- Моделирование и анализ параллельных вычислений.

Содержание
- 2. Эффективность параллельных вычислений Жесткие требования к эффективности определены задачами (экология, аэродинамика, геофизика, геном и др.): исследуемые
- 3. Зачем нужны модели и их анализ? Для разработки эффективных параллельных алгоритмов оценивают эффективность использования параллелизма: эффективность
- 4. Модель вычислений Граф «операции – операнды» описывает алгоритм вычислений на уровне операций и информационных зависимостей. Предположения
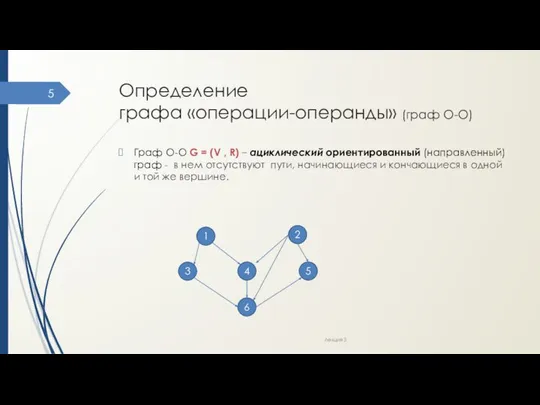
- 5. Определение графа «операции-операнды» (граф О-О) Граф О-О G = (V , R) – ациклический ориентированный (направленный)
- 6. Определение графа «операции-операнды» (граф О-О) G = (V , R) V – множество вершин графа, представляющих
- 7. Пример модели вычислений (S прямоугольника) Лекция 3
- 8. Комментарии к модели Можно выбрать иную схему вычислений и построить другую модель. Операции, между которыми нет
- 9. Оценки трудоемкости параллельных алгоритмов Speedup - ускорение за счёт параллельного выполнения на N процессорах (потоках) a(N)
- 10. Граф О-О и показатели эффективности для типовых задач Алгоритмы вычисления сумм Лекция 3 Общая задача -
- 11. Последовательный алгоритм S=0; S+=x1; … Возможно только последовательное выполнение, распараллеливание данного алгоритма выполнить нельзя. Лекция 3
- 12. Каскадная схема Возможно распараллеливание алгоритма суммирования Лекция 3
- 13. Оценка эффективности Количество итераций (уровней) каскадной схемы: k = log2n (на рисунке при n=4, k=2) Общее
- 14. Оценка эффективности Время выполнения на 1 процессоре (равно количеству операций): Т1 = Kпосл Время выполнения на
- 15. Улучшение каскадной схемы Цель – асимптотически ненулевая эффективность. Суть алгоритма: все суммируемые значения подразделяются на (n/log2n)
- 16. Улучшение каскадной схемы Пример при n=16: все суммируемые значения подразделяются на (n/log2n)=4 группы, в каждой из
- 17. Модифицированная каскадная схема Лекция 3
- 18. Оценка эффективности Для этапа 1 число параллельных операций k1 = log2n необходимое число процессоров р1= n/log2n
- 19. Выводы Неочевидность приемов распараллеливания Неочевидность оценок эффективности Возможность разных вариантов параллельных схем Наглядность модели на графах
- 20. Передача данных. Коммуникационная трудоемкость алгоритмов В рассмотренных оценках не учтены затраты времени на передачу данных. Основа
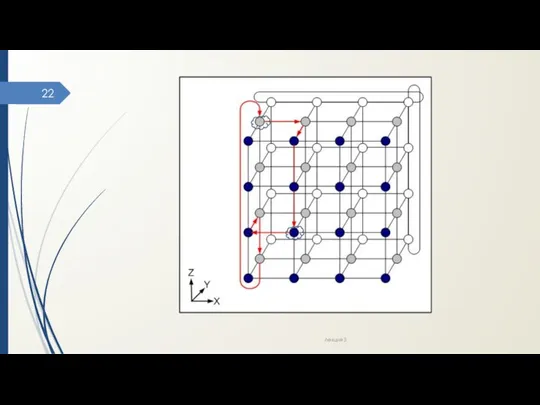
- 21. Пример оптимальных АМ Алгоритмы, основанные на покоординатной маршрутизации (dimension ordered routing) – поочередный поиск путей передачи
- 22. Лекция 3
- 23. Характеристики коммуникационной составляющей длительности выполнения параллельного алгоритма в МВС Время передачи данных определяют: Время начальной подготовки
- 24. Методы передачи данных 1. Метод передачи сообщений как неделимых блоков информации (store-and-forward routing, SFR): CPU1 Готовит
- 25. Методы передачи данных 2. Метод передачи пакетов – сообщение состоит из блоков информации (пакетов) (cut-through-routing, CTR)
- 26. Преимущества и недостатки CTR Ускоряет пересылку данных. Снижает потребность в памяти для хранения пересылаемых данных и
- 27. Классификация операций передачи данных в МВС передача данных (сообщений): между двумя CPU сети, от одного CPU
- 29. Скачать презентацию

Эффективность параллельных вычислений
Жесткие требования к эффективности определены задачами (экология, аэродинамика, геофизика,
Эффективность параллельных вычислений
Жесткие требования к эффективности определены задачами (экология, аэродинамика, геофизика,

Зачем нужны модели и их анализ?
Для разработки эффективных параллельных алгоритмов оценивают
Зачем нужны модели и их анализ?
Для разработки эффективных параллельных алгоритмов оценивают

Модель вычислений
Граф «операции – операнды» описывает алгоритм вычислений на уровне операций
Модель вычислений
Граф «операции – операнды» описывает алгоритм вычислений на уровне операций
Определение
графа «операции-операнды» (граф О-О)
Граф О-О G = (V , R)
Определение
графа «операции-операнды» (граф О-О)
Граф О-О G = (V , R)

Определение
графа «операции-операнды» (граф О-О)
G = (V , R)
V –
Определение
графа «операции-операнды» (граф О-О)
G = (V , R)
V –
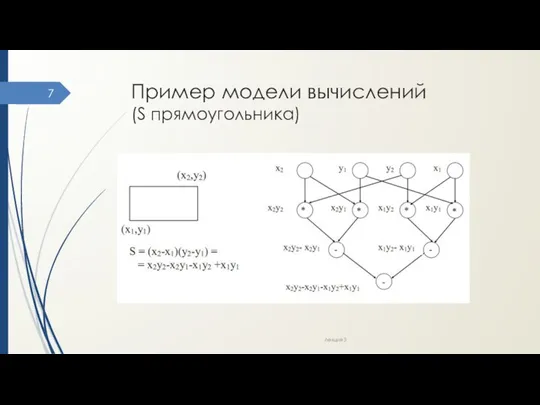
Пример модели вычислений
(S прямоугольника)
Лекция 3
Пример модели вычислений
(S прямоугольника)
Лекция 3

Комментарии к модели
Можно выбрать иную схему вычислений и построить другую модель.
Операции,
Комментарии к модели
Можно выбрать иную схему вычислений и построить другую модель.
Операции,

Оценки трудоемкости параллельных алгоритмов
Speedup - ускорение за счёт параллельного выполнения на
Оценки трудоемкости параллельных алгоритмов
Speedup - ускорение за счёт параллельного выполнения на

Граф О-О и показатели эффективности для типовых задач
Алгоритмы вычисления сумм
Лекция 3
Общая
Граф О-О и показатели эффективности для типовых задач
Алгоритмы вычисления сумм
Лекция 3
Общая

Последовательный алгоритм
S=0; S+=x1; …
Возможно только последовательное выполнение, распараллеливание данного алгоритма выполнить
Последовательный алгоритм
S=0; S+=x1; …
Возможно только последовательное выполнение, распараллеливание данного алгоритма выполнить

Каскадная схема
Возможно распараллеливание алгоритма суммирования
Лекция 3
Каскадная схема
Возможно распараллеливание алгоритма суммирования
Лекция 3

Оценка эффективности
Количество итераций (уровней) каскадной схемы:
k = log2n
(на рисунке при n=4,
Оценка эффективности
Количество итераций (уровней) каскадной схемы:
k = log2n
(на рисунке при n=4,

Оценка эффективности
Время выполнения на 1 процессоре (равно количеству операций):
Т1 = Kпосл
Время
Оценка эффективности
Время выполнения на 1 процессоре (равно количеству операций):
Т1 = Kпосл
Время

Улучшение каскадной схемы
Цель – асимптотически ненулевая эффективность.
Суть алгоритма:
все суммируемые значения подразделяются
Улучшение каскадной схемы
Цель – асимптотически ненулевая эффективность.
Суть алгоритма:
все суммируемые значения подразделяются

Улучшение каскадной схемы
Пример при n=16:
все суммируемые значения подразделяются на (n/log2n)=4 группы,
Улучшение каскадной схемы
Пример при n=16:
все суммируемые значения подразделяются на (n/log2n)=4 группы,
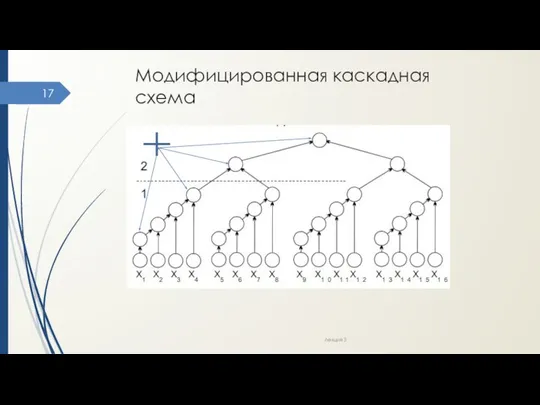
Модифицированная каскадная схема
Лекция 3
Модифицированная каскадная схема
Лекция 3

Оценка эффективности
Для этапа 1
число параллельных операций k1 = log2n
необходимое число
Оценка эффективности
Для этапа 1
число параллельных операций k1 = log2n
необходимое число

Выводы
Неочевидность приемов распараллеливания
Неочевидность оценок эффективности
Возможность разных вариантов параллельных схем
Наглядность модели на
Выводы
Неочевидность приемов распараллеливания
Неочевидность оценок эффективности
Возможность разных вариантов параллельных схем
Наглядность модели на

Передача данных.
Коммуникационная трудоемкость алгоритмов
В рассмотренных оценках не учтены затраты времени
Передача данных.
Коммуникационная трудоемкость алгоритмов
В рассмотренных оценках не учтены затраты времени

Пример оптимальных АМ
Алгоритмы, основанные на покоординатной маршрутизации (dimension ordered routing) –
Пример оптимальных АМ
Алгоритмы, основанные на покоординатной маршрутизации (dimension ordered routing) –
Лекция 3
Лекция 3

Характеристики коммуникационной составляющей длительности выполнения параллельного алгоритма в МВС
Время передачи данных
Характеристики коммуникационной составляющей длительности выполнения параллельного алгоритма в МВС
Время передачи данных

Методы передачи данных
1. Метод передачи сообщений как неделимых блоков информации (store-and-forward
Методы передачи данных
1. Метод передачи сообщений как неделимых блоков информации (store-and-forward

Методы передачи данных
2. Метод передачи пакетов – сообщение состоит из блоков
Методы передачи данных
2. Метод передачи пакетов – сообщение состоит из блоков

Преимущества и недостатки CTR
Ускоряет пересылку данных.
Снижает потребность в памяти для
Преимущества и недостатки CTR
Ускоряет пересылку данных.
Снижает потребность в памяти для

Классификация операций передачи данных в МВС
передача данных (сообщений):
между двумя CPU сети,
от
Классификация операций передачи данных в МВС
передача данных (сообщений):
между двумя CPU сети,
от
 Психосоциальная работа Обзорная лекция Дудкин А.С. 2009
Психосоциальная работа Обзорная лекция Дудкин А.С. 2009 Память в вычислительных системах
Память в вычислительных системах Презентация Основные направления деятельности ФТС на 2011-2013 годы
Презентация Основные направления деятельности ФТС на 2011-2013 годы Построение сечений
Построение сечений Агенство по организации Вашего отдыха
Агенство по организации Вашего отдыха Petrobras
Petrobras Приложение в программе DELPHI в виде теста
Приложение в программе DELPHI в виде теста Китайская Народная Республика
Китайская Народная Республика Примеры символьной обработки (язык C, лекция 9)
Примеры символьной обработки (язык C, лекция 9) Транспортная инфраструктура
Транспортная инфраструктура Объекты и типы
Объекты и типы Алгебра Алгебра Тема: «Свойства степени с натуральным показателем» Учитель Попова Ольга Николаевна
Алгебра Алгебра Тема: «Свойства степени с натуральным показателем» Учитель Попова Ольга Николаевна  Управляющие операторы языка высокого уровня. Лекция 3
Управляющие операторы языка высокого уровня. Лекция 3 Криптон Ключевая система
Криптон Ключевая система Презентация на тему "Создай себе хорошее настроение" - скачать презентации по Педагогике
Презентация на тему "Создай себе хорошее настроение" - скачать презентации по Педагогике Презентация Международное разделение труда
Презентация Международное разделение труда Рекомендации по выбору посадок
Рекомендации по выбору посадок Аллергия
Аллергия Северное Возрождение Художественная культура 15-17 вв., в странах, которые находятся севернее Италии, прежде всего: Нидерланды, Герм
Северное Возрождение Художественная культура 15-17 вв., в странах, которые находятся севернее Италии, прежде всего: Нидерланды, Герм Обзор процесса создания дочерних процессов. Стандарт ISO
Обзор процесса создания дочерних процессов. Стандарт ISO Наши установки на жизнь
Наши установки на жизнь Политическая и социогуманитарная составляющие идеологии белорусского государства
Политическая и социогуманитарная составляющие идеологии белорусского государства Архитектура и система команд Intel
Архитектура и система команд Intel Основы Спортивной Кардиологии. Внезапная Смерть В Спорте
Основы Спортивной Кардиологии. Внезапная Смерть В Спорте Новый 2019 год - год жёлтой земляной свиньи
Новый 2019 год - год жёлтой земляной свиньи Подготовили: Порошина Л.В., Анкудинова М.А., гр.Ю-102
Подготовили: Порошина Л.В., Анкудинова М.А., гр.Ю-102 Презентация Влияние петровских реформ на формирование русского менталитета
Презентация Влияние петровских реформ на формирование русского менталитета Collections and generics
Collections and generics