- Массивно-параллельные системы

Содержание
- 2. MPP архитектура (massive parallel processing) - массивно-параллельная архитектура. Особенность - память физически разделена. Система строится из
- 3. MPP архитектура (massive parallel processing) - массивно-параллельная архитектура. Главное преимущество: хорошая масштабируемость (отличие от SMP-систем каждый
- 4. MPP архитектура (massive parallel processing) - массивно-параллельная архитектура. Недостатки: •Отсутствие общей памяти заметно снижает скорость межпроцессорного
- 5. Операционная система и способ программирования Существуют два основных варианта: Полноценная ОС работает только на управляющей машине
- 6. Немного истории=) С самого начала компьютерной эры существовала необходимость во все более и более производительных системах.
- 7. ILLIAC IV
- 8. Способ доступа к модулям памяти Имеет ли каждый процессор локальную память и обращается к другим блокам
- 9. Система с распределенной памятью
- 10. Коммутативная сеть с общей памятью.
- 11. Способ доступа к модулям памяти 1) Компьютеры с распределенной памятью (Distributed memory) Каждый процессор имеет доступ
- 12. Способ доступа к модулям памяти 2) Компьютеры с общей (разделяемой) памятью (True shared memory) Каждый процессор
- 13. Способ доступа к модулям памяти 3) Компьютеры с виртуальной общей (разделяемой) памятью (Virtual shared memory) В
- 14. И на последок Массивно-параллельные системы остаются достаточно дорогими. Однако заложенная в них идея - использование большого
- 15. Несколько примеров 1) - CRAY T3E - массивно-параллельный компьютер фирмы Тега
- 16. Несколько примеров 1) - CRAY T3E - массивно-параллельный компьютер фирмы Тега Каждый узел в системе содержит
- 17. Несколько примеров 2) Cray T3D
- 18. Несколько примеров Общая структура компьютера CRAY T3D Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной
- 20. Скачать презентацию

MPP архитектура (massive parallel processing) - массивно-параллельная архитектура.
Особенность - память физически
MPP архитектура (massive parallel processing) - массивно-параллельная архитектура.
Особенность - память физически

MPP архитектура (massive parallel processing) - массивно-параллельная архитектура.
Главное преимущество: хорошая масштабируемость
MPP архитектура (massive parallel processing) - массивно-параллельная архитектура.
Главное преимущество: хорошая масштабируемость

MPP архитектура (massive parallel processing) - массивно-параллельная архитектура.
Недостатки:
•Отсутствие общей
MPP архитектура (massive parallel processing) - массивно-параллельная архитектура.
Недостатки:
•Отсутствие общей

Операционная система и способ программирования
Существуют два основных варианта:
Полноценная ОС работает
Операционная система и способ программирования
Существуют два основных варианта:
Полноценная ОС работает

Немного истории=)
С самого начала компьютерной эры существовала необходимость во все более
Немного истории=)
С самого начала компьютерной эры существовала необходимость во все более

ILLIAC IV
ILLIAC IV

Способ доступа к модулям памяти
Имеет ли каждый процессор локальную память
Способ доступа к модулям памяти
Имеет ли каждый процессор локальную память
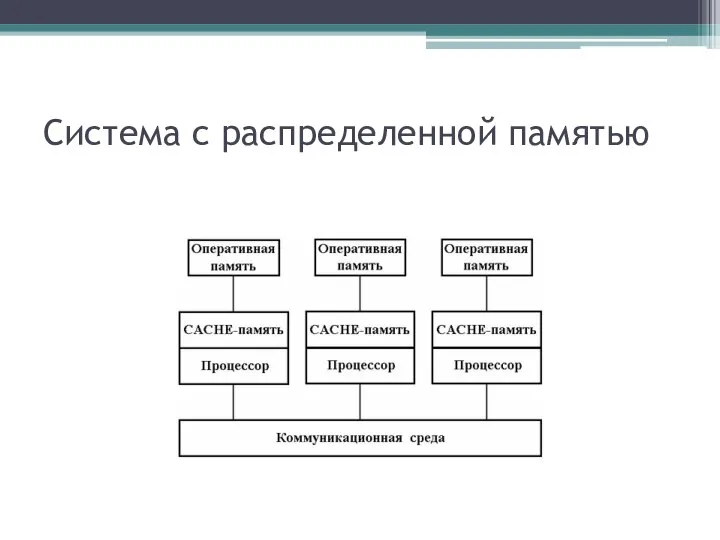
Система с распределенной памятью
Система с распределенной памятью
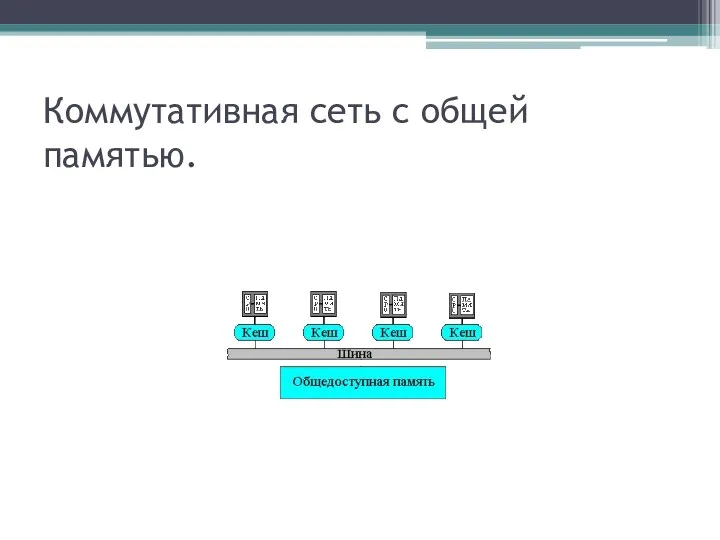
Коммутативная сеть с общей памятью.
Коммутативная сеть с общей памятью.

Способ доступа к модулям памяти
1) Компьютеры с распределенной памятью (Distributed memory)
Способ доступа к модулям памяти
1) Компьютеры с распределенной памятью (Distributed memory)

Способ доступа к модулям памяти
2) Компьютеры с общей (разделяемой) памятью (True shared
Способ доступа к модулям памяти
2) Компьютеры с общей (разделяемой) памятью (True shared

Способ доступа к модулям памяти
3) Компьютеры с виртуальной общей (разделяемой) памятью (Virtual
Способ доступа к модулям памяти
3) Компьютеры с виртуальной общей (разделяемой) памятью (Virtual

И на последок
Массивно-параллельные системы остаются достаточно дорогими. Однако заложенная в них
И на последок
Массивно-параллельные системы остаются достаточно дорогими. Однако заложенная в них

Несколько примеров
1) - CRAY T3E - массивно-параллельный компьютер фирмы Тега
Несколько примеров
1) - CRAY T3E - массивно-параллельный компьютер фирмы Тега

Несколько примеров
1) - CRAY T3E - массивно-параллельный компьютер фирмы Тега
Каждый
Несколько примеров
1) - CRAY T3E - массивно-параллельный компьютер фирмы Тега
Каждый

Несколько примеров
2) Cray T3D
Несколько примеров
2) Cray T3D

Несколько примеров
Общая структура компьютера CRAY T3D
Компьютер CRAY T3D - это
Несколько примеров
Общая структура компьютера CRAY T3D
Компьютер CRAY T3D - это
 Программирование на языке высокого уровня. (Лекции 1, 2)
Программирование на языке высокого уровня. (Лекции 1, 2) Понятие консалтинга в области информационных технологий
Понятие консалтинга в области информационных технологий  Физическое воспитание
Физическое воспитание Мольер Жан Батист
Мольер Жан Батист Разработка грунта землеройно-транспортными машинами
Разработка грунта землеройно-транспортными машинами Факторы, усиливающие коррупцию в РФ. Григоров Георгий Т-095
Факторы, усиливающие коррупцию в РФ. Григоров Георгий Т-095 Социология общественного мнения Вводная лекция
Социология общественного мнения Вводная лекция ЕС и Европейските институции Ролята на неправителствения сектор Петър Нацев, Парламентарен сътрудник на Илиана Иванова
ЕС и Европейските институции Ролята на неправителствения сектор Петър Нацев, Парламентарен сътрудник на Илиана Иванова Документальное оформление операций по учету основных средств
Документальное оформление операций по учету основных средств Эталонны
Эталонны  Организация внеурочной деятельности обучающихся: моделирование и проектирование кафедра педагогики и андрагогики ТОГИРРО 201
Организация внеурочной деятельности обучающихся: моделирование и проектирование кафедра педагогики и андрагогики ТОГИРРО 201 Sofaz. The State Oil Fund of the Republic of Azerbaijan
Sofaz. The State Oil Fund of the Republic of Azerbaijan Интерактивные KPI процессов eTOM Ф.В.Краснов
Интерактивные KPI процессов eTOM Ф.В.Краснов  ИНТЕРМОДАЛЬНЫЕ ПЕРЕВОЗКИ ГРУЗОВ Контейнерные перевозки грузов; Операторы смешанной перевозки грузов; Особенности взаимодей
ИНТЕРМОДАЛЬНЫЕ ПЕРЕВОЗКИ ГРУЗОВ Контейнерные перевозки грузов; Операторы смешанной перевозки грузов; Особенности взаимодей Прыжки в высоту способом «фосбери-флоп»
Прыжки в высоту способом «фосбери-флоп» Лекция 4. Курсовая работа по дисциплине «Основы конструирования программ» (2 семестр)
Лекция 4. Курсовая работа по дисциплине «Основы конструирования программ» (2 семестр) ОСНОВОПОЛАГАЮЩИЕ ИДЕИ И ПРИНЦИПЫ УПРАВЛЕНИЯ ИЗМЕНЕНИЯМИ
ОСНОВОПОЛАГАЮЩИЕ ИДЕИ И ПРИНЦИПЫ УПРАВЛЕНИЯ ИЗМЕНЕНИЯМИ Тема: Действия с натуральными числами
Тема: Действия с натуральными числами Президент Н.Назарбаевтың еуразиялық идеясы
Президент Н.Назарбаевтың еуразиялық идеясы Организация ЛПО
Организация ЛПО  Акробатика и воздушная гимнастика на полотнах
Акробатика и воздушная гимнастика на полотнах Тема 7. Трудовой договор План лекции № 1 1.Понятие и содержание трудового договора. 2.Порядок заключения трудового договора. 3.П
Тема 7. Трудовой договор План лекции № 1 1.Понятие и содержание трудового договора. 2.Порядок заключения трудового договора. 3.П Итоги работы предприятий агропромышленного комплекса Жлобинского района за январь-июль 2019 года
Итоги работы предприятий агропромышленного комплекса Жлобинского района за январь-июль 2019 года Проекционное черчение. Проецирование на несколько проекций
Проекционное черчение. Проецирование на несколько проекций Техническое описание и анализ конструкции компрессора газотурбинного двигателя АИ-450 МС
Техническое описание и анализ конструкции компрессора газотурбинного двигателя АИ-450 МС Понятие о физиотерапии. Постоянный ток. Импульсные токи
Понятие о физиотерапии. Постоянный ток. Импульсные токи Почвенно-географическое районирование
Почвенно-географическое районирование How to Download the Firmware image over the USB
How to Download the Firmware image over the USB