- Способы представления исходной информации в интеллектуальных системах

Содержание
- 2. Человек, решающий задачу выбора целесообразного поведения в той или иной ситуации, прежде всего анализирует существенные и
- 3. Оценка входной ситуации человеком происходит на основе совокупности сигналов, поступающих от его органов чувств. На основании
- 4. Вычислительная машина, на которой моделируется аналогичный процесс, должна обладать возможностью получать описание входной ситуации от внешних
- 5. Для того, чтобы эффективно оценить, относятся ли различные ситуации к одному классу, интеллектуальная система должна иметь
- 6. Обучение на основе примеров является типичным случаем индуктивного обучения и широко используется в интеллектуальных системах. На
- 7. Источником примеров, на которых осуществляется обучение, может быть учитель то есть лицо, которое заранее знает концепцию
- 8. Источником примеров для обучения может быть внешняя среда, с которой взаимодействует интеллектуальная система. В этом случае
- 9. Наконец, источником примеров для обучения может стать сама интеллектуальная система. Например, в случае взаимодействия интеллектуального робота
- 10. Для системы машинного обучения принципиально важным является вопрос, что поступает на вход системы, в каком виде
- 11. Значения, которые могут принимать признаки объекта, относятся к трем основным типам: количественные или числовые, качественные и
- 12. В случае, если признаки могут иметь качественный характер, но при этом их значения можно упорядочить друг
- 13. Третий случай заключается в том, что значения признаков имеют чисто качественный характер, связать эти значения между
- 16. Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году, включает в себя более 100 различных
- 17. Рассмотрим пример процедуры кластерного анализа. Допустим, мы имеем набор данных А, состоящий из 14-ти примеров, у
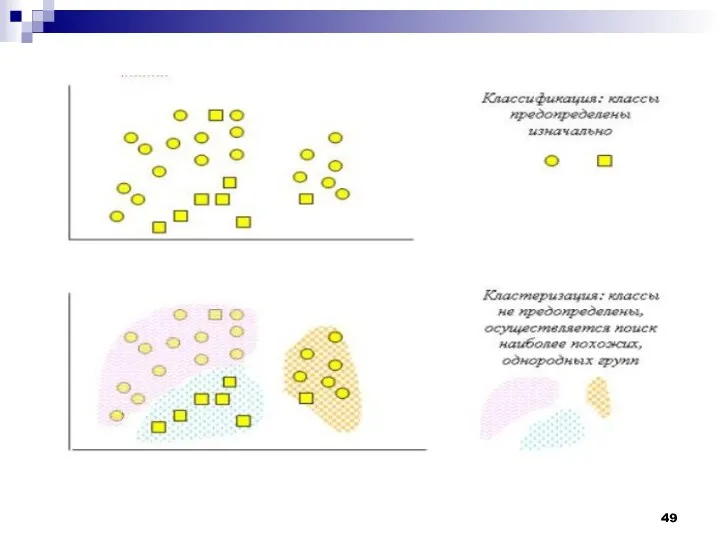
- 19. Данные в табличной форме не носят информативный характер. Представим переменные X и Y в виде диаграммы
- 20. На рисунке мы видим несколько групп "похожих" примеров. Примеры (объекты), которые по значениям X и Y
- 21. Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i и j на плоскости, когда
- 22. Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i и j на плоскости, когда
- 23. Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера. Центр кластера - это среднее
- 24. Спорный объект - это объект, который по мере сходства может быть отнесен к нескольким кластерам. Размер
- 26. Работа кластерного анализа опирается на два предположения. Первое предположение - рассматриваемые признаки объекта в принципе допускают
- 27. Рассмотрим пример. Представим себе, что данные признака х в наборе данных А на два порядка больше
- 28. Эта проблема решается при помощи предварительной стандартизации переменных. Стандартизация (standardization) или нормирование (normalization) приводит значения всех
- 29. Наряду со стандартизацией переменных, существует вариант придания каждой из них определенного коэффициента важности, или веса, который
- 30. Методы кластерного анализа можно разделить на две группы: иерархические; неиерархические. Суть иерархической кластеризации состоит в последовательном
- 31. Иерархические агломеративные методы (Agglomerative Nesting, AGNES) Эта группа методов характеризуется последовательным объединением исходных элементов и соответствующим
- 32. Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA) Эти методы являются логической противоположностью агломеративным методам. В начале
- 34. Программная реализация алгоритмов кластерного анализа широко представлена в различных инструментах Data Mining, которые позволяют решать задачи
- 35. Иерархические алгоритмы связаны с построением дендрограмм (от греческого dendron - "дерево"), которые являются результатом иерархического кластерного
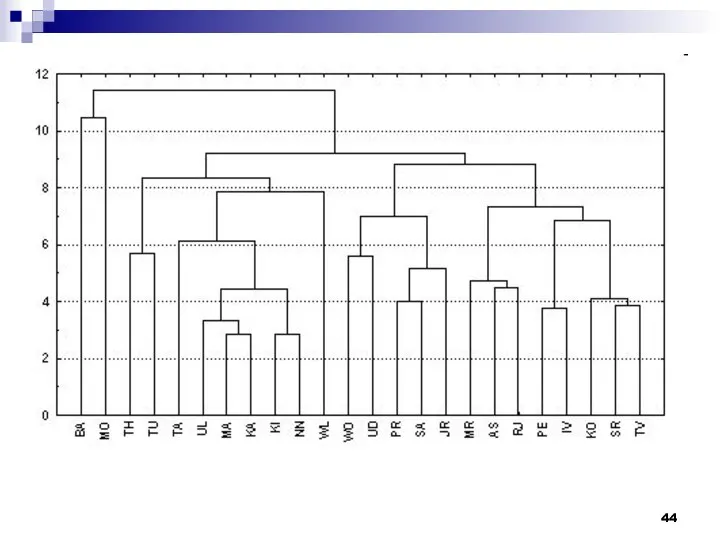
- 36. Существует много способов построения дендрограмм. В дендрограмме объекты могут располагаться вертикально или горизонтально. Пример вертикальной дендрограммы
- 37. Числа 11, 10, 3 и т.д. соответствуют номерам объектов или наблюдений исходной выборки. Мы видим, что
- 38. Методы объединения или связи Когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются
- 39. Метод ближнего соседа или одиночная связь. Здесь расстояние между двумя кластерами определяется расстоянием между двумя наиболее
- 41. Метод Варда (Ward's method). В качестве расстояния между кластерами берется прирост суммы квадратов расстояний объектов до
- 43. Метод наиболее удаленных соседей или полная связь. Здесь расстояния между кластерами определяются наибольшим расстоянием между любыми
- 45. Метод невзвешенного попарного среднего (метод невзвешенного попарного арифметического среднего - unweighted pair-group method using arithmetic averages,
- 46. Метод взвешенного попарного среднего (метод взвешенного попарного арифметического среднего - weighted pair-group method using arithmetic averages,
- 47. Невзвешенный центроидный метод (метод невзвешенного попарного центроидного усреднения - unweighted pair-group method using the centroid average
- 50. Важность алгоритмов “обучения без учителя” в том, что реальные признаки, описывающие объекты распознавания, очень часто бывают
- 51. Дадим более строгую формулировку задачи обучения «без учителя». Пусть обучающая выборка содержит М объектов: X =
- 52. где xij — значение j-ro признака для i-го объекта, п — количество признаков, характеризующих объект. Признаки,
- 53. При решении задачи обучения «без учителя» самыми несложными являются алгоритмы, основанные на мерах близости. Для достижения
- 54. Алгоритм, основанный на понятии порогового расстояния Пороговый алгоритм — один из самых несложных алгоритмов, базирующихся на
- 55. Самая первая точка-прототип может выбираться произвольно. Результатом работы такого алгоритма будет разбиение объектов выборки X на
- 56. Алгоритм Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки). Количество классов К положить равным
- 57. Алгоритм 3. Определить пороговое расстояние Т = D(Z1,Z2)/2. Построить
- 58. Алгоритм
- 59. Рассмотрим пример работы алгоритма, основанного на вычислении порогового расстояния. Пусть каждый объект из множества объектов, представленных
- 60. Выберем в качестве точки-прототипа первого класса точку Х1 из обучающей выборки (обозначается далее Z1). В таблице
- 61. Наиболее удаленным объектом для Z1 будет Х8. Пороговое расстояние Точка Х8 становится точкой-прототипом второго класса и
- 66. К достоинствам рассмотренного алгоритма следует отнести простоту реализации и небольшой объем вычислений. Недостатки: не предусмотрено уточнение
- 67. Из этого следует, что полезно было бы использовать алгоритмы, допускающие многократную коррекцию формируемых классов, например, можно
- 68. Алгоритм MAXMIN Рассмотрим алгоритм, более эффективный по сравнению с предыдущим и являющийся улучшением порогового алгоритма. Исходными
- 69. Алгоритм MAXMIN На первом этапе алгоритма все объекты разделяются по классам на основе критерия минимального расстояния
- 70. В этом алгоритме пороговое расстояние не является фиксированным, а определяется на основе среднего расстояния между всеми
- 71. Алгоритм Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки). Количество классов К положить равным
- 72. Алгоритм
- 73. Алгоритм
- 74. Рассмотрим работу алгоритма MAXMIN на примере. Как и в предыдущем случае выберем объекты, которые заданы двумя
- 76. Скачать презентацию

Человек, решающий задачу выбора целесообразного поведения в той или иной ситуации,
Человек, решающий задачу выбора целесообразного поведения в той или иной ситуации,

Оценка входной ситуации человеком происходит на основе совокупности сигналов, поступающих от
Оценка входной ситуации человеком происходит на основе совокупности сигналов, поступающих от

Вычислительная машина, на которой моделируется аналогичный процесс, должна обладать возможностью получать
Вычислительная машина, на которой моделируется аналогичный процесс, должна обладать возможностью получать

Для того, чтобы эффективно оценить, относятся ли различные ситуации к одному
Для того, чтобы эффективно оценить, относятся ли различные ситуации к одному

Обучение на основе примеров является типичным случаем индуктивного обучения и широко
Обучение на основе примеров является типичным случаем индуктивного обучения и широко

Источником примеров, на которых осуществляется обучение, может быть учитель то есть
Источником примеров, на которых осуществляется обучение, может быть учитель то есть

Источником примеров для обучения может быть внешняя среда, с которой взаимодействует
Источником примеров для обучения может быть внешняя среда, с которой взаимодействует

Наконец, источником примеров для обучения может стать сама интеллектуальная система. Например,
Наконец, источником примеров для обучения может стать сама интеллектуальная система. Например,

Для системы машинного обучения принципиально важным является вопрос, что поступает на
Для системы машинного обучения принципиально важным является вопрос, что поступает на

Значения, которые могут принимать признаки объекта, относятся к трем основным типам:
Значения, которые могут принимать признаки объекта, относятся к трем основным типам:

В случае, если признаки могут иметь качественный характер, но при этом
В случае, если признаки могут иметь качественный характер, но при этом

Третий случай заключается в том, что значения признаков имеют чисто качественный
Третий случай заключается в том, что значения признаков имеют чисто качественный
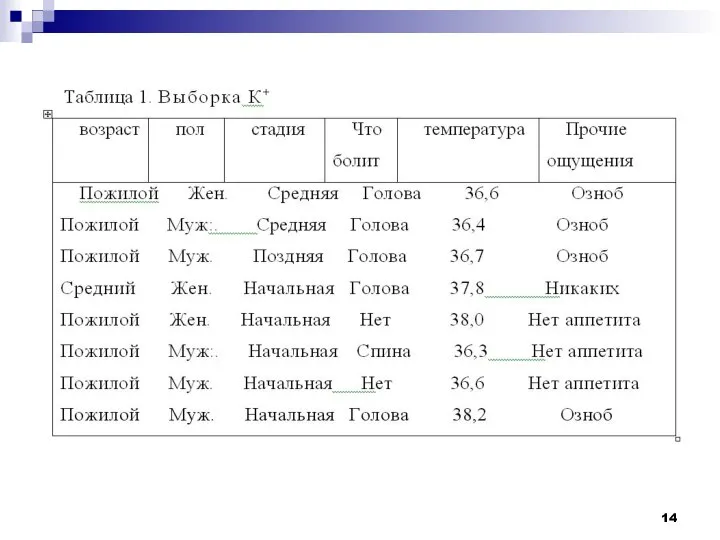


Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году, включает
Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году, включает

Рассмотрим пример процедуры кластерного анализа.
Допустим, мы имеем набор данных А, состоящий
Рассмотрим пример процедуры кластерного анализа.
Допустим, мы имеем набор данных А, состоящий
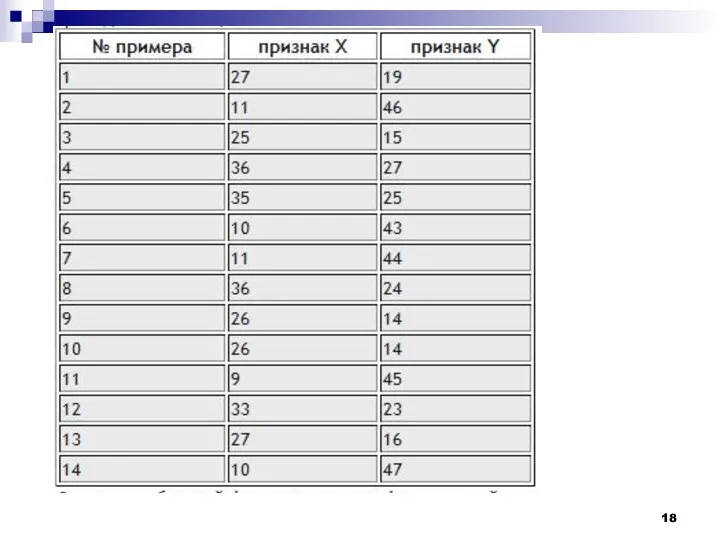
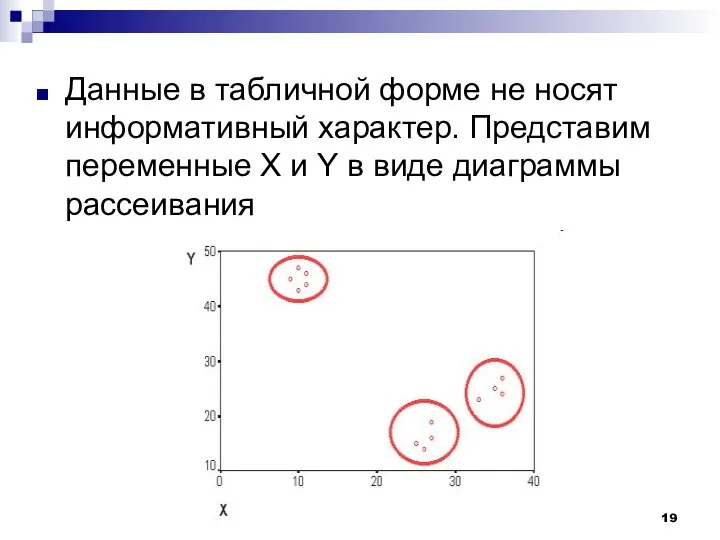
Данные в табличной форме не носят информативный характер. Представим переменные X
Данные в табличной форме не носят информативный характер. Представим переменные X

На рисунке мы видим несколько групп "похожих" примеров. Примеры (объекты), которые
На рисунке мы видим несколько групп "похожих" примеров. Примеры (объекты), которые

Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i
Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i

Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i
Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i

Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера.
Центр
Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера.
Центр

Спорный объект - это объект, который по мере сходства может быть
Спорный объект - это объект, который по мере сходства может быть
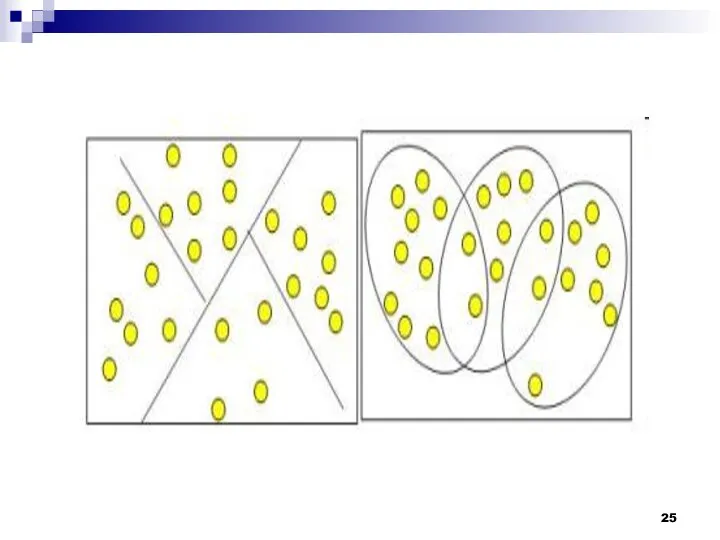

Работа кластерного анализа опирается на два предположения. Первое предположение - рассматриваемые
Работа кластерного анализа опирается на два предположения. Первое предположение - рассматриваемые

Рассмотрим пример. Представим себе, что данные признака х в наборе данных
Рассмотрим пример. Представим себе, что данные признака х в наборе данных

Эта проблема решается при помощи предварительной стандартизации переменных. Стандартизация (standardization) или
Эта проблема решается при помощи предварительной стандартизации переменных. Стандартизация (standardization) или

Наряду со стандартизацией переменных, существует вариант придания каждой из них определенного
Наряду со стандартизацией переменных, существует вариант придания каждой из них определенного

Методы кластерного анализа можно разделить на две группы:
иерархические;
неиерархические.
Суть иерархической
Методы кластерного анализа можно разделить на две группы:
иерархические;
неиерархические.
Суть иерархической

Иерархические агломеративные методы (Agglomerative Nesting, AGNES)
Эта группа методов характеризуется последовательным объединением
Иерархические агломеративные методы (Agglomerative Nesting, AGNES)
Эта группа методов характеризуется последовательным объединением

Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA)
Эти методы являются логической противоположностью
Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA)
Эти методы являются логической противоположностью
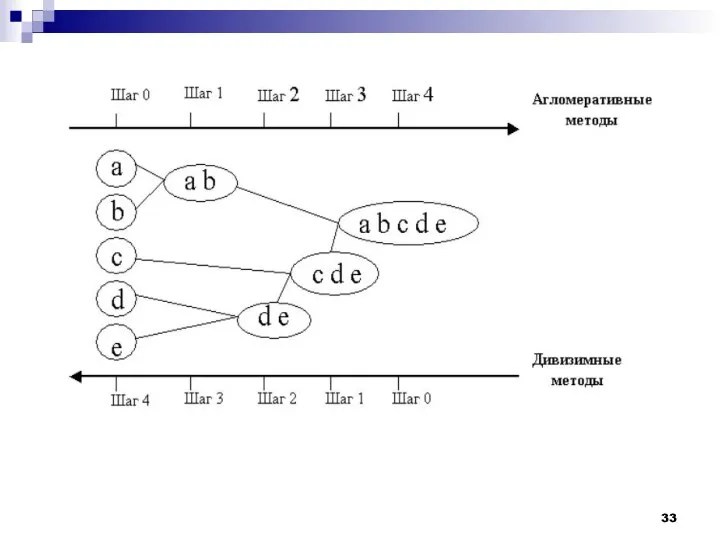

Программная реализация алгоритмов кластерного анализа широко представлена в различных инструментах Data
Программная реализация алгоритмов кластерного анализа широко представлена в различных инструментах Data

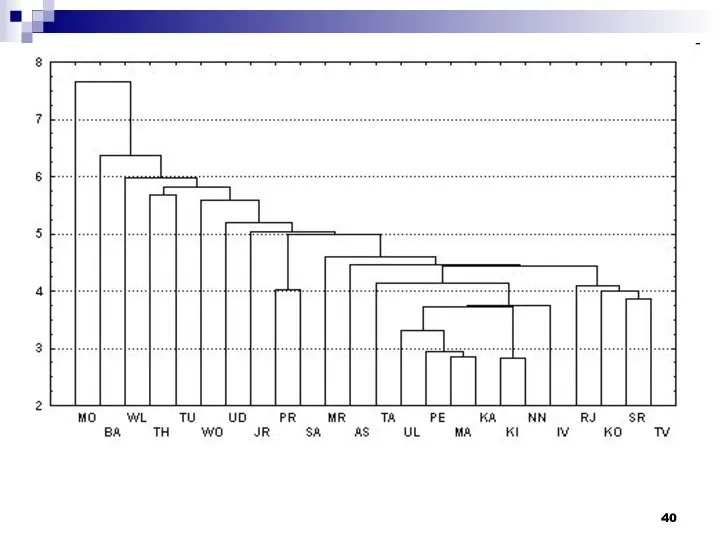
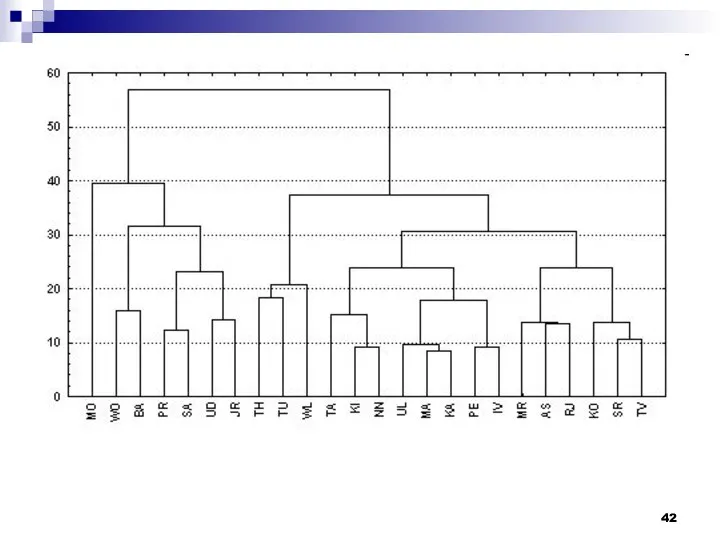
Иерархические алгоритмы связаны с построением дендрограмм (от греческого dendron - "дерево"),
Иерархические алгоритмы связаны с построением дендрограмм (от греческого dendron - "дерево"),
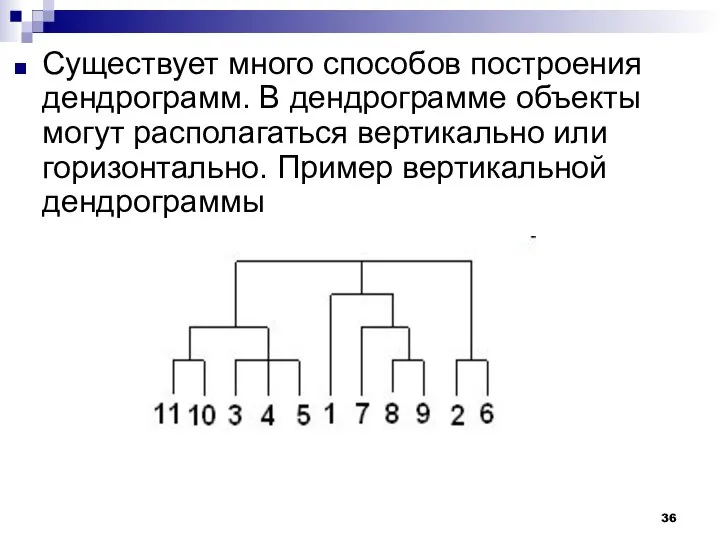
Существует много способов построения дендрограмм. В дендрограмме объекты могут располагаться вертикально
Существует много способов построения дендрограмм. В дендрограмме объекты могут располагаться вертикально

Числа 11, 10, 3 и т.д. соответствуют номерам объектов или наблюдений
Числа 11, 10, 3 и т.д. соответствуют номерам объектов или наблюдений

Методы объединения или связи
Когда каждый объект представляет собой отдельный кластер, расстояния
Методы объединения или связи
Когда каждый объект представляет собой отдельный кластер, расстояния

Метод ближнего соседа или одиночная связь. Здесь расстояние между двумя кластерами
Метод ближнего соседа или одиночная связь. Здесь расстояние между двумя кластерами

Метод Варда (Ward's method). В качестве расстояния между кластерами берется прирост
Метод Варда (Ward's method). В качестве расстояния между кластерами берется прирост

Метод наиболее удаленных соседей или полная связь. Здесь расстояния между кластерами
Метод наиболее удаленных соседей или полная связь. Здесь расстояния между кластерами

Метод невзвешенного попарного среднего (метод невзвешенного попарного арифметического среднего - unweighted
Метод невзвешенного попарного среднего (метод невзвешенного попарного арифметического среднего - unweighted

Метод взвешенного попарного среднего (метод взвешенного попарного арифметического среднего - weighted
Метод взвешенного попарного среднего (метод взвешенного попарного арифметического среднего - weighted

Невзвешенный центроидный метод (метод невзвешенного попарного центроидного усреднения - unweighted pair-group
Невзвешенный центроидный метод (метод невзвешенного попарного центроидного усреднения - unweighted pair-group


Важность алгоритмов “обучения без учителя” в том, что реальные признаки, описывающие
Важность алгоритмов “обучения без учителя” в том, что реальные признаки, описывающие

Дадим более строгую формулировку задачи обучения «без учителя».
Пусть обучающая выборка содержит
Дадим более строгую формулировку задачи обучения «без учителя».
Пусть обучающая выборка содержит

где xij — значение j-ro признака для i-го объекта, п —

При решении задачи обучения «без учителя» самыми несложными являются алгоритмы, основанные
При решении задачи обучения «без учителя» самыми несложными являются алгоритмы, основанные

Алгоритм, основанный на понятии порогового расстояния
Пороговый алгоритм — один из самых
Алгоритм, основанный на понятии порогового расстояния
Пороговый алгоритм — один из самых

Самая первая точка-прототип может выбираться произвольно. Результатом работы такого алгоритма будет
Самая первая точка-прототип может выбираться произвольно. Результатом работы такого алгоритма будет

Алгоритм
Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки).
Алгоритм
Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки).

Алгоритм
3. Определить пороговое расстояние Т = D(Z1,Z2)/2.
Построить
Алгоритм
3. Определить пороговое расстояние Т = D(Z1,Z2)/2.
Построить

Алгоритм
Алгоритм

Рассмотрим пример работы алгоритма, основанного на вычислении порогового расстояния. Пусть каждый
Рассмотрим пример работы алгоритма, основанного на вычислении порогового расстояния. Пусть каждый
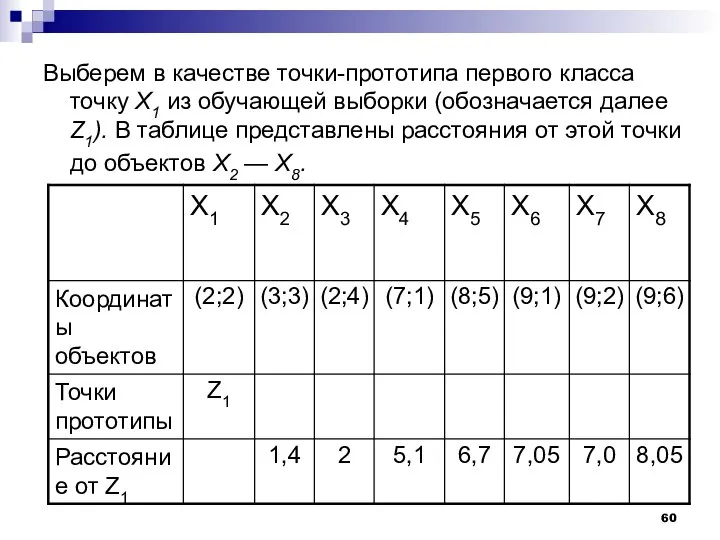
Выберем в качестве точки-прототипа первого класса точку Х1 из обучающей выборки
Выберем в качестве точки-прототипа первого класса точку Х1 из обучающей выборки

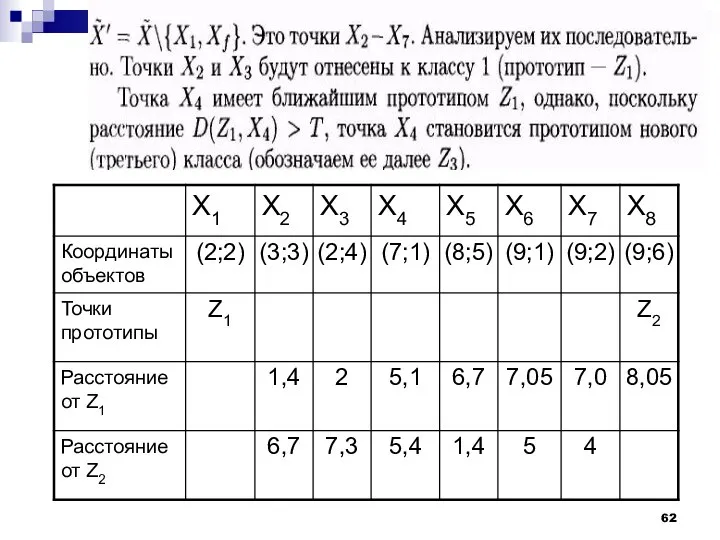
Наиболее удаленным объектом для Z1 будет Х8.
Пороговое расстояние
Точка Х8 становится
Наиболее удаленным объектом для Z1 будет Х8.
Пороговое расстояние
Точка Х8 становится
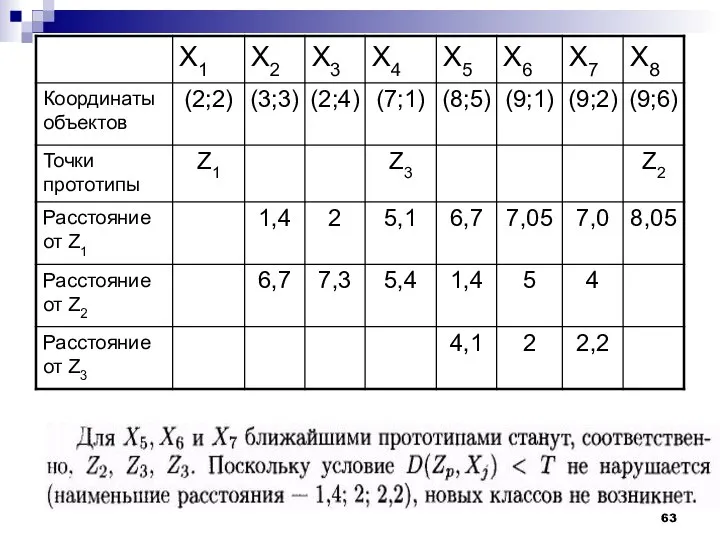


К достоинствам рассмотренного алгоритма следует отнести простоту реализации и небольшой объем
К достоинствам рассмотренного алгоритма следует отнести простоту реализации и небольшой объем

Из этого следует, что полезно было бы использовать алгоритмы, допускающие многократную
Из этого следует, что полезно было бы использовать алгоритмы, допускающие многократную

Алгоритм MAXMIN
Рассмотрим алгоритм, более эффективный по сравнению с предыдущим и являющийся
Алгоритм MAXMIN
Рассмотрим алгоритм, более эффективный по сравнению с предыдущим и являющийся

Алгоритм MAXMIN
На первом этапе алгоритма все объекты разделяются по классам на
Алгоритм MAXMIN
На первом этапе алгоритма все объекты разделяются по классам на

В этом алгоритме пороговое расстояние не является фиксированным, а определяется на
В этом алгоритме пороговое расстояние не является фиксированным, а определяется на

Алгоритм
Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки). Количество
Алгоритм
Выбрать точку-прототип первого класса (например, объект Х1 из обучающей выборки). Количество

Алгоритм
Алгоритм

Алгоритм
Алгоритм
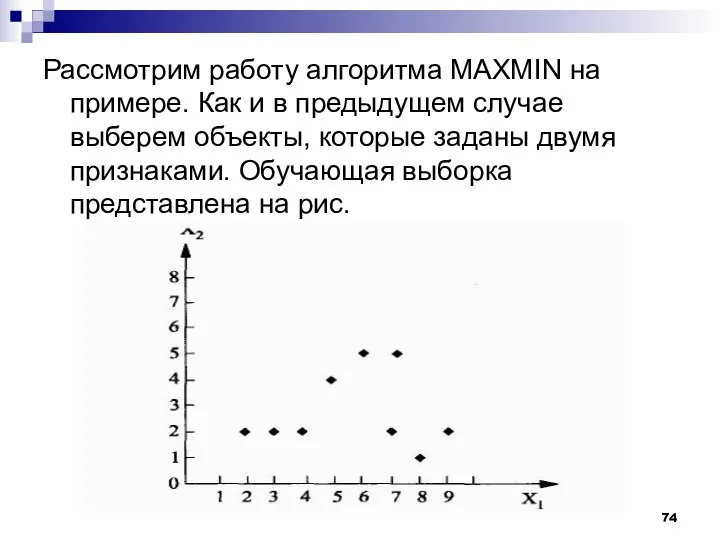
Рассмотрим работу алгоритма MAXMIN на примере. Как и в предыдущем случае
Рассмотрим работу алгоритма MAXMIN на примере. Как и в предыдущем случае
 Презентация "Андрей Матвеев" - скачать презентации по МХК
Презентация "Андрей Матвеев" - скачать презентации по МХК Die Zeit
Die Zeit . Экомониторинг
. Экомониторинг Հայկազուն-Երվանդունիների թագավորություն (6)
Հայկազուն-Երվանդունիների թագավորություն (6) German Customs and Traditions
German Customs and Traditions Ноябрь – зиме родной брат
Ноябрь – зиме родной брат Леонард Эйлер. Круги Эйлера
Леонард Эйлер. Круги Эйлера Шағын бизнес
Шағын бизнес Концепция подготовки спортивного резерва в РФ до 2025
Концепция подготовки спортивного резерва в РФ до 2025 Презентация "Государственное регулирование цен" - скачать презентации по Экономике
Презентация "Государственное регулирование цен" - скачать презентации по Экономике Mitsubishi Galant VIII - история автомобиля
Mitsubishi Galant VIII - история автомобиля Католическая церковь
Католическая церковь Презентация Дальневосточное Таможенное управление
Презентация Дальневосточное Таможенное управление Третейское разбирательство. Нотариат в Российской Федерации
Третейское разбирательство. Нотариат в Российской Федерации ТЕРМОРЕГУЛЯЦИЯ
ТЕРМОРЕГУЛЯЦИЯ Меры социальной поддержки по ЖКУ. Субсидии
Меры социальной поддержки по ЖКУ. Субсидии Этапы создания текста перевода
Этапы создания текста перевода Взаимоотношения с риелторскими службами
Взаимоотношения с риелторскими службами Оборудование плавильного участка
Оборудование плавильного участка Микробиология сальмонеллезов
Микробиология сальмонеллезов Вибрационные методы
Вибрационные методы Пампа Моняк
Пампа Моняк Культура и поведение
Культура и поведение Туристский клуб «Белки». Первый сплав по Берди - «Первооткрыватель»
Туристский клуб «Белки». Первый сплав по Берди - «Первооткрыватель» Cyber Spying in world today
Cyber Spying in world today OptoGaN Enabling bulb-like brightness for LEDs
OptoGaN Enabling bulb-like brightness for LEDs Виды отклонений от языковой нормы и их передача
Виды отклонений от языковой нормы и их передача Отделение электроники. Лидский колледж
Отделение электроники. Лидский колледж