- NUMA-системы

Содержание
- 2. ОСНОВНЫЕ КЛАССЫ СОВРЕМЕННЫХ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ. Массивно-параллельные системы (MPP) MPP система состоит из однородных вычислительных узлов, включающих:
- 3. Параллельные векторные системы (PVP) Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды
- 4. ОПИСАНИЕ NUMA-АРХИТЕКТУРЫ. Гибридная архитектура воплощает в себе удобства систем с общей памятью и относительную дешевизну систем
- 5. ВОЗНИКНОВЕНИЕ И РАЗВИТИЕ NUMA-СИСТЕМ Первый этап. Прототипы Numa-систем. Понятие NUMA-архитектуры возникло в конце 80-х годов с
- 6. Второй этап. Первую машину основанную на гибридной архитектуре предложил Стив Воллох и воплотил в системах серии
- 7. Третий этап. Следующим этапом развития архитектуры NUMA является появление архитектуры NUMAFlex. 25 июля 2000 г. компания
- 8. МАШТАБИРУЕМОСТЬ. Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей и возможностями операционной системы
- 9. ОПЕРАЦИОННАЯ СИСТЕМА. Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также
- 10. ОСОБЕННОСТИ ПО NUMA-СИСТЕМ Для разработчика ПО следствием указанных выше особенностей NUMA-машин является то, что программы должны
- 11. ДОСТОИНСТВА Одним из достоинств является то, что можно использовать модель программирования, аналогичную SMP, в силу этого
- 12. НЕДОСТАТКИ Серьезные трудности связанные с управлением данными и когерентности кэшей, если она не реализованна аппаратно. Относительная
- 13. ПРИМЕРЫ Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC
- 15. Скачать презентацию

ОСНОВНЫЕ КЛАССЫ СОВРЕМЕННЫХ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ.
Массивно-параллельные системы (MPP)
MPP система состоит из однородных
ОСНОВНЫЕ КЛАССЫ СОВРЕМЕННЫХ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ.
Массивно-параллельные системы (MPP)
MPP система состоит из однородных

Параллельные векторные системы (PVP)
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров,
Параллельные векторные системы (PVP)
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров,
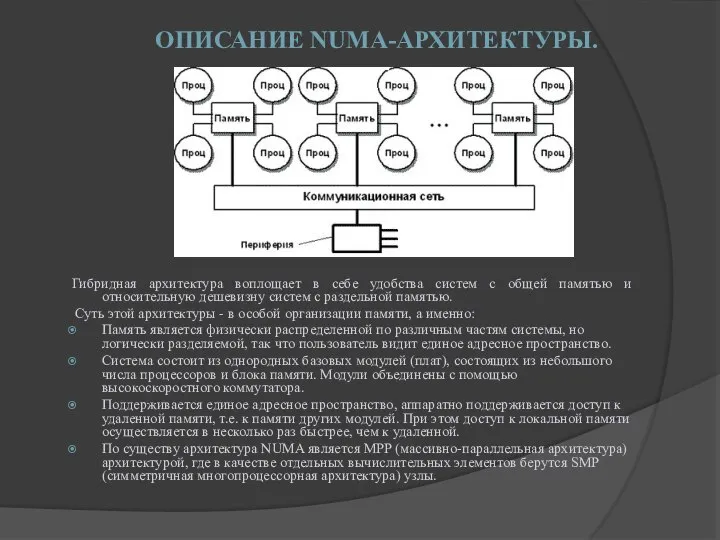
ОПИСАНИЕ NUMA-АРХИТЕКТУРЫ.
Гибридная архитектура воплощает в себе удобства систем с общей памятью
ОПИСАНИЕ NUMA-АРХИТЕКТУРЫ.
Гибридная архитектура воплощает в себе удобства систем с общей памятью

ВОЗНИКНОВЕНИЕ И РАЗВИТИЕ NUMA-СИСТЕМ
Первый этап. Прототипы Numa-систем.
Понятие NUMA-архитектуры возникло в конце
ВОЗНИКНОВЕНИЕ И РАЗВИТИЕ NUMA-СИСТЕМ
Первый этап. Прототипы Numa-систем.
Понятие NUMA-архитектуры возникло в конце

Второй этап.
Первую машину основанную на гибридной архитектуре предложил Стив Воллох и
Второй этап.
Первую машину основанную на гибридной архитектуре предложил Стив Воллох и

Третий этап.
Следующим этапом развития архитектуры NUMA является появление архитектуры NUMAFlex. 25
Третий этап.
Следующим этапом развития архитектуры NUMA является появление архитектуры NUMAFlex. 25

МАШТАБИРУЕМОСТЬ.
Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей
МАШТАБИРУЕМОСТЬ.
Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей

ОПЕРАЦИОННАЯ СИСТЕМА.
Обычно вся система работает под управлением единой ОС, как в
ОПЕРАЦИОННАЯ СИСТЕМА.
Обычно вся система работает под управлением единой ОС, как в

ОСОБЕННОСТИ ПО NUMA-СИСТЕМ
Для разработчика ПО следствием указанных выше особенностей NUMA-машин является
ОСОБЕННОСТИ ПО NUMA-СИСТЕМ
Для разработчика ПО следствием указанных выше особенностей NUMA-машин является

ДОСТОИНСТВА
Одним из достоинств является то, что можно использовать модель программирования, аналогичную
ДОСТОИНСТВА
Одним из достоинств является то, что можно использовать модель программирования, аналогичную

НЕДОСТАТКИ
Серьезные трудности связанные с управлением данными и когерентности кэшей, если она
НЕДОСТАТКИ
Серьезные трудности связанные с управлением данными и когерентности кэшей, если она

ПРИМЕРЫ
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях,
ПРИМЕРЫ
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях,
 Разнообразие форм и методов работы с учащимися по предметам школьная проблемная группа учителей ИЗО, ОБЖ, физической культуры и
Разнообразие форм и методов работы с учащимися по предметам школьная проблемная группа учителей ИЗО, ОБЖ, физической культуры и  Лидеры и элиты в политической жизни
Лидеры и элиты в политической жизни South Korea
South Korea «Придворный живописец Диего Веласкес». Искусство портрета. Образ человека 17 века
«Придворный живописец Диего Веласкес». Искусство портрета. Образ человека 17 века PAP5450DUO service manual
PAP5450DUO service manual Королевство Бутан
Королевство Бутан Циклические алгоритмы
Циклические алгоритмы Защита и обработка конфиденциальных документов. Порядок работы исполнителя с конфиденциальными документами
Защита и обработка конфиденциальных документов. Порядок работы исполнителя с конфиденциальными документами Памятники педагогической мысли Руси XI-XV века
Памятники педагогической мысли Руси XI-XV века Презентация на тему "фруктовая аптека" - скачать презентации по Медицине
Презентация на тему "фруктовая аптека" - скачать презентации по Медицине Гірськолижні курорти
Гірськолижні курорти Қазақстан Республикасы еңбек құқығы
Қазақстан Республикасы еңбек құқығы Хвойные деревья Томской области
Хвойные деревья Томской области Организация экономического сотрудничества и развития (ОЭСР) (Organization for Economic Co‑operation and Development - OECD) Хандюкова Ксения 3ЭФМ
Организация экономического сотрудничества и развития (ОЭСР) (Organization for Economic Co‑operation and Development - OECD) Хандюкова Ксения 3ЭФМ Презентация Типология общества
Презентация Типология общества  Особенности социально-экономического развития Индии Дисциплина: «Мировая экономика» Преподаватель: профессор кафедры МЭО, к.э.н.
Особенности социально-экономического развития Индии Дисциплина: «Мировая экономика» Преподаватель: профессор кафедры МЭО, к.э.н. Подготовка к ЕГЭ частьА 10 класс
Подготовка к ЕГЭ частьА 10 класс Конструкция и техническое обслуживание пассажирских вагонов
Конструкция и техническое обслуживание пассажирских вагонов Главная цель конкурса — поддержка гражданских инициатив на основе масштабного и разностороннего сотрудничества между Церковью,
Главная цель конкурса — поддержка гражданских инициатив на основе масштабного и разностороннего сотрудничества между Церковью,  Рисуем птичку Сегодня мы научимся рисовать птичку
Рисуем птичку Сегодня мы научимся рисовать птичку урок изобразительного искусства 3 класс учитель Кирсанова Надежда Владиславовна МОУ лицей № 10 города Советска Калининградско
урок изобразительного искусства 3 класс учитель Кирсанова Надежда Владиславовна МОУ лицей № 10 города Советска Калининградско Презентация "Три ступени – Три Дохода" - скачать презентации по Экономике
Презентация "Три ступени – Три Дохода" - скачать презентации по Экономике Презентация "Образ твой, над Русью вознесенный" - скачать презентации по МХК
Презентация "Образ твой, над Русью вознесенный" - скачать презентации по МХК Невербальное Воздействие
Невербальное Воздействие Назначение и принцип работы насосов
Назначение и принцип работы насосов British police
British police Класс. Описание класса
Класс. Описание класса Покажчики та масиви
Покажчики та масиви