- Моделирование и анализ параллельных вычислений.

Содержание
- 2. Оценка трудоемкости операции передачи данных между 2 узлами кластера Подход 1: tн не зависит от объема
- 3. Оценка трудоемкости операции передачи данных между 2 узлами кластера Подход 2: Учитывается n - число пакетов,
- 4. Оценка трудоемкости операции передачи данных между 2 узлами кластера Предполагается Подготовка данных для 2,3, … пакетов
- 5. Оценка трудоемкости операции передачи данных между 2 узлами кластера Подход 2 – итоговое соотношение
- 6. Оценка трудоемкости операции передачи данных между 2 узлами кластера Подход 3 (упрощение подхода 1) – модель
- 7. Этапы разработки параллельных алгоритмов (распараллеливания) 1. Анализ общей схемы вычислений - для разделения на независимые (относительно)
- 8. Дополнительные предположения Равномерность загрузки всех CPU (балансировка). Минимизация коммуникационных взаимодействий между подзадачами. Возможность пересмотра шагов после
- 9. Этап 1 разработки параллельных алгоритмов 1. Разделение вычислений на независимые подзадачи Требования к подзадачам: Равные объемы
- 10. Два основных типа вычислительных схем, основанных на разделении данных: Ленточная схема Блочная схема
- 11. Сфера применимости – однотипная обработка большого набора данных: Матричные вычисления Численные методы решения уравнений в частных
- 12. Сетки, или решетки
- 13. Выполнение разных операций над одним набором данных – функциональный параллелизм Обработка разных запросов к БД Одновременное
- 14. Этап 2 разработки параллельных алгоритмов 2. Выделение информационных зависимостей Взаимосвязан с этапом 1: Выделение подзадач должно
- 15. Формы информационного взаимодействия Схемы передачи данных: Локальные – обмен для части подзадач (как правило, на соседних
- 16. Формы информационного взаимодействия Схемы передачи данных: Синхронные – операции передачи данных начинают выполняться только при готовности
- 17. Этап 3 разработки параллельных алгоритмов 3. Масштабирование Необходимо, если число подзадач ≠ количеству CPU Типы масштабирования:
- 18. Агрегация Укрупнение вычислений для уменьшения числа подзадач. В результате должно соблюдаться (см. этап 1) : Одинаковая
- 19. Декомпозиция Детализация вычислений (увеличение числа подзадач) для загрузки всех доступных CPU. Декомпозиция выполняется до базовых задач
- 20. Этап 4 разработки параллельных алгоритмов 4. Распределение подзадач между CPU. Необходимо для МВС с распределенной памятью.
- 21. Практические рекомендации Анализируем задачу для выделения подзадач, которые могут выполняться одновременно Изменяем структуру задачи для эффективного
- 22. Технологии параллельного программирования В основе может быть: Язык параллельного программирования. Прикладной программный интерфейс (API), реализованный с
- 23. Примеры технологий ПП OpenMP: директивы компилятора для простого параллельного программирования. MPI: библиотечные подпрограммы для реализации высокоэффективной
- 24. 3. Основы технологии OpenMP. Модель «fork-join». Классификация переменных. Основные директивы и их опции. Распараллеливание по данным
- 25. Технология разработки параллельных программ для МВС с общей памятью (OpenMP) OpenMP (Open Multi-Processing) — открытый развивающийся
- 26. Модель программирования OpenMP Разветвление-объединение (fork-join) Работа программы начинается с одного (корневого) потока, или нити (thread –
- 28. Скачать презентацию

Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 1:
tн
Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 1:
tн

Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 2:
Учитывается
Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 2:
Учитывается

Оценка трудоемкости операции передачи данных между 2 узлами кластера
Предполагается
Подготовка данных
Оценка трудоемкости операции передачи данных между 2 узлами кластера
Предполагается
Подготовка данных

Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 2
Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 2

Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 3
Оценка трудоемкости операции передачи данных между 2 узлами кластера
Подход 3

Этапы разработки параллельных алгоритмов (распараллеливания)
1. Анализ общей схемы вычислений -
для
Этапы разработки параллельных алгоритмов (распараллеливания)
1. Анализ общей схемы вычислений - для

Дополнительные предположения
Равномерность загрузки всех CPU (балансировка).
Минимизация коммуникационных взаимодействий между подзадачами.
Возможность пересмотра
Дополнительные предположения
Равномерность загрузки всех CPU (балансировка).
Минимизация коммуникационных взаимодействий между подзадачами.
Возможность пересмотра
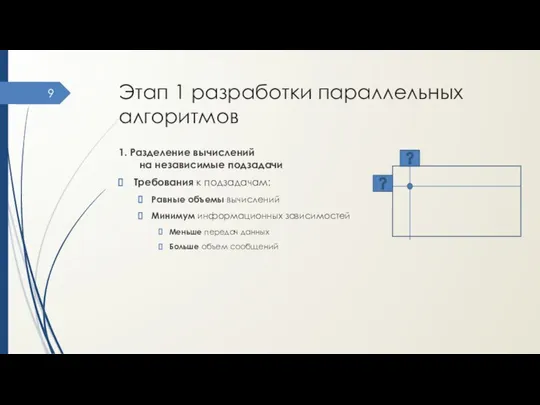
Этап 1 разработки параллельных алгоритмов
1. Разделение вычислений на независимые подзадачи
Требования
Этап 1 разработки параллельных алгоритмов
1. Разделение вычислений на независимые подзадачи
Требования
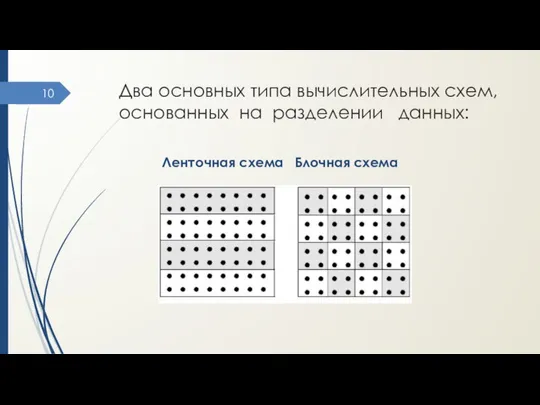
Два основных типа вычислительных схем, основанных на разделении данных:
Ленточная схема Блочная
Два основных типа вычислительных схем, основанных на разделении данных:
Ленточная схема Блочная

Сфера применимости – однотипная обработка большого набора данных:
Матричные вычисления
Численные методы решения
Сфера применимости – однотипная обработка большого набора данных:
Матричные вычисления
Численные методы решения
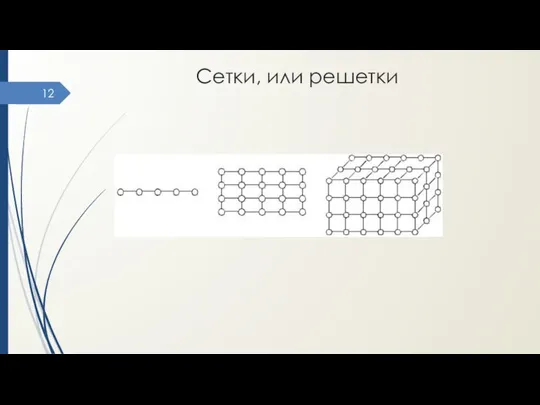
Сетки, или решетки
Сетки, или решетки

Выполнение разных операций над одним набором данных –
функциональный параллелизм
Обработка разных
Выполнение разных операций над одним набором данных –
функциональный параллелизм
Обработка разных

Этап 2 разработки параллельных алгоритмов
2. Выделение информационных зависимостей
Взаимосвязан с этапом 1:
Выделение
Этап 2 разработки параллельных алгоритмов
2. Выделение информационных зависимостей
Взаимосвязан с этапом 1:
Выделение

Формы информационного взаимодействия
Схемы передачи данных:
Локальные – обмен для части подзадач
(как
Формы информационного взаимодействия
Схемы передачи данных:
Локальные – обмен для части подзадач
(как

Формы информационного взаимодействия
Схемы передачи данных:
Синхронные –
операции передачи данных
начинают выполняться
Формы информационного взаимодействия
Схемы передачи данных:
Синхронные –
операции передачи данных
начинают выполняться

Этап 3 разработки параллельных алгоритмов
3. Масштабирование
Необходимо, если
число подзадач ≠ количеству
Этап 3 разработки параллельных алгоритмов
3. Масштабирование
Необходимо, если
число подзадач ≠ количеству

Агрегация
Укрупнение вычислений для уменьшения числа подзадач.
В результате должно соблюдаться
(см. этап
Агрегация
Укрупнение вычислений для уменьшения числа подзадач.
В результате должно соблюдаться
(см. этап

Декомпозиция
Детализация вычислений (увеличение числа подзадач) для загрузки всех доступных CPU.
Декомпозиция выполняется
Декомпозиция
Детализация вычислений (увеличение числа подзадач) для загрузки всех доступных CPU.
Декомпозиция выполняется

Этап 4 разработки параллельных алгоритмов
4. Распределение подзадач между CPU.
Необходимо для
Этап 4 разработки параллельных алгоритмов
4. Распределение подзадач между CPU.
Необходимо для

Практические рекомендации
Анализируем задачу для выделения подзадач, которые могут выполняться одновременно
Изменяем структуру
Практические рекомендации
Анализируем задачу для выделения подзадач, которые могут выполняться одновременно
Изменяем структуру

Технологии параллельного программирования
В основе может быть:
Язык параллельного программирования.
Прикладной программный интерфейс (API),
Технологии параллельного программирования
В основе может быть:
Язык параллельного программирования.
Прикладной программный интерфейс (API),

Примеры технологий ПП
OpenMP: директивы компилятора для простого параллельного программирования.
MPI: библиотечные подпрограммы
Примеры технологий ПП
OpenMP: директивы компилятора для простого параллельного программирования.
MPI: библиотечные подпрограммы

3. Основы технологии OpenMP.
Модель «fork-join».
Классификация переменных.
Основные директивы и
3. Основы технологии OpenMP.
Модель «fork-join».
Классификация переменных.
Основные директивы и

Технология разработки параллельных программ для МВС с общей памятью (OpenMP)
OpenMP (Open Multi-Processing) —
Технология разработки параллельных программ для МВС с общей памятью (OpenMP)
OpenMP (Open Multi-Processing) —

Модель программирования OpenMP
Разветвление-объединение (fork-join)
Работа программы начинается с одного (корневого) потока, или
Модель программирования OpenMP
Разветвление-объединение (fork-join)
Работа программы начинается с одного (корневого) потока, или
 Махмұт Қашқари
Махмұт Қашқари Динара 4пая1 орыс т (1)
Динара 4пая1 орыс т (1) Цели и принципы кредитно-денежной политики Подготовила студентка ФТД-4 группы Т-103 Лепичева Наталия
Цели и принципы кредитно-денежной политики Подготовила студентка ФТД-4 группы Т-103 Лепичева Наталия Sevilla
Sevilla Договор проката Подготовил: студент Группы Ю-092 Виноградская Екатерина
Договор проката Подготовил: студент Группы Ю-092 Виноградская Екатерина Презентация Авиационная промышленность. Рынок гражданской авиации
Презентация Авиационная промышленность. Рынок гражданской авиации  Планирование на предприятии
Планирование на предприятии Этические нормы СО. Выполнила:
Этические нормы СО. Выполнила: ООП. Часть 3. Полиморфизм
ООП. Часть 3. Полиморфизм Кто такие октябрята? - презентация для начальной школы_
Кто такие октябрята? - презентация для начальной школы_ Влияние питания
Влияние питания Терроризм
Терроризм Понятие абсентеизма на предприятии и способы его снижения
Понятие абсентеизма на предприятии и способы его снижения Jesus raises a widow’s son in Nain
Jesus raises a widow’s son in Nain Стартап. Мета та завдання стартапів. Відмінні особливості стартапів
Стартап. Мета та завдання стартапів. Відмінні особливості стартапів Проектное фото жилого комплекса
Проектное фото жилого комплекса Правописание ЧА – ЩА, ЧУ – ЩУ - презентация для начальной школы
Правописание ЧА – ЩА, ЧУ – ЩУ - презентация для начальной школы Регистрация юридических лиц
Регистрация юридических лиц Забойные двигатели: Типы, классификация, устройство. Монтаж и эксплуатация бурового оборудования. Лекция 4
Забойные двигатели: Типы, классификация, устройство. Монтаж и эксплуатация бурового оборудования. Лекция 4 Міжнародний тероризм
Міжнародний тероризм Записи в мові Паскаль. Множини. Оператор приєднання WITH
Записи в мові Паскаль. Множини. Оператор приєднання WITH ПРЕЗЕНТАЦИЯ набор в ВУЦ
ПРЕЗЕНТАЦИЯ набор в ВУЦ Роль развития профессионализма учителя в повышении показателей ГИА
Роль развития профессионализма учителя в повышении показателей ГИА Мониторы
Мониторы  Places of Interest in Russia
Places of Interest in Russia Финансовый контроль
Финансовый контроль Средства объектно-ориентированного программирования (Delphi / Pascal, глава 7)
Средства объектно-ориентированного программирования (Delphi / Pascal, глава 7) Понятие ЕСЭ. Принципы построения ССОП и АТС
Понятие ЕСЭ. Принципы построения ССОП и АТС