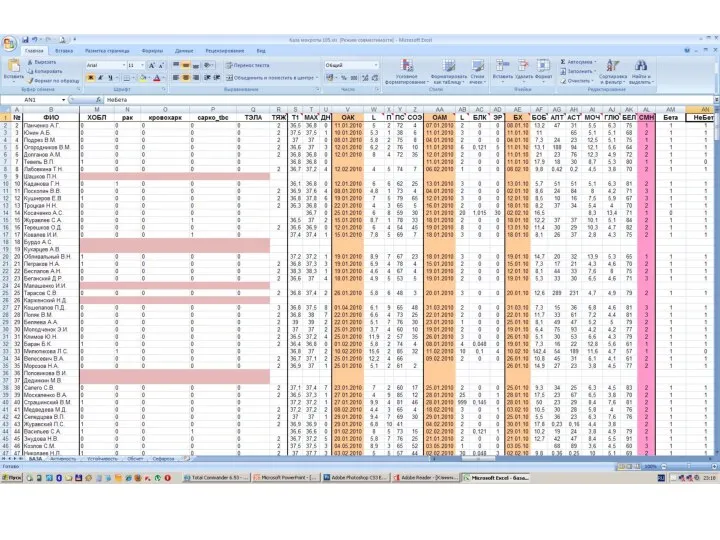
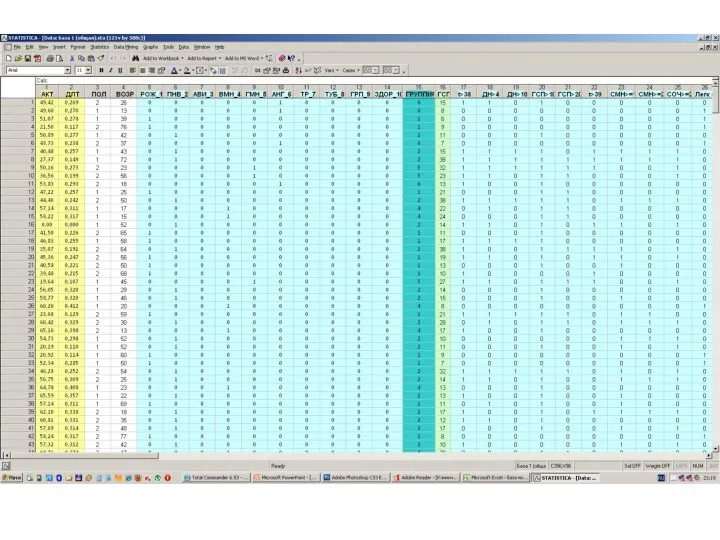

Резюме
Существует ряд правил построения электронных таблиц для обеспечения их максимальной совместимости
Резюме
Существует ряд правил построения электронных таблиц для обеспечения их максимальной совместимости

5. Значения всех переменных, вносимые в таблицу, должны быть числовыми; символьные
5. Значения всех переменных, вносимые в таблицу, должны быть числовыми; символьные

8. По возможности следует избегать пустых ячеек на месте отсутствующих данных;
8. По возможности следует избегать пустых ячеек на месте отсутствующих данных;
 ИНФОРМАЦИЯ Понятие количества информации. Подходы к определению количества информации. Единицы измерения .
ИНФОРМАЦИЯ Понятие количества информации. Подходы к определению количества информации. Единицы измерения .  Презентация "Графические способы представления учебной информации" - скачать презентации по Информатике
Презентация "Графические способы представления учебной информации" - скачать презентации по Информатике Информационные технологии в проектной деятельности
Информационные технологии в проектной деятельности Компьютерные вирусы: методы распространения, профилактика заражения
Компьютерные вирусы: методы распространения, профилактика заражения Проект Из Рук в Руки
Проект Из Рук в Руки Специфика печати, радио, телевидения и Интернета как разновидностей СМИ
Специфика печати, радио, телевидения и Интернета как разновидностей СМИ Алгоритмы в нашей жизни
Алгоритмы в нашей жизни Работа с файлами для АСУб и ЭВМб. Тема 2-4
Работа с файлами для АСУб и ЭВМб. Тема 2-4 Компьютерные сети Классификация
Компьютерные сети Классификация Журналистика. Китай и Индия
Журналистика. Китай и Индия Алгоритмическая конструкция ветвление
Алгоритмическая конструкция ветвление Элементы теории информации
Элементы теории информации Гласные после шипящих 3 класс
Гласные после шипящих 3 класс  Курсы по 3D моделированию
Курсы по 3D моделированию Презентация "Устройство компьютера 10 класс" - скачать презентации по Информатике
Презентация "Устройство компьютера 10 класс" - скачать презентации по Информатике Работа с файлами (язык Си)
Работа с файлами (язык Си) Компьютерные сети
Компьютерные сети Введение в дисциплину. Единицы измерения. Системы счисления. Лекция №1
Введение в дисциплину. Единицы измерения. Системы счисления. Лекция №1 Социальные сети
Социальные сети CorelDraw
CorelDraw Кодирование числовой информации
Кодирование числовой информации Unity Start M1 L10
Unity Start M1 L10 Основы алгоритмизации и программирования. Лекция 13
Основы алгоритмизации и программирования. Лекция 13 Доступ к системе Антиплагиат 3.3 для преподавателей
Доступ к системе Антиплагиат 3.3 для преподавателей 1-2 - Разветвляющиеся алгоритмы - 2022
1-2 - Разветвляющиеся алгоритмы - 2022 Урок №3. Формы представления данных (таблицы, формы, запросы, отчеты)
Урок №3. Формы представления данных (таблицы, формы, запросы, отчеты) Ввод текста, его редактирование и форматирование
Ввод текста, его редактирование и форматирование Разработка сайта для интернет-магазина по продаже гитар “Guitar”
Разработка сайта для интернет-магазина по продаже гитар “Guitar”