- Классификация архитектур вычислительных систем

Содержание
- 2. Введение Общие принципы функционирования параллельных машин векторно-конвейерные массивно-параллельные компьютеры с широким командным словом систолические массивы гиперкубы
- 3. Классификация Флинна самая ранняя и наиболее известная классификация Классификация базируется на понятии потока - последовательности элементов
- 4. Дополнения Ванга и Бриггса Патч для архитектуры Флинна Детализирует классы архитектур : SIMD,SISD,MIMD Класс SISD разбивается
- 5. Классификация Фенга Классификация вычислительных систем на основе двух простых характеристик Число бит n в машинном слове,
- 6. Классификация Шора Выделение типичных способов компоновки вычислительных систем на основе фиксированного числа базисных блоков: устройства управления,
- 7. Классификация Шора Если объединить принципы построения машин I и II, то получим машину III. Эта машина
- 8. Классификация Шора Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV, например в виде
- 9. Классификация Хендлера основа классификации - явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой способы
- 10. Классификация Хокни Детализация классификции Флинна систематизации компьютеров, попадающих в класс MIMD по систематике Флинна. Множественный поток
- 11. Классификация Джонсона классификацию MIMD архитектур на основе структуры памяти и реализации механизма взаимодействия и синхронизации между
- 12. Классификация Базу Любую параллельную вычислительную систему можно однозначно описать последовательностью решений, принятых на этапе ее проектирования,
- 13. Классификация Кришнамарфи аналог Базу для классификации параллельных вычислительных систем предлагает использовать четыре характеристики степень гранулярности; способ
- 14. Классификация Скилликорна очередная попытка расширить классификацию Флинна Классификация состоит из двух уровней. На первом уровне она
- 15. Классификация Дазгупты последние исследования по классификации Модифиация метода Скилликорна Назовем классом классификационной схемы именованную группу объектов,
- 16. Классификация Дункана Систематика очень простая: процессоры системы работают либо синхронно, либо независимо друг от друга, либо
- 18. Скачать презентацию

Введение
Общие принципы функционирования параллельных машин
векторно-конвейерные
массивно-параллельные
компьютеры с широким командным словом
систолические массивы
гиперкубы
спецпроцессоры
мультипроцессоры
иерархические
кластерные компьютеры
dataflow
матричные
Введение
Общие принципы функционирования параллельных машин
векторно-конвейерные
массивно-параллельные
компьютеры с широким командным словом
систолические массивы
гиперкубы
спецпроцессоры
мультипроцессоры
иерархические
кластерные компьютеры
dataflow
матричные
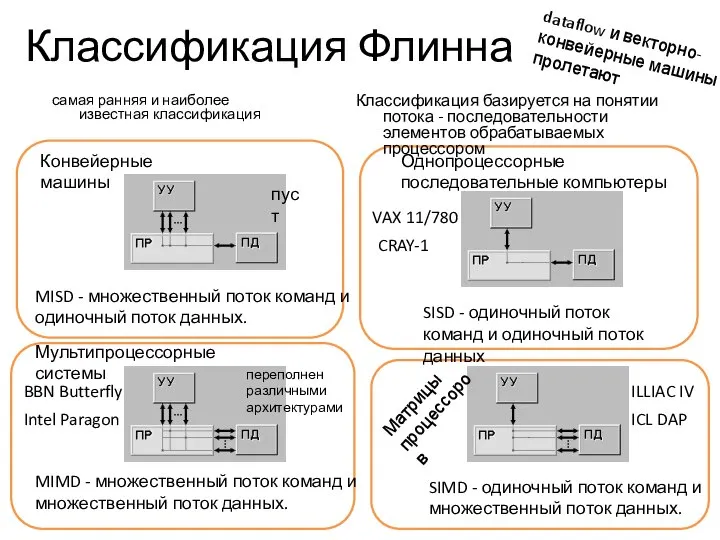
Классификация Флинна
самая ранняя и наиболее известная классификация
Классификация базируется на понятии потока
Классификация Флинна
самая ранняя и наиболее известная классификация
Классификация базируется на понятии потока

Дополнения Ванга и Бриггса
Патч для архитектуры Флинна
Детализирует классы архитектур : SIMD,SISD,MIMD
Класс
Дополнения Ванга и Бриггса
Патч для архитектуры Флинна
Детализирует классы архитектур : SIMD,SISD,MIMD
Класс

Классификация Фенга
Классификация вычислительных систем на основе двух простых характеристик
Число бит n
Классификация Фенга
Классификация вычислительных систем на основе двух простых характеристик
Число бит n
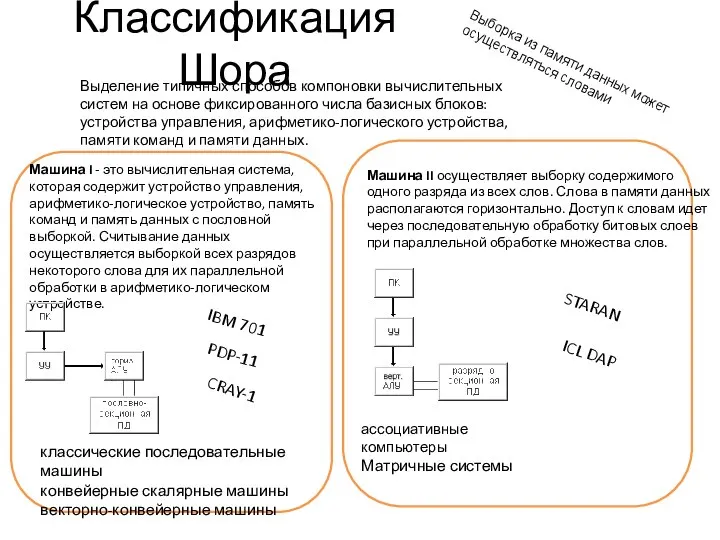
Классификация Шора
Выделение типичных способов компоновки вычислительных систем на основе фиксированного числа
Классификация Шора
Выделение типичных способов компоновки вычислительных систем на основе фиксированного числа
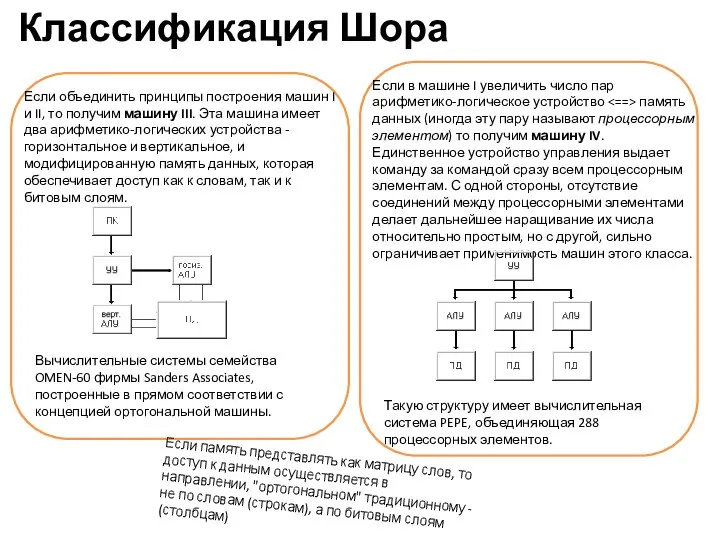
Классификация Шора
Если объединить принципы построения машин I и II, то получим
Классификация Шора
Если объединить принципы построения машин I и II, то получим
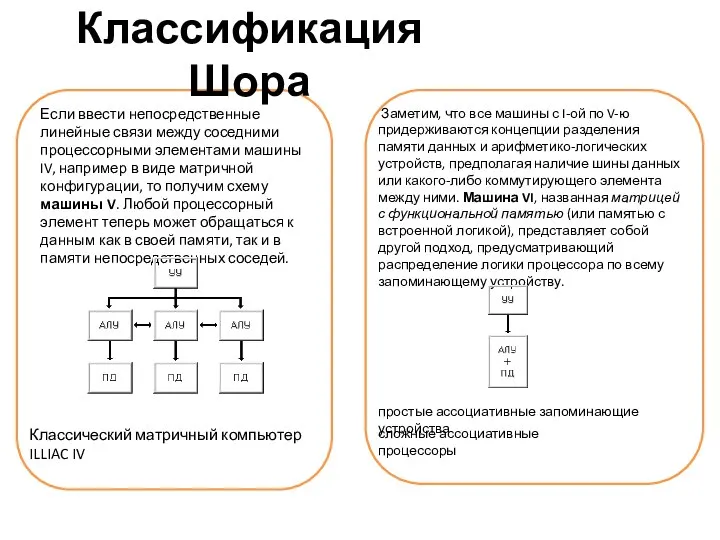
Классификация Шора
Если ввести непосредственные линейные связи между соседними процессорными элементами машины
Классификация Шора
Если ввести непосредственные линейные связи между соседними процессорными элементами машины
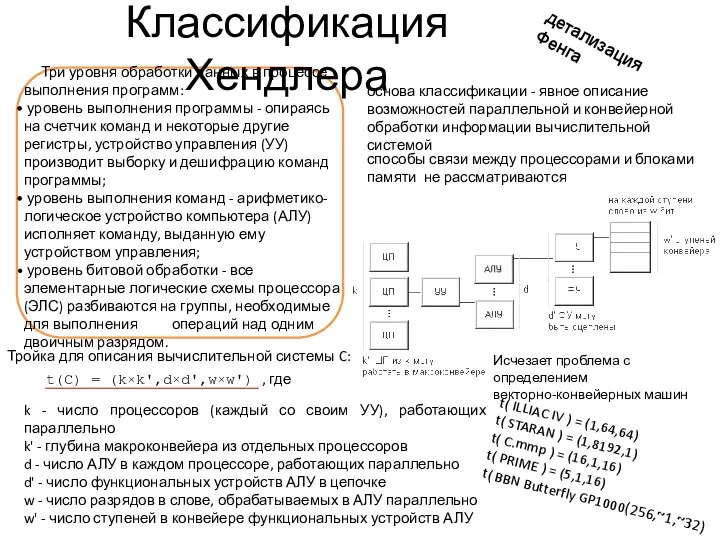
Классификация Хендлера
основа классификации - явное описание возможностей параллельной и конвейерной обработки
Классификация Хендлера
основа классификации - явное описание возможностей параллельной и конвейерной обработки
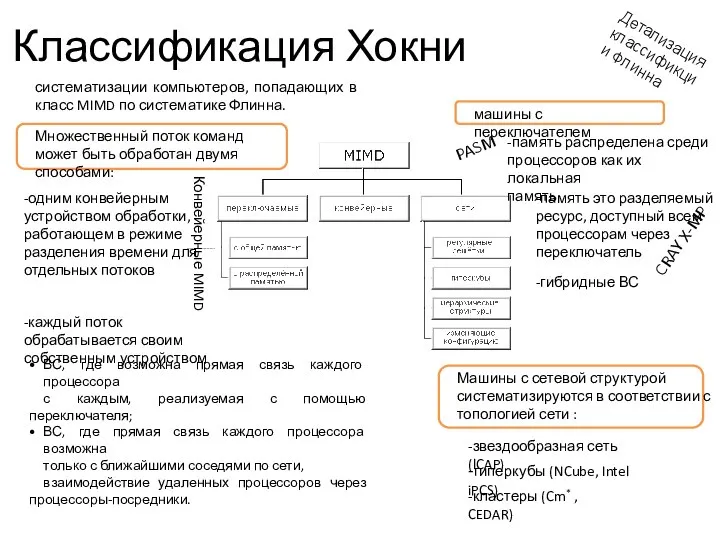
Классификация Хокни
Детализация классификции Флинна
систематизации компьютеров, попадающих в класс MIMD по систематике
Классификация Хокни
Детализация классификции Флинна
систематизации компьютеров, попадающих в класс MIMD по систематике

Классификация Джонсона
классификацию MIMD архитектур на основе структуры памяти и реализации механизма
Классификация Джонсона
классификацию MIMD архитектур на основе структуры памяти и реализации механизма
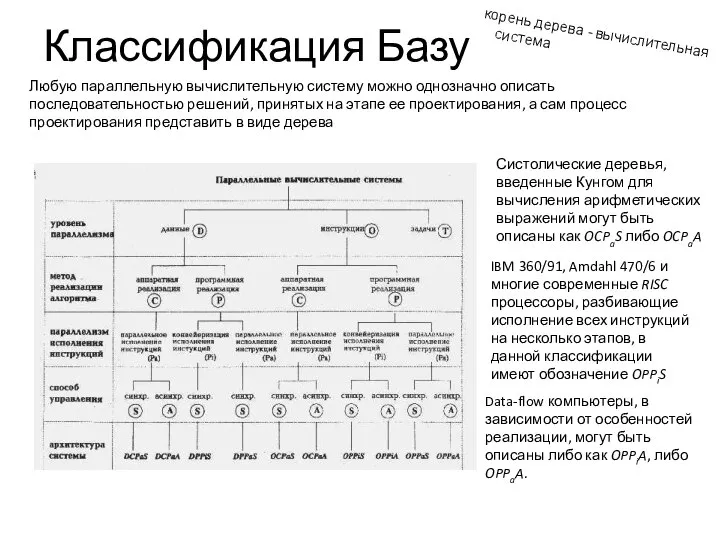
Классификация Базу
Любую параллельную вычислительную систему можно однозначно описать последовательностью решений, принятых
Классификация Базу
Любую параллельную вычислительную систему можно однозначно описать последовательностью решений, принятых
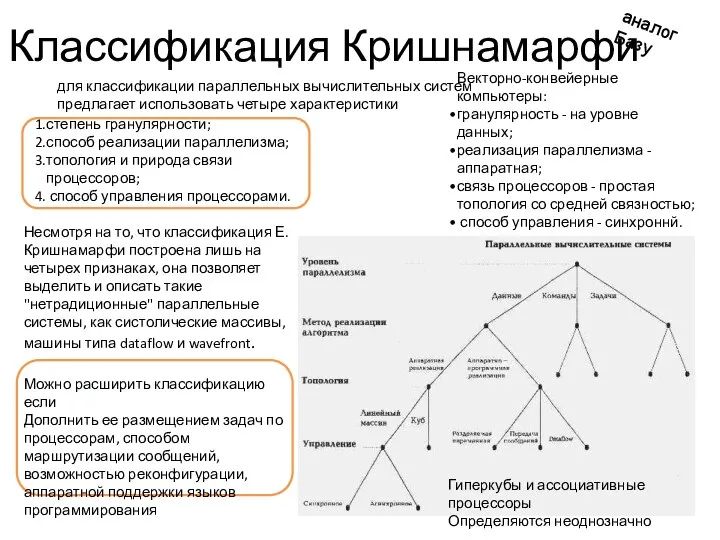
Классификация Кришнамарфи
аналог Базу
для классификации параллельных вычислительных систем предлагает использовать четыре характеристики
Классификация Кришнамарфи
аналог Базу
для классификации параллельных вычислительных систем предлагает использовать четыре характеристики
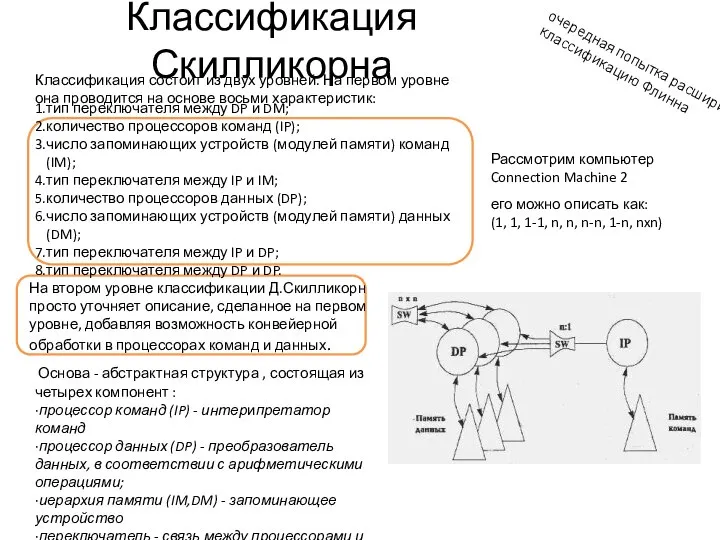
Классификация Скилликорна
очередная попытка расширить классификацию Флинна
Классификация состоит из двух уровней. На
Классификация Скилликорна
очередная попытка расширить классификацию Флинна
Классификация состоит из двух уровней. На

Классификация Дазгупты
последние исследования по классификации
Модифиация метода Скилликорна
Назовем классом классификационной схемы именованную
Классификация Дазгупты
последние исследования по классификации
Модифиация метода Скилликорна
Назовем классом классификационной схемы именованную

Классификация Дункана
Систематика очень простая: процессоры системы работают либо синхронно, либо независимо
Классификация Дункана
Систематика очень простая: процессоры системы работают либо синхронно, либо независимо
 Инструментарий веб-студии: от брифа до презентации Балахтин Кирилл Руководитель отдела по работе с клиентами Интерактивное аген
Инструментарий веб-студии: от брифа до презентации Балахтин Кирилл Руководитель отдела по работе с клиентами Интерактивное аген Обобщения знаний о частях речи 3 класс - презентация для начальной школы_____________________________________________________________________________________________________________
Обобщения знаний о частях речи 3 класс - презентация для начальной школы_____________________________________________________________________________________________________________ Physical education communication
Physical education communication Визитная карточка
Визитная карточка Концепция предвыборного плаката партии КПРФ
Концепция предвыборного плаката партии КПРФ Бізнес-план кафе "White&black"
Бізнес-план кафе "White&black" НАША МОСКВА - презентация для начальной школы_
НАША МОСКВА - презентация для начальной школы_ Формы трудовой деятельности
Формы трудовой деятельности  02Извещение о НС
02Извещение о НС Портфолио дисциплины
Портфолио дисциплины Презентация____
Презентация____ Нелинейная оптика
Нелинейная оптика  Строительство здания производственного назначения
Строительство здания производственного назначения Язык и речь
Язык и речь Дозиметрические единицы и защита от радиоактивных излучений.
Дозиметрические единицы и защита от радиоактивных излучений. Источники финансирования инвестиций
Источники финансирования инвестиций Воспаление. ГЕМАТОЛОГИЧЕСКИЙ ССИНДРОМ ОТВЕТ ОСТРОЙ ФАЗЫ ЛИХОРАДКА
Воспаление. ГЕМАТОЛОГИЧЕСКИЙ ССИНДРОМ ОТВЕТ ОСТРОЙ ФАЗЫ ЛИХОРАДКА презентация коррупция
презентация коррупция Строение и функции нервной системы человека Подготовила Ученицы 9-в класса Горловского УВК №22 Оклей Виктория
Строение и функции нервной системы человека Подготовила Ученицы 9-в класса Горловского УВК №22 Оклей Виктория Архитектурно-планировочные приемы при реконструкции жилых зданий
Архитектурно-планировочные приемы при реконструкции жилых зданий Дифференциальная диагностика нарушений ритма сердца
Дифференциальная диагностика нарушений ритма сердца  Принцип черного ящика
Принцип черного ящика Тема: «Порядок прекращения деятельности юридических лиц» Выполнил: Студент 2-го курса Группа Юб 03/1303 Якушенко Игорь
Тема: «Порядок прекращения деятельности юридических лиц» Выполнил: Студент 2-го курса Группа Юб 03/1303 Якушенко Игорь  франция мәдениеті
франция мәдениеті Теоретические распределения в анализе вариационных рядов
Теоретические распределения в анализе вариационных рядов становление туризма в СССР
становление туризма в СССР  Магнезиальные вяжущие
Магнезиальные вяжущие Волоконно-оптические линии связи. Основные характеристики электромагнитного поля и среды его распространения.
Волоконно-оптические линии связи. Основные характеристики электромагнитного поля и среды его распространения.