- Алгоритмы обучения без учителя

Содержание
- 2. Алгоритм MAXMIN Рассмотрим алгоритм, более эффективный по сравнению с предыдущим и являющийся улучшением порогового алгоритма. Исходными
- 3. Алгоритм MAXMIN На первом этапе алгоритма все объекты разделяются по классам на основе критерия минимального расстояния
- 4. В этом алгоритме пороговое расстояние не является фиксированным, а определяется на основе среднего расстояния между всеми
- 5. Алгоритм Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки). Количество классов К положить равным
- 6. Алгоритм
- 7. Алгоритм
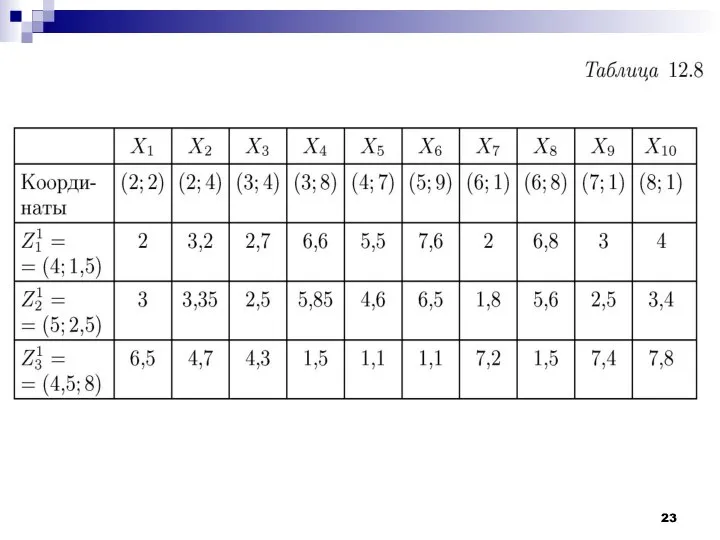
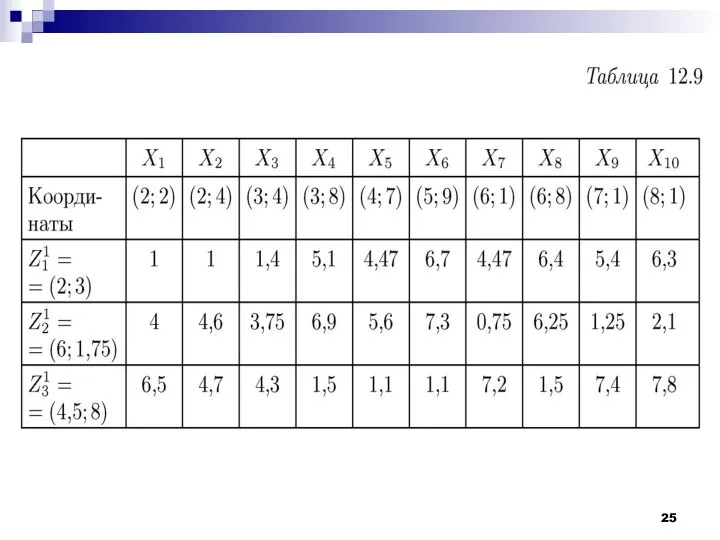
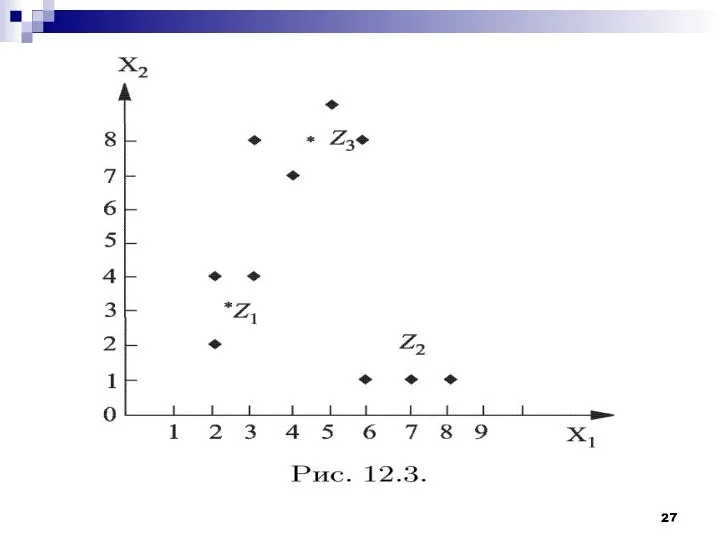
- 8. Рассмотрим работу алгоритма MAXMIN на примере. Как и в предыдущем случае выберем объекты, которые заданы двумя
- 28. Проблемы алгоритма K-средних: необходимо заранее знать количество кластеров. алгоритм очень чувствителен к выбору начальных центров кластеров.
- 31. Нечеткий алгоритм кластеризации с-means С последней проблемой k-means успешно справляется алгоритм с-means. Вместо однозначного ответа на
- 33. Алгоритм ISODATA (Iterative Self-Organizing Data Analysis Techniques) основывается на алгоритме k средних, но включает набор оказавшихся
- 34. Это число выступает в качестве рекомендации: в результате работы алгоритма может быть построено как меньшее, так
- 35. Ликвидируются кластеры, в состав которых входит менее чем заданное число элементов. Для каждого текущего кластера определяется
- 36. Решение о расщеплении принимается с учетом размера кластера в направлении вытянутости (этот размер может сравниваться с
- 38. Использующиеся в алгоритме ISODATA эвристики помогают не только подбирать более подходящее число классов, но и находить
- 56. Задача минимизации количества решающих функций, достаточных для классификации образов, может быть очень важна, особенно если количество
- 59. Прямого ответа на этот вопрос можно избежать, если конструировать методы распознавания на основе неких эвристических соображений.
- 60. Эти эталонные объекты являются наиболее типичными представителями класса. Типичность эталонного объекта означает, что он в среднем
- 62. Классы, однако, могут обладать разными свойствами. Простейшим свойством является характерный размер класса, который может быть оценен
- 65. В соответствии с данным решающим правилом просматривается вся обучающая выборка, в ней находится образ, расположенный наиболее
- 66. Метод ближайшего соседа весьма чувствителен к выбросам, то есть тем образам обучающей выборки, для которых указаны
- 86. Скачать презентацию

Алгоритм MAXMIN
Рассмотрим алгоритм, более эффективный по сравнению с предыдущим и являющийся
Алгоритм MAXMIN
Рассмотрим алгоритм, более эффективный по сравнению с предыдущим и являющийся

Алгоритм MAXMIN
На первом этапе алгоритма все объекты разделяются по классам на
Алгоритм MAXMIN
На первом этапе алгоритма все объекты разделяются по классам на

В этом алгоритме пороговое расстояние не является фиксированным, а определяется на
В этом алгоритме пороговое расстояние не является фиксированным, а определяется на

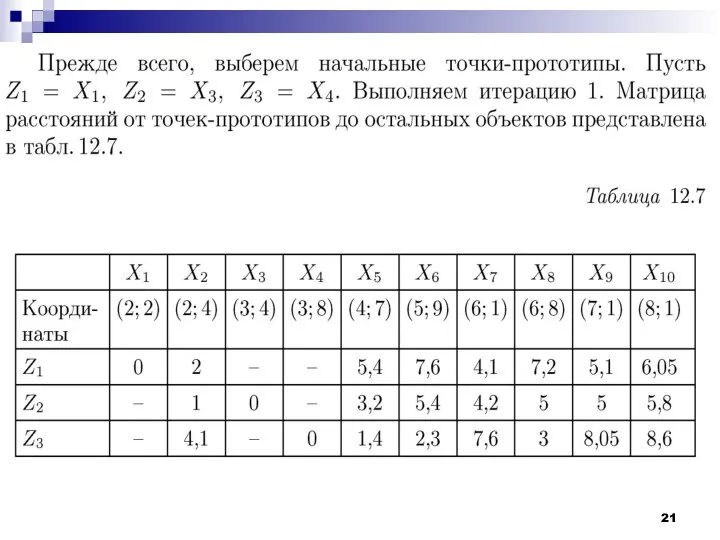
Алгоритм
Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки). Количество
Алгоритм
Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки). Количество

Алгоритм
Алгоритм

Алгоритм
Алгоритм
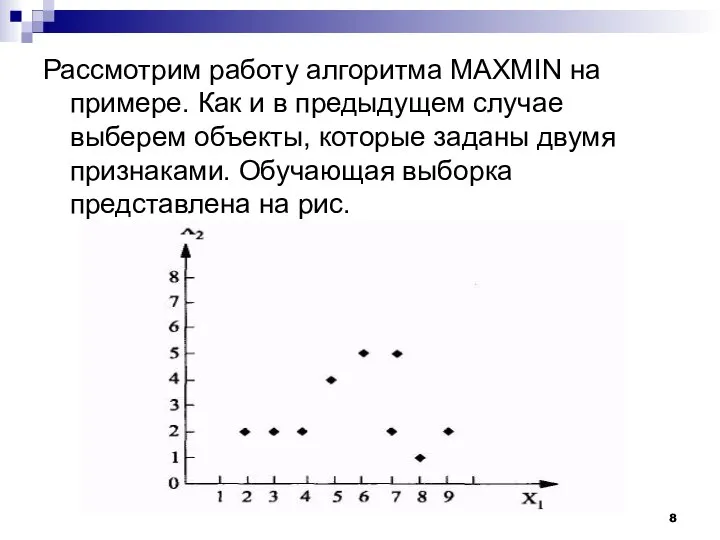
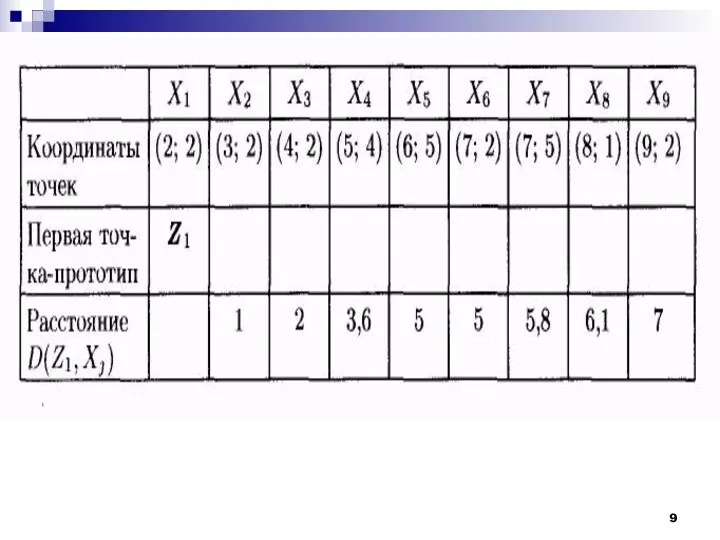
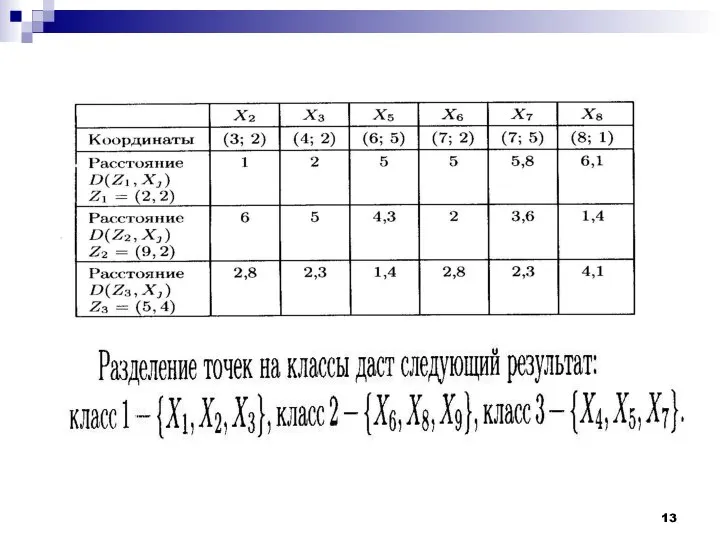
Рассмотрим работу алгоритма MAXMIN на примере. Как и в предыдущем случае
Рассмотрим работу алгоритма MAXMIN на примере. Как и в предыдущем случае














Проблемы алгоритма K-средних:
необходимо заранее знать количество кластеров.
алгоритм очень чувствителен к
Проблемы алгоритма K-средних:
необходимо заранее знать количество кластеров.
алгоритм очень чувствителен к



Нечеткий алгоритм кластеризации с-means
С последней проблемой k-means успешно справляется алгоритм
Нечеткий алгоритм кластеризации с-means
С последней проблемой k-means успешно справляется алгоритм
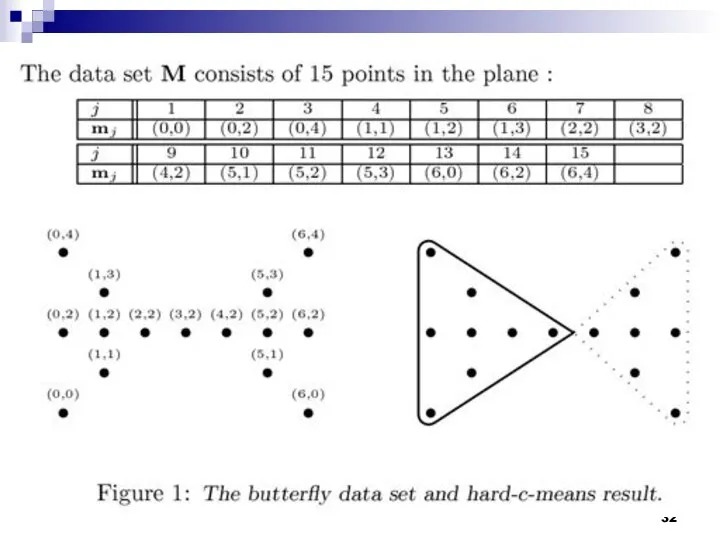

Алгоритм ISODATA (Iterative Self-Organizing Data Analysis Techniques) основывается на алгоритме k
Алгоритм ISODATA (Iterative Self-Organizing Data Analysis Techniques) основывается на алгоритме k

Это число выступает в качестве рекомендации: в результате работы алгоритма может
Это число выступает в качестве рекомендации: в результате работы алгоритма может

Ликвидируются кластеры, в состав которых входит менее чем заданное число элементов.
Для
Ликвидируются кластеры, в состав которых входит менее чем заданное число элементов.
Для

Решение о расщеплении принимается с учетом размера кластера в направлении вытянутости
Решение о расщеплении принимается с учетом размера кластера в направлении вытянутости
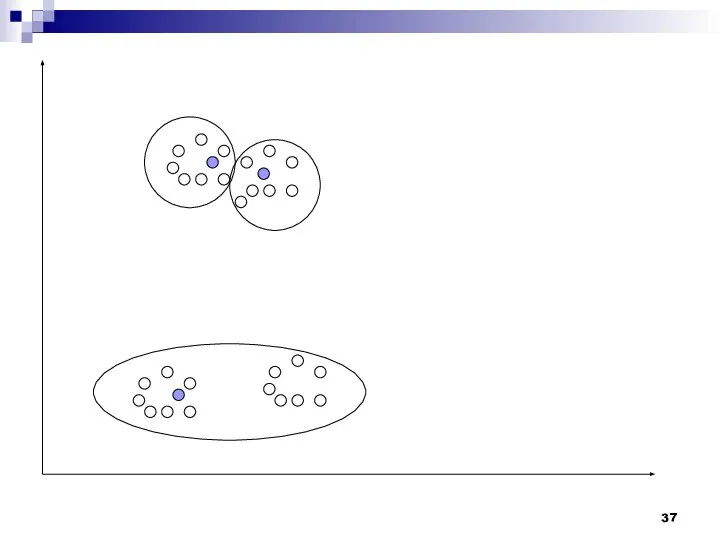

Использующиеся в алгоритме ISODATA эвристики помогают не только подбирать более подходящее
Использующиеся в алгоритме ISODATA эвристики помогают не только подбирать более подходящее




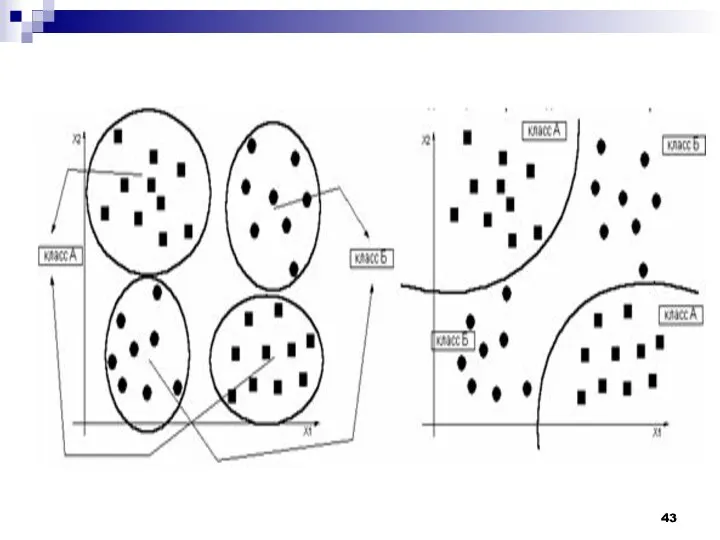








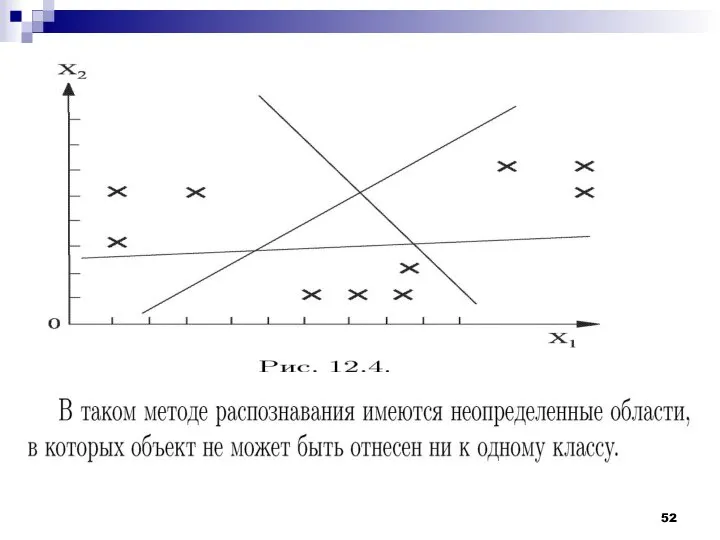
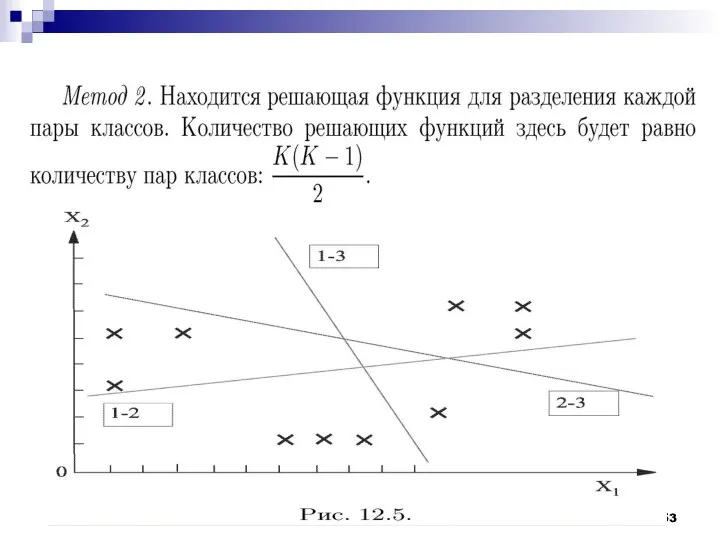

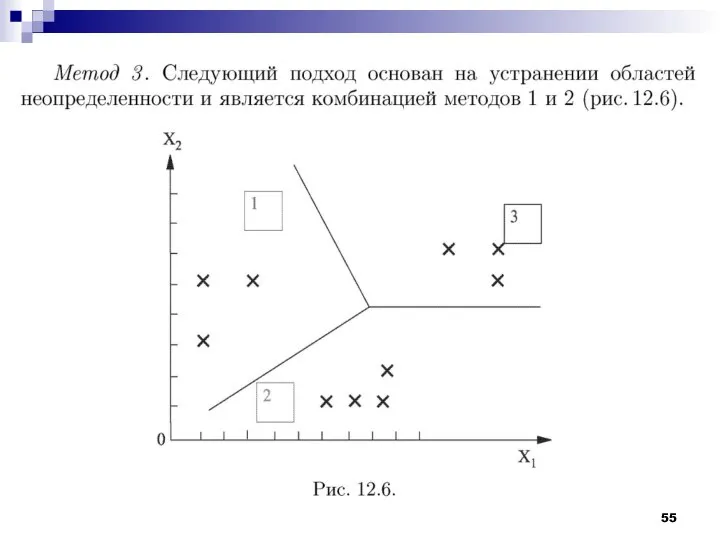

Задача минимизации количества решающих функций, достаточных для классификации образов, может быть
Задача минимизации количества решающих функций, достаточных для классификации образов, может быть



Прямого ответа на этот вопрос можно избежать, если конструировать методы распознавания
Прямого ответа на этот вопрос можно избежать, если конструировать методы распознавания

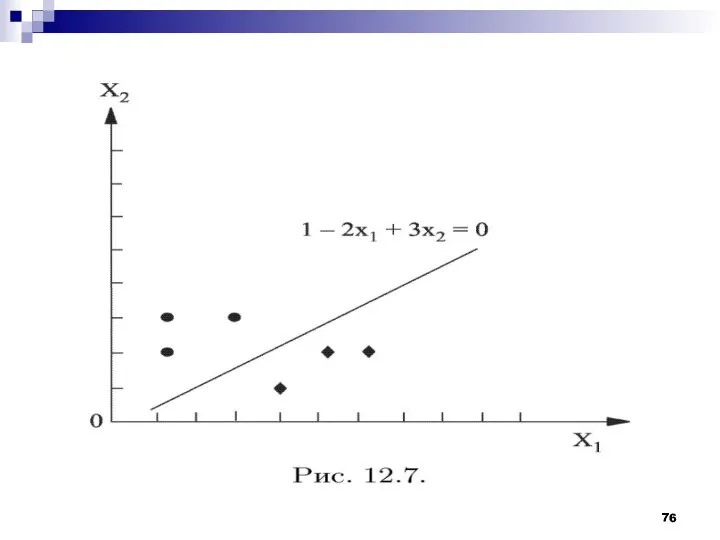
Эти эталонные объекты являются наиболее типичными представителями класса. Типичность эталонного объекта
Эти эталонные объекты являются наиболее типичными представителями класса. Типичность эталонного объекта

Классы, однако, могут обладать разными свойствами. Простейшим свойством является характерный размер
Классы, однако, могут обладать разными свойствами. Простейшим свойством является характерный размер



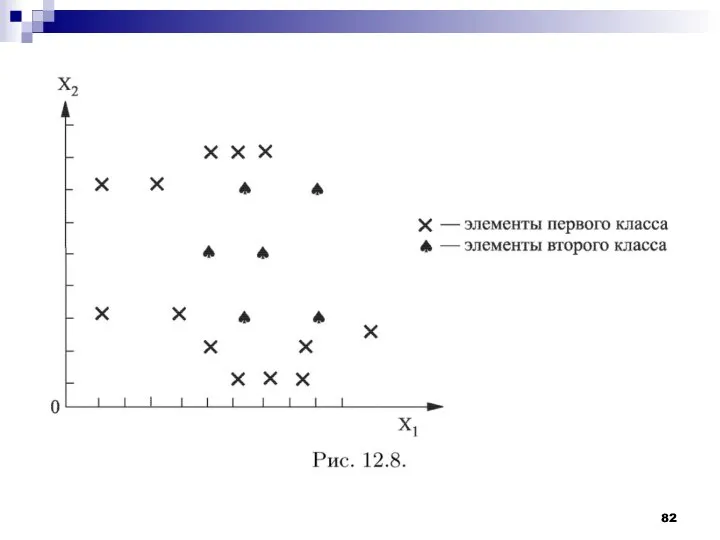
В соответствии с данным решающим правилом просматривается вся обучающая выборка, в
В соответствии с данным решающим правилом просматривается вся обучающая выборка, в

Метод ближайшего соседа весьма чувствителен к выбросам, то есть тем образам
Метод ближайшего соседа весьма чувствителен к выбросам, то есть тем образам
















 Япония
Япония Задание поверхностей на комплексном чертеже. Развертывающиеся линейчатые поверхности. Поверхности с плоскостью параллелизма
Задание поверхностей на комплексном чертеже. Развертывающиеся линейчатые поверхности. Поверхности с плоскостью параллелизма Фактори економічного зростання
Фактори економічного зростання Формула стоимости. 3-й класс - презентация для начальной школы
Формула стоимости. 3-й класс - презентация для начальной школы ELIKA и ELIKA PRO профессиональные антенны
ELIKA и ELIKA PRO профессиональные антенны Система горячего водоснабжения. Система холодного водоснабжения
Система горячего водоснабжения. Система холодного водоснабжения Материнская плата
Материнская плата МОНОПОЛИЯ И РЫНОЧНАЯ ВЛАСТЬ В УСЛОВИЯХ НЕСОВЕРШЕННОЙ КОНКУРЕНЦИИ
МОНОПОЛИЯ И РЫНОЧНАЯ ВЛАСТЬ В УСЛОВИЯХ НЕСОВЕРШЕННОЙ КОНКУРЕНЦИИ ИМИДЖ ОРГАНИЗАЦИИ
ИМИДЖ ОРГАНИЗАЦИИ Жалаң сөз және оның морфологиялық құрылымы
Жалаң сөз және оның морфологиялық құрылымы Звіт про роботу в конкурсах - презентация для начальной школы_
Звіт про роботу в конкурсах - презентация для начальной школы_ Виды корпусов и блоков питания системного блока ПК
Виды корпусов и блоков питания системного блока ПК Теократия, гражданская и духовная власть в одном лице
Теократия, гражданская и духовная власть в одном лице Умей сказать «НЕТ!» ПАНАЧЁВА И.Е. МОУ УЙСКО-ЧЕБАРКУЛЬСКАЯ СОШ
Умей сказать «НЕТ!» ПАНАЧЁВА И.Е. МОУ УЙСКО-ЧЕБАРКУЛЬСКАЯ СОШ  Анализ затрат на лекарственные средства с помощью ABC/VEV методологии
Анализ затрат на лекарственные средства с помощью ABC/VEV методологии  Массивы. Объявление
Массивы. Объявление Физическое воспитание детей среднего школьного возраста
Физическое воспитание детей среднего школьного возраста Мастер - класс « Рисование контурами»
Мастер - класс « Рисование контурами»  Конструирование и программирование роботов на базе конструкторов Lego WeDo и Lego Mindstorms
Конструирование и программирование роботов на базе конструкторов Lego WeDo и Lego Mindstorms Билік құрылмындағы партиялар ролі
Билік құрылмындағы партиялар ролі Проектирование устройства программирования и настройки коротковолновой радиостанции «VERTEX VX-1210»
Проектирование устройства программирования и настройки коротковолновой радиостанции «VERTEX VX-1210» Жалпыреспубликалық Бірыңғай «Адалдық Сағаты»
Жалпыреспубликалық Бірыңғай «Адалдық Сағаты» Травматология
Травматология ТЕЛЕСКОПИ
ТЕЛЕСКОПИ ХУДОЖНИКИ 18 ВЕКА
ХУДОЖНИКИ 18 ВЕКА Петергоф. Дворцы
Петергоф. Дворцы Интернет-ресурсы по культуре
Интернет-ресурсы по культуре Русский портрет XVIII века Материалы к уроку МХК в 11 классе
Русский портрет XVIII века Материалы к уроку МХК в 11 классе