- Основы проектирования программ

Содержание
- 2. 6 Основы проектирования программ 111 V Разработка документации Основной результат этого этапа – также создание эксплуатационной
- 3. 7 Работа с динамическими структурами данных 112 В предыдущих лекциях мы рассматривали программирование, связанное с обработкой
- 4. 7 Работа с динамическими структурами данных 113 Схема распределения памяти программ на Turbo Pascal Рис. П.6.1
- 5. 7 Работа с динамическими структурами данных 114 Префикс сегмента программы (Program Segment Prefix - PSP) -
- 6. 7 Работа с динамическими структурами данных 115 Раздел оперативной памяти, распределяемый статически, называется статической памятью; динамически
- 7. 7 Работа с динамическими структурами данных 116 Объект данных обладает динамической структурой, если его размер изменяется
- 8. 7 Работа с динамическими структурами данных 117 Указатели Для работы с динамическими программными объектами в Паскале
- 9. 7 Работа с динамическими структурами данных 118 С помощью нетипизированных указателей удобно динамически размещать данные, структура
- 10. 7 Работа с динамическими структурами данных 119 Выделение и освобождение динамической памяти Вся ДП рассматривается как
- 11. Графически действие процедуры new можно изобразить так: 7 Работа с динамическими структурами данных 120 Освобождение динамической
- 12. 7 Работа с динамическими структурами данных 121 Процедура dispose освобождает память, занятую динамической переменной. При этом
- 13. 7 Работа с динамическими структурами данных 122 Существует единственная константа ссылочного типа nil, которая обозначает «пустой»
- 14. 7 Работа с динамическими структурами данных 123 В Паскале определены стандартные функции для работы с указателями:
- 15. 7 Работа с динамическими структурами данных 124 Рассмотрим пример работы с указателями:
- 16. 7 Работа с динамическими структурами данных 125 Серия последовательных обращений к New и Dispose обычно приводит
- 17. 7 Работа с динамическими структурами данных 126
- 18. 7 Работа с динамическими структурами данных 127 Динамические структуры данных Переменные типа «указатель» обычно используют при
- 19. 7 Работа с динамическими структурами данных 128 В зависимости от количества полей в адресной части и
- 20. 7 Работа с динамическими структурами данных 129 Исходные установки В начале программы работы с линейными динамическими
- 21. 7 Работа с динамическими структурами данных 130 Пример1 Разработать программу, которая строит список по типу стека
- 22. begin ReadLn(a); new(first); {запрашиваем память под элемент} first ^.num:=а; {заносим число в информационное поле} first ^.р:=nil;
- 23. {удаление стека с выводом значений его элементов} while first nil do begin a:=q^.num; {заносим информационное поле
- 24. Пример 2 Разработать программу, которая строит список по типу очереди из целых чисел, вводимых с клавиатуры.
- 25. 7 Работа с динамическими структурами данных 134 Динамические структуры Линейные односвязные списки (однонаправленные цепочки). Списком называется
- 26. 7 Работа с динамическими структурами данных 135 Описание списка Пример описания списка Type ukazat= ^ S;
- 27. 7 Работа с динамическими структурами данных 136 Продолжим формирование списка. Для этого нужно добавить элемент либо
- 28. 7 Работа с динамическими структурами данных 137 Б) Добавление элемента в конец списка. Для этого введем
- 29. New( x^. next); {выделяем память для следующего элемента} 7 Работа с динамическими структурами данных 138 x:=
- 30. Просмотр списка While u nil do Begin Writeln (u^.inf); u:= u^.next; end; 7 Работа с динамическими
- 31. 7 Работа с динамическими структурами данных 140 x:= u; u:= u^.next; dispose(x); Б) Удаление элемента из
- 32. 7 Работа с динамическими структурами данных 141 x:= u; while ( x nil) and ( x^.
- 33. В)Удаление из конца списка. Для этого нужно найти предпоследний элемент. x:= u; dx:= u; while x^.next
- 34. Выделим типовые операции над списками: добавление элемента в начало списка; удаление элемента из начала списка; добавление
- 35. Бинарные деревья В математике бинарным (двоичным) деревом называют конечное множество вершин, которое либо пусто, либо состоит
- 36. 7 Работа с динамическими структурами данных 145 Корень дерева листья листья листья Левая ветвь Корень левого
- 37. Построение дерева выполняется следующим образом. Если дерево пусто, то первая же вершина становится корнем дерева. Добавление
- 38. Исходные установки. В начале программы необходимо описать элемент и его тип: Туре top_ptr = ^top; {тип
- 39. 1.Построение дерева. Дерево строится в соответствии с главным правилом. Например, пусть дана последовательность целых чисел {5,
- 40. 5 a) 5 2 б) 7 Работа с динамическими структурами данных 149 5 2 8 в)
- 41. 7 Работа с динамическими структурами данных 150 5 2 8 7 1 2 6 9 Рис.
- 42. Фрагмент программы, реализующий добавление вершины к дереву, состоит из трех частей: создания вершины, поиска корня, к
- 43. {поиск корня для добавляемой вершины} pass:=root; {начинаем с корня бинарного дерева} while pass nil do {пока
- 44. Используя рекурсивность определения дерева, можно построить рекурсивную процедуру добавления вершин к дереву. В качестве параметров эта
- 45. 2.Поиск вершины в сортированном бинарном дереве. Поиск в сортированном бинарном дереве осуществляется следующим образом: Вначале значение
- 46. • удаляемая вершина содержит две ветви: в этом случае нужно найти подходящую вершину, которую можно вставить
- 47. 7 Работа с динамическими структурами данных 156 5 2 8 7 1 2 6 9 Рис.
- 49. Скачать презентацию

6 Основы проектирования программ 111
V Разработка документации
Основной результат этого этапа
6 Основы проектирования программ 111
V Разработка документации
Основной результат этого этапа

7 Работа с динамическими структурами данных 112
В предыдущих лекциях мы
7 Работа с динамическими структурами данных 112
В предыдущих лекциях мы
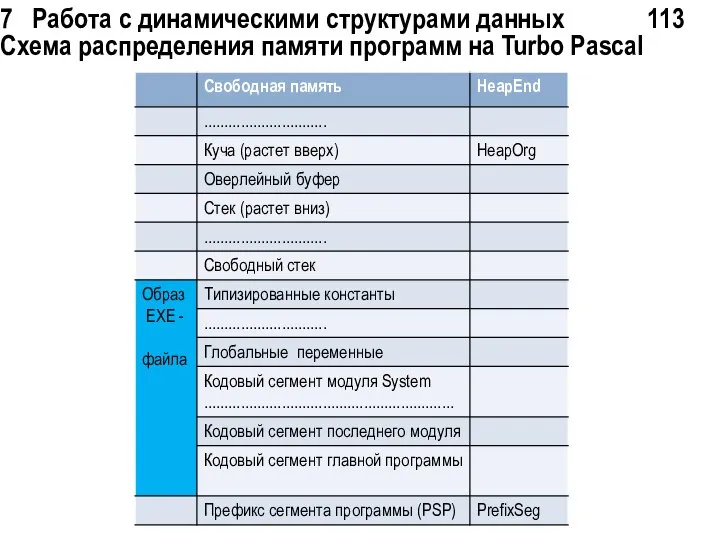
7 Работа с динамическими структурами данных 113 Схема распределения памяти программ
7 Работа с динамическими структурами данных 113 Схема распределения памяти программ

7 Работа с динамическими структурами данных 114
Префикс сегмента программы (Program Segment
7 Работа с динамическими структурами данных 114
Префикс сегмента программы (Program Segment

7 Работа с динамическими структурами данных 115
Раздел оперативной памяти, распределяемый статически,
7 Работа с динамическими структурами данных 115
Раздел оперативной памяти, распределяемый статически,

7 Работа с динамическими структурами данных 116
Объект данных обладает динамической структурой,
7 Работа с динамическими структурами данных 116
Объект данных обладает динамической структурой,

7 Работа с динамическими структурами данных 117
Указатели
Для работы с динамическими
7 Работа с динамическими структурами данных 117
Указатели
Для работы с динамическими

7 Работа с динамическими структурами данных 118
С помощью нетипизированных указателей удобно
7 Работа с динамическими структурами данных 118
С помощью нетипизированных указателей удобно

7 Работа с динамическими структурами данных 119
Выделение и освобождение динамической
7 Работа с динамическими структурами данных 119
Выделение и освобождение динамической

Графически действие процедуры new можно изобразить так:
7 Работа с динамическими структурами
Графически действие процедуры new можно изобразить так:
7 Работа с динамическими структурами

7 Работа с динамическими структурами данных 121
Процедура dispose освобождает память,
7 Работа с динамическими структурами данных 121
Процедура dispose освобождает память,

7 Работа с динамическими структурами данных 122
Существует единственная константа ссылочного
7 Работа с динамическими структурами данных 122
Существует единственная константа ссылочного

7 Работа с динамическими структурами данных 123
В Паскале определены стандартные
7 Работа с динамическими структурами данных 123
В Паскале определены стандартные
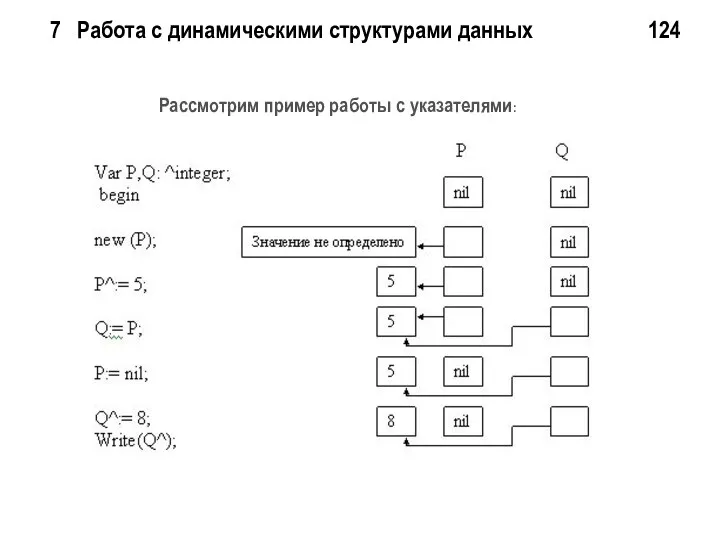
7 Работа с динамическими структурами данных 124
Рассмотрим пример работы с
7 Работа с динамическими структурами данных 124
Рассмотрим пример работы с

7 Работа с динамическими структурами данных 125
Серия последовательных обращений к
7 Работа с динамическими структурами данных 125
Серия последовательных обращений к
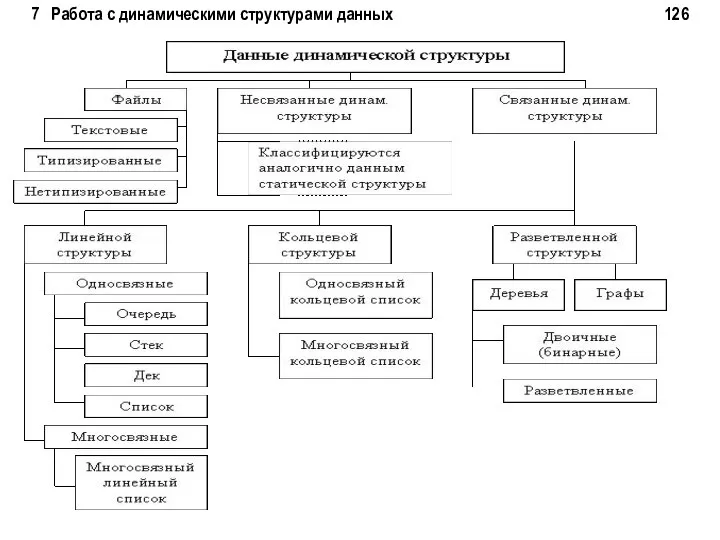
7 Работа с динамическими структурами данных 126
7 Работа с динамическими структурами данных 126

7 Работа с динамическими структурами данных 127
Динамические структуры данных
Переменные типа
7 Работа с динамическими структурами данных 127
Динамические структуры данных
Переменные типа

7 Работа с динамическими структурами данных 128
В зависимости от количества
7 Работа с динамическими структурами данных 128
В зависимости от количества

7 Работа с динамическими структурами данных 129
Исходные установки
В начале программы
7 Работа с динамическими структурами данных 129
Исходные установки
В начале программы

7 Работа с динамическими структурами данных 130
Пример1 Разработать программу, которая
7 Работа с динамическими структурами данных 130
Пример1 Разработать программу, которая

begin
ReadLn(a);
new(first); {запрашиваем память под элемент}
first ^.num:=а; {заносим число в информационное поле}
first
begin
ReadLn(a);
new(first); {запрашиваем память под элемент}
first ^.num:=а; {заносим число в информационное поле}
first

{удаление стека с выводом значений его элементов}
while first <> nil do
{удаление стека с выводом значений его элементов}
while first <> nil do

Пример 2 Разработать программу, которая строит список по типу очереди из
Пример 2 Разработать программу, которая строит список по типу очереди из
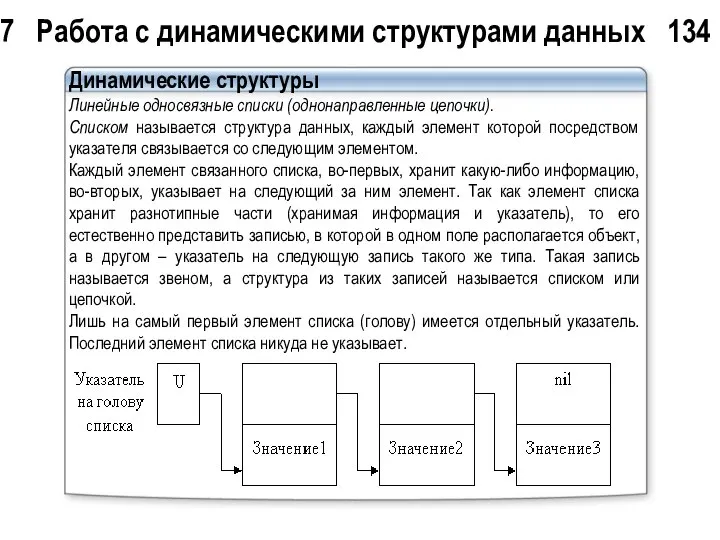
7 Работа с динамическими структурами данных 134
Динамические структуры
Линейные односвязные списки
7 Работа с динамическими структурами данных 134
Динамические структуры
Линейные односвязные списки

7 Работа с динамическими структурами данных 135
Описание списка
Пример описания списка
7 Работа с динамическими структурами данных 135
Описание списка
Пример описания списка
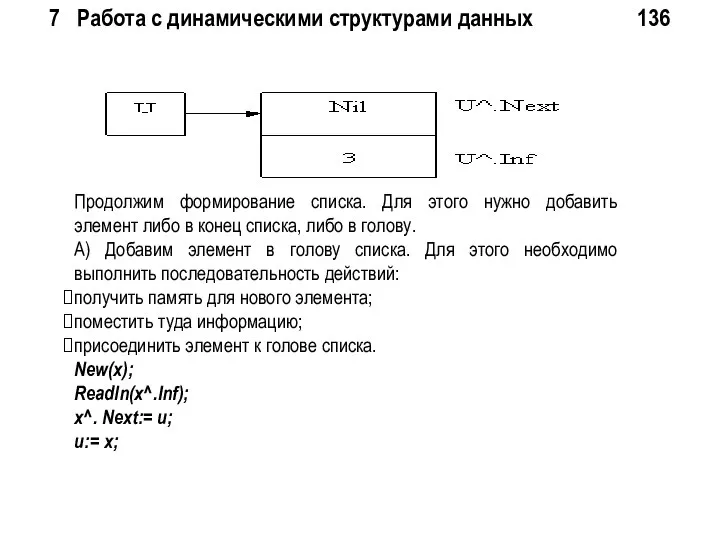
7 Работа с динамическими структурами данных 136
Продолжим формирование списка. Для
7 Работа с динамическими структурами данных 136
Продолжим формирование списка. Для
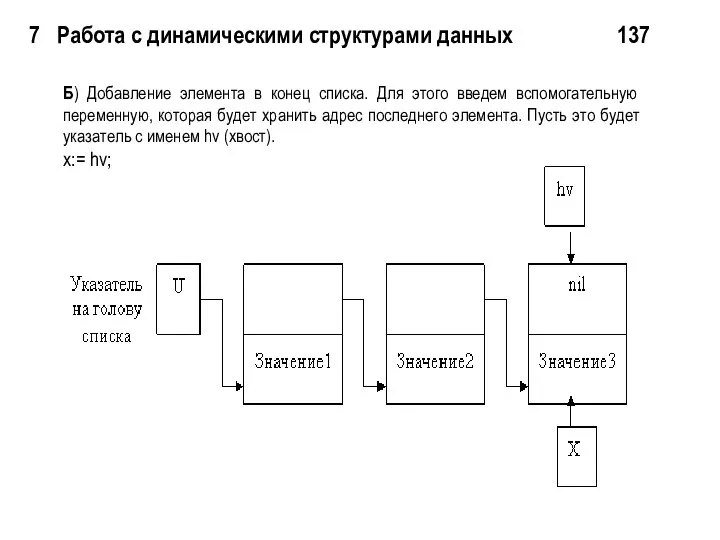
7 Работа с динамическими структурами данных 137
Б) Добавление элемента в
7 Работа с динамическими структурами данных 137
Б) Добавление элемента в
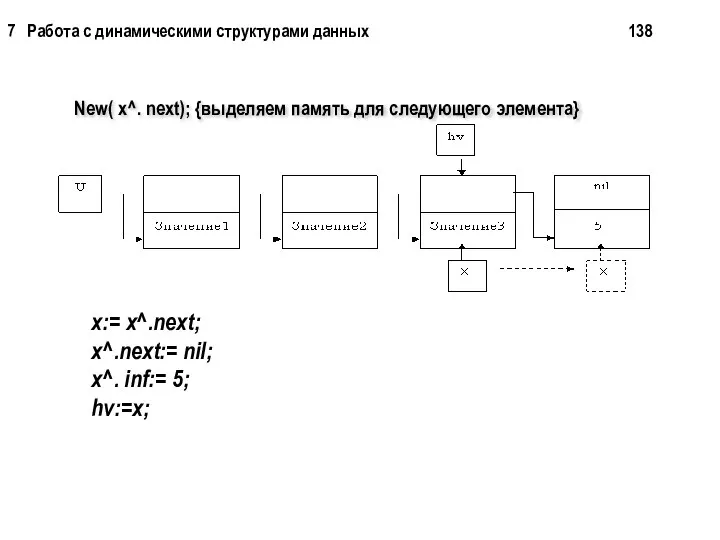
New( x^. next); {выделяем память для следующего элемента}
7 Работа с динамическими
New( x^. next); {выделяем память для следующего элемента}
7 Работа с динамическими

Просмотр списка
While u<> nil do
Begin
Writeln (u^.inf);
u:= u^.next;
end;
7 Работа с динамическими структурами
Просмотр списка
While u<> nil do
Begin
Writeln (u^.inf);
u:= u^.next;
end;
7 Работа с динамическими структурами
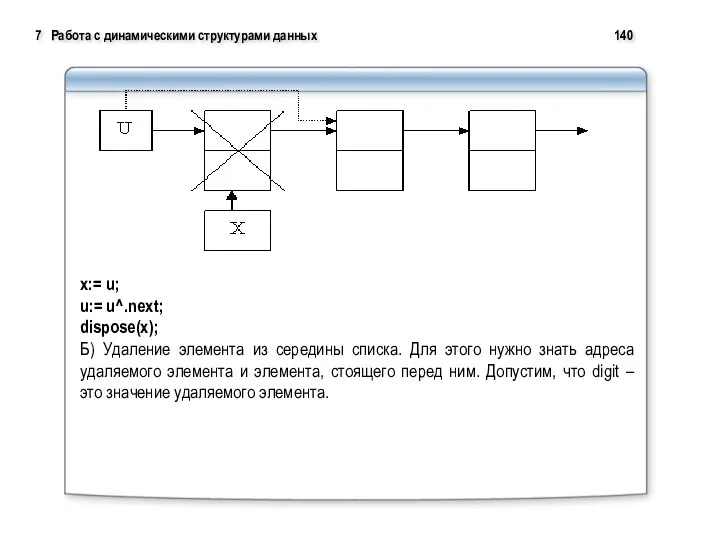
7 Работа с динамическими структурами данных 140
x:= u;
u:= u^.next;
dispose(x);
7 Работа с динамическими структурами данных 140
x:= u; u:= u^.next; dispose(x);
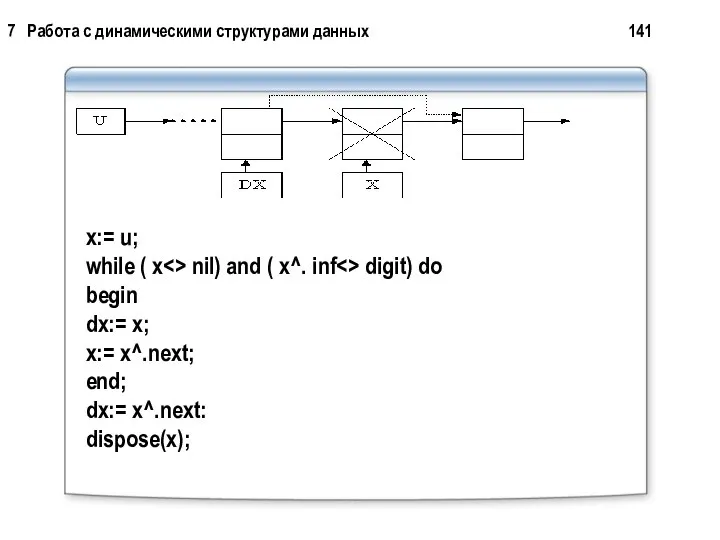
7 Работа с динамическими структурами данных 141
x:= u;
while
7 Работа с динамическими структурами данных 141
x:= u; while

В)Удаление из конца списка. Для этого нужно найти предпоследний элемент.
x:= u;
В)Удаление из конца списка. Для этого нужно найти предпоследний элемент.
x:= u;

Выделим типовые операции над списками:
добавление элемента в начало списка;
удаление элемента
Выделим типовые операции над списками:
добавление элемента в начало списка;
удаление элемента

Бинарные деревья
В математике бинарным (двоичным) деревом называют конечное множество вершин, которое
Бинарные деревья
В математике бинарным (двоичным) деревом называют конечное множество вершин, которое
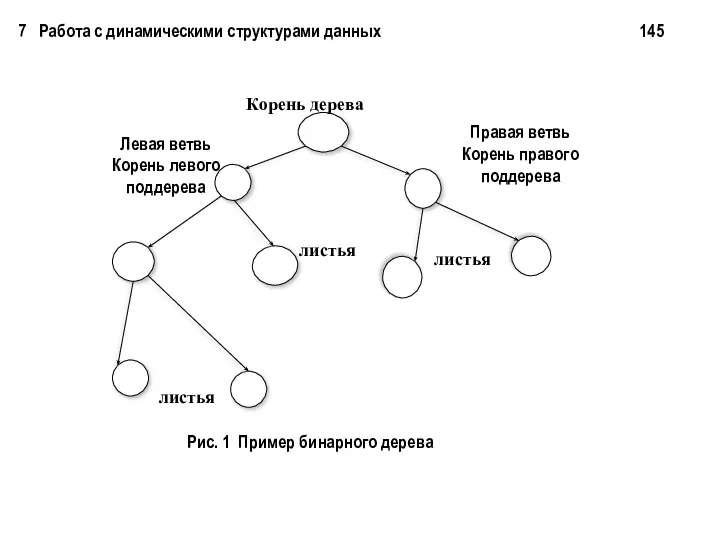
7 Работа с динамическими структурами данных 145
Корень дерева
листья
листья
листья
Левая ветвь
Корень
7 Работа с динамическими структурами данных 145
Корень дерева
листья
листья
листья
Левая ветвь
Корень

Построение дерева выполняется следующим образом.
Если дерево пусто, то первая же
Построение дерева выполняется следующим образом.
Если дерево пусто, то первая же

Исходные установки. В начале программы необходимо описать элемент и его тип:
Туре
Исходные установки. В начале программы необходимо описать элемент и его тип:
Туре

1.Построение дерева.
Дерево строится в соответствии с главным правилом.
Например, пусть дана
1.Построение дерева.
Дерево строится в соответствии с главным правилом.
Например, пусть дана
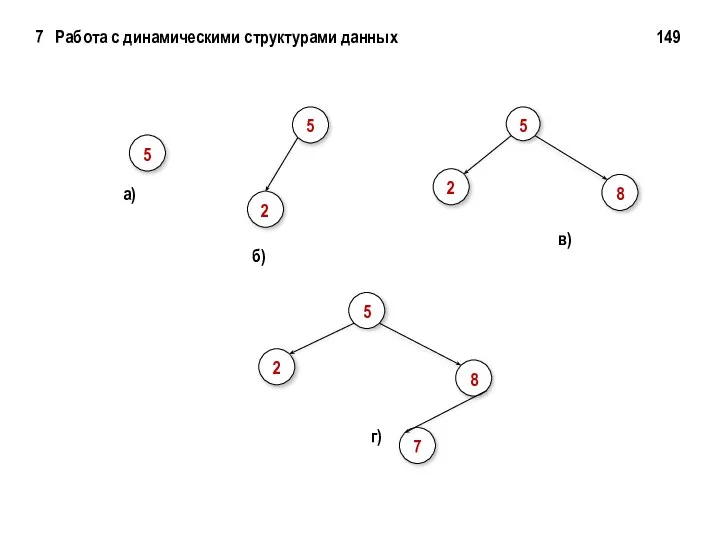
5
a)
5
2
б)
7 Работа с динамическими структурами данных 149
5
2
8
в)
5
2
8
7
г)
5
a)
5
2
б)
7 Работа с динамическими структурами данных 149
5
2
8
в)
5
2
8
7
г)
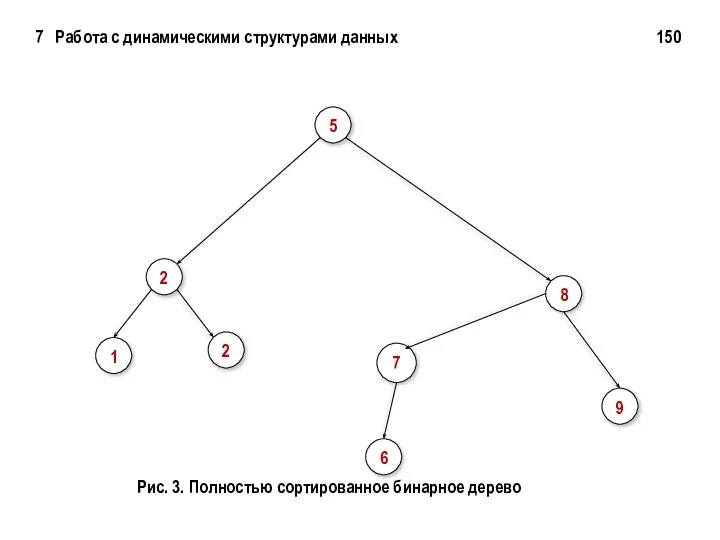
7 Работа с динамическими структурами данных 150
5
2
8
7
1
2
6
9
Рис. 3. Полностью сортированное
7 Работа с динамическими структурами данных 150
5
2
8
7
1
2
6
9
Рис. 3. Полностью сортированное

Фрагмент программы, реализующий добавление вершины к дереву, состоит из трех частей:
Фрагмент программы, реализующий добавление вершины к дереву, состоит из трех частей:

{поиск корня для добавляемой вершины}
pass:=root; {начинаем с корня бинарного дерева}
while pass
{поиск корня для добавляемой вершины}
pass:=root; {начинаем с корня бинарного дерева}
while pass

Используя рекурсивность определения дерева, можно построить рекурсивную процедуру добавления вершин к
Используя рекурсивность определения дерева, можно построить рекурсивную процедуру добавления вершин к

2.Поиск вершины в сортированном бинарном дереве. Поиск в сортированном бинарном дереве
2.Поиск вершины в сортированном бинарном дереве. Поиск в сортированном бинарном дереве

• удаляемая вершина содержит две ветви: в этом случае нужно найти
• удаляемая вершина содержит две ветви: в этом случае нужно найти
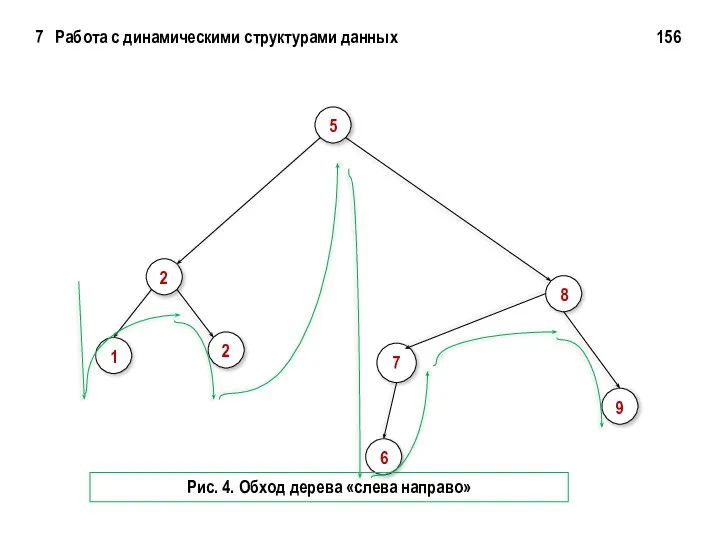
7 Работа с динамическими структурами данных 156
5
2
8
7
1
2
6
9
Рис. 4. Обход дерева
7 Работа с динамическими структурами данных 156
5
2
8
7
1
2
6
9
Рис. 4. Обход дерева
 Технология ремонта кузовов автомобиля
Технология ремонта кузовов автомобиля Вирусы гриппа Подготовила: Курганова Е., РЭ-2, 3 курс
Вирусы гриппа Подготовила: Курганова Е., РЭ-2, 3 курс Что делать в трудную минуту? Молодёжь Смоленской Центральной Церкви
Что делать в трудную минуту? Молодёжь Смоленской Центральной Церкви Домашняя мультимедиа-платформа с голосовым помощником Алисой
Домашняя мультимедиа-платформа с голосовым помощником Алисой Аналық тақша
Аналық тақша Basics of software development (continued)
Basics of software development (continued) Основы логики
Основы логики Электрические машины и электропривод. Введение
Электрические машины и электропривод. Введение Galileo galilei, February 15, 1564 - January 8, 1642
Galileo galilei, February 15, 1564 - January 8, 1642 Программирование. Экзамен
Программирование. Экзамен Устройства компьютера
Устройства компьютера Электрооборудование. Электроснабжение бортовой сети
Электрооборудование. Электроснабжение бортовой сети Весело колосится густая рожь.
Весело колосится густая рожь. Анималотерапия - презентация для начальной школы_
Анималотерапия - презентация для начальной школы_ Административное правонарушение Опрос
Административное правонарушение Опрос FORTRAN Название языка происходит от словосочетания FORmulae TRANslation — преобразование формул
FORTRAN Название языка происходит от словосочетания FORmulae TRANslation — преобразование формул Государственный Дарвиновский музей
Государственный Дарвиновский музей Типология и классификация политической культуры
Типология и классификация политической культуры Скульптурные шедевры Л.Бернини
Скульптурные шедевры Л.Бернини Ватто Антуан
Ватто Антуан Теория ландшафтной архитектуры и методология проектирования
Теория ландшафтной архитектуры и методология проектирования Презентацию выполнила студентка – заочница 2 курса филологического ф – та Купчихина Елена Николаевна Владимир, 2013 год
Презентацию выполнила студентка – заочница 2 курса филологического ф – та Купчихина Елена Николаевна Владимир, 2013 год Общая эндокринология
Общая эндокринология  Цивилизация и культура
Цивилизация и культура Political parties in Estonia
Political parties in Estonia Медный, бронзовый, железный века на Луганщине
Медный, бронзовый, железный века на Луганщине Методика работы Учителя физической культуры СОШ № 80 Чигилейчик Лады Юрьевны
Методика работы Учителя физической культуры СОШ № 80 Чигилейчик Лады Юрьевны Ноосфера . Эволюция представлений о месте человека в природе
Ноосфера . Эволюция представлений о месте человека в природе