- Vnitřní řazení v poli (in sito)

Содержание
- 2. K seřazení položek použijeme metodu pří-mého výběru (straight selection). Princip: Ze všech položek vektoru vyber nejmenší
- 3. procedure STRSEL(var POLE:A; N:INDEX); var I,J,K: INDEX; POM: SLOZKA; begin for I:=1 to N-1 do begin
- 4. K seřazení položek použijeme metodu pří-mého vkládání (straight insertion). Princip: V i-tém kroku se zpracovává i-tá
- 5. procedure STRINS(var POLE:A; N:INDEX); var I,J :INDEX; POM :SLOZKA; begin for I:=2 to N do begin
- 6. K seřazení položek vektoru použijeme některou z metod přímé výměny. Metody jsou založeny na principu srovnávání
- 7. procedure BUBBLE(var POLE:A; N:INDEX); var I,J :INDEX; POM :SLOZKA; begin for I:=2 to N do for
- 8. b) u bublinového řazení s výhodou (tzv. Ripple sort) je vzata v úvahu skutečnost, že vektor
- 9. procedure RIPPLE(var POLE:A; N:INDEX); var J,I : INDEX; POM : SLOZKA; SETRIDENO : Boolean; begin I:=1;
- 10. c) Další modifikací je Shaker sort. Princip: V určitém kroku prohlížíme řazený vektor dvakrát. Nejprve např.
- 11. procedure SHAKER(var POLE:A; N:INDEX); var I,J,H,D : INDEX; POM : SLOZKA; begin H := 2; D
- 12. Předchozí 3 metody (Bubble, Ripple a Shaker sort) vycházely z principu, že v každém kroku se
- 13. procedure SHUTT(var POLE:A; N:INDEX); var I :INDEX; POM :INTEGER; begin I:=2; while I if POLE[I] then
- 14. K seřazení většího množství dat se používají duchaplnější metody, z nichž jmenujme alespoň Quick sort, Shell
- 15. procedure QUICK(var POLE:A; N: INDEX); const M = 12; type STRUKTURA = array[1..M] of record H,
- 16. Rekurzivní obdoba předchozího algoritmu: procedure QUICKR(var POLE:A; N: INDEX); procedure SORT(H,D : INDEX); var I, J
- 17. Verzí je možno vytvořit mnoho. Přístup QUICK1 PRESKUP QUICK1 QUICK1 … . . .
- 18. postihuje algoritmus s procedurami PRESKUP a QUICK1 Procedure PRESKUP(DM,HM:byte; var J:byte); var D, H :byte; POM,X
- 19. Algoritmus založený na metodě QUICKsort přináší také následující řešení: Program QUICKSORT000; uses CRT; type COSI=integer; var
- 20. Použití každé z výše uvedených řadících procedur vyžaduje stejné definice a deklarace. Můžeme tedy vytvořit program
- 21. Metoda Shell sort, neboli Shellova metoda řazení (řazení se snižujícím se přírůstkem) . Princip: Rozdělení řazených
- 22. Následující program má stejnou logiku jako poslední výše uvedený program. Za povšimnutí stojí pouze jiná definice
- 23. procedure SHELL(var POLE:A; N: INDEX); type STRUKTURA = array[1..PS] of INDEX; var I, J, R, S
- 24. begin write('Zadej pocet nacitanych hodnot ke trideni: '); readln(POCET); for K:=1 to POCET do begin write('Zadej
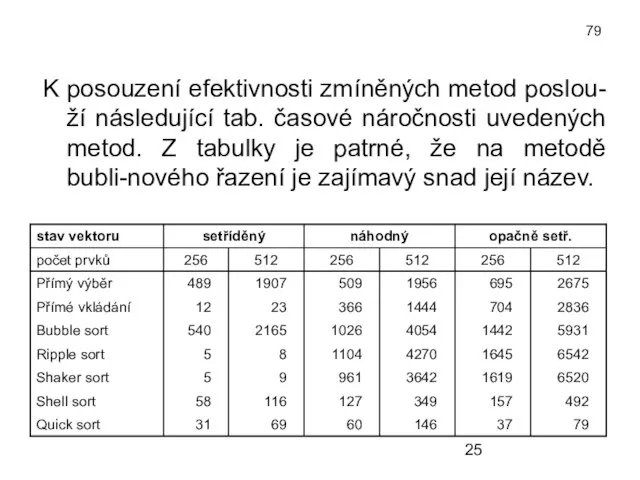
- 25. 79 K posouzení efektivnosti zmíněných metod poslou-ží následující tab. časové náročnosti uvedených metod. Z tabulky je
- 27. Скачать презентацию

K seřazení položek použijeme metodu pří-mého výběru (straight selection).
Princip:
Ze všech
K seřazení položek použijeme metodu pří-mého výběru (straight selection).
Princip:
Ze všech

procedure STRSEL(var POLE:A; N:INDEX);
var I,J,K: INDEX;
POM: SLOZKA;
begin
procedure STRSEL(var POLE:A; N:INDEX);
var I,J,K: INDEX;
POM: SLOZKA;
begin

K seřazení položek použijeme metodu pří-mého vkládání (straight insertion).
Princip:
V i-tém
K seřazení položek použijeme metodu pří-mého vkládání (straight insertion).
Princip:
V i-tém

procedure STRINS(var POLE:A; N:INDEX);
var I,J :INDEX;
POM :SLOZKA;
begin
procedure STRINS(var POLE:A; N:INDEX);
var I,J :INDEX;
POM :SLOZKA;
begin

K seřazení položek vektoru použijeme některou z metod přímé výměny. Metody
K seřazení položek vektoru použijeme některou z metod přímé výměny. Metody

procedure BUBBLE(var POLE:A; N:INDEX);
var I,J :INDEX;
POM :SLOZKA;
begin
procedure BUBBLE(var POLE:A; N:INDEX);
var I,J :INDEX;
POM :SLOZKA;
begin

b) u bublinového řazení s výhodou (tzv. Ripple sort) je vzata
b) u bublinového řazení s výhodou (tzv. Ripple sort) je vzata

procedure RIPPLE(var POLE:A; N:INDEX);
var J,I : INDEX;
POM : SLOZKA;
procedure RIPPLE(var POLE:A; N:INDEX);
var J,I : INDEX;
POM : SLOZKA;

c) Další modifikací je Shaker sort.
Princip:
V určitém kroku prohlížíme
c) Další modifikací je Shaker sort.
Princip:
V určitém kroku prohlížíme

procedure SHAKER(var POLE:A; N:INDEX);
var I,J,H,D : INDEX;
POM : SLOZKA;
procedure SHAKER(var POLE:A; N:INDEX);
var I,J,H,D : INDEX;
POM : SLOZKA;

Předchozí 3 metody (Bubble, Ripple a Shaker sort) vycházely z principu,
Předchozí 3 metody (Bubble, Ripple a Shaker sort) vycházely z principu,

procedure SHUTT(var POLE:A; N:INDEX);
var I :INDEX;
POM :INTEGER;
begin I:=2;
procedure SHUTT(var POLE:A; N:INDEX);
var I :INDEX;
POM :INTEGER;
begin I:=2;

K seřazení většího množství dat se používají duchaplnější metody, z nichž
K seřazení většího množství dat se používají duchaplnější metody, z nichž

procedure QUICK(var POLE:A; N: INDEX);
const M = 12;
type STRUKTURA
procedure QUICK(var POLE:A; N: INDEX);
const M = 12;
type STRUKTURA

Rekurzivní obdoba předchozího algoritmu:
procedure QUICKR(var POLE:A; N: INDEX);
procedure SORT(H,D :
Rekurzivní obdoba předchozího algoritmu:
procedure QUICKR(var POLE:A; N: INDEX);
procedure SORT(H,D :

Verzí je možno vytvořit mnoho. Přístup
QUICK1
PRESKUP
QUICK1
QUICK1
…
.
.
.
Verzí je možno vytvořit mnoho. Přístup
QUICK1
PRESKUP
QUICK1
QUICK1
…
.
.
.

postihuje algoritmus s procedurami PRESKUP a QUICK1
Procedure PRESKUP(DM,HM:byte; var J:byte);
postihuje algoritmus s procedurami PRESKUP a QUICK1
Procedure PRESKUP(DM,HM:byte; var J:byte);

Algoritmus založený na metodě QUICKsort přináší také následující řešení:
Program QUICKSORT000;
uses
Algoritmus založený na metodě QUICKsort přináší také následující řešení:
Program QUICKSORT000;
uses

Použití každé z výše uvedených řadících procedur vyžaduje stejné definice a
Použití každé z výše uvedených řadících procedur vyžaduje stejné definice a

Metoda Shell sort, neboli Shellova metoda řazení (řazení se snižujícím se
Metoda Shell sort, neboli Shellova metoda řazení (řazení se snižujícím se

Následující program má stejnou logiku jako poslední výše uvedený program. Za
Následující program má stejnou logiku jako poslední výše uvedený program. Za
![procedure SHELL(var POLE:A; N: INDEX); type STRUKTURA = array[1..PS] of INDEX;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/596451/slide-22.jpg)
procedure SHELL(var POLE:A; N: INDEX);
type STRUKTURA = array[1..PS] of
procedure SHELL(var POLE:A; N: INDEX);
type STRUKTURA = array[1..PS] of

begin
write('Zadej pocet nacitanych hodnot ke trideni: ');
readln(POCET);
begin
write('Zadej pocet nacitanych hodnot ke trideni: ');
readln(POCET);
79
K posouzení efektivnosti zmíněných metod poslou-ží následující tab. časové náročnosti uvedených
79
K posouzení efektivnosti zmíněných metod poslou-ží následující tab. časové náročnosti uvedených
 Разработка робота на основе платформы Аrduino в качестве учебного пособия для МДК 02.03 Мехатроника и робототехника
Разработка робота на основе платформы Аrduino в качестве учебного пособия для МДК 02.03 Мехатроника и робототехника Действия с информацией. Хранение информации 5 класс Учитель информатики Елена Геннадьевна Лопатина
Действия с информацией. Хранение информации 5 класс Учитель информатики Елена Геннадьевна Лопатина Компьютер изнутри
Компьютер изнутри Безопасность детей в сети интернет. Родители и дети-вместе в интернете
Безопасность детей в сети интернет. Родители и дети-вместе в интернете Условная функция и логические выражения в табличном процессоре Excel
Условная функция и логические выражения в табличном процессоре Excel Әлеуметтік желілердің қазіргі жастардың дүниетанымына
Әлеуметтік желілердің қазіргі жастардың дүниетанымына Информационные системы и технологии в экономике. Тема 4. Структура ЭИС
Информационные системы и технологии в экономике. Тема 4. Структура ЭИС Интернет как средство связи. Влияние интернета на речь
Интернет как средство связи. Влияние интернета на речь С++ // язык программирования
С++ // язык программирования Относительная сложность. Колмогоровский подход
Относительная сложность. Колмогоровский подход Фундаментальная информатика и информационные технологии
Фундаментальная информатика и информационные технологии Двоичное представление информации в компьютере. Представление чисел в компьютере
Двоичное представление информации в компьютере. Представление чисел в компьютере Основные понятия и определения. Классификация архитектур информационных систем
Основные понятия и определения. Классификация архитектур информационных систем Программа для обучения. Наша команда Liga
Программа для обучения. Наша команда Liga Познавая Сурский край
Познавая Сурский край Что такое OpenGL?
Что такое OpenGL? Project report Активиа 14 дней
Project report Активиа 14 дней Базовые типы данных и ввод-вывод. Лабораторная работа №1
Базовые типы данных и ввод-вывод. Лабораторная работа №1 Принципы построения сетей документальной электросвязи
Принципы построения сетей документальной электросвязи Раздел 7 Линейный анализ устойчивости
Раздел 7 Линейный анализ устойчивости  Цифровые вычислительные устройства и микропроцессоры приборных комплексов
Цифровые вычислительные устройства и микропроцессоры приборных комплексов Кодирование чисел. Системы счисления
Кодирование чисел. Системы счисления Что такое современные медиа. И почему они гораздо больше, чем СМИ
Что такое современные медиа. И почему они гораздо больше, чем СМИ Обработка lightroom. Задание
Обработка lightroom. Задание К/р №4 ИНФО-9 по теме «Редакторы, таблицы, базы данных» 4
К/р №4 ИНФО-9 по теме «Редакторы, таблицы, базы данных» 4 Презентация "Поколения ЭВМ" - скачать презентации по Информатике
Презентация "Поколения ЭВМ" - скачать презентации по Информатике УИС «Моё дело»
УИС «Моё дело» Информация и информатика
Информация и информатика