- Словарные коды класса LZ

Содержание
- 2. Общая схема кодирования в LZ-методах При кодировании сообщение разбивается на слова переменной длины. При обработке очередного
- 3. При декодировании по принятому коду определяется закодированное слово. В случае получения специального символа, сигнализирующего о передаче
- 4. По способу организации хранения и поиска слов словарные методы можно разделить на две большие группы: алгоритмы,
- 5. Алгоритмы класса LZ отличаются: размерами окна; способами кодирования слов; алгоритмами обновления словаря и т.п. Все указанные
- 6. Кодирование с использованием скользящего окна Рассмотрим основные этапы кодирования сообщения Х=х1х2х3х4…, которое порождается некоторым источником информации
- 7. Если символ х1 найден, то осуществляется поиск в окне слова х1х2, начинающегося с этого символа. Если
- 8. Пример. Пусть алфавит источника А={а, b, с}, длина окна W=6. Необходимо закодировать исходное сообщение bababaabacabac. После
- 9. - Далее окно сдвигаем на 3 символа вправо и ищем в окне букву с. Ее нет
- 10. Кодирование последовательности bababaabacabac
- 11. Кодирование с использованием адаптивного словаря В этих словарных методах для хранения слов используется адаптивный словарь, заполняющийся
- 12. Пример. Пусть алфавит источника А={а, b, с}, размер словаря V=8. Необходимо закодировать исходное сообщение abababaabacabac. 1.
- 13. 2. Читаем первые две буквы ab, ищем слово ab в словаре. Этого слова нет, поэтому поместим
- 14. 3. Далее читаем букву a и ищем в словаре слово ba. Этого слова нет, поэтому запишем
- 15. 4. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке
- 16. 5. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке
- 17. 6. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке
- 18. Если словарь заполняется до окончания кодирования, то можно записывать новые слова в словарь, начиная со строки
- 19. 8. Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке
- 20. 9. Закодируем букву с кодом 010. Конец входной последовательности. Таким образом, входное сообщение будет закодировано так:
- 21. Алгоритм на псевдокоде Кодирование с адаптивным словарем Обозначим: CurCode – текущий код PrevCode – предыдущий код
- 22. S:=9; L:=0; DicPos:=257 (256+конец сжатия) DO (not EOF) CurCode:=Read( ) (читаем следующий байт из файла) M[L]:=CurCode;
- 23. Рассмотрим теперь на примере ранее закодированного сообщения abababaabacabac (алфавит источника А={а, b, с}, размер словаря V=8)
- 24. 3. Читаем следующий код 001, по коду найдем в словаре букву b. Получим новое слово ab,
- 25. 5. Читаем код 101, такого кода нет в словаре. Тогда добавляем к слову ab первую букву
- 26. 7. Читаем код 010, по коду находим в словаре букву с, добавляем букву с к предыдущему
- 27. 9. Читаем код 010, по коду находим в словаре букву с, добавляем букву с к предыдущему
- 28. Алгоритм на псевдокоде Декодирование с адаптивным словарем Обозначим: CurCode – текущий код PrevCode – предыдущий код
- 29. S:=9; L:=0; DicPos:=257 DO CurCode:=Read(S) (читаем из файла S бит) IF (CurCode=256) break FI IF (C[CurCode]
- 31. Скачать презентацию

Общая схема кодирования в LZ-методах
При кодировании сообщение разбивается на
Общая схема кодирования в LZ-методах
При кодировании сообщение разбивается на

При декодировании по принятому коду определяется закодированное слово.
В
При декодировании по принятому коду определяется закодированное слово.
В

По способу организации хранения и поиска слов словарные методы можно
По способу организации хранения и поиска слов словарные методы можно

Алгоритмы класса LZ отличаются:
размерами окна;
способами кодирования слов;
алгоритмами обновления словаря
Алгоритмы класса LZ отличаются:
размерами окна;
способами кодирования слов;
алгоритмами обновления словаря

Кодирование с использованием скользящего окна
Рассмотрим основные этапы кодирования сообщения Х=х1х2х3х4…, которое
Кодирование с использованием скользящего окна
Рассмотрим основные этапы кодирования сообщения Х=х1х2х3х4…, которое

Если символ х1 найден, то осуществляется поиск в окне слова х1х2,
Если символ х1 найден, то осуществляется поиск в окне слова х1х2,

Пример. Пусть алфавит источника А={а, b, с}, длина окна W=6. Необходимо
Пример. Пусть алфавит источника А={а, b, с}, длина окна W=6. Необходимо

- Далее окно сдвигаем на 3 символа вправо и ищем в
- Далее окно сдвигаем на 3 символа вправо и ищем в
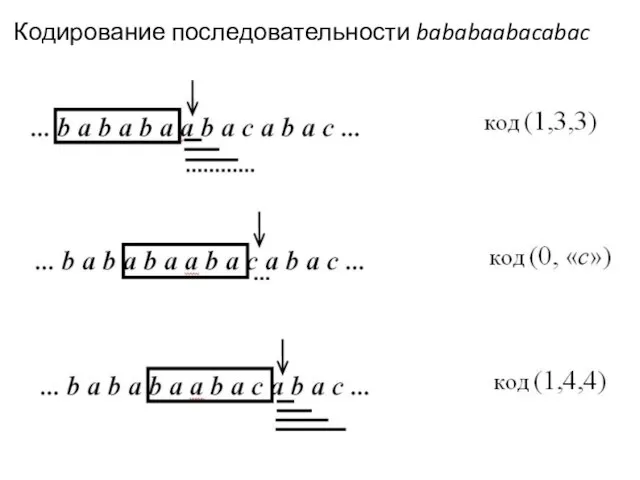
Кодирование последовательности bababaabacabac
Кодирование последовательности bababaabacabac

Кодирование с использованием адаптивного словаря
В этих словарных методах для хранения слов
Кодирование с использованием адаптивного словаря
В этих словарных методах для хранения слов
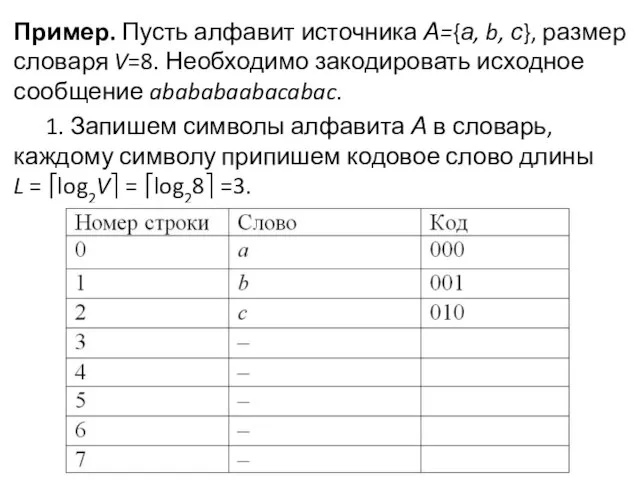
Пример. Пусть алфавит источника А={а, b, с}, размер словаря V=8. Необходимо
Пример. Пусть алфавит источника А={а, b, с}, размер словаря V=8. Необходимо

2. Читаем первые две буквы ab, ищем слово ab в словаре.
2. Читаем первые две буквы ab, ищем слово ab в словаре.
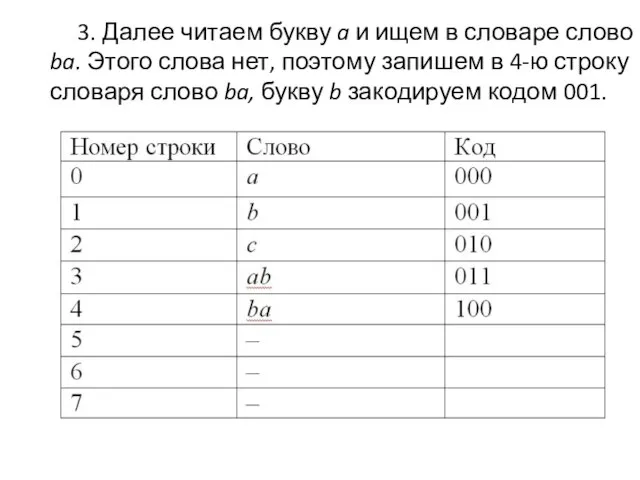
3. Далее читаем букву a и ищем в словаре слово ba.
3. Далее читаем букву a и ищем в словаре слово ba.

4. Читаем букву b, ищем в словаре слово ab. Это слово
4. Читаем букву b, ищем в словаре слово ab. Это слово

5. Читаем букву b, ищем в словаре слово ab. Это слово
5. Читаем букву b, ищем в словаре слово ab. Это слово

6. Читаем букву b, ищем в словаре слово ab. Это слово
6. Читаем букву b, ищем в словаре слово ab. Это слово

Если словарь заполняется до окончания кодирования, то можно записывать новые слова
Если словарь заполняется до окончания кодирования, то можно записывать новые слова

8. Читаем букву b, ищем в словаре слово ab. Это слово
8. Читаем букву b, ищем в словаре слово ab. Это слово

9. Закодируем букву с кодом 010. Конец входной последовательности.
Таким образом, входное
9. Закодируем букву с кодом 010. Конец входной последовательности.
Таким образом, входное

Алгоритм на псевдокоде
Кодирование с адаптивным словарем
Обозначим:
CurCode – текущий код
PrevCode
Алгоритм на псевдокоде
Кодирование с адаптивным словарем
Обозначим:
CurCode – текущий код
PrevCode

<Инициализация словаря символами исходного алфавита>
S:=9; L:=0; DicPos:=257 (256+конец сжатия)
DO (not EOF)
CurCode:=Read(
<Инициализация словаря символами исходного алфавита>
S:=9; L:=0; DicPos:=257 (256+конец сжатия)
DO (not EOF)
CurCode:=Read(

Рассмотрим теперь на примере ранее закодированного сообщения abababaabacabac (алфавит источника А={а,
Рассмотрим теперь на примере ранее закодированного сообщения abababaabacabac (алфавит источника А={а,

3. Читаем следующий код 001, по коду найдем в словаре букву
3. Читаем следующий код 001, по коду найдем в словаре букву

5. Читаем код 101, такого кода нет в словаре. Тогда добавляем
5. Читаем код 101, такого кода нет в словаре. Тогда добавляем

7. Читаем код 010, по коду находим в словаре букву с,
7. Читаем код 010, по коду находим в словаре букву с,

9. Читаем код 010, по коду находим в словаре букву с,
9. Читаем код 010, по коду находим в словаре букву с,

Алгоритм на псевдокоде
Декодирование с адаптивным словарем
Обозначим:
CurCode – текущий код
PrevCode –
Алгоритм на псевдокоде
Декодирование с адаптивным словарем
Обозначим:
CurCode – текущий код
PrevCode –

<Инициализация словаря символами исходного алфавита>
S:=9; L:=0; DicPos:=257
DO
CurCode:=Read(S) (читаем из файла S
<Инициализация словаря символами исходного алфавита>
S:=9; L:=0; DicPos:=257
DO
CurCode:=Read(S) (читаем из файла S
 Понятие информационного процесса, автоматизация офиса
Понятие информационного процесса, автоматизация офиса SpamAssassin
SpamAssassin  Кодирование и декодирование информации
Кодирование и декодирование информации Объёмные геометрические фигуры Математика, 1 класс
Объёмные геометрические фигуры Математика, 1 класс Линейные списки. Структура данных очередь
Линейные списки. Структура данных очередь Система учета потребления коммунальных ресурсов
Система учета потребления коммунальных ресурсов Алгоритм с повторением
Алгоритм с повторением Основные алгоритмические структуры в сказках А.С. Пушкина
Основные алгоритмические структуры в сказках А.С. Пушкина Операции в языке С (продолжение)
Операции в языке С (продолжение) Urban 7. Microvehicle solutions APP + BOX concept
Urban 7. Microvehicle solutions APP + BOX concept Криптоанализ. Атака грубой силы. Частотный анализ. Атака по образцу. Атака знания исходного текста
Криптоанализ. Атака грубой силы. Частотный анализ. Атака по образцу. Атака знания исходного текста Дополнительные возможности Mathcad: Панель Исчисление. Символьные вычисления. Лекция 8. Часть 2
Дополнительные возможности Mathcad: Панель Исчисление. Символьные вычисления. Лекция 8. Часть 2 Безпека в Інтернеті
Безпека в Інтернеті Инструменты тестирования
Инструменты тестирования Графический интерфейс ОС и приложений.
Графический интерфейс ОС и приложений. Зачем нужен NFT
Зачем нужен NFT Тема 13 Понятие об алгоритме 1. Понятие об алгоритме 2. Способы записи алгоритмов 3. Алгоритмы ветвления 4. Циклические алгоритмы
Тема 13 Понятие об алгоритме 1. Понятие об алгоритме 2. Способы записи алгоритмов 3. Алгоритмы ветвления 4. Циклические алгоритмы Информационное моделирование. Курс для дистанционного обучения. 9 класс
Информационное моделирование. Курс для дистанционного обучения. 9 класс Развитие технологии беспроводных сетей
Развитие технологии беспроводных сетей Курсовое проектирование по ТРПО
Курсовое проектирование по ТРПО Презентация на тему Управление компьютером
Презентация на тему Управление компьютером Технические средства автоматизации. Датчики
Технические средства автоматизации. Датчики Начала С/C++: переменная, программа и ввод-вывод. С / С++. Тема 02
Начала С/C++: переменная, программа и ввод-вывод. С / С++. Тема 02 Информатика как наука и вид практической деятельности
Информатика как наука и вид практической деятельности  Базовая конфигурация компьютера. Устройство компьютера
Базовая конфигурация компьютера. Устройство компьютера Графический редактор PAINT
Графический редактор PAINT Динамические данные
Динамические данные Изменения в ЕГЭ по информатике в 2010-11 году Анализ и прогноз изменений
Изменения в ЕГЭ по информатике в 2010-11 году Анализ и прогноз изменений