- Основные понятия математической статистики. (Лекция 3)

Содержание
- 2. Основные понятия математической статистики. Математическая статистика – это раздел математики о методах регистрации, систематизации и анализа
- 3. Генеральная совокупность – это совокупность всех объектов, которые имеют типичную характеристику или признак. Это все возможные
- 4. Основные задачи, которые стоят перед математической статистикой: 1. Определение закона распределения случайной величины по имеющимся статистическим
- 5. Схема предварительной обработки экспериментальных данных. 1). Сбор экспериментальных данных. Чтобы определить закон распределения случайной величины, нужно
- 6. Пример: При измерении частоты пульса у 10 пациентов получены следующие результаты: 90, 110, 65, 80, 90,
- 7. Схема предварительной обработки экспериментальных данных. 2).Составление вариационного ряда. Вариационный ряд (статистическое распределение) -- это двойной ряд
- 8. Для нашего примера вариационный ряд имеет вид: Очевидно, что , где к – количество различных значений(к=6).
- 9. Если признак изменяется непрерывно, то составляется интервальный вариационный ряд: В первой строке указываются интервалы изменения признака,
- 10. Пример.
- 11. Если признак изменяется непрерывно, то составляется интервальный вариационный ряд: В первой строке указываются интервалы изменения признака,
- 12. 2. Статистические характеристики совокупности. Математическое ожидание M[X],дисперсия D[X],среднее квадратическое отклонение σ[X] -- это числовые характеристики (параметры),
- 13. 3. Ошибка среднего арифметического. Извлечём из генеральной совокупности N выборок, тогда их средние арифметические сами будут
- 14. 4. Доверительный интервал и доверительная вероятность. Истинные значения М[X] и D[X] можно найти по генеральной совокупности,
- 15. Основная масса случайных величин в биологии и медицине распределена по нормальному закону распределения, следовательно, задав доверительную
- 16. 5. Распределение Стьюдента. Нормированная случайная величина вычисляется по формуле: Плотность вероятности случайной величины: Где Вn --
- 18. Скачать презентацию

Основные понятия математической статистики.
Математическая статистика – это раздел математики о методах
Основные понятия математической статистики.
Математическая статистика – это раздел математики о методах

Генеральная совокупность – это совокупность всех объектов, которые имеют типичную характеристику
Генеральная совокупность – это совокупность всех объектов, которые имеют типичную характеристику

Основные задачи, которые стоят перед математической статистикой:
1. Определение закона распределения случайной
Основные задачи, которые стоят перед математической статистикой:
1. Определение закона распределения случайной

Схема предварительной обработки экспериментальных данных.
1). Сбор экспериментальных данных.
Чтобы определить закон распределения
Схема предварительной обработки экспериментальных данных.
1). Сбор экспериментальных данных.
Чтобы определить закон распределения

Пример:
При измерении частоты пульса у 10 пациентов получены следующие результаты: 90,
Пример:
При измерении частоты пульса у 10 пациентов получены следующие результаты: 90,

Схема предварительной обработки экспериментальных данных.
2).Составление вариационного ряда.
Вариационный ряд (статистическое распределение) --
Схема предварительной обработки экспериментальных данных.
2).Составление вариационного ряда.
Вариационный ряд (статистическое распределение) --
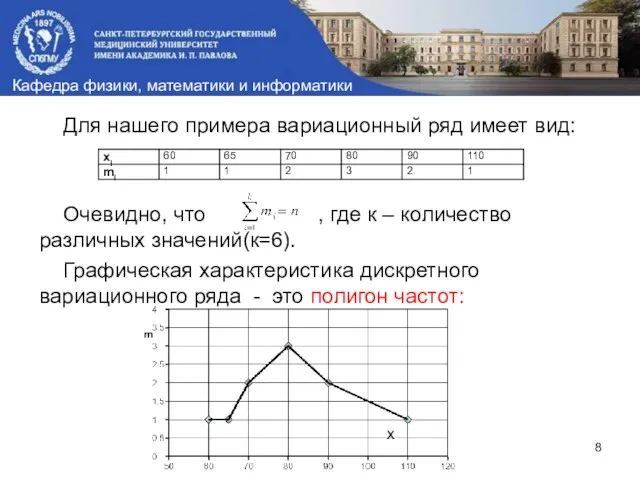
Для нашего примера вариационный ряд имеет вид:
Очевидно, что , где к
Для нашего примера вариационный ряд имеет вид:
Очевидно, что , где к

Если признак изменяется непрерывно, то составляется интервальный вариационный ряд:
В первой строке
Если признак изменяется непрерывно, то составляется интервальный вариационный ряд:
В первой строке

Пример.
Пример.
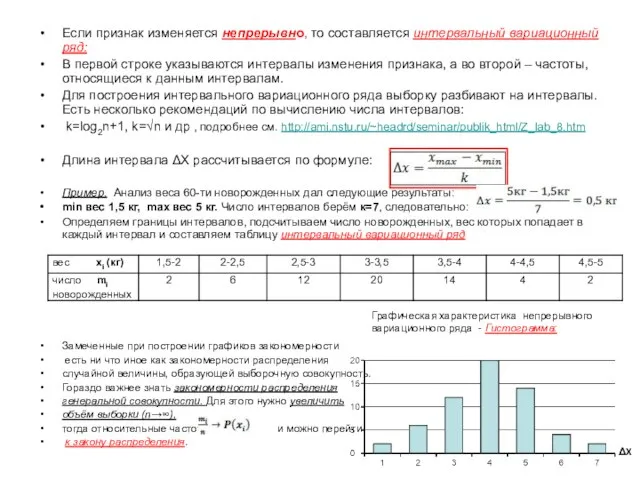
Если признак изменяется непрерывно, то составляется интервальный вариационный ряд:
В первой строке
Если признак изменяется непрерывно, то составляется интервальный вариационный ряд:
В первой строке
![2. Статистические характеристики совокупности. Математическое ожидание M[X],дисперсия D[X],среднее квадратическое отклонение σ[X]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/546449/slide-11.jpg)
2. Статистические характеристики совокупности.
Математическое ожидание M[X],дисперсия D[X],среднее квадратическое отклонение σ[X] --
2. Статистические характеристики совокупности.
Математическое ожидание M[X],дисперсия D[X],среднее квадратическое отклонение σ[X] --

3. Ошибка среднего арифметического.
Извлечём из генеральной совокупности N выборок, тогда
3. Ошибка среднего арифметического.
Извлечём из генеральной совокупности N выборок, тогда
![4. Доверительный интервал и доверительная вероятность. Истинные значения М[X] и D[X]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/546449/slide-13.jpg)
4. Доверительный интервал и доверительная вероятность.
Истинные значения М[X] и D[X] можно
4. Доверительный интервал и доверительная вероятность.
Истинные значения М[X] и D[X] можно

Основная масса случайных величин в биологии и медицине распределена по нормальному
Основная масса случайных величин в биологии и медицине распределена по нормальному

5. Распределение Стьюдента.
Нормированная случайная величина вычисляется по формуле:
Плотность вероятности случайной величины:
5. Распределение Стьюдента.
Нормированная случайная величина вычисляется по формуле:
Плотность вероятности случайной величины:
 Теорема невесты
Теорема невесты Параллельные прямые, признаки параллельности прямых, свойства углов при параллельных прямых
Параллельные прямые, признаки параллельности прямых, свойства углов при параллельных прямых Математические кроссворды
Математические кроссворды Проект по геометрии на тему: Формулы площадей треугольников
Проект по геометрии на тему: Формулы площадей треугольников Лекция № 12 Быстрое преобразование Фурье Нахождение спектральных составляющих дискретного комплексного сигнала непосредственн
Лекция № 12 Быстрое преобразование Фурье Нахождение спектральных составляющих дискретного комплексного сигнала непосредственн Решение уравнений (5 класс)
Решение уравнений (5 класс) Графическое решение квадратных уравнений
Графическое решение квадратных уравнений Числовые ряды
Числовые ряды Теория графов
Теория графов Умножение и деление дробей 6 класс
Умножение и деление дробей 6 класс  Обзор методов оценки профессиональных рисков
Обзор методов оценки профессиональных рисков Координаты. Координатная плоскость
Координаты. Координатная плоскость Парная регрессия и корреляция
Парная регрессия и корреляция Региональный компонент на уроках математики в начальных классах. Мелеузовский район
Региональный компонент на уроках математики в начальных классах. Мелеузовский район Синтез оптимальных дискретных детерминированных систем. Нахождение оптимального программного управления (лекция 3)
Синтез оптимальных дискретных детерминированных систем. Нахождение оптимального программного управления (лекция 3) Математическая игра «Морской бой»
Математическая игра «Морской бой» Теорема Безу. Схема Горнера. 10 класс
Теорема Безу. Схема Горнера. 10 класс Кубик Рубика - гимнастика ума. Исследовательская работа
Кубик Рубика - гимнастика ума. Исследовательская работа Уравнение. Решение задач с помощью уравнений
Уравнение. Решение задач с помощью уравнений Рене Декарт и его открытия
Рене Декарт и его открытия Методика изучения времени
Методика изучения времени Многранники в нашей жизни
Многранники в нашей жизни Решение прикладных задач
Решение прикладных задач Действия с геометрическими фигурами, координатами и векторами
Действия с геометрическими фигурами, координатами и векторами Решение логарифмических уравнений и неравенств
Решение логарифмических уравнений и неравенств Деление десятичных дробей на натуральное число
Деление десятичных дробей на натуральное число Математическое моделирование. (Лекция 3)
Математическое моделирование. (Лекция 3) Приведенные квадратные уравнения
Приведенные квадратные уравнения