- Классификация вычислительных систем

Содержание
- 2. Классификация ПВС по архитектуре Архитектура ВС - общая логическая организация ВС: определяющая процесс обработки данных, включающая
- 3. Основные типы ВС по Флинну (Michael J. Flynn, Таксономия Флинна - 1966 г.) АЛГОРИТМЫ И ТЕХНОЛОГИИ
- 4. Основные типы ВС по Флинну SISD (Single Instruction Single Data) – 1 поток команд, 1 поток
- 5. Основные типы ВС по Флинну SIMD (Single Instruction Multiple Data) – 1 поток команд, много потоков
- 6. Основные типы ВС по Флинну MISD (Multiple Instruction Single Data) – много потоков команд, 1 поток
- 7. Разновидности ВС типа MIMD Дальнейшая классификация ВС – по способам организации оперативной памяти: Мультипроцессоры – ВС
- 8. Мультипроцессоры – способы построения общей памяти Единая общая память с равноправным (однородным) доступом (Uniform Memory Access,
- 9. Архитектура систем UMA АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2
- 10. Cache memory – кэш-память, кэш: промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена
- 11. Проблемы UMA. Однозначность данных Доступ с разных процессоров к общим данным ? Необходимо обеспечивать однозначность (когерентность)
- 12. Копии значения переменной x – в разных кэшах ? Возможно изменение х одним из процессоров. АЛГОРИТМЫ
- 13. Проблемы UMA. Синхронизация Доступ с разных процессоров к общим данным ? Необходимость синхронизации взаимодействия одновременно выполняемых
- 14. Синхронизация. Семафор Семафор – системный объект, с набором методов. В C/C++, C# можно работать с семафорами
- 15. Синхронизация. Мьютекс Мьютекс – системный объект, с набором методов. В C/C++, C# можно работать с мьютексами
- 16. Синхронизация. Критические секции Критическая секция - участок кода, который может одномоментно выполнять только один поток. В
- 17. Синхронизация. События Событие - объект, который может быть в состоянии нейтральном или сигнализирующем. Поток может ждать
- 18. Мультипроцессоры – способы построения общей памяти 2. Физически распределенная общая память с неравноправным (неоднородным) доступом (Non-Uniform
- 19. Архитектура систем NUMA АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2
- 20. NUMA системы Для данных используются только локальные кэши процессоров – нет общей памяти => нет проблемы
- 21. Мультикомпьютеры МК – ВС с распределенной памятью самостоятельных компьютеров, объединенных в сеть МК – системы типа
- 22. Основные типы МК – многопроцессорных вычислительных систем Массивно (массово)-параллельные системы, MPP-системы (Massively Parallel Processing – массово-параллельная
- 23. Основные типы МК – многопроцессорных вычислительных систем Кластер - набор рабочих станций (или даже ПК) общего
- 24. Классификация многопроцессорных ВС (подробно см. http://parallel.ru/computers/classes.html) АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2
- 25. Коммуникация в МВС Коммуникация между процессорами обеспечивает: взаимодействие, синхронизацию, взаимоисключения выполняемых процессов ? Коммуникационная «трудоемкость» алгоритма
- 26. Примеры топологий сетей в МВС АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2
- 27. Особенности топологий сетей передачи данных Тип - Преимущества - Реализация Полный граф – минимум затрат на
- 28. Характеристики топологий сети Диаметр – определяет время передачи данных через max расстояние между 2 CPU сети
- 30. Скачать презентацию

Классификация ПВС по архитектуре
Архитектура ВС - общая логическая организация ВС:
Классификация ПВС по архитектуре
Архитектура ВС - общая логическая организация ВС:
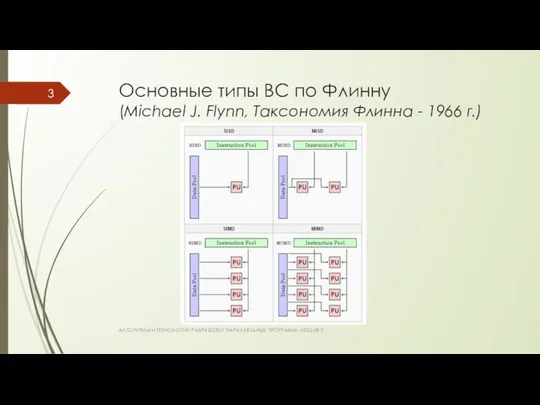
Основные типы ВС по Флинну
(Michael J. Flynn, Таксономия Флинна -
Основные типы ВС по Флинну (Michael J. Flynn, Таксономия Флинна -

Основные типы ВС по Флинну
SISD (Single Instruction Single Data) –
Основные типы ВС по Флинну
SISD (Single Instruction Single Data) –

Основные типы ВС по Флинну
SIMD (Single Instruction Multiple Data) –
Основные типы ВС по Флинну
SIMD (Single Instruction Multiple Data) –

Основные типы ВС по Флинну
MISD (Multiple Instruction Single Data) – много
Основные типы ВС по Флинну
MISD (Multiple Instruction Single Data) – много

Разновидности ВС типа MIMD
Дальнейшая классификация ВС – по способам организации оперативной
Разновидности ВС типа MIMD
Дальнейшая классификация ВС – по способам организации оперативной

Мультипроцессоры –
способы построения общей памяти
Единая общая память с равноправным (однородным)
Мультипроцессоры –
способы построения общей памяти
Единая общая память с равноправным (однородным)
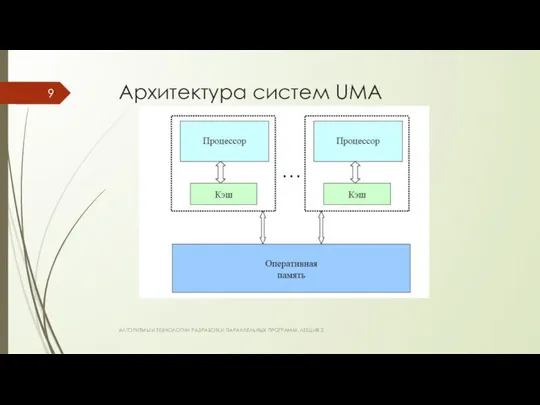
Архитектура систем UMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2
Архитектура систем UMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2

Cache memory – кэш-память, кэш:
промежуточный буфер с быстрым доступом, содержащий информацию, которая
Cache memory – кэш-память, кэш: промежуточный буфер с быстрым доступом, содержащий информацию, которая

Проблемы UMA. Однозначность данных
Доступ с разных процессоров к общим данным ?
Необходимо
Проблемы UMA. Однозначность данных
Доступ с разных процессоров к общим данным ?
Необходимо
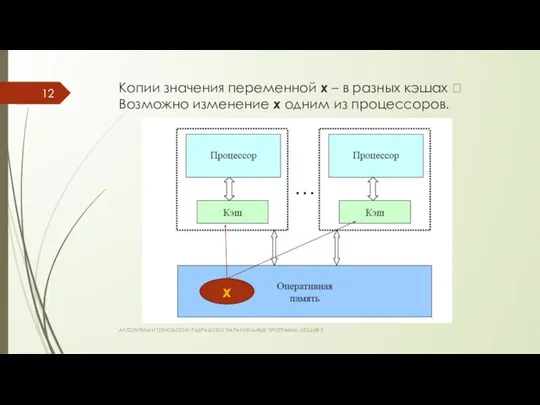
Копии значения переменной x – в разных кэшах ? Возможно изменение
Копии значения переменной x – в разных кэшах ? Возможно изменение

Проблемы UMA. Синхронизация
Доступ с разных процессоров к общим данным ?
Необходимость синхронизации
Проблемы UMA. Синхронизация
Доступ с разных процессоров к общим данным ?
Необходимость синхронизации

Синхронизация. Семафор
Семафор – системный объект,
с набором методов.
В C/C++, C# можно
Синхронизация. Семафор
Семафор – системный объект,
с набором методов.
В C/C++, C# можно

Синхронизация. Мьютекс
Мьютекс – системный объект,
с набором методов.
В C/C++, C# можно
Синхронизация. Мьютекс
Мьютекс – системный объект,
с набором методов.
В C/C++, C# можно

Синхронизация. Критические секции
Критическая секция - участок кода, который может одномоментно выполнять
Синхронизация. Критические секции
Критическая секция - участок кода, который может одномоментно выполнять

Синхронизация. События
Событие - объект, который может быть
в состоянии нейтральном или
Синхронизация. События
Событие - объект, который может быть в состоянии нейтральном или

Мультипроцессоры –
способы построения общей памяти
2. Физически распределенная общая память с
Мультипроцессоры –
способы построения общей памяти
2. Физически распределенная общая память с
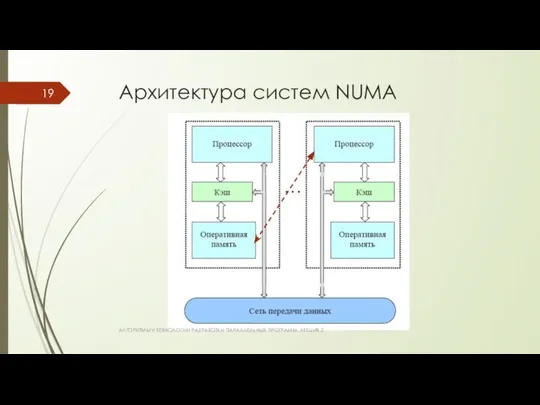
Архитектура систем NUMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2
Архитектура систем NUMA
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ 2

NUMA системы
Для данных используются только локальные кэши процессоров – нет общей
NUMA системы
Для данных используются только локальные кэши процессоров – нет общей

Мультикомпьютеры
МК – ВС с распределенной памятью самостоятельных компьютеров, объединенных в сеть
МК
Мультикомпьютеры
МК – ВС с распределенной памятью самостоятельных компьютеров, объединенных в сеть
МК

Основные типы МК – многопроцессорных вычислительных систем
Массивно (массово)-параллельные системы, MPP-системы (Massively
Основные типы МК – многопроцессорных вычислительных систем
Массивно (массово)-параллельные системы, MPP-системы (Massively

Основные типы МК – многопроцессорных вычислительных систем
Кластер - набор рабочих станций
Основные типы МК – многопроцессорных вычислительных систем
Кластер - набор рабочих станций
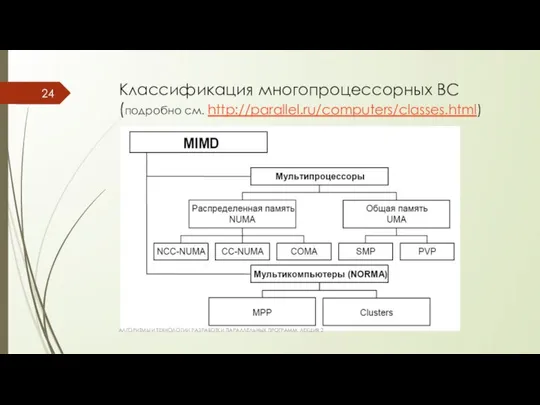
Классификация многопроцессорных ВС
(подробно см. http://parallel.ru/computers/classes.html)
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ
Классификация многопроцессорных ВС
(подробно см. http://parallel.ru/computers/classes.html)
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ

Коммуникация в МВС
Коммуникация между процессорами обеспечивает:
взаимодействие, синхронизацию, взаимоисключения выполняемых процессов
Коммуникация в МВС
Коммуникация между процессорами обеспечивает:
взаимодействие, синхронизацию, взаимоисключения выполняемых процессов
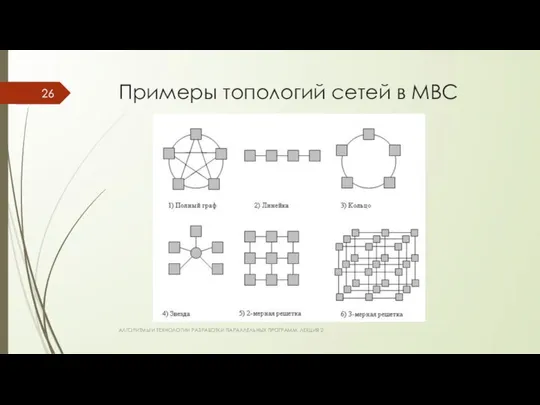
Примеры топологий сетей в МВС
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ
Примеры топологий сетей в МВС
АЛГОРИТМЫ И ТЕХНОЛОГИИ РАЗРАБОТКИ ПАРАЛЛЕЛЬНЫХ ПРОГРАММ. ЛЕКЦИЯ

Особенности топологий сетей передачи данных
Тип - Преимущества - Реализация
Полный граф – минимум
Особенности топологий сетей передачи данных
Тип - Преимущества - Реализация
Полный граф – минимум

Характеристики топологий сети
Диаметр – определяет время передачи данных через max расстояние
Характеристики топологий сети
Диаметр – определяет время передачи данных через max расстояние
 Курсовая работа «Религиозный радикализм: государственно-общественное регулирование»
Курсовая работа «Религиозный радикализм: государственно-общественное регулирование» Компьютерная графика
Компьютерная графика Органы мочевой системы
Органы мочевой системы  Benjamin Franklin (1706-1790)
Benjamin Franklin (1706-1790) Аудитория Уанета Январь 2011 г. gemiusAudience
Аудитория Уанета Январь 2011 г. gemiusAudience An american summer
An american summer Презентация "Театр и музыка Древней Греции (10 класс)" - скачать презентации по МХК
Презентация "Театр и музыка Древней Греции (10 класс)" - скачать презентации по МХК Введение в направление подготовки: местное самоуправление
Введение в направление подготовки: местное самоуправление Изобразительное искусство романтизма
Изобразительное искусство романтизма Основные особенности управленческой деятельности Планирование воспитательной деятельности в образовательном учреждении
Основные особенности управленческой деятельности Планирование воспитательной деятельности в образовательном учреждении Техническое обслуживание и ремонт газораспределительного механизма двигателя А-41
Техническое обслуживание и ремонт газораспределительного механизма двигателя А-41 150 культур Дона
150 культур Дона Религия. Иудаизм
Религия. Иудаизм Звіт про роботу в конкурсах - презентация для начальной школы_
Звіт про роботу в конкурсах - презентация для начальной школы_ запросы в БД
запросы в БД  Гимнастика. Виды гимнастики
Гимнастика. Виды гимнастики Понятие и признаки правоотношений
Понятие и признаки правоотношений Государственные символы России. Герб. Флаг. Гимн России
Государственные символы России. Герб. Флаг. Гимн России Экспериментальный сад «Лоулайн Лэб» (Lowline Lab)
Экспериментальный сад «Лоулайн Лэб» (Lowline Lab) Гимнастика, часть физической культуры
Гимнастика, часть физической культуры Негізгі және қосымша шағымдарын анықтау
Негізгі және қосымша шағымдарын анықтау Презентация по алгебре Линейные уравнения с одной переменной 7 класс
Презентация по алгебре Линейные уравнения с одной переменной 7 класс Dativ
Dativ Basics of software development O. Fedorova, associate professor of Department PMI
Basics of software development O. Fedorova, associate professor of Department PMI ПРЕЗЕНТАЦИЯ НА ТЕМУ: «СИСТЕМА ВЫСШЕГО ОБРАЗОВАНИЯ ВЕЛИКОБРИТАНИИ».
ПРЕЗЕНТАЦИЯ НА ТЕМУ: «СИСТЕМА ВЫСШЕГО ОБРАЗОВАНИЯ ВЕЛИКОБРИТАНИИ». Зачем нужен менеджер продукта при живом проектировщике интерфейсов? Денис Бесков / http://beskov.ru World Usability Day, Москва, 2011
Зачем нужен менеджер продукта при живом проектировщике интерфейсов? Денис Бесков / http://beskov.ru World Usability Day, Москва, 2011 Канализация электроэнергии на напряжении выше 1 кВ
Канализация электроэнергии на напряжении выше 1 кВ Презентация "Рембрандт ван Рейн (1606-1669)" - скачать презентации по МХК
Презентация "Рембрандт ван Рейн (1606-1669)" - скачать презентации по МХК