- Обзор программируемых логических интегральных схем и интегральных схем гибкой логики

Содержание
- 2. Интерфейс программирования и тестирования JTAG/IEEE 1149.1 Рис. 1.2 Соединение 4 БИС интерфейсом тестирования. При этом регистры
- 3. Интерфейс программирования и тестирования JTAG/IEEE 1149.1 Рис. 1.3. Структурная схема порта тестирования и программирования. Контроллер JTAG
- 4. Интерфейс программирования и тестирования JTAG/IEEE 1149.1 Рис. 1.4. Ячейки периферийного тестирования. С точки зрения контроллера JTAG
- 5. КЛАССИФИКАЦИЯ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ЦИФРОВЫХ ВЫЧИСЛИТЕЛЕЙ
- 6. Векторные команды и матричная вычислительная система Векторные команды задают операции над элементами одного или нескольких векторов.
- 7. Конвейеризация вычислений и организация векторных вычислителей класса ОКМД таблица занятости конвейера
- 8. Основы проектирования аппаратных средств конвейерных вычислителей При проектировании конвейерных устройств, следует обратить внимание на логическое проектирование
- 9. Основы проектирования аппаратных средств конвейерных вычислителей Таким образом, условие правильного функционирования логики ступени конвейера: Tmax W
- 10. Основы проектирования аппаратных средств конвейерных вычислителей Второй метод пакетирования СИ использует временную цепь передачи, которая включает
- 11. Основы проектирования аппаратных средств конвейерных вычислителей
- 12. Многопроцессорные комплексы Вычислительные алгоритмы на основе ряда слабосвязанных потоков команд и данных реализуются в многопроцессорных комплексах
- 13. Многопроцессорные комплексы Для снижения требований по быстродействию к общему ОЗУ при реализации первого механизма, помимо общей,
- 14. Многопроцессорные комплексы Два фактора ограничивают производительность таких комплексов: ‑ организация связей между элементами комплекса, практически каждый
- 15. Вычислители, управляемые потоками данных К архитектуре МКМД вычислителей относятся потоковые параллельные вычислители, или устройства, управляемые потоками
- 16. ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ Скоростные параллельные вычислители на несколько порядков опережают по быстродействию системы динамического
- 17. ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ Другая причина усложнения систем ОЗУ в высокопроизводительных вычислителях - повышенные требования
- 18. ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ При обращении вычислителя к КЭШ - памяти аппаратура КЭШа сравнивает параллельно
- 19. ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
- 20. Особенности архитектуры универсальных производительных микропроцессоров Рис. 6.1 Структура исполнительных блоков Pentium III
- 21. Особенности архитектуры универсальных производительных микропроцессоров Выигрыш в производительности при таком подходе происходит при выполнении условных циклов,
- 22. Особенности архитектуры универсальных производительных микропроцессоров . Пока отсутствуют команды ветвлений, последовательность команд загружается в первую очередь.
- 23. Цифровые сигнальные процессоры. Рис. 7.1. Архитектура DSP56001
- 24. Цифровые сигнальные процессоры. Рис. 7.2. Архитектура TMS320C40
- 25. Цифровые сигнальные процессоры. На рис. 7.3 показан вариант топологии связей процессоров. Рис. 7.3. Топология связей ЦСП
- 27. Скачать презентацию

Интерфейс программирования и тестирования JTAG/IEEE 1149.1
Рис. 1.2 Соединение 4 БИС
Интерфейс программирования и тестирования JTAG/IEEE 1149.1
Рис. 1.2 Соединение 4 БИС
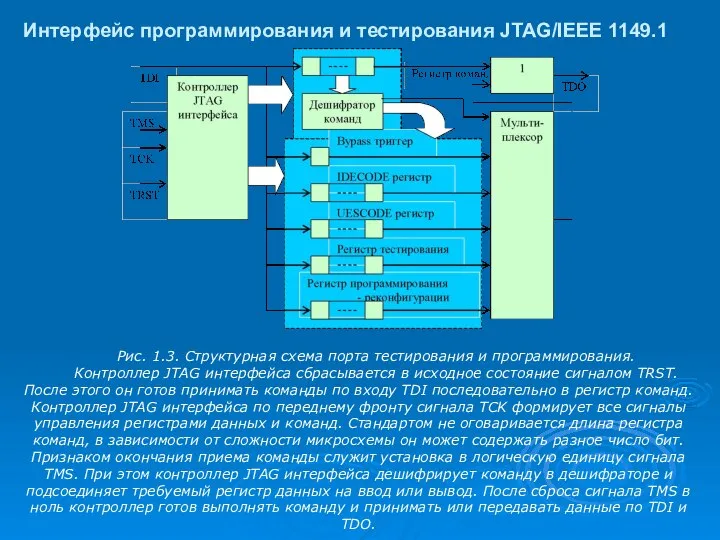
Интерфейс программирования и тестирования JTAG/IEEE 1149.1
Рис. 1.3. Структурная схема порта
Интерфейс программирования и тестирования JTAG/IEEE 1149.1
Рис. 1.3. Структурная схема порта
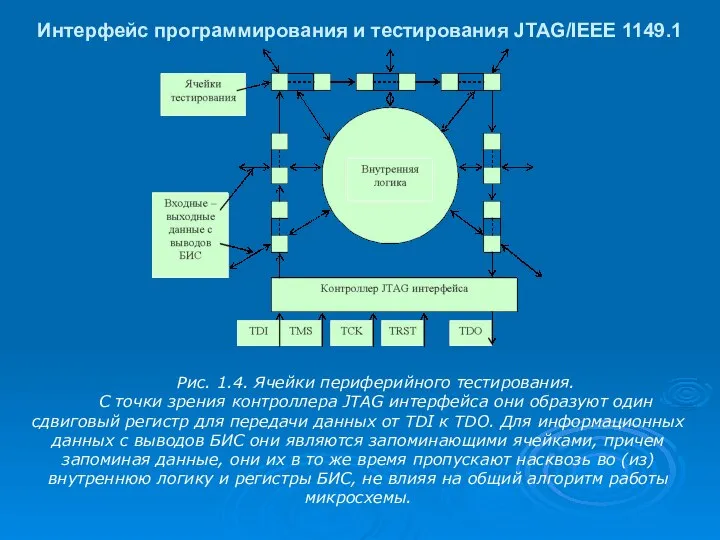
Интерфейс программирования и тестирования JTAG/IEEE 1149.1
Рис. 1.4. Ячейки периферийного тестирования.
С
Интерфейс программирования и тестирования JTAG/IEEE 1149.1
Рис. 1.4. Ячейки периферийного тестирования.
С
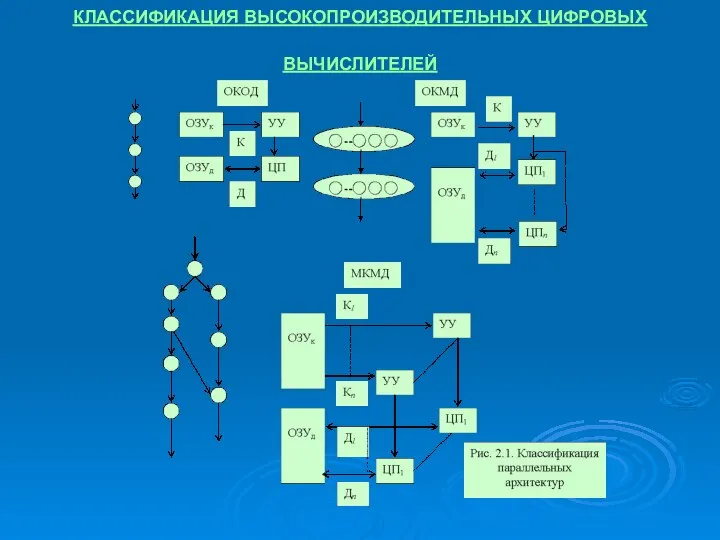
КЛАССИФИКАЦИЯ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ЦИФРОВЫХ ВЫЧИСЛИТЕЛЕЙ
КЛАССИФИКАЦИЯ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ЦИФРОВЫХ ВЫЧИСЛИТЕЛЕЙ
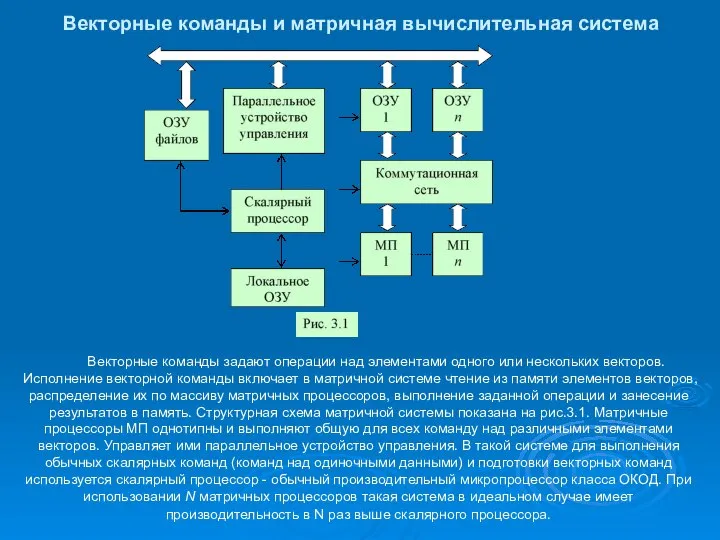
Векторные команды и матричная вычислительная система
Векторные команды задают операции над
Векторные команды и матричная вычислительная система
Векторные команды задают операции над
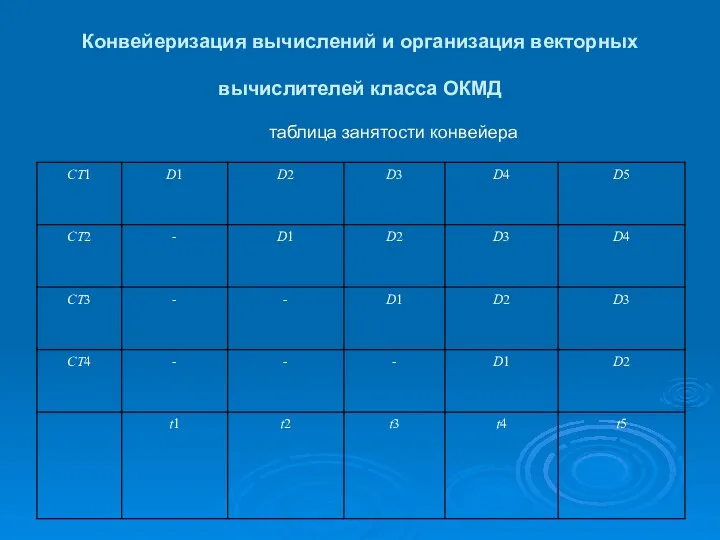
Конвейеризация вычислений и организация векторных вычислителей класса ОКМД
таблица занятости конвейера
Конвейеризация вычислений и организация векторных вычислителей класса ОКМД
таблица занятости конвейера
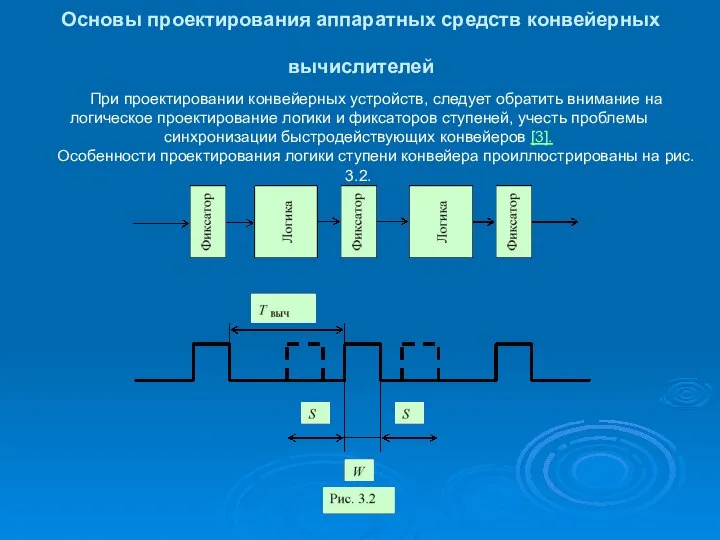
Основы проектирования аппаратных средств конвейерных вычислителей
При проектировании конвейерных устройств, следует
Основы проектирования аппаратных средств конвейерных вычислителей
При проектировании конвейерных устройств, следует
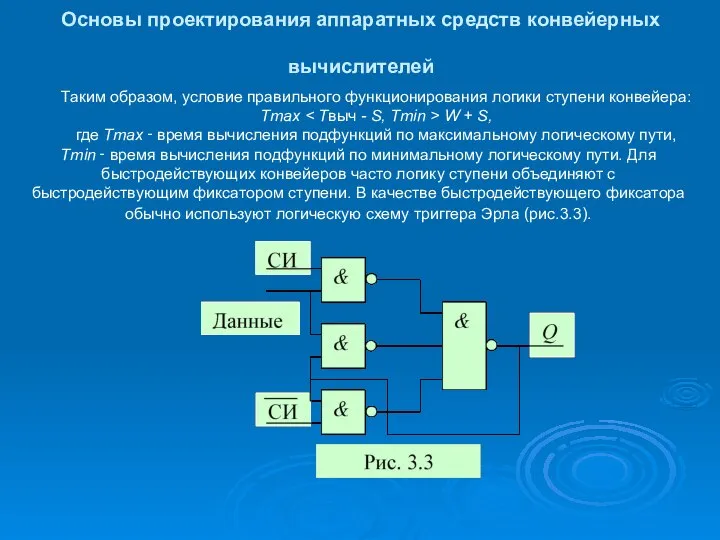
Основы проектирования аппаратных средств конвейерных вычислителей
Таким образом, условие правильного функционирования
Основы проектирования аппаратных средств конвейерных вычислителей
Таким образом, условие правильного функционирования
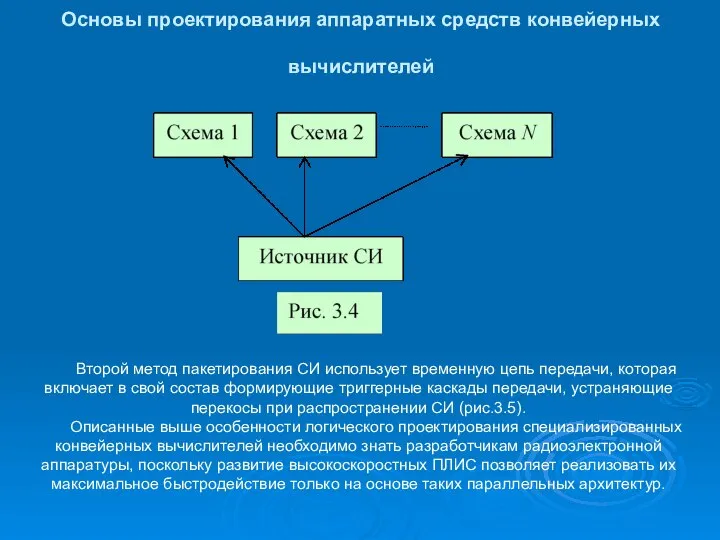
Основы проектирования аппаратных средств конвейерных вычислителей
Второй метод пакетирования СИ использует
Основы проектирования аппаратных средств конвейерных вычислителей
Второй метод пакетирования СИ использует
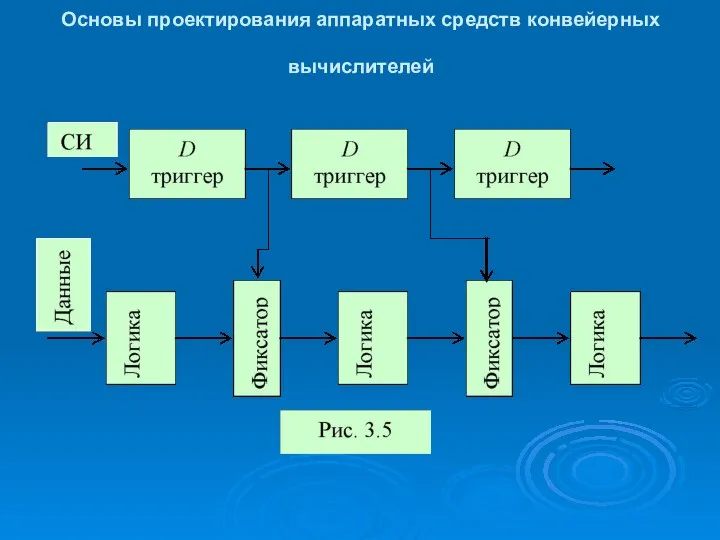
Основы проектирования аппаратных средств конвейерных вычислителей
Основы проектирования аппаратных средств конвейерных вычислителей

Многопроцессорные комплексы
Вычислительные алгоритмы на основе ряда слабосвязанных потоков команд и
Многопроцессорные комплексы
Вычислительные алгоритмы на основе ряда слабосвязанных потоков команд и
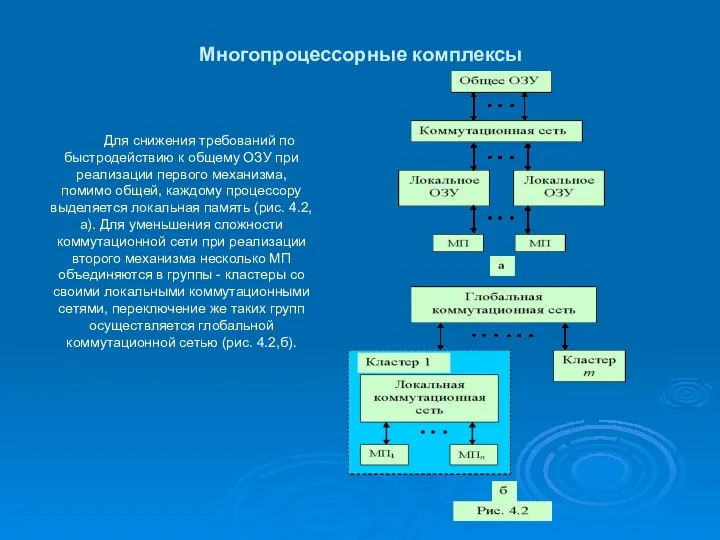
Многопроцессорные комплексы
Для снижения требований по быстродействию к общему ОЗУ при
Многопроцессорные комплексы
Для снижения требований по быстродействию к общему ОЗУ при
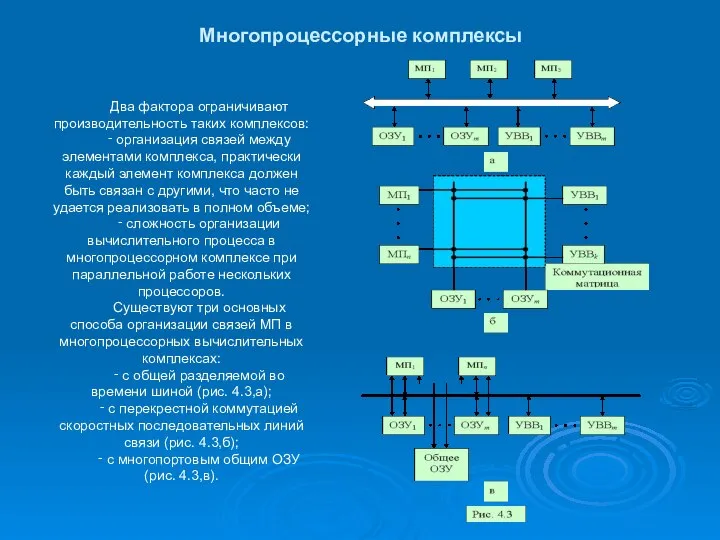
Многопроцессорные комплексы
Два фактора ограничивают производительность таких комплексов:
‑ организация связей между
Многопроцессорные комплексы
Два фактора ограничивают производительность таких комплексов:
‑ организация связей между
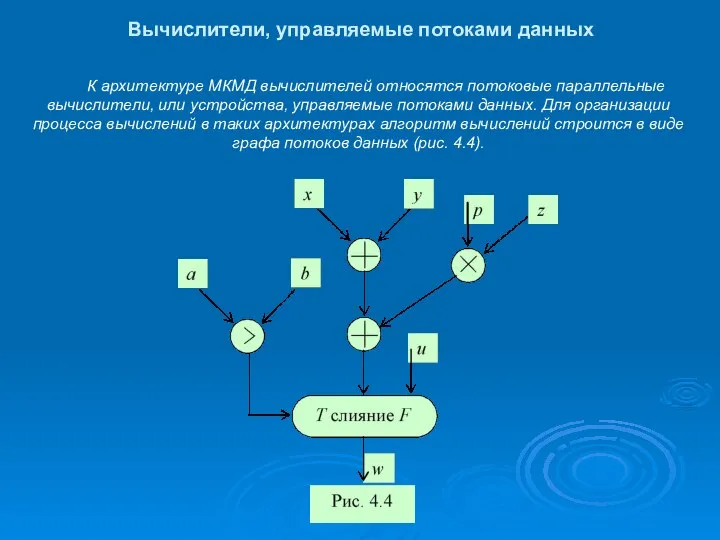
Вычислители, управляемые потоками данных
К архитектуре МКМД вычислителей относятся потоковые параллельные
Вычислители, управляемые потоками данных
К архитектуре МКМД вычислителей относятся потоковые параллельные
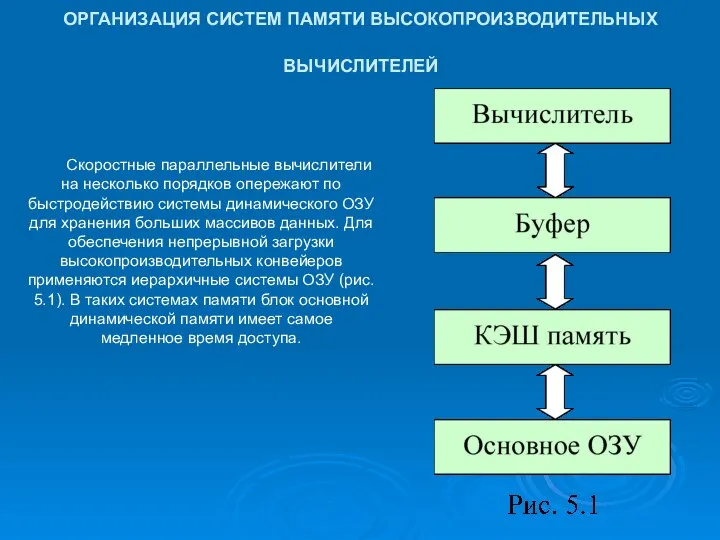
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
Скоростные параллельные вычислители на несколько порядков
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
Скоростные параллельные вычислители на несколько порядков
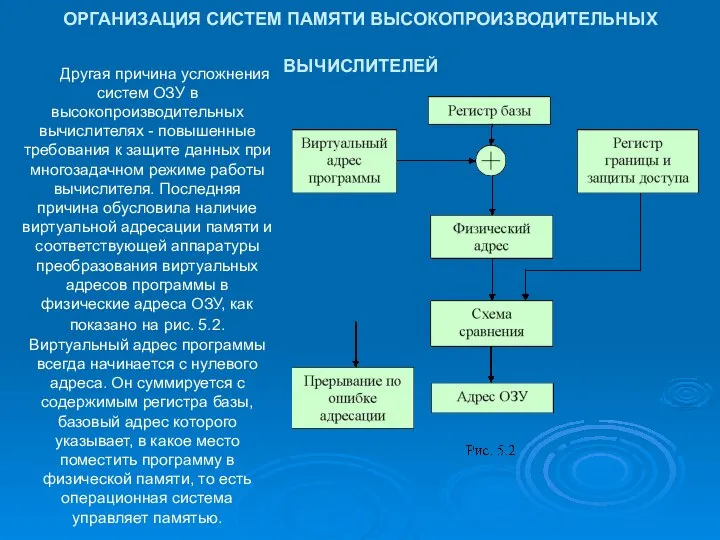
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
Другая причина усложнения систем ОЗУ в
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
Другая причина усложнения систем ОЗУ в
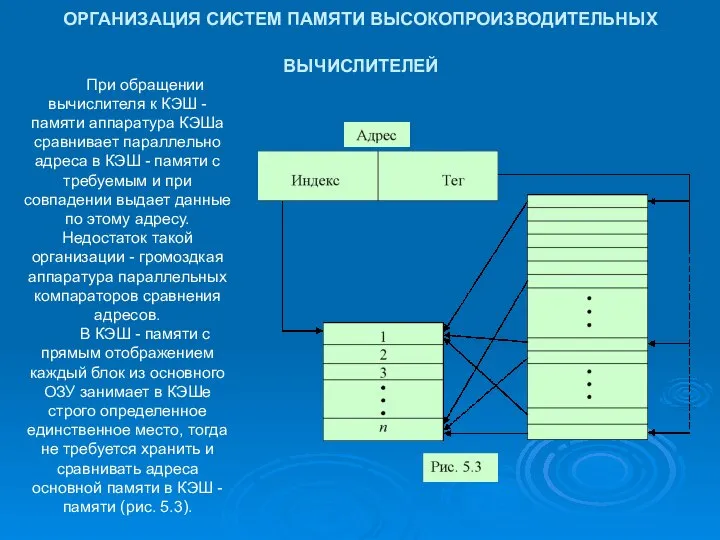
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
При обращении вычислителя к КЭШ -
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
При обращении вычислителя к КЭШ -
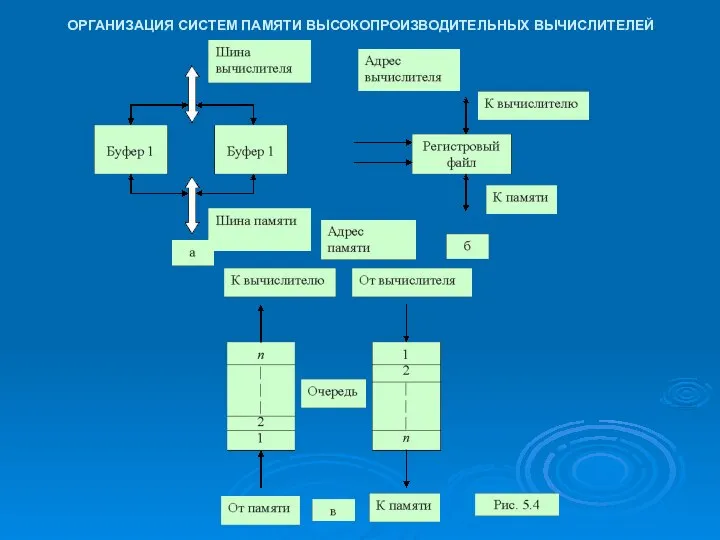
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
ОРГАНИЗАЦИЯ СИСТЕМ ПАМЯТИ ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЕЙ
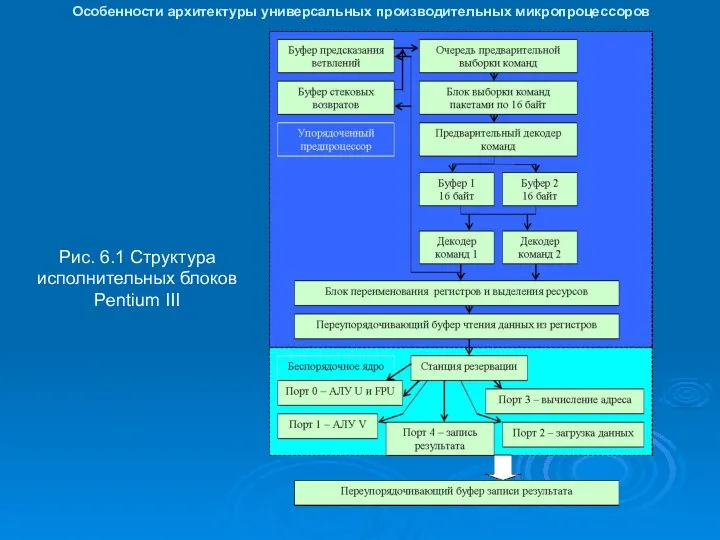
Особенности архитектуры универсальных производительных микропроцессоров
Рис. 6.1 Структура исполнительных блоков Pentium
Особенности архитектуры универсальных производительных микропроцессоров
Рис. 6.1 Структура исполнительных блоков Pentium

Особенности архитектуры универсальных производительных микропроцессоров
Выигрыш в производительности при таком подходе
Особенности архитектуры универсальных производительных микропроцессоров
Выигрыш в производительности при таком подходе
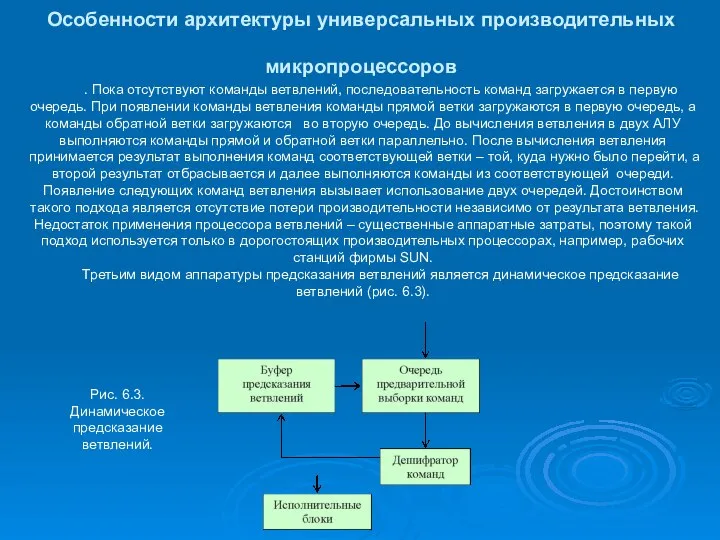
Особенности архитектуры универсальных производительных микропроцессоров
. Пока отсутствуют команды ветвлений, последовательность
Особенности архитектуры универсальных производительных микропроцессоров
. Пока отсутствуют команды ветвлений, последовательность
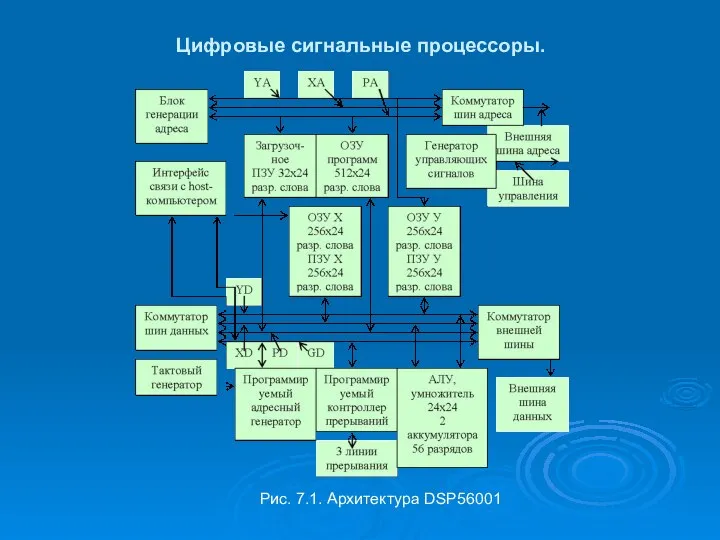
Цифровые сигнальные процессоры.
Рис. 7.1. Архитектура DSP56001
Цифровые сигнальные процессоры.
Рис. 7.1. Архитектура DSP56001
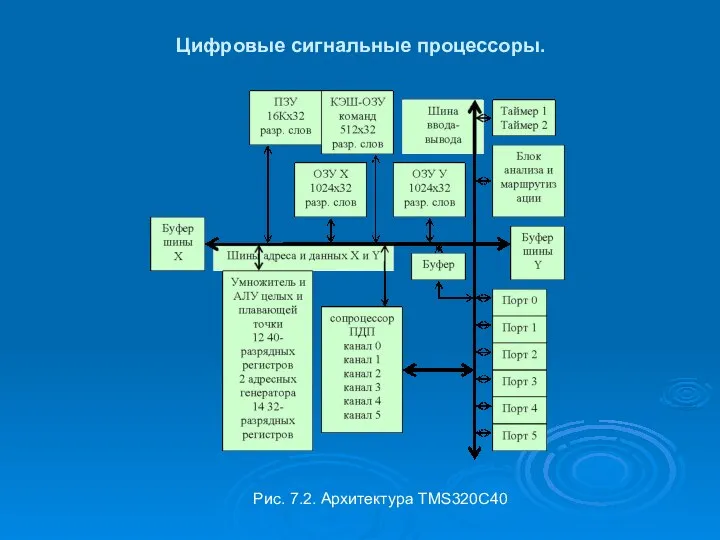
Цифровые сигнальные процессоры.
Рис. 7.2. Архитектура TMS320C40
Цифровые сигнальные процессоры.
Рис. 7.2. Архитектура TMS320C40
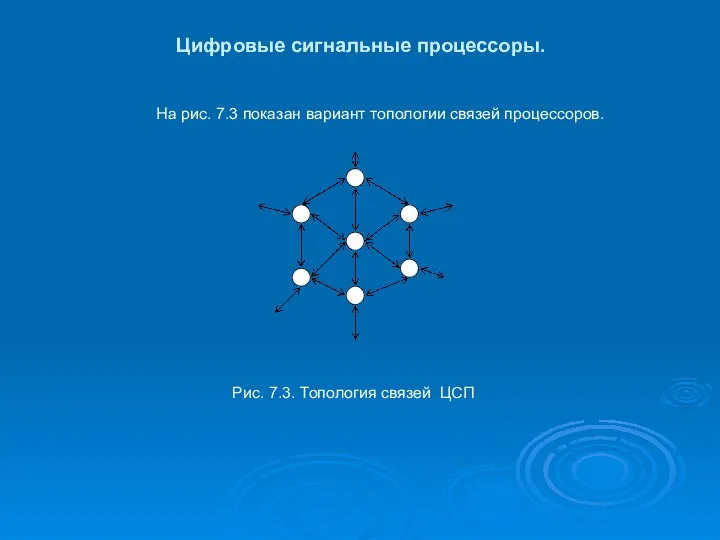
Цифровые сигнальные процессоры.
На рис. 7.3 показан вариант топологии связей процессоров.
Рис. 7.3.
Цифровые сигнальные процессоры.
На рис. 7.3 показан вариант топологии связей процессоров.
Рис. 7.3.
 Сью Таунсенд
Сью Таунсенд Лингво-лагерь Join Us Camp
Лингво-лагерь Join Us Camp Понятие цены Методы ценообразования
Понятие цены Методы ценообразования BERLIN (Spitzname von Berlin ist “Spree-Athen”)
BERLIN (Spitzname von Berlin ist “Spree-Athen”) Презентация "Коммерческие банки" - скачать презентации по Экономике
Презентация "Коммерческие банки" - скачать презентации по Экономике Od osoby, która cię kocha
Od osoby, która cię kocha Индустриальный пейзаж
Индустриальный пейзаж Древние образы, единство формы и декора в народных игрушках - презентация
Древние образы, единство формы и декора в народных игрушках - презентация Принципы БЖД
Принципы БЖД Система органов местного самоуправления
Система органов местного самоуправления Инсталлируемые веб-приложения Service Workers, Cache API, WebRTC
Инсталлируемые веб-приложения Service Workers, Cache API, WebRTC Буддизм
Буддизм Двумерные массивы. Замена строк и столбцов в матрице. Транспонирование матрицы.
Двумерные массивы. Замена строк и столбцов в матрице. Транспонирование матрицы. Математики Франции
Математики Франции ELearnExpo 2005 Moskow 26-27 May www.mmlab.ru Системы поддержки совместного обучения для eLearning Михаил Николаевич Морозов Лаборатория систем мультимед
ELearnExpo 2005 Moskow 26-27 May www.mmlab.ru Системы поддержки совместного обучения для eLearning Михаил Николаевич Морозов Лаборатория систем мультимед Презентация Система правовой охраны интеллектуальной собственности в России
Презентация Система правовой охраны интеллектуальной собственности в России Новейшие строительные материалы в условиях Крайнего Севера
Новейшие строительные материалы в условиях Крайнего Севера Цифровая схемотехника. Диодно-транзисторная логика
Цифровая схемотехника. Диодно-транзисторная логика Педагогический проект «ВО ИМЯ ПОЗНАНИЯ И РАДОСТИ ТРУДА» Срок реализации 15.08.2010г-15.06.2011г Автор – Елена Викторовна Золотенко
Педагогический проект «ВО ИМЯ ПОЗНАНИЯ И РАДОСТИ ТРУДА» Срок реализации 15.08.2010г-15.06.2011г Автор – Елена Викторовна Золотенко  Современный этап развития ядерной энергетики.Реакторы на тепловых и быстрых нейтронах
Современный этап развития ядерной энергетики.Реакторы на тепловых и быстрых нейтронах Валентин Григорьевич Распутин
Валентин Григорьевич Распутин Правовой статус педагогических работников
Правовой статус педагогических работников РОЛЬ ДВИГАТЕЛЬНОЙ АКТИВНОСТИ В КОРРЕКЦИОННО-РАЗВИВАЮЩЕМ ОБУЧЕНИИ ДЕТЕЙ С ОБЩИМ НЕДОРАЗВИТИЕМ РЕЧИ.
РОЛЬ ДВИГАТЕЛЬНОЙ АКТИВНОСТИ В КОРРЕКЦИОННО-РАЗВИВАЮЩЕМ ОБУЧЕНИИ ДЕТЕЙ С ОБЩИМ НЕДОРАЗВИТИЕМ РЕЧИ. Детали машин
Детали машин Презентация на тему "Внематочная беременность" - скачать презентации по Медицине
Презентация на тему "Внематочная беременность" - скачать презентации по Медицине Культура Древнего Египта
Культура Древнего Египта  Мемы в искусстве и культуре
Мемы в искусстве и культуре Презентация Стаж государственной службы: понятие, особенности исчисления. Выслуга лет. Лица, имеющие право на получение пенсии за
Презентация Стаж государственной службы: понятие, особенности исчисления. Выслуга лет. Лица, имеющие право на получение пенсии за