- Стеки, очереди, деки

Содержание
- 2. Стек – это последовательный список переменной длины, включение и исключение элементов из которого производится только с
- 3. Абстрактное понятие стека допускает неопределенно большой список. Логически подносы в столовой могут складываться бесконечно. В действительности
- 4. ADT Stack (абстрактный тип данных) Данные Список элементов с позицией top, указывающей на вершину стека. Операции
- 5. Pop Вход: Нет Предусловия: Стек не пустой. Процесс: Удаление элемента из вершины стека. Выход: Возвращать элемент
- 6. LIFO (last-in/first-out – «последний вошел – первый вышел») При реализации стека на основе одномерного массива размер
- 7. При реализации стека с помощью указателей размер стека ограничен доступным объемом свободной памяти. Графическая структура стека
- 8. Класс Stack Члены класса Stack включают список, индекс или указатель на вершину стека и набор стековых
- 9. Первоначально стек пуст и top = -1. Элементы вводятся в массив (функция Push) в возрастающем порядке
- 10. Спецификация класса Stack //ОБЪЯВЛЕНИЕ //#include //#include const int MaxStackSize = 50; class Stack { private: //
- 11. ОПИСАНИЕ спецификации Данные в стеке имеют тип DataType, который должен определяться с использованием оператора typedef. Пользователь
- 12. Допустим, объявление стека и реализация содержатся в файле astack.h. typedef int DataType; ….. #include astack.h; //
- 13. Реализация класса Stack // инициализация вершины стека Stack::Stack (void) : top(-1) { } //поместить элемент в
- 14. // взять элемент из стека DataType Stack::Pop (void) { DataType temp; // стек пуст, завершить программу
- 15. // возвратить данные в вершине стека DataType Stack::Peek (void) const { // если стек пуст, завершить
- 16. Для защиты целостности стека класс предусматривает операции тестирования состояния стека. // тестирование стека на наличие в
- 17. Пример применения Палиндромы. Когда DataType является типом char, приложение обрабатывает символьный стек. Приложение определяет палиндромы, являющиеся
- 18. #include // … typedef char DataType; // элементы стека - символы #include “astack.h" // создает новую
- 19. int main ( ) { const int True = 1, False = 0; Stack S; char
- 20. Стек является чрезвычайно удобной структурой данных для многих задач вычислительной техники. Наиболее типичной из таких задач
- 21. Стек используется для размещения в нем локальных переменных процедур и иных программных блоков. При каждой активизации
- 22. В микропроцессорах семейства Intel, как и в большинстве современных процессорных архитектур, поддерживается аппаратный стек. Аппаратный стек
- 23. Очереди Очередь (queue) — структура данных типа «список», позволяющая добавлять элементы лишь в конец списка, и
- 24. Очереди часто используются в программах для реализации буфера, в который можно положить элемент для последующей обработки,
- 25. Очередь может быть реализована двумя способами: на основе массивов и списками при помощи указателей. Начало очереди
- 26. Рассмотрим класс Queue - используется массив для сохранения списка элементов и определяет переменные, которые поддерживают позиции
- 27. Спецификация класса Queue ОБЪЯВЛЕНИЕ #include … const int MaxQSize = 50; // максимальный размер списка очереди
- 28. Пусть объявление очереди и реализация содержатся в файле aqueue.h. ПРИМЕР typedef int DataType; #include aqueue.h ….
- 29. Схема организации линейной очереди на основе массива Простейшая линейная очередь на основе одномерного массива. При исключении
- 30. Вид 4: клиенты D, Е и F встают в очередь, заполняя ее, а клиент G должен
- 31. Кольцевая очередь является более эффективной. Элементы кольцевой очереди организованы логически в окружность. Переменная front всегда является
- 32. Круговая модель очереди Реализуем круговое движение, используя операцию остатка от деления: Перемещение конца очереди вперед: rear
- 33. Используем целый массив qlist (размер = 4) из четырех элементов для реализации круговой очереди. Первоначально count
- 34. Конструктор Queue Конструктор инициализирует элементы данных front rear и count нулевыми значениями. Это задает пустую очередь.
- 35. Перед началом процесса вставки индекс rear указывает на следующую позицию в списке. Новый элемент помещается в
- 36. Qinsert // вставить item в круговую очередь void Queue::QInsert (const DataType& item) { if (count =
- 37. Операция QDelete удаляет элемент из начала очереди, позиции, на которую ссылается индекс front. Процесс удаления начинается
- 38. Qdelete // удалить элемент из начала очереди и возвратить его значение DataType Queue::QDelete(void) { DataType temp;
- 39. Реализация очереди с помощью указателей struct SQueue { int dann; SQueue *next; }; SQueue * front=NULL,
- 40. Очереди приоритетов (Ранее дано определение, что очередь — это структура данных, которая обеспечивает FIFO-порядок элементов. Очередь
- 41. Структура, называемая очередью приоритетов (priority queue), имеет опeрации PQInsert и PQDelete: PQInsert просто вставляет элемент данных
- 42. Очередь приоритетов можно представить в виде нескольких очередей, где каждая очередь используется для своего приоритета.
- 43. ADT - очередь приоритетов описывается как список с операциями для добавления или удаления элементов из списка.
- 44. Спецификация класса PQueue ОБЪЯВЛЕНИЕ #include … const int MaxPQSize = 50; class PQueue { int count;
- 45. Метод PQDelete удаляет элемент с высшим приоритетом из списка. Полагаем, что элемент с высшим приоритетом —
- 46. PQInsert // вставить элемент в очередь приоритетов void PQueue::PQInsert (const DataType& item) { //если уже вcе
- 47. PQDelete // удаляет элемент из очереди приоритетов и возвращает его значение DataType PQueue::PQDelete(void) { DataType min;
- 48. Операция PQInsert имеет время вычисления (порядок) О(1), так как она непосредственно добавляет элемент в конец списка.
- 49. Дек (от англ. deq - double ended queue, очередь с двумя концами) - это такой последовательный
- 50. Задачи, требующие структуры дека, встречаются в вычислительной технике и программировании гораздо реже, чем задачи, реализуемые на
- 51. Вся организация дека выполняется программистом без каких-либо специальных средств системной поддержки. Однако, в качестве примера такой
- 52. В программных системах, обрабатывающих объекты сложной структуры, могут решаться разные подзадачи, каждая из которых требует, возможно,
- 53. Мультисписок состоит из элементов, содержащих такое число указателей, которое позволяет организовать их одновременно в виде нескольких
- 55. Для того чтобы при выборке каждого подмножества не выполнять полный просмотр с отсеиванием записей, к требуемому
- 56. Каждая подзадача работает со своим подмножеством как с линейным списком, используя для этого определенное поле связок.
- 57. Экономия памяти далеко не единственная причина, по которой применяют мультисписки. Многие реальные структуры данных не сводятся
- 58. Часто в виде мультисписков представляют матрицы очень большой размерности, в которых большинство элементов равны 0 (такие
- 60. Нелинейные разветвленные списки Нелинейным разветвленным списком является список, элементами которого могут быть тоже списки. (a,(b,c,d),e,(f,g)) (
- 62. Скачать презентацию

Стек – это последовательный список переменной длины, включение и исключение элементов
Стек – это последовательный список переменной длины, включение и исключение элементов

Абстрактное понятие стека допускает неопределенно большой список. Логически подносы в столовой
Абстрактное понятие стека допускает неопределенно большой список. Логически подносы в столовой

ADT Stack (абстрактный тип данных)
Данные
Список элементов с позицией top, указывающей на
ADT Stack (абстрактный тип данных)
Данные
Список элементов с позицией top, указывающей на

Pop
Вход: Нет
Предусловия: Стек не пустой.
Процесс: Удаление элемента из вершины стека.
Выход: Возвращать элемент из вершины
Pop
Вход: Нет
Предусловия: Стек не пустой.
Процесс: Удаление элемента из вершины стека.
Выход: Возвращать элемент из вершины

LIFO (last-in/first-out – «последний вошел – первый вышел»)
При реализации стека на
LIFO (last-in/first-out – «последний вошел – первый вышел»)
При реализации стека на
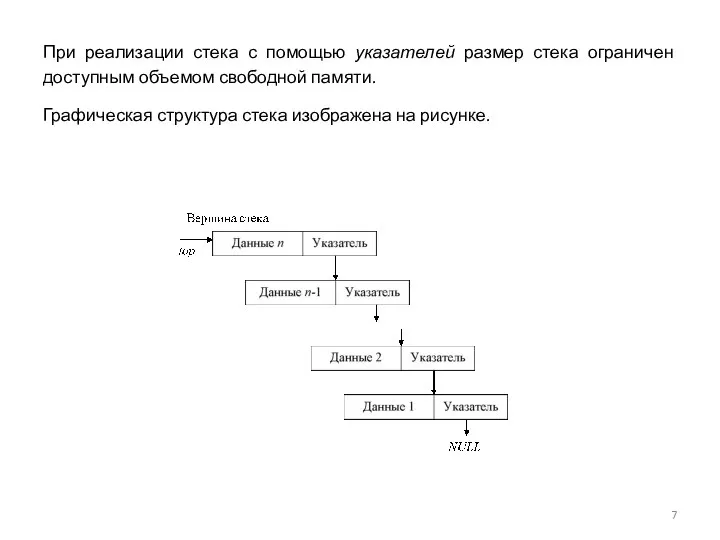
При реализации стека с помощью указателей размер стека ограничен доступным объемом
При реализации стека с помощью указателей размер стека ограничен доступным объемом

Класс Stack
Члены класса Stack включают список, индекс или указатель на вершину
Класс Stack
Члены класса Stack включают список, индекс или указатель на вершину

Первоначально стек пуст и top = -1.
Элементы вводятся в массив
Первоначально стек пуст и top = -1.
Элементы вводятся в массив

Спецификация класса Stack
//ОБЪЯВЛЕНИЕ
//#include
//#include
const int MaxStackSize = 50;
class Stack
{
private:
Спецификация класса Stack
//ОБЪЯВЛЕНИЕ
//#include
//#include
const int MaxStackSize = 50;
class Stack
{
private:

ОПИСАНИЕ спецификации
Данные в стеке имеют тип DataType, который должен определяться с
ОПИСАНИЕ спецификации
Данные в стеке имеют тип DataType, который должен определяться с

Допустим, объявление стека и реализация содержатся в файле astack.h.
typedef int DataType;
…..
#include
Допустим, объявление стека и реализация содержатся в файле astack.h.
typedef int DataType;
…..
#include

Реализация класса Stack
// инициализация вершины стека
Stack::Stack (void) : top(-1) { }
//поместить
Реализация класса Stack
// инициализация вершины стека
Stack::Stack (void) : top(-1) { }
//поместить

// взять элемент из стека
DataType Stack::Pop (void)
{ DataType temp;
// стек
// взять элемент из стека
DataType Stack::Pop (void)
{ DataType temp;
// стек

// возвратить данные в вершине стека
DataType Stack::Peek (void) const
{ //
// возвратить данные в вершине стека
DataType Stack::Peek (void) const
{ //

Для защиты целостности стека класс предусматривает операции тестирования состояния стека.
// тестирование
Для защиты целостности стека класс предусматривает операции тестирования состояния стека.
// тестирование
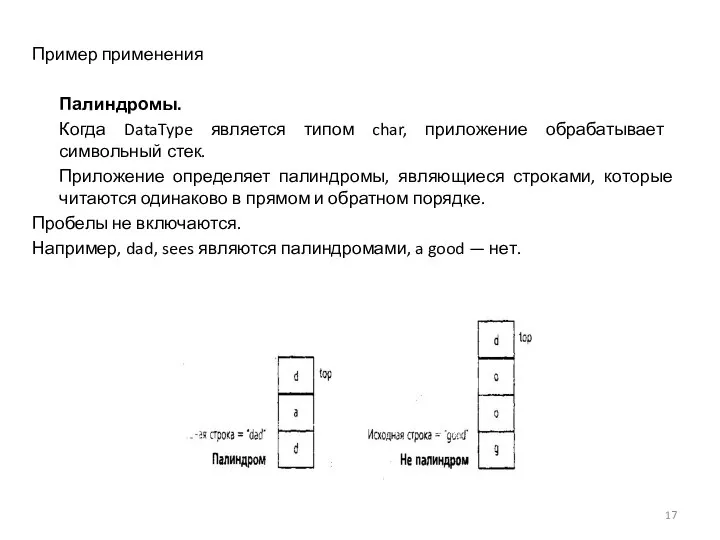
Пример применения
Палиндромы.
Когда DataType является типом char, приложение обрабатывает символьный стек.
Пример применения
Палиндромы.
Когда DataType является типом char, приложение обрабатывает символьный стек.

#include
// …
typedef char DataType; // элементы стека - символы
#include “astack.h"
// создает
#include
// …
typedef char DataType; // элементы стека - символы
#include “astack.h"
// создает

int main ( )
{
const int True = 1, False
int main ( )
{
const int True = 1, False

Стек является чрезвычайно удобной структурой данных для многих задач вычислительной техники.
Стек является чрезвычайно удобной структурой данных для многих задач вычислительной техники.

Стек используется для размещения в нем локальных переменных процедур и иных
Стек используется для размещения в нем локальных переменных процедур и иных

В микропроцессорах семейства Intel, как и в большинстве современных процессорных архитектур,
В микропроцессорах семейства Intel, как и в большинстве современных процессорных архитектур,

Очереди
Очередь (queue) — структура данных типа «список», позволяющая добавлять элементы лишь
Очереди
Очередь (queue) — структура данных типа «список», позволяющая добавлять элементы лишь

Очереди часто используются в программах для реализации буфера, в который можно
Очереди часто используются в программах для реализации буфера, в который можно

Очередь может быть реализована двумя способами: на основе массивов и списками
Очередь может быть реализована двумя способами: на основе массивов и списками

Рассмотрим класс Queue - используется массив для сохранения списка элементов и
Рассмотрим класс Queue - используется массив для сохранения списка элементов и

Спецификация класса Queue
ОБЪЯВЛЕНИЕ
#include
…
const int MaxQSize = 50; // максимальный размер списка
Спецификация класса Queue
ОБЪЯВЛЕНИЕ
#include
…
const int MaxQSize = 50; // максимальный размер списка

Пусть объявление очереди и реализация содержатся в файле aqueue.h.
ПРИМЕР
typedef int
Пусть объявление очереди и реализация содержатся в файле aqueue.h.
ПРИМЕР
typedef int

Схема организации линейной очереди на основе массива
Простейшая линейная очередь на основе
Схема организации линейной очереди на основе массива
Простейшая линейная очередь на основе

Вид 4: клиенты D, Е и F встают в очередь, заполняя
Вид 4: клиенты D, Е и F встают в очередь, заполняя

Кольцевая очередь является более эффективной.
Элементы кольцевой очереди организованы логически в
Кольцевая очередь является более эффективной.
Элементы кольцевой очереди организованы логически в
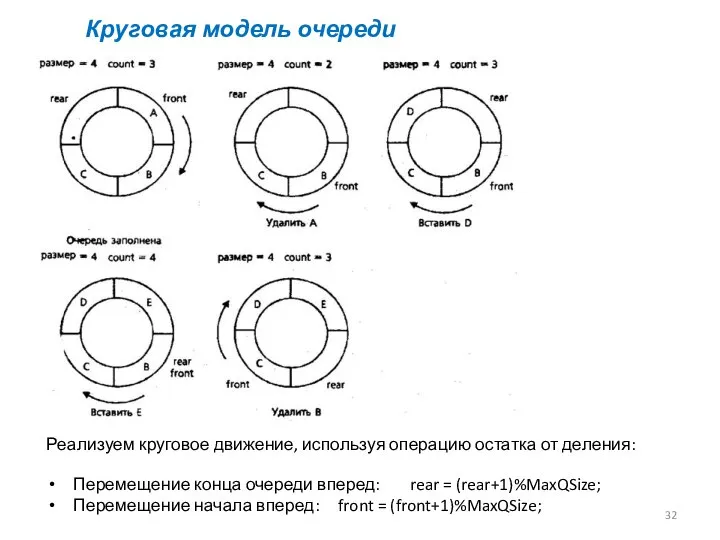
Круговая модель очереди
Реализуем круговое движение, используя операцию остатка от деления:
Перемещение конца
Круговая модель очереди
Реализуем круговое движение, используя операцию остатка от деления:
Перемещение конца

Используем целый массив qlist (размер = 4) из четырех элементов для
Используем целый массив qlist (размер = 4) из четырех элементов для

Конструктор Queue
Конструктор инициализирует элементы данных front rear и count нулевыми значениями.
Конструктор Queue
Конструктор инициализирует элементы данных front rear и count нулевыми значениями.

Перед началом процесса вставки индекс rear указывает на следующую позицию в
Перед началом процесса вставки индекс rear указывает на следующую позицию в
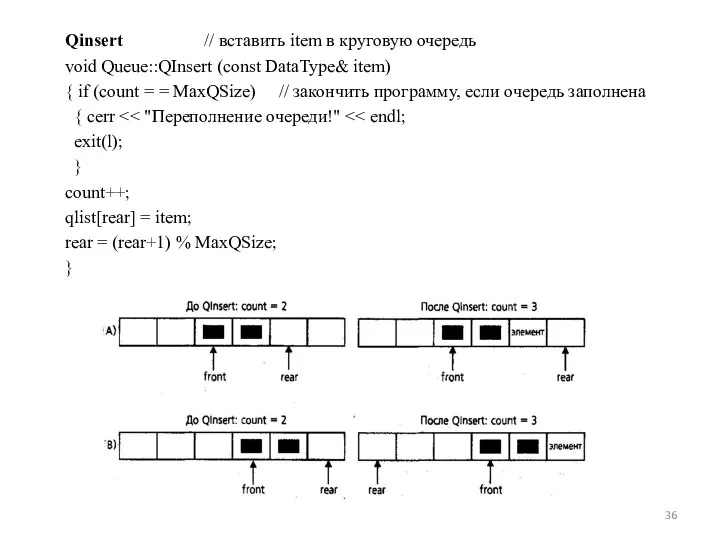
Qinsert // вставить item в круговую очередь
void Queue::QInsert (const DataType&
Qinsert // вставить item в круговую очередь
void Queue::QInsert (const DataType&

Операция QDelete удаляет элемент из начала очереди, позиции, на которую ссылается
Операция QDelete удаляет элемент из начала очереди, позиции, на которую ссылается

Qdelete // удалить элемент из начала очереди и возвратить его значение
Qdelete // удалить элемент из начала очереди и возвратить его значение

Реализация очереди с помощью указателей
struct SQueue { int dann;
SQueue
Реализация очереди с помощью указателей
struct SQueue { int dann;
SQueue

Очереди приоритетов
(Ранее дано определение, что очередь — это структура данных, которая
Очереди приоритетов
(Ранее дано определение, что очередь — это структура данных, которая

Структура, называемая очередью приоритетов (priority queue), имеет опeрации PQInsert и PQDelete:
PQInsert
Структура, называемая очередью приоритетов (priority queue), имеет опeрации PQInsert и PQDelete:
PQInsert

Очередь приоритетов можно представить в виде нескольких очередей, где каждая очередь
Очередь приоритетов можно представить в виде нескольких очередей, где каждая очередь

ADT - очередь приоритетов описывается как список с операциями для добавления
ADT - очередь приоритетов описывается как список с операциями для добавления

Спецификация класса PQueue
ОБЪЯВЛЕНИЕ
#include
…
const int MaxPQSize = 50;
class PQueue
{ int
Спецификация класса PQueue
ОБЪЯВЛЕНИЕ
#include
…
const int MaxPQSize = 50;
class PQueue
{ int

Метод PQDelete удаляет элемент с высшим приоритетом из списка.
Полагаем, что
Метод PQDelete удаляет элемент с высшим приоритетом из списка.
Полагаем, что
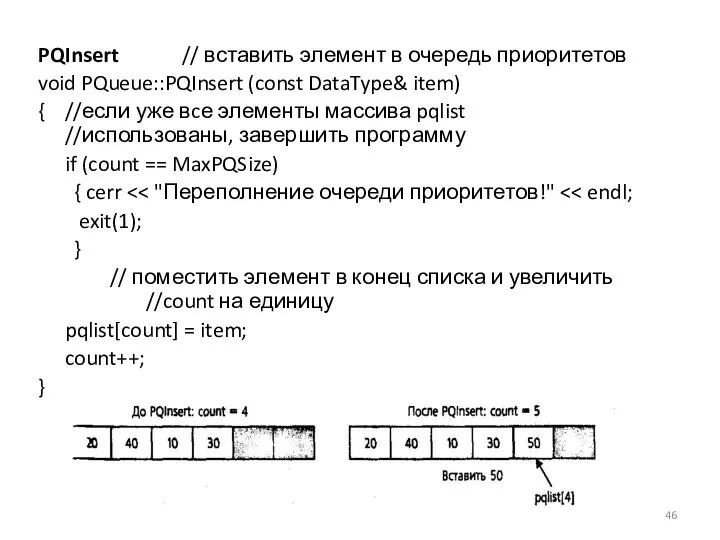
PQInsert // вставить элемент в очередь приоритетов
void PQueue::PQInsert (const DataType& item)
{ //если
PQInsert // вставить элемент в очередь приоритетов
void PQueue::PQInsert (const DataType& item)
{ //если

PQDelete // удаляет элемент из очереди приоритетов и возвращает его значение
DataType
PQDelete // удаляет элемент из очереди приоритетов и возвращает его значение
DataType

Операция PQInsert имеет время вычисления (порядок) О(1), так как она непосредственно
Операция PQInsert имеет время вычисления (порядок) О(1), так как она непосредственно

Дек (от англ. deq - double ended queue, очередь с двумя
Дек (от англ. deq - double ended queue, очередь с двумя

Задачи, требующие структуры дека, встречаются в вычислительной технике и программировании гораздо
Задачи, требующие структуры дека, встречаются в вычислительной технике и программировании гораздо

Вся организация дека выполняется программистом без каких-либо специальных средств системной поддержки.
Однако,
Вся организация дека выполняется программистом без каких-либо специальных средств системной поддержки.
Однако,

В программных системах, обрабатывающих объекты сложной структуры, могут решаться разные подзадачи,
В программных системах, обрабатывающих объекты сложной структуры, могут решаться разные подзадачи,

Мультисписок состоит из элементов, содержащих такое число указателей, которое позволяет организовать
Мультисписок состоит из элементов, содержащих такое число указателей, которое позволяет организовать


Для того чтобы при выборке каждого подмножества не выполнять полный просмотр
Для того чтобы при выборке каждого подмножества не выполнять полный просмотр

Каждая подзадача работает со своим подмножеством как с линейным списком, используя
Каждая подзадача работает со своим подмножеством как с линейным списком, используя

Экономия памяти далеко не единственная причина, по которой применяют мультисписки.
Многие
Экономия памяти далеко не единственная причина, по которой применяют мультисписки.
Многие

Часто в виде мультисписков представляют матрицы очень большой размерности, в которых
Часто в виде мультисписков представляют матрицы очень большой размерности, в которых


Нелинейные разветвленные списки
Нелинейным разветвленным списком является список, элементами которого могут
Нелинейные разветвленные списки
Нелинейным разветвленным списком является список, элементами которого могут
 Презентация "Дисплейные технологии: сегодня и завтра" - скачать презентации по Информатике
Презентация "Дисплейные технологии: сегодня и завтра" - скачать презентации по Информатике Робот – фельдшер. Мобильная робототехника 14+
Робот – фельдшер. Мобильная робототехника 14+ Особенности проведения первого этапа аккредитации в дистанционной форме
Особенности проведения первого этапа аккредитации в дистанционной форме Component Enabler for .NET. Overview
Component Enabler for .NET. Overview Sociologia generale e dell’innovazione digitale
Sociologia generale e dell’innovazione digitale Проектирование программного комплекса для автоматизации деятельности автозаправочной станции
Проектирование программного комплекса для автоматизации деятельности автозаправочной станции მონაცემთა ბაზები
მონაცემთა ბაზები MS Word. Интерфейс, элементы документа, начало работы с документом
MS Word. Интерфейс, элементы документа, начало работы с документом Вставка объектов в текстовый документ
Вставка объектов в текстовый документ Разработка программного средства для автоматизации документооборота в системе клиент-банк
Разработка программного средства для автоматизации документооборота в системе клиент-банк Представление чисел в компьютере. Неотрицательные числа
Представление чисел в компьютере. Неотрицательные числа Системное программное обеспечение: антивирусные программы
Системное программное обеспечение: антивирусные программы Intro to AI Platform
Intro to AI Platform Запрос и отчёты в базах данных
Запрос и отчёты в базах данных Теория принятия решений принятие оптимальных решений методами динамического программирования
Теория принятия решений принятие оптимальных решений методами динамического программирования Текстовый редактор word. 9-10 класс
Текстовый редактор word. 9-10 класс База данных - основа информационной системы
База данных - основа информационной системы «1С:Расчет квартплаты и бухгалтерия ЖКХ» для предприятий ЖКХ Сервис «Отраслевые решения 1С через Интернет»
«1С:Расчет квартплаты и бухгалтерия ЖКХ» для предприятий ЖКХ Сервис «Отраслевые решения 1С через Интернет» Программирование задач с ветвлением
Программирование задач с ветвлением ИТ в гуманитарных исследованиях
ИТ в гуманитарных исследованиях Аттестационная работа. Образовательная программа. Создание мобильных приложений в App Inventor 2
Аттестационная работа. Образовательная программа. Создание мобильных приложений в App Inventor 2 Основы алгебры логики
Основы алгебры логики Прикладное программное обеспечение
Прикладное программное обеспечение Простые типы данных языка Assembler. Сегмент данных
Простые типы данных языка Assembler. Сегмент данных Мәліметтер қоры (МҚ)
Мәліметтер қоры (МҚ) Проектирование реляционной базы данных. Основные принципы проектирования
Проектирование реляционной базы данных. Основные принципы проектирования Creation of a regional political talk-show
Creation of a regional political talk-show Заключительный урок по информатике. Викторина. 10 класс
Заключительный урок по информатике. Викторина. 10 класс