- Tensilica Xtensa

Содержание
- 2. Overview Background Changes in progress from Xtensa to Xtensa LX Automated Development Process ISA TIE Language
- 3. Tensilica Founded in 1997 in Santa Clara, California by a group of engineers from Intel, SGI,
- 4. Why? Embedded application problems with high cost custom designs or low performance (inefficiencient) processors System on
- 5. The Problem with RTL Rapidly increasing number of transistors require more RTL blocks on chip Hardcoded
- 6. Tensilica’s Solution Xtensa Focusing on design through the processor, and not through hardwired RTL
- 7. Xtensa First appearing in 1999 32-bit microprocessor core with a graphical configuration interface and integrated tool
- 8. Xtensa – In a Nutshell Enables embedded system designers to build better, more highly integrated products
- 9. Xtensa - Deliverables Provided as synthesizable RTL cores Gate count range: 25,000 – 150,000+ Increase in
- 10. Xtensa – Verification Challenges To extensively verify the configurable processor to ensure each possible configuration will
- 11. Xtensa – Basic Architecture 78 instructions five-stage pipeline that supports single-cycle execution 1 - load/store model
- 12. Xtensa – Basic Architecture Processor Configuration Power Usage: 200mW, 0.25 μm, 1.5V Clock Speed: 170 MHz
- 13. Xtensa - ISA Priorities used in ISA Development Code Size, Configurability, Processor Cost, Energy Efficiency, Scalability,
- 14. Xtensa III With Virtual IP Group developed an MP3 audio decoder for Tensilica's Xtensa configurable microprocessor
- 15. Xtensa IV Used white box verification methodology for the original development Includes 0-In Check and the
- 16. Xtensa V 350MHz (synthesized), as small as 18K gates (0.25mm2) More flexible interfaces for multiple processors
- 17. Xtensa V – Performance Cost Timeline
- 18. Xtensa 6 Extremely fast customization path Three major enhancements from Xtensa V Auto customize processor from
- 19. Xtensa LX “Fastest processor core ever” – Tensilica I/O bandwidth, compute parallelism, and low-power optimization equivalent
- 20. Xtensa 6 Vs Xtensa LX
- 21. Xtensa LX Strongest selling point is performance DSP operations can be encapsulated into custom instructions High
- 22. Xtensa LX Vs General Purpose
- 23. Xtensa LX – Traditional Limitations 1 Operation / cycle Load/Store overhead
- 24. Xtensa LX Options: Extra load/store unit, wide interfaces, compound instructions Up to 19 GB/sec of throughput
- 25. Xtensa LX – Highlights Lower power usage I/O throughput at RTL speeds Outstanding computer performance XPRES
- 26. Xtensa LX – Lower Power Useage Automated the insertion of fine-grain clock gating for every functional
- 27. Outstanding Computing Performance Extensible using FLIX (Flexible Length Instruction Xtensions) Similar to VLIW – but customizable
- 28. XPRES Compiler Powerful synthesis tool Creates tailored processor descriptions Run on native C/C++ code
- 29. Automated Development Clients log into website Accessing Process Generator Builds a model in RTL Verilog or
- 30. Automated Development Create special instructions described and written in TIE TIE semantics allow system to modify
- 31. Xtensa LX – Basic Architecture Processor Configuration Power Usage: 76 μW/MHz , 47 μW/MHz ( 5
- 32. Xtensa LX Architecture 32-bit ALU 1 or 2 Load/Store Model Registers 32-bit general purpose register file
- 33. Xtensa LX Architecture General Purpose AR Register File 32 or 64 registers Instructions have access through
- 34. Xtensa LX Architecture
- 35. Xtensa LX Pipelining 5 or 7 Stage Pipeline Design 5 stage pipeline has stages: IF, Register
- 36. Xtensa LX Instruction Set ISA consists of 80 core instructions including both 16 and 24 bit
- 37. Xtensa LX Instruction Set Processor Control Instructions RSR, WSR, XSR Read Special Register, Write Special Register
- 38. Xtensa LX ISA – Building Blocks MUL32 MUL32 adds 32 bit multiplier MUL16 and MAC16 MUL16
- 39. Xtensa LX ISA – Building Blocks Floating Point Unit 32-bit, single precision, floating-point coprocessor Vectra LX
- 40. Vectra LX DSP Engine FLIX-based (why it is 64 bits) Vectra LX instructions encoded in 64
- 41. Vectra LX DSP Engine
- 42. Tensilica Instruction Extension Method used to extend the processor’s architecture and instruction set Can be used
- 43. Tensilica Instruction Extension TIE Compiler Generates file used to configure software development tools so that they
- 44. TIE Resembles Verilog More concise than RTL (it omits all sequential logic, pipeline registers, and initialization
- 45. TIE Queues and Ports New way to communicate with external devices Queues: data can be sent
- 46. TIE TIE Combines multiple operations into one using: Fusion SIMD/Vector Transformation FLIX
- 47. Fusion Allows you to combine dependent operations into a single instruction Consider: computing the average of
- 48. Fusion Fuse the two operations into a single TIE instruction operation AVERAGE{out AR res, in AR
- 49. SIMD/Vector Transformation Single Instruction, Multiple Data Fusing instructions into a “vector” Allows replication of the same
- 50. SIMD/Vector Transformation Computing four 16-bit averages Each data vector must be 64 bits (4 x 16
- 51. FLIX Flexible length instruction extension Key in extreme extensibility Huge performance gains possible Code size reduction
- 52. FLIX
- 53. FLIX - Usage Used selectively when parallelism is needed Avoids code bloat Used seemlessly and modelessly
- 54. XPRES Compiler Powerful synthesis tool Creates tailored processor descriptions Run on native C/C++ code Three optimizations
- 55. XPRES Compiler Analyzes C/C++ code Generates possible configurations Compares performance criteria to silicon size (cost) Returns
- 56. XPRES Compiler - Results Application dependent Compute intensive programs Data intensive programs More is sometimes less
- 57. XPRES – 4 Program Test “Bit Manipulator” program Cut cycles to a third
- 58. XPRES – 4 Program Test H.264 Deblocking Filter 6% performance improvement
- 59. XPRES – 4 Program Test MPEG4 decoder 23% performance increase
- 60. XPRES – 4 Program Test SAD – sum of absolute difference 63% performance increase
- 61. Xtensa Hi-Fi 2 Audio Engine Add-on package for Xtensa LX Advantages over common audio processors: better
- 62. Xtensa Hi-Fi 2 Audio Engine Audio packages integrated into an SOC design, so no additional codec
- 63. Xtensa Hi-Fi 2 Audio Engine Uses over 300 audio specific DLP instructions. Features dual-multiply accumulate for
- 64. Speed-up Example GSM Audio Codec – written in C Profiling code using unaltered RISC architecture showed
- 65. Speed-up Example Viterbi butterfly instruction Acts like compression for the data Consists of 8 logical operation
- 66. EEMBC Networking Benchmark Xtensa LX received highest benchmark ever achieved on the Networking version 2 test.
- 67. EEMBC Networking Benchmark Normalized (per MHz) EEMBC TCPmark Simulates performance in internet enabled client side performance
- 68. EEMBC Networking Benchmark Normalized (by MHz) EEMBC IPmark Simulates performance in network routers, gateways, and switches
- 69. EEMBC Networking Benchmark Total Code Size
- 71. How Xtensa Compares
- 72. How Xtensa Compares
- 73. How Xtensa Compares (cont)
- 74. Uses of Xtensa Products NVIDIA – Licensed Xtensa LX “We were very impressed with Tensilica's automated
- 75. Uses of Xtensa Products LG Cell Phone Phone is digital broadcast enabled Xtensa processor was used
- 76. In case you are wondering.. --Tensilica's announced licensees include Agilent, ALPS, AMCC (JNI Corporation), Astute Networks,
- 78. Скачать презентацию

Overview
Background
Changes in progress from Xtensa to Xtensa LX
Automated Development Process
ISA
TIE Language
Benchmarks
Overview
Background
Changes in progress from Xtensa to Xtensa LX
Automated Development Process
ISA
TIE Language
Benchmarks

Tensilica
Founded in 1997 in Santa Clara, California by a group of
Tensilica
Founded in 1997 in Santa Clara, California by a group of

Why?
Embedded application problems with high cost custom designs or low performance
Why?
Embedded application problems with high cost custom designs or low performance

The Problem with RTL
Rapidly increasing number of transistors require more RTL
The Problem with RTL
Rapidly increasing number of transistors require more RTL

Tensilica’s Solution
Xtensa
Focusing on design through the processor, and not through hardwired
Tensilica’s Solution
Xtensa
Focusing on design through the processor, and not through hardwired

Xtensa
First appearing in 1999
32-bit microprocessor core with a graphical configuration interface
Xtensa
First appearing in 1999
32-bit microprocessor core with a graphical configuration interface

Xtensa – In a Nutshell
Enables embedded system designers to build better,
Xtensa – In a Nutshell
Enables embedded system designers to build better,

Xtensa - Deliverables
Provided as synthesizable RTL cores
Gate count range: 25,000 –
Xtensa - Deliverables
Provided as synthesizable RTL cores
Gate count range: 25,000 –

Xtensa – Verification Challenges
To extensively verify the configurable processor to ensure
Xtensa – Verification Challenges
To extensively verify the configurable processor to ensure

Xtensa – Basic Architecture
78 instructions
five-stage pipeline that supports single-cycle execution
1 -
Xtensa – Basic Architecture
78 instructions
five-stage pipeline that supports single-cycle execution
1 -

Xtensa – Basic Architecture
Processor Configuration
Power Usage: 200mW, 0.25 μm, 1.5V
Clock Speed:
Xtensa – Basic Architecture
Processor Configuration
Power Usage: 200mW, 0.25 μm, 1.5V
Clock Speed:

Xtensa - ISA
Priorities used in ISA Development
Code Size, Configurability, Processor Cost,
Xtensa - ISA
Priorities used in ISA Development
Code Size, Configurability, Processor Cost,

Xtensa III
With Virtual IP Group developed an MP3 audio decoder for
Xtensa III
With Virtual IP Group developed an MP3 audio decoder for

Xtensa IV
Used white box verification methodology for the original development
Includes 0-In
Xtensa IV
Used white box verification methodology for the original development
Includes 0-In

Xtensa V
350MHz (synthesized), as small as 18K gates (0.25mm2)
More flexible
Xtensa V
350MHz (synthesized), as small as 18K gates (0.25mm2)
More flexible
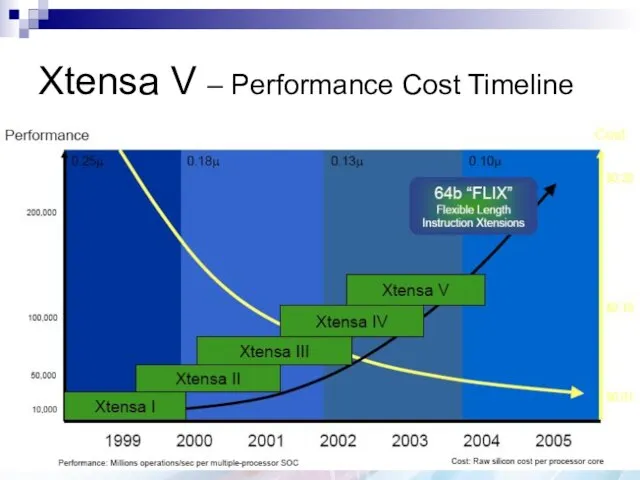
Xtensa V – Performance Cost Timeline
Xtensa V – Performance Cost Timeline

Xtensa 6
Extremely fast customization path
Three major enhancements from Xtensa V
Auto customize
Xtensa 6
Extremely fast customization path
Three major enhancements from Xtensa V
Auto customize

Xtensa LX
“Fastest processor core ever” – Tensilica
I/O bandwidth, compute parallelism, and
Xtensa LX
“Fastest processor core ever” – Tensilica
I/O bandwidth, compute parallelism, and
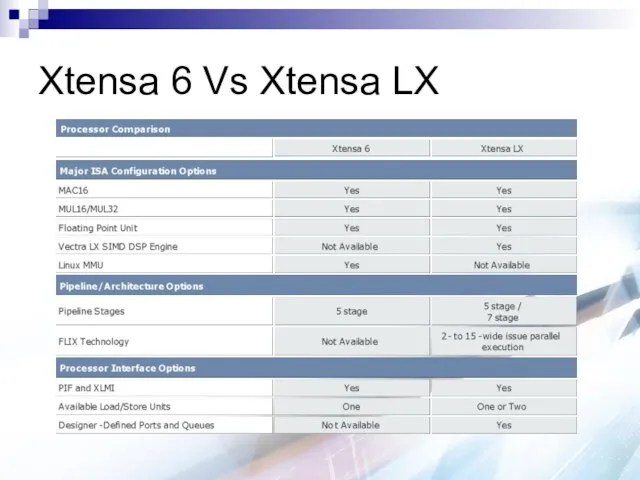
Xtensa 6 Vs Xtensa LX
Xtensa 6 Vs Xtensa LX

Xtensa LX
Strongest selling point is performance
DSP operations can be encapsulated into
Xtensa LX
Strongest selling point is performance
DSP operations can be encapsulated into
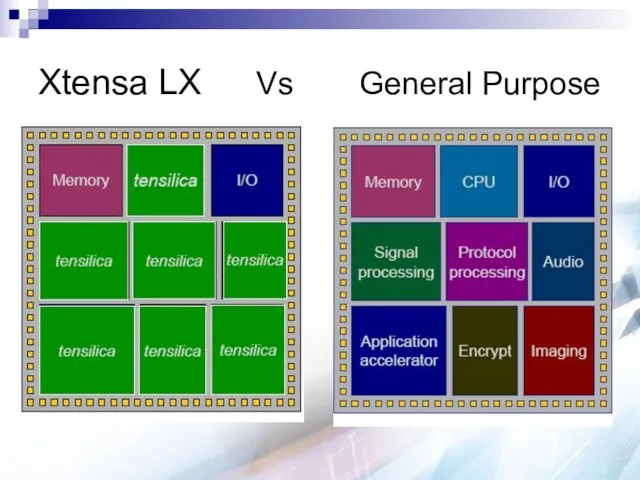
Xtensa LX Vs General Purpose
Xtensa LX Vs General Purpose

Xtensa LX – Traditional Limitations
1 Operation / cycle
Load/Store overhead
Xtensa LX – Traditional Limitations
1 Operation / cycle
Load/Store overhead
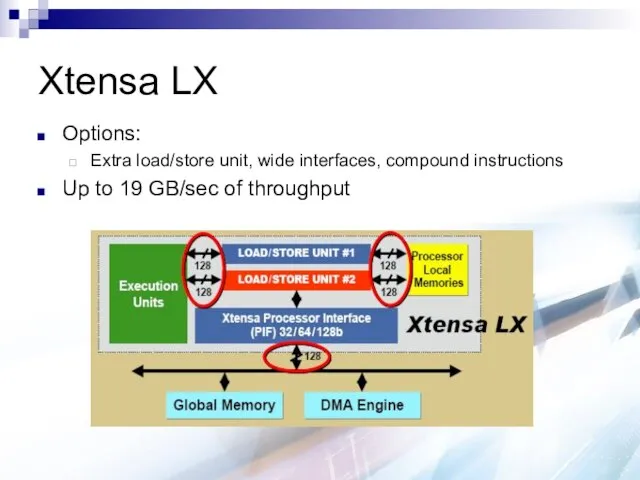
Xtensa LX
Options:
Extra load/store unit, wide interfaces, compound instructions
Up to 19 GB/sec
Xtensa LX
Options:
Extra load/store unit, wide interfaces, compound instructions
Up to 19 GB/sec

Xtensa LX – Highlights
Lower power usage
I/O throughput at RTL speeds
Outstanding computer
Xtensa LX – Highlights
Lower power usage
I/O throughput at RTL speeds
Outstanding computer

Xtensa LX – Lower Power Useage
Automated the insertion of fine-grain clock
Xtensa LX – Lower Power Useage
Automated the insertion of fine-grain clock

Outstanding Computing Performance
Extensible using FLIX
(Flexible Length Instruction Xtensions)
Similar to VLIW
Outstanding Computing Performance
Extensible using FLIX
(Flexible Length Instruction Xtensions)
Similar to VLIW

XPRES Compiler
Powerful synthesis tool
Creates tailored processor descriptions
Run on native C/C++ code
XPRES Compiler
Powerful synthesis tool
Creates tailored processor descriptions
Run on native C/C++ code

Automated Development
Clients log into website
Accessing Process Generator
Builds a model in RTL
Automated Development
Clients log into website
Accessing Process Generator
Builds a model in RTL

Automated Development
Create special instructions described and written in TIE
TIE semantics allow
Automated Development
Create special instructions described and written in TIE
TIE semantics allow

Xtensa LX – Basic Architecture
Processor Configuration
Power Usage: 76 μW/MHz , 47
Xtensa LX – Basic Architecture
Processor Configuration
Power Usage: 76 μW/MHz , 47

Xtensa LX Architecture
32-bit ALU
1 or 2 Load/Store Model
Registers
32-bit general purpose register
Xtensa LX Architecture
32-bit ALU
1 or 2 Load/Store Model
Registers
32-bit general purpose register

Xtensa LX Architecture
General Purpose AR Register File
32 or 64 registers
Instructions have
Xtensa LX Architecture
General Purpose AR Register File
32 or 64 registers
Instructions have
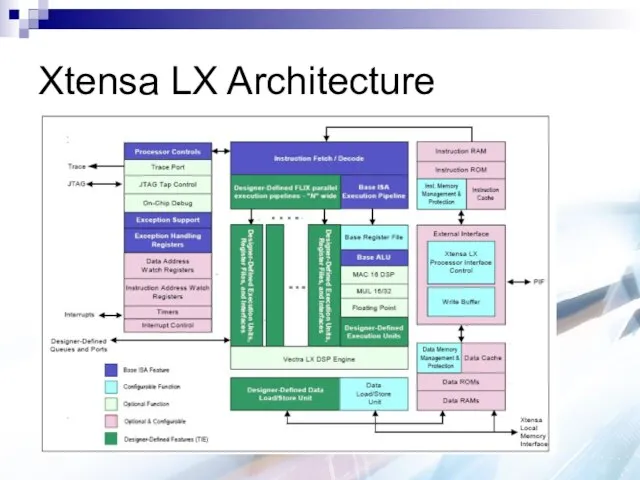
Xtensa LX Architecture
Xtensa LX Architecture

Xtensa LX Pipelining
5 or 7 Stage Pipeline Design
5 stage pipeline has
Xtensa LX Pipelining
5 or 7 Stage Pipeline Design
5 stage pipeline has

Xtensa LX Instruction Set
ISA consists of 80 core instructions including both
Xtensa LX Instruction Set
ISA consists of 80 core instructions including both

Xtensa LX Instruction Set
Processor Control Instructions
RSR, WSR, XSR
Read Special Register, Write
Xtensa LX Instruction Set
Processor Control Instructions
RSR, WSR, XSR
Read Special Register, Write

Xtensa LX ISA – Building Blocks
MUL32
MUL32 adds 32 bit multiplier
MUL16 and
Xtensa LX ISA – Building Blocks
MUL32
MUL32 adds 32 bit multiplier
MUL16 and

Xtensa LX ISA – Building Blocks
Floating Point Unit
32-bit, single precision, floating-point
Xtensa LX ISA – Building Blocks
Floating Point Unit
32-bit, single precision, floating-point

Vectra LX DSP Engine
FLIX-based (why it is 64 bits)
Vectra LX instructions
Vectra LX DSP Engine
FLIX-based (why it is 64 bits)
Vectra LX instructions
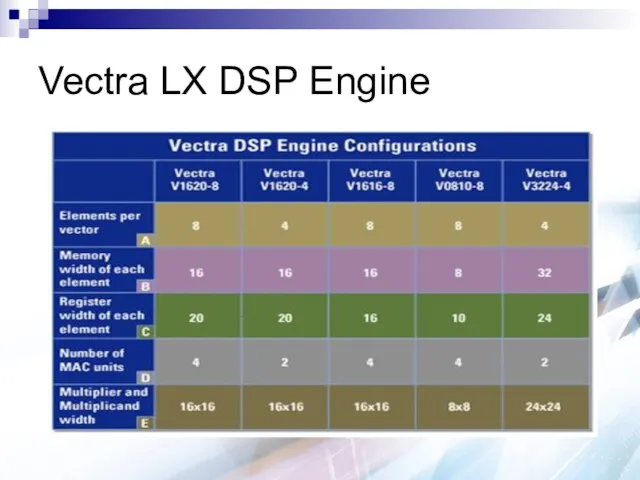
Vectra LX DSP Engine
Vectra LX DSP Engine

Tensilica Instruction Extension
Method used to extend the processor’s architecture and instruction
Tensilica Instruction Extension
Method used to extend the processor’s architecture and instruction

Tensilica Instruction Extension
TIE Compiler
Generates file used to configure software development tools
Tensilica Instruction Extension
TIE Compiler
Generates file used to configure software development tools

TIE
Resembles Verilog
More concise than RTL (it omits all sequential logic, pipeline
TIE
Resembles Verilog
More concise than RTL (it omits all sequential logic, pipeline

TIE Queues and Ports
New way to communicate with external devices
Queues: data
TIE Queues and Ports
New way to communicate with external devices
Queues: data

TIE
TIE Combines multiple operations into one using:
Fusion
SIMD/Vector Transformation
FLIX
TIE
TIE Combines multiple operations into one using:
Fusion
SIMD/Vector Transformation
FLIX

Fusion
Allows you to combine dependent operations into a single instruction
Consider: computing
Fusion
Allows you to combine dependent operations into a single instruction
Consider: computing

Fusion
Fuse the two operations into a single TIE instruction
operation AVERAGE{out AR
Fusion
Fuse the two operations into a single TIE instruction
operation AVERAGE{out AR

SIMD/Vector Transformation
Single Instruction, Multiple Data
Fusing instructions into a “vector”
Allows replication of
SIMD/Vector Transformation
Single Instruction, Multiple Data
Fusing instructions into a “vector”
Allows replication of

SIMD/Vector Transformation
Computing four 16-bit averages
Each data vector must be 64 bits
SIMD/Vector Transformation
Computing four 16-bit averages
Each data vector must be 64 bits

FLIX
Flexible length instruction extension
Key in extreme extensibility
Huge performance gains possible
Code size
FLIX
Flexible length instruction extension
Key in extreme extensibility
Huge performance gains possible
Code size

FLIX
FLIX

FLIX - Usage
Used selectively when parallelism is needed
Avoids code bloat
Used seemlessly
FLIX - Usage
Used selectively when parallelism is needed
Avoids code bloat
Used seemlessly

XPRES Compiler
Powerful synthesis tool
Creates tailored processor descriptions
Run on native C/C++ code
Three
XPRES Compiler
Powerful synthesis tool
Creates tailored processor descriptions
Run on native C/C++ code
Three

XPRES Compiler
Analyzes C/C++ code
Generates possible configurations
Compares performance criteria to silicon size
XPRES Compiler
Analyzes C/C++ code
Generates possible configurations
Compares performance criteria to silicon size

XPRES Compiler - Results
Application dependent
Compute intensive programs
Data intensive programs
More is
XPRES Compiler - Results
Application dependent
Compute intensive programs
Data intensive programs
More is
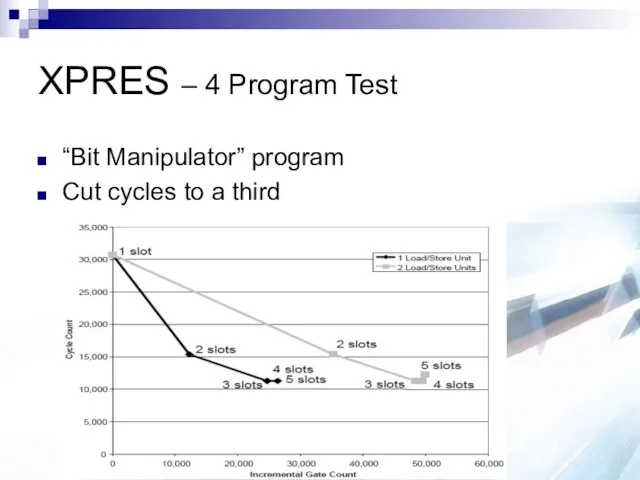
XPRES – 4 Program Test
“Bit Manipulator” program
Cut cycles to a third
XPRES – 4 Program Test
“Bit Manipulator” program
Cut cycles to a third

XPRES – 4 Program Test
H.264 Deblocking Filter
6% performance improvement
XPRES – 4 Program Test
H.264 Deblocking Filter
6% performance improvement
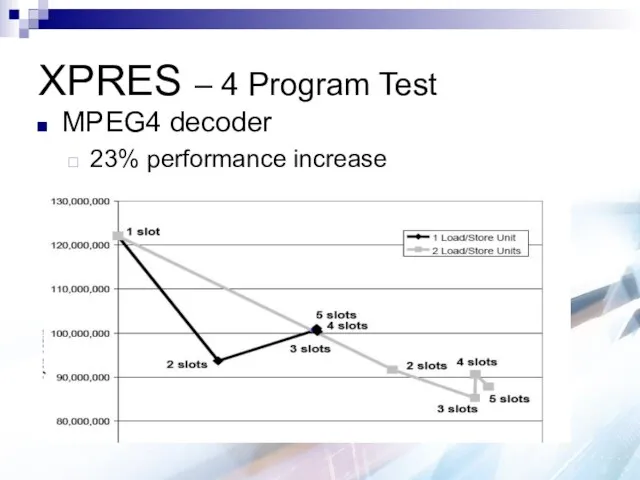
XPRES – 4 Program Test
MPEG4 decoder
23% performance increase
XPRES – 4 Program Test
MPEG4 decoder
23% performance increase
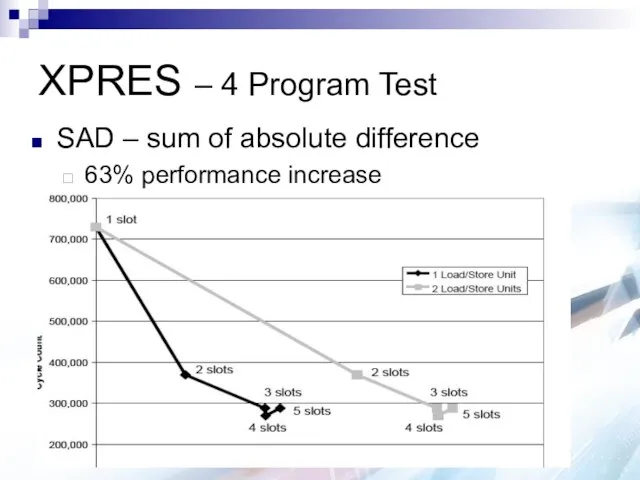
XPRES – 4 Program Test
SAD – sum of absolute difference
63% performance
XPRES – 4 Program Test
SAD – sum of absolute difference
63% performance

Xtensa Hi-Fi 2 Audio Engine
Add-on package for Xtensa LX
Advantages over common
Xtensa Hi-Fi 2 Audio Engine
Add-on package for Xtensa LX
Advantages over common

Xtensa Hi-Fi 2 Audio Engine
Audio packages integrated into an SOC design,
Xtensa Hi-Fi 2 Audio Engine
Audio packages integrated into an SOC design,

Xtensa Hi-Fi 2 Audio Engine
Uses over 300 audio specific DLP instructions.
Xtensa Hi-Fi 2 Audio Engine
Uses over 300 audio specific DLP instructions.

Speed-up Example
GSM Audio Codec – written in C
Profiling code using unaltered
Speed-up Example
GSM Audio Codec – written in C
Profiling code using unaltered

Speed-up Example
Viterbi butterfly instruction
Acts like compression for the data
Consists of 8
Speed-up Example
Viterbi butterfly instruction
Acts like compression for the data
Consists of 8

EEMBC Networking Benchmark
Xtensa LX received highest benchmark ever achieved on the
EEMBC Networking Benchmark
Xtensa LX received highest benchmark ever achieved on the

EEMBC Networking Benchmark
Normalized (per MHz) EEMBC TCPmark
Simulates performance in internet
EEMBC Networking Benchmark
Normalized (per MHz) EEMBC TCPmark
Simulates performance in internet

EEMBC Networking Benchmark
Normalized (by MHz) EEMBC IPmark
Simulates performance in network routers,
EEMBC Networking Benchmark
Normalized (by MHz) EEMBC IPmark
Simulates performance in network routers,
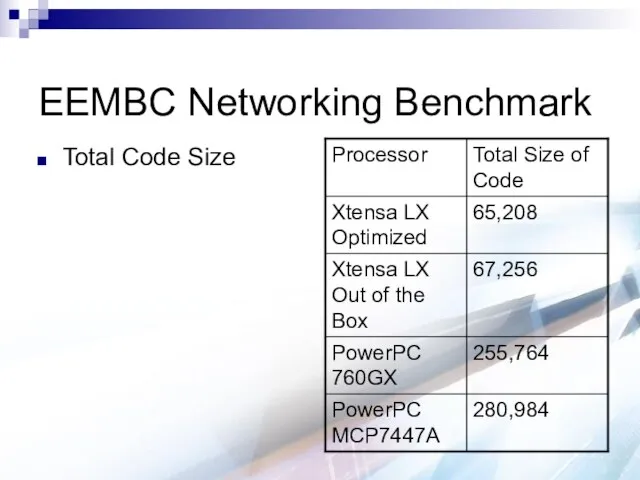
EEMBC Networking Benchmark
Total Code Size
EEMBC Networking Benchmark
Total Code Size

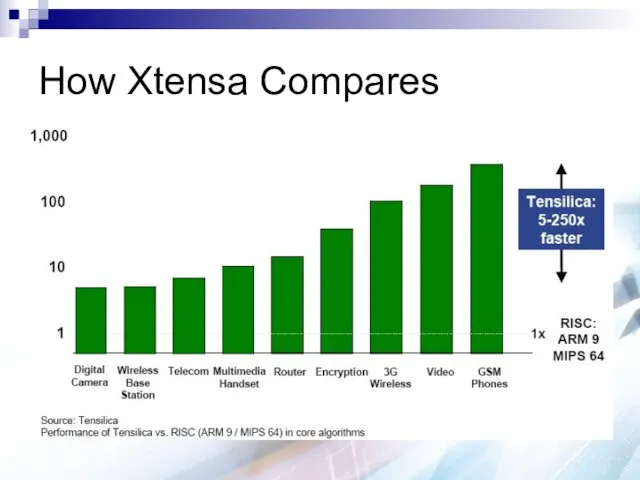
How Xtensa Compares
How Xtensa Compares
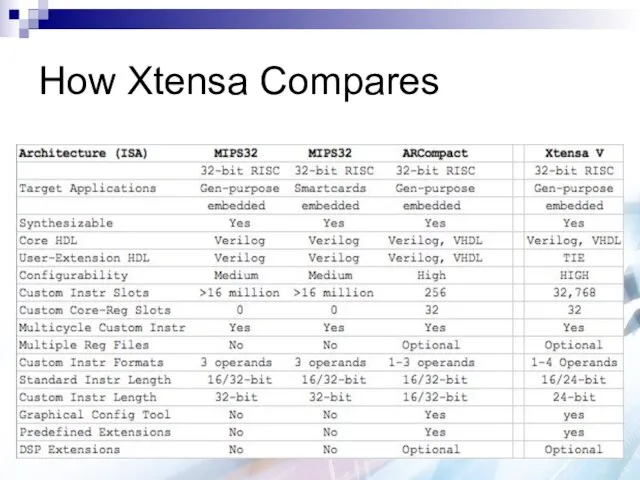
How Xtensa Compares
How Xtensa Compares
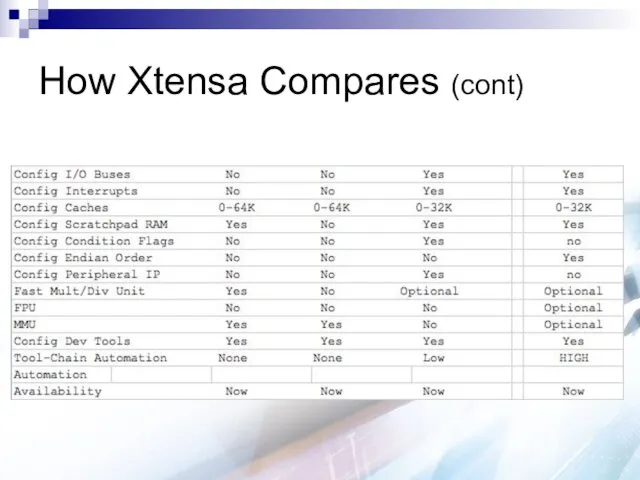
How Xtensa Compares (cont)
How Xtensa Compares (cont)

Uses of Xtensa Products
NVIDIA – Licensed Xtensa LX
“We were very
Uses of Xtensa Products
NVIDIA – Licensed Xtensa LX
“We were very

Uses of Xtensa Products
LG Cell Phone
Phone is digital broadcast enabled
Xtensa processor
Uses of Xtensa Products
LG Cell Phone
Phone is digital broadcast enabled
Xtensa processor

In case you are wondering..
--Tensilica's announced licensees include Agilent, ALPS, AMCC
In case you are wondering..
--Tensilica's announced licensees include Agilent, ALPS, AMCC
 Редактор таблиц GNUmeric
Редактор таблиц GNUmeric Работа в Excel 2007
Работа в Excel 2007 Процесс миграции проектов с системы ECOD1 на ECOD2
Процесс миграции проектов с системы ECOD1 на ECOD2 Концепции BTL-проектов
Концепции BTL-проектов Оcнови роботи в пакеті Scilab
Оcнови роботи в пакеті Scilab Введение в web-технологии. Основы HTML. Создание дизайна сайта
Введение в web-технологии. Основы HTML. Создание дизайна сайта Компьютерные сети
Компьютерные сети Правова природа доменних імен
Правова природа доменних імен Журналист. Профессия
Журналист. Профессия Тестирование программного обеспечения
Тестирование программного обеспечения Документы системы качества
Документы системы качества Как стать любимым тестировщиком у разработчика. Повышение качества взаимодействия программиста и тестировщика
Как стать любимым тестировщиком у разработчика. Повышение качества взаимодействия программиста и тестировщика Анализ защищённости программного обеспечения
Анализ защищённости программного обеспечения Презентация по информатике ИНФОРМАЦИОННЫЕ РЕВОЛЮЦИИ
Презентация по информатике ИНФОРМАЦИОННЫЕ РЕВОЛЮЦИИ  2. Java Basics. Java Statements
2. Java Basics. Java Statements Презентация "Получение новой информации" - скачать презентации по Информатике
Презентация "Получение новой информации" - скачать презентации по Информатике HPE Mobile Center. Мобильное банковское приложение
HPE Mobile Center. Мобильное банковское приложение Типы информационных моделей. Основные этапы разработки и исследования моделей на компьютере
Типы информационных моделей. Основные этапы разработки и исследования моделей на компьютере Объединение компьютеров в локальную сеть. Организация работы пользователей в локальных компьютерных сетях
Объединение компьютеров в локальную сеть. Организация работы пользователей в локальных компьютерных сетях Вы скачали файл… Борисов В.А. Красноармейский филиал ГОУ ВПО «Академия народного хозяйства при Правительстве РФ» Красноармейск 2010 г.
Вы скачали файл… Борисов В.А. Красноармейский филиал ГОУ ВПО «Академия народного хозяйства при Правительстве РФ» Красноармейск 2010 г. Системы счисления
Системы счисления Арифметические и логические операции
Арифметические и логические операции טקסט ועיצוב HTML
טקסט ועיצוב HTML Использование интернет-платформы quezzez.com на уроках английского языка
Использование интернет-платформы quezzez.com на уроках английского языка Компьютерная безопасность
Компьютерная безопасность Информационные технологии Определение информационной технологии Цель информационной технологии Инструментарий Характеристик
Информационные технологии Определение информационной технологии Цель информационной технологии Инструментарий Характеристик Определение метрик. Качество программного продукта
Определение метрик. Качество программного продукта Представление звука в памяти компьютера. Технические средства мультимедиа
Представление звука в памяти компьютера. Технические средства мультимедиа