- СППР, хранилища и витрины данных, интеллектуальный анализ данных

Содержание
- 2. «Заглядывай вперед или окажешься позади» Бенджамин Франклин «Планировать – это хлопотать по поводу наилучшего метода получения
- 3. « Человека, который преуспел в руководстве, но не искушен в выполнении трех интеллектуальных функций управления (формирование
- 4. « Планирование – это проектирование желаемого будущего и эффективных путей его достижения. Это орудие мудрых, но
- 5. Технология Data Мining (также называемая Knowledge Discovery in Data) изучает процесс нахождения новых, действительных и потенциально
- 6. Системы поддержки принятия решений - СППР (DSS, Decision Support Systems) Основная задача СППР - предоставить аналитикам
- 7. Компьютерный анализ ситуаций, создаваемый СППР
- 8. Классы задач анализа данных Информационно-поисковый: СППР осуществляет поиск необходимых данных. Характерной чертой такого анализа является выполнение
- 10. OLTP (Online Transaction Processing), транзакционная система — обработка транзакций в реальном времени. Способ организации БД, при
- 11. Хранилища данных В основе концепции ХД лежит идея разделения данных, используемых для оперативной обработки и для
- 12. ОИД - оперативные источники данных
- 14. Проблемы создания физического ХД: необходимость интеграции данных из неоднородных источников в распределенной среде; потребность в эффективном
- 15. Buтpина данных (ВД) - это упрощенный вариант ХД, содержащий только тематически объединенные данные.
- 16. Архитектура ХД
- 17. Состав ХД Детальными являются данные, переносимые непосредственно из ОИД. Они соответствуют элементарным событиям, фиксируемым OL ТР
- 18. Состав ХД Для удобства работы с ХД необходима информация о содержащихся в нем данных. Такая информация
- 19. Информационные потоки в ХД Входной поток (Inflow) образуется данными, копируемыми из оперативных источников данных (ОИД) в
- 20. ЕТL- процесс (Еxtraction, Тransformation, Loading)
- 21. Очистка данных Уровень ячейки таблицы: Орфографические ошибки (опечатки) Oтсутствие данных Фиктивные значения Логически неверные значения Закодированные
- 22. ОLАР-системы Многомерная модель данных Измерение - это последовательность значений одного из анализируемых параметров. Например, для параметра
- 23. Гиперкуб
- 24. Операция среза (slice)
- 25. Операция вращения (rotate)
- 26. Консолидация (Drill Up) и детализация (Drill Down)
- 27. Двенадцать правил Кодда Многомерность Прозрачность Доступность Постоянная производительность при разработке отчетов Клиент-серверная архитектура Равноправие измерений Динамическое
- 28. Дополнительные правила Кодда Пакетное извлечение против интерпретации Поддержка всех моделей ОLАР-анализа Обработка ненормализованных данных Сохранение результатов
- 29. Тест FASMI F AST (Быстрый) ANALYSIS (Анализ) SHARED (Разделяемой) МULТIDIМЕNSIONАL (Mногомерной) INFORMAТION (Информации)
- 30. OLAP-серверы MOLAP - многомерный (multivаriаtе) ОLАР. Для реализации многомерной модели используют многомерные БД; ROLAP - реляционный
- 31. MOLAP Каждый «кубик» преобразуется в отдельную строку таблицы:
- 32. MOLAP Преимущества: поиск и выборка данных осуществляются значительно быстрее, легко включить в информационную модель разнообразные встроенные
- 33. MOLAP – когда использовать? объем исходных данных для анализа не слишком велик (не более нескольких гигабайт),
- 34. ROLAP – схема «звезда» В центре – таблица фактов, по краям – таблицы измерений
- 35. ROLAP – схема «снежинка»
- 37. Скачать презентацию

«Заглядывай вперед или окажешься позади»
Бенджамин Франклин
«Планировать – это хлопотать по
«Заглядывай вперед или окажешься позади»
Бенджамин Франклин
«Планировать – это хлопотать по

« Человека, который преуспел в руководстве, но не искушен в выполнении
« Человека, который преуспел в руководстве, но не искушен в выполнении

« Планирование – это проектирование желаемого будущего и эффективных путей его
« Планирование – это проектирование желаемого будущего и эффективных путей его

Технология Data Мining
(также называемая Knowledge Discovery in Data) изучает процесс нахождения
Технология Data Мining
(также называемая Knowledge Discovery in Data) изучает процесс нахождения

Системы поддержки принятия решений - СППР
(DSS, Decision Support Systems)
Основная задача
Системы поддержки принятия решений - СППР
(DSS, Decision Support Systems)
Основная задача
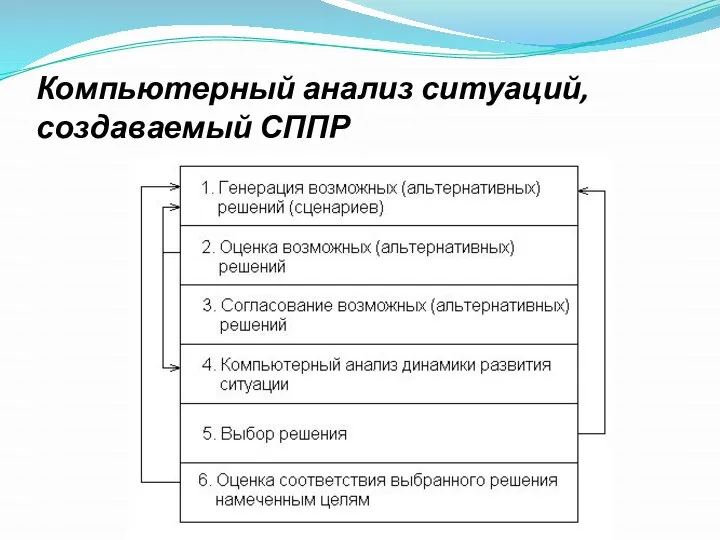
Компьютерный анализ ситуаций, создаваемый СППР
Компьютерный анализ ситуаций, создаваемый СППР

Классы задач анализа данных
Информационно-поисковый: СППР осуществляет поиск необходимых данных. Характерной чертой
Классы задач анализа данных
Информационно-поисковый: СППР осуществляет поиск необходимых данных. Характерной чертой
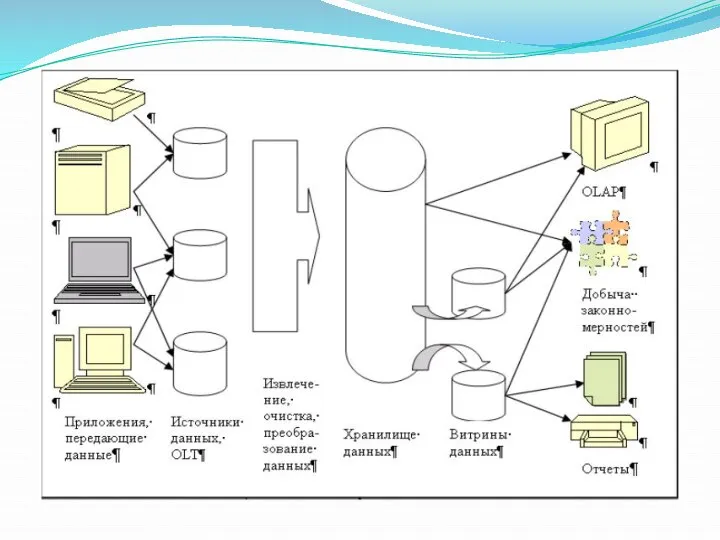
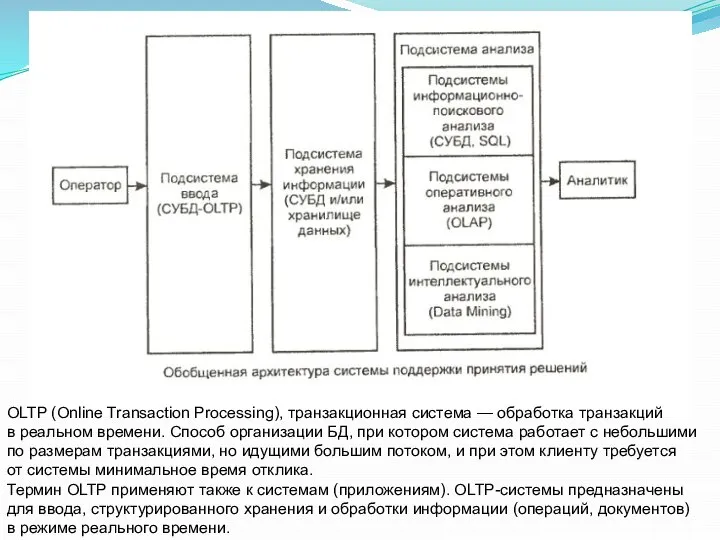
OLTP (Online Transaction Processing), транзакционная система — обработка транзакций
в реальном
OLTP (Online Transaction Processing), транзакционная система — обработка транзакций
в реальном

Хранилища данных
В основе концепции ХД лежит идея разделения данных, используемых для
Хранилища данных
В основе концепции ХД лежит идея разделения данных, используемых для
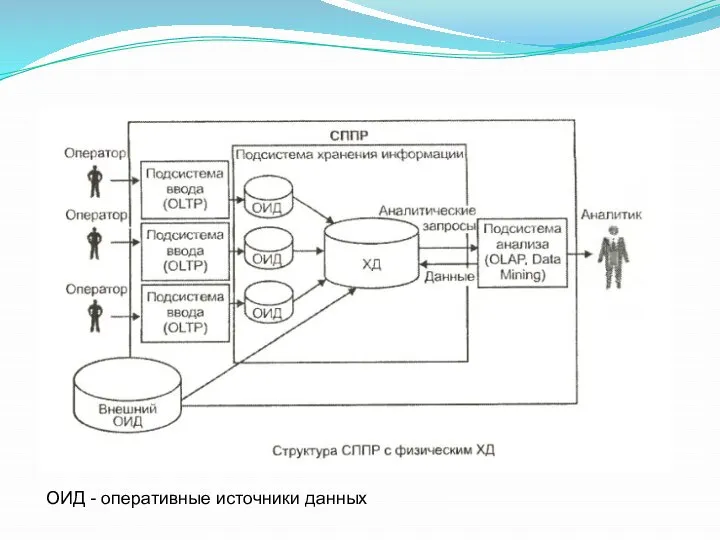
ОИД - оперативные источники данных
ОИД - оперативные источники данных
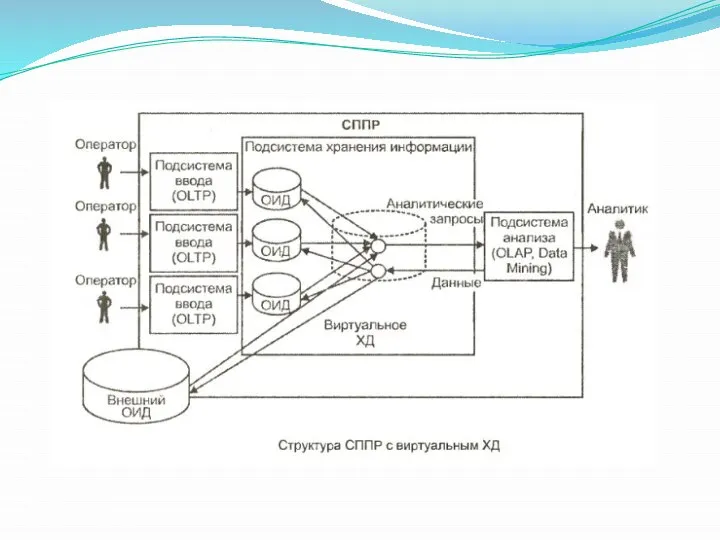

Проблемы создания физического ХД:
необходимость интеграции данных из неоднородных источников в распределенной
Проблемы создания физического ХД:
необходимость интеграции данных из неоднородных источников в распределенной
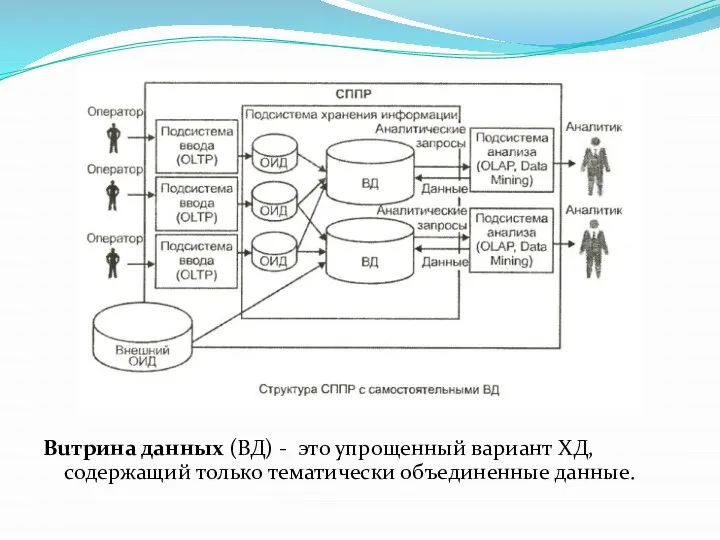
Buтpина данных (ВД) - это упрощенный вариант ХД, содержащий только тематически
Buтpина данных (ВД) - это упрощенный вариант ХД, содержащий только тематически
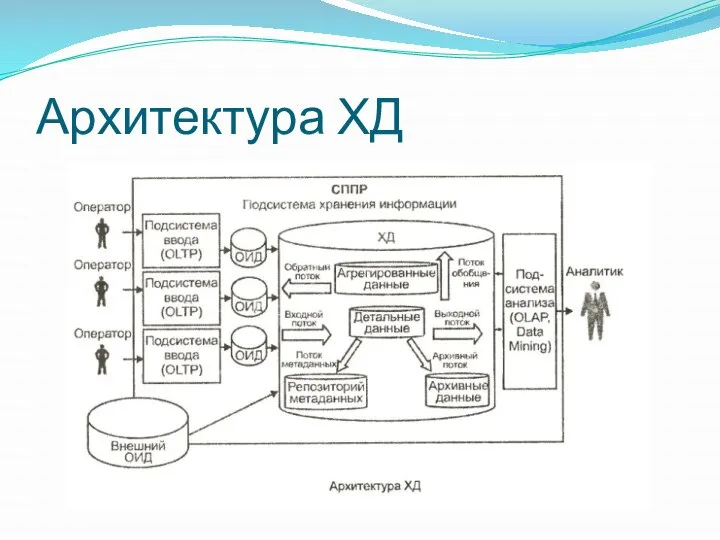
Архитектура ХД
Архитектура ХД

Состав ХД
Детальными являются данные, переносимые непосредственно из ОИД. Они соответствуют элементарным
Состав ХД
Детальными являются данные, переносимые непосредственно из ОИД. Они соответствуют элементарным

Состав ХД
Для удобства работы с ХД необходима информация о содержащихся в
Состав ХД
Для удобства работы с ХД необходима информация о содержащихся в

Информационные потоки в ХД
Входной поток (Inflow) образуется данными, копируемыми из оперативных
Информационные потоки в ХД
Входной поток (Inflow) образуется данными, копируемыми из оперативных
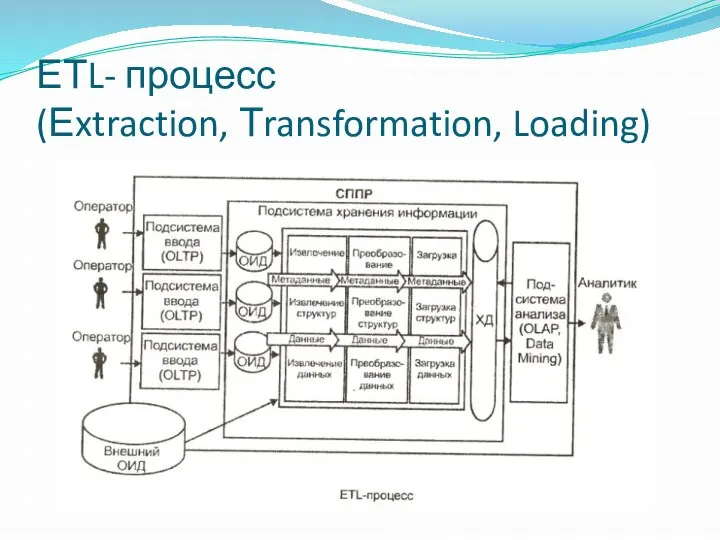
ЕТL- процесс
(Еxtraction, Тransformation, Loading)
ЕТL- процесс
(Еxtraction, Тransformation, Loading)

Очистка данных
Уровень ячейки таблицы:
Орфографические ошибки (опечатки)
Oтсутствие данных
Фиктивные значения
Логически
Очистка данных
Уровень ячейки таблицы:
Орфографические ошибки (опечатки)
Oтсутствие данных
Фиктивные значения
Логически

ОLАР-системы
Многомерная модель данных
Измерение - это последовательность значений одного из анализируемых
ОLАР-системы
Многомерная модель данных
Измерение - это последовательность значений одного из анализируемых
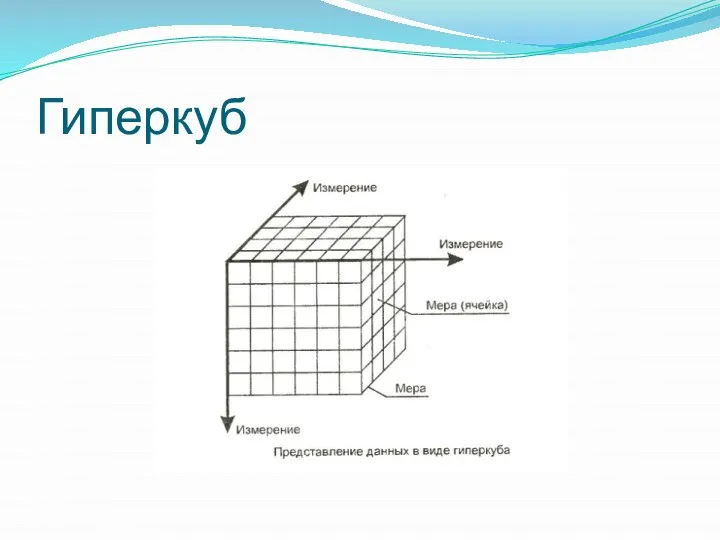
Гиперкуб
Гиперкуб
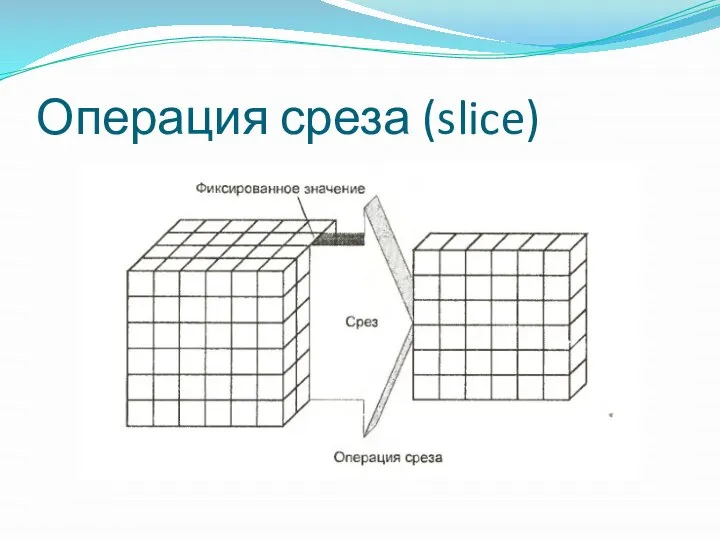
Операция среза (slice)
Операция среза (slice)
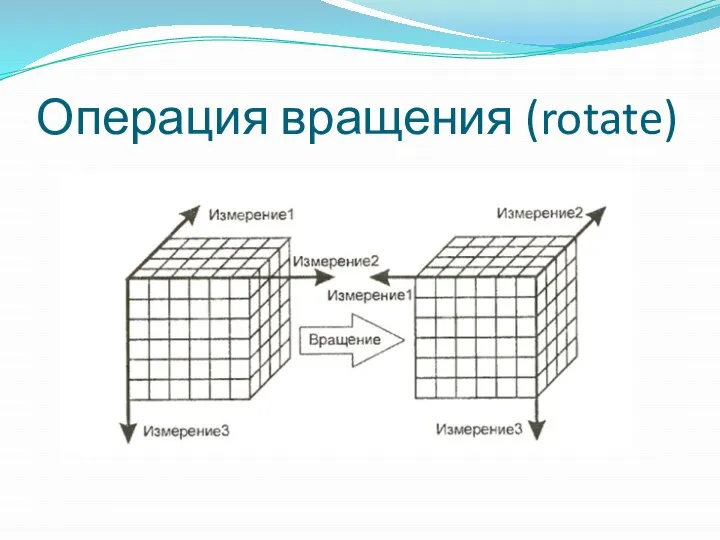
Операция вращения (rotate)
Операция вращения (rotate)
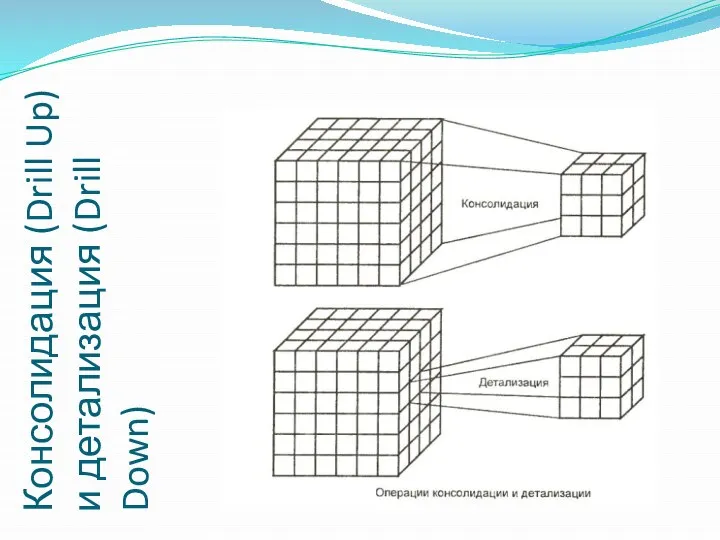
Консолидация (Drill Up)
и детализация (Drill Down)
Консолидация (Drill Up)
и детализация (Drill Down)

Двенадцать правил Кодда
Многомерность
Прозрачность
Доступность
Постоянная производительность при разработке отчетов
Клиент-серверная архитектура
Равноправие измерений
Динамическое
Двенадцать правил Кодда
Многомерность
Прозрачность
Доступность
Постоянная производительность при разработке отчетов
Клиент-серверная архитектура
Равноправие измерений
Динамическое

Дополнительные правила Кодда
Пакетное извлечение против интерпретации
Поддержка всех моделей ОLАР-анализа
Обработка ненормализованных
Дополнительные правила Кодда
Пакетное извлечение против интерпретации
Поддержка всех моделей ОLАР-анализа
Обработка ненормализованных

Тест FASMI
F AST (Быстрый)
ANALYSIS (Анализ)
SHARED (Разделяемой)
МULТIDIМЕNSIONАL (Mногомерной)
Тест FASMI
F AST (Быстрый)
ANALYSIS (Анализ)
SHARED (Разделяемой)
МULТIDIМЕNSIONАL (Mногомерной)

OLAP-серверы
MOLAP - многомерный (multivаriаtе) ОLАР. Для реализации многомерной модели используют многомерные
OLAP-серверы
MOLAP - многомерный (multivаriаtе) ОLАР. Для реализации многомерной модели используют многомерные
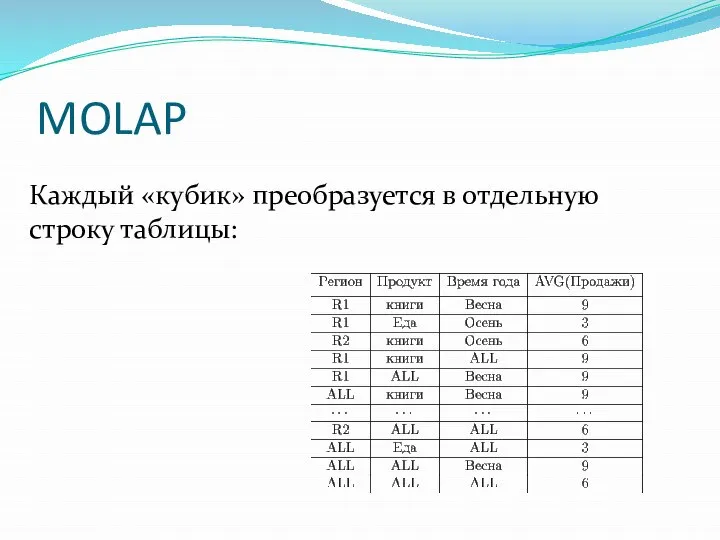
MOLAP
Каждый «кубик» преобразуется в отдельную строку таблицы:
MOLAP
Каждый «кубик» преобразуется в отдельную строку таблицы:

MOLAP
Преимущества:
поиск и выборка данных осуществляются значительно быстрее,
легко включить в информационную
MOLAP
Преимущества:
поиск и выборка данных осуществляются значительно быстрее,
легко включить в информационную

MOLAP – когда использовать?
объем исходных данных для анализа не слишком велик
MOLAP – когда использовать?
объем исходных данных для анализа не слишком велик
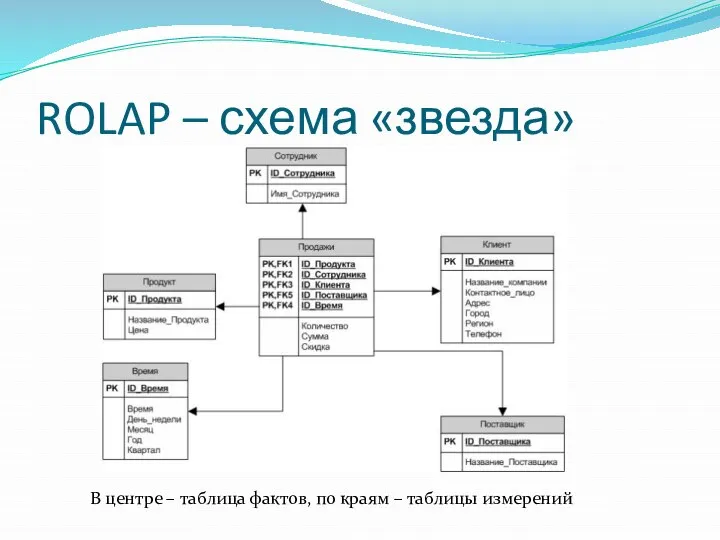
ROLAP – схема «звезда»
В центре – таблица фактов, по краям –
ROLAP – схема «звезда»
В центре – таблица фактов, по краям –
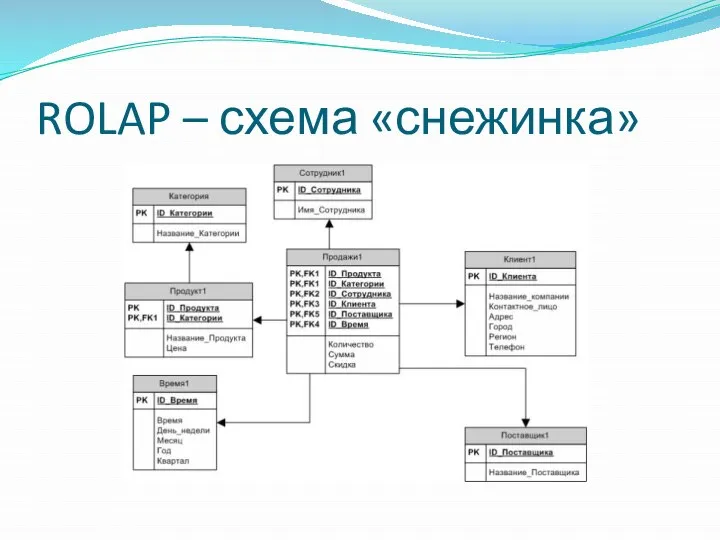
ROLAP – схема «снежинка»
ROLAP – схема «снежинка»
 Информационная разминка
Информационная разминка Теория информации (лекция 1)
Теория информации (лекция 1) Архитектура СУБД Oracle. Основные понятия. (Лекция 2)
Архитектура СУБД Oracle. Основные понятия. (Лекция 2) Система тестирования и сертификации. Макет
Система тестирования и сертификации. Макет Электронная почта
Электронная почта Мастерская Третье измерение. Наноград, Сочи 2017 День 4. Шпаргалка по шейдерам
Мастерская Третье измерение. Наноград, Сочи 2017 День 4. Шпаргалка по шейдерам Информационно-рекламная сеть
Информационно-рекламная сеть Источники ошибок в ПК Прусак А.В.
Источники ошибок в ПК Прусак А.В.  Совершенная дизъюнктивная нормальная форма
Совершенная дизъюнктивная нормальная форма Компания КОРЗИЛЛА
Компания КОРЗИЛЛА Государственные цифровые сервисы. Федеральные уроки информатики
Государственные цифровые сервисы. Федеральные уроки информатики Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера 3D-печать. Шестерни редуктора
3D-печать. Шестерни редуктора Создаем БД. Практические задания
Создаем БД. Практические задания Протокол BGP
Протокол BGP Применение баз данных. 11 класс
Применение баз данных. 11 класс Семантическая сегментация изображений на основе метода машинного обучения
Семантическая сегментация изображений на основе метода машинного обучения Компьютерные вирусы и антивирусы
Компьютерные вирусы и антивирусы Базы данных. Информационные системы
Базы данных. Информационные системы Тема урока «АЛГОРИТМ И ЕГО СВОЙСТВА» Учитель информатики Редько Галина Геннадьевна
Тема урока «АЛГОРИТМ И ЕГО СВОЙСТВА» Учитель информатики Редько Галина Геннадьевна Презентация "Файлы, файловая система и работа с ними" - скачать презентации по Информатике
Презентация "Файлы, файловая система и работа с ними" - скачать презентации по Информатике Комп'ютерні науки у створеннні АКС – автомобільних комп'ютернних систем
Комп'ютерні науки у створеннні АКС – автомобільних комп'ютернних систем Настройка точек доступа (1).pptx
Настройка точек доступа (1).pptx Отражение (reflection). Лекция 5
Отражение (reflection). Лекция 5 Еженедельный отчет. 16-22 апреля. Сайт lsr.ru (только СПб)
Еженедельный отчет. 16-22 апреля. Сайт lsr.ru (только СПб) Операционная система Программное обеспечение
Операционная система Программное обеспечение Презентация "Построение таблиц истинности" - скачать презентации по Информатике
Презентация "Построение таблиц истинности" - скачать презентации по Информатике Поиск данных. Поиск и систематизация информации
Поиск данных. Поиск и систематизация информации