- Программирование и разработка веб-приложений. Использование Python для работы с XML

Содержание
- 2. Вид XML файла
- 3. Основные модули для парсинга from xml.dom import minidom from xml.etree import ElementTree #import xml.etree.ElementTree as ET
- 4. Работа с файлом XML_FILE='sample3.xml' tree = ET.ElementTree(file=XML_FILE) tree=ET.parse('sample3.xml') file01=open('books.xml','r') tree=ElementTree.parse(file01) xmldoc=minidom.parse('books.xml')
- 5. Парсинг XML файла from xml.dom import minidom xmldoc=minidom.parse('books.xml') a_list=xmldoc.getElementsByTagName('person') print(len(a_list)) print(a_list[0].attributes['name'].value) for i in a_list: print(i.attributes['name'].value)
- 6. Распарсить строку from xml.dom import minidom f = minidom.parseString(''' ''') Использование xml.dom
- 7. a = f.getElementsByTagName('Book') #взятие элементов по тегу name=[] author=[] pers=[] for i in a: name.append(i.getAttribute('name')) #добавление
- 8. Просмотр корня дерева from xml.etree import ElementTree file01=open('books.xml','r') tree=ElementTree.parse(file01) print(tree) root=tree.getroot() print(root) print(root.tag) print(root.attrib) print(root.text) ElementTree
- 9. Просмотр тегов и атрибутов for i in root: print(i.tag, i.attrib) print(root[0][0].text) for i in root: for
- 10. Просмотр тегов корня from xml.etree import ElementTree file01=open('books.xml','r') tree=ElementTree.parse(file01) #tree=ElementTree.ElementTree(file='books.xml') root=tree.getroot() print(root) print(root.tag) print(root.attrib) print(root.text) for
- 11. Проход по свойствам корня root=tree.getroot() for i in root: print(i.tag, i.attrib)
- 12. Просмотр, используя keys и items for i in root: print(i.tag,i.keys(),i.items())
- 13. keys и items с итератором по root for i in root.iter(): print(i.tag, i.keys(),i.items(),i.text)
- 14. Использование итератора для просмотра сведений for i in root.iter('book'): print(i.tag, i.keys(),i.items(),i.text)
- 15. Использование итератора поиска for i in root.iterfind('.'): print(i.tag)
- 16. for i in root.iterfind('.//'): print(i.tag)
- 17. for i in root.iterfind('./book//'): print(i.tag)
- 18. Использование итератора для просмотра сведений for i in tree.iter('person'): print(i.attrib)
- 19. Одиночны поиск и поиск всех информации for i in root.findall('book'): bookpages=i.find('pages').text bookpersons=i.findall('person') name=i.get('name') print(name) print(bookpages) print(bookpersons)
- 20. Запись #iter ищет среди потомков number for i in root.iter('number'): new_number=int(i.text)+1 i.text=str(new_number) i.set('updated','2017') tree.write('books2.xml')
- 21. Поиск и удаление for i in root.findall('book'): pages=int(i.find('pages').text) print(pages) if pages >100: root.remove(i)
- 22. Проход по дереву и обновление значений book=ElementTree.Element('book') number=ElementTree.SubElement(book,'number') year=ElementTree.SubElement(book,'year').set('year','2017') pages=ElementTree.SubElement(book,'pages').set('pages','100') number.set('pages','50') ElementTree.dump(book)
- 23. book=ElementTree.Element('book') number=ElementTree.SubElement(book,'number') year=ElementTree.SubElement(book,'year').set('year','2017') pages=ElementTree.SubElement(book,'pages').set('pages','100') number.set('pages','50') root.append(book)
- 25. Скачать презентацию

Вид XML файла
Вид XML файла

Основные модули для парсинга
from xml.dom import minidom
from xml.etree import ElementTree
#import xml.etree.ElementTree
Основные модули для парсинга
from xml.dom import minidom
from xml.etree import ElementTree
#import xml.etree.ElementTree

Работа с файлом
XML_FILE='sample3.xml'
tree = ET.ElementTree(file=XML_FILE)
tree=ET.parse('sample3.xml')
file01=open('books.xml','r')
tree=ElementTree.parse(file01)
xmldoc=minidom.parse('books.xml')
Работа с файлом
XML_FILE='sample3.xml'
tree = ET.ElementTree(file=XML_FILE)
tree=ET.parse('sample3.xml')
file01=open('books.xml','r')
tree=ElementTree.parse(file01)
xmldoc=minidom.parse('books.xml')
![Парсинг XML файла from xml.dom import minidom xmldoc=minidom.parse('books.xml') a_list=xmldoc.getElementsByTagName('person') print(len(a_list)) print(a_list[0].attributes['name'].value)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1364207/slide-4.jpg)
Парсинг XML файла
from xml.dom import minidom
xmldoc=minidom.parse('books.xml')
a_list=xmldoc.getElementsByTagName('person')
print(len(a_list))
print(a_list[0].attributes['name'].value)
for i in a_list:
print(i.attributes['name'].value)
Использование xml.dom
Парсинг XML файла
from xml.dom import minidom
xmldoc=minidom.parse('books.xml')
a_list=xmldoc.getElementsByTagName('person')
print(len(a_list))
print(a_list[0].attributes['name'].value)
for i in a_list:
print(i.attributes['name'].value)
Использование xml.dom

Распарсить строку
from xml.dom import minidom
f = minidom.parseString('''
Распарсить строку
from xml.dom import minidom
f = minidom.parseString('''
![a = f.getElementsByTagName('Book') #взятие элементов по тегу name=[] author=[] pers=[] for](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1364207/slide-6.jpg)
a = f.getElementsByTagName('Book') #взятие элементов по тегу
name=[]
author=[]
pers=[]
for i in a:
name.append(i.getAttribute('name'))
a = f.getElementsByTagName('Book') #взятие элементов по тегу
name=[]
author=[]
pers=[]
for i in a:
name.append(i.getAttribute('name'))

Просмотр корня дерева
from xml.etree import ElementTree
file01=open('books.xml','r')
tree=ElementTree.parse(file01)
print(tree)
root=tree.getroot()
print(root)
print(root.tag)
print(root.attrib)
print(root.text)
ElementTree
Просмотр корня дерева
from xml.etree import ElementTree
file01=open('books.xml','r')
tree=ElementTree.parse(file01)
print(tree)
root=tree.getroot()
print(root)
print(root.tag)
print(root.attrib)
print(root.text)
ElementTree
![Просмотр тегов и атрибутов for i in root: print(i.tag, i.attrib) print(root[0][0].text)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1364207/slide-8.jpg)
Просмотр тегов и атрибутов
for i in root:
print(i.tag, i.attrib)
print(root[0][0].text)
for i
Просмотр тегов и атрибутов
for i in root:
print(i.tag, i.attrib)
print(root[0][0].text)
for i

Просмотр тегов корня
from xml.etree import ElementTree
file01=open('books.xml','r')
tree=ElementTree.parse(file01)
#tree=ElementTree.ElementTree(file='books.xml')
root=tree.getroot()
print(root)
print(root.tag)
print(root.attrib)
print(root.text)
for i in root.iterfind('.'):
print(i.tag)
Просмотр тегов корня
from xml.etree import ElementTree
file01=open('books.xml','r')
tree=ElementTree.parse(file01)
#tree=ElementTree.ElementTree(file='books.xml')
root=tree.getroot()
print(root)
print(root.tag)
print(root.attrib)
print(root.text)
for i in root.iterfind('.'):
print(i.tag)

Проход по свойствам корня
root=tree.getroot()
for i in root:
print(i.tag, i.attrib)
Проход по свойствам корня
root=tree.getroot()
for i in root:
print(i.tag, i.attrib)

Просмотр, используя keys и items
for i in root:
print(i.tag,i.keys(),i.items())
Просмотр, используя keys и items
for i in root:
print(i.tag,i.keys(),i.items())

keys и items с итератором по root
for i in root.iter():
print(i.tag, i.keys(),i.items(),i.text)
keys и items с итератором по root
for i in root.iter():
print(i.tag, i.keys(),i.items(),i.text)

Использование итератора для просмотра сведений
for i in root.iter('book'):
print(i.tag, i.keys(),i.items(),i.text)
Использование итератора для просмотра сведений
for i in root.iter('book'):
print(i.tag, i.keys(),i.items(),i.text)

Использование итератора поиска
for i in root.iterfind('.'):
print(i.tag)
Использование итератора поиска
for i in root.iterfind('.'):
print(i.tag)

for i in root.iterfind('.//'):
print(i.tag)
for i in root.iterfind('.//'):
print(i.tag)

for i in root.iterfind('./book//'):
print(i.tag)
for i in root.iterfind('./book//'):
print(i.tag)

Использование итератора для просмотра сведений
for i in tree.iter('person'):
print(i.attrib)
Использование итератора для просмотра сведений
for i in tree.iter('person'):
print(i.attrib)

Одиночны поиск и поиск всех информации
for i in root.findall('book'):
bookpages=i.find('pages').text
bookpersons=i.findall('person')
name=i.get('name')
print(name)
print(bookpages)
print(bookpersons)
Одиночны поиск и поиск всех информации
for i in root.findall('book'):
bookpages=i.find('pages').text
bookpersons=i.findall('person')
name=i.get('name')
print(name)
print(bookpages)
print(bookpersons)

Запись
#iter ищет среди потомков number
for i in root.iter('number'):
new_number=int(i.text)+1
i.text=str(new_number)
i.set('updated','2017')
tree.write('books2.xml')
Запись
#iter ищет среди потомков number
for i in root.iter('number'):
new_number=int(i.text)+1
i.text=str(new_number)
i.set('updated','2017')
tree.write('books2.xml')

Поиск и удаление
for i in root.findall('book'):
pages=int(i.find('pages').text)
print(pages)
if pages >100:
root.remove(i)
Поиск и удаление
for i in root.findall('book'):
pages=int(i.find('pages').text)
print(pages)
if pages >100:
root.remove(i)

Проход по дереву и обновление значений
book=ElementTree.Element('book')
number=ElementTree.SubElement(book,'number')
year=ElementTree.SubElement(book,'year').set('year','2017')
pages=ElementTree.SubElement(book,'pages').set('pages','100')
number.set('pages','50')
ElementTree.dump(book)
Проход по дереву и обновление значений
book=ElementTree.Element('book')
number=ElementTree.SubElement(book,'number')
year=ElementTree.SubElement(book,'year').set('year','2017')
pages=ElementTree.SubElement(book,'pages').set('pages','100')
number.set('pages','50')
ElementTree.dump(book)

book=ElementTree.Element('book')
number=ElementTree.SubElement(book,'number')
year=ElementTree.SubElement(book,'year').set('year','2017')
pages=ElementTree.SubElement(book,'pages').set('pages','100')
number.set('pages','50')
root.append(book)
book=ElementTree.Element('book')
number=ElementTree.SubElement(book,'number')
year=ElementTree.SubElement(book,'year').set('year','2017')
pages=ElementTree.SubElement(book,'pages').set('pages','100')
number.set('pages','50')
root.append(book)
 Сибирское таможенное управление
Сибирское таможенное управление Фурье
Фурье Туркеста́но-Сиби́рская магистра́ль
Туркеста́но-Сиби́рская магистра́ль Достопримечательности Лондона
Достопримечательности Лондона Perfekt
Perfekt Нравственно-патриотическое воспитание дошкольников через ознакомление с традициями и культурой своего народа
Нравственно-патриотическое воспитание дошкольников через ознакомление с традициями и культурой своего народа РЕЗЕРВНЫЙ ФОНД,ЕГО ЗНАЧЕНИЕ ДЛЯ РОССИЙСКОЙ ЭКОНОМИКИ ВЫПОЛНИЛА СТУДЕНТКА 4 КУРСА ГРУППЫ Т-081 УЛАН КЫЗЫ АЙГЕРИМ
РЕЗЕРВНЫЙ ФОНД,ЕГО ЗНАЧЕНИЕ ДЛЯ РОССИЙСКОЙ ЭКОНОМИКИ ВЫПОЛНИЛА СТУДЕНТКА 4 КУРСА ГРУППЫ Т-081 УЛАН КЫЗЫ АЙГЕРИМ Особенности выполнения программ AVR-МК
Особенности выполнения программ AVR-МК Презентация Разделение властей и система противовесов в Афинах
Презентация Разделение властей и система противовесов в Афинах  Изображение весны в творчестве русских живописцев
Изображение весны в творчестве русских живописцев Православный праздник пасхи
Православный праздник пасхи Бұл қазақ халқының ең бірінші панасы
Бұл қазақ халқының ең бірінші панасы Моє хобі - футбол
Моє хобі - футбол Грузовая авианакладная
Грузовая авианакладная Плиты с деревянным каркасом. Конструирование и расчет. Пластмассовые плиты
Плиты с деревянным каркасом. Конструирование и расчет. Пластмассовые плиты Презентация на тему Можно ли жить и не дышать?
Презентация на тему Можно ли жить и не дышать? Школа футбольного арбитра. Правило 9. Мяч в игре и не в игре
Школа футбольного арбитра. Правило 9. Мяч в игре и не в игре Презентация Металлоизделия
Презентация Металлоизделия Онкология Лекция для студентов III курса врачебных факультетов Профессор В.И.Тихонов
Онкология Лекция для студентов III курса врачебных факультетов Профессор В.И.Тихонов  SLF4J project
SLF4J project  Русская прялка
Русская прялка Граждане как субъекты административного права
Граждане как субъекты административного права Датчики. Лямбда-зонд, датчики частоты вращения коленвала и распредвал
Датчики. Лямбда-зонд, датчики частоты вращения коленвала и распредвал Крещение Господне
Крещение Господне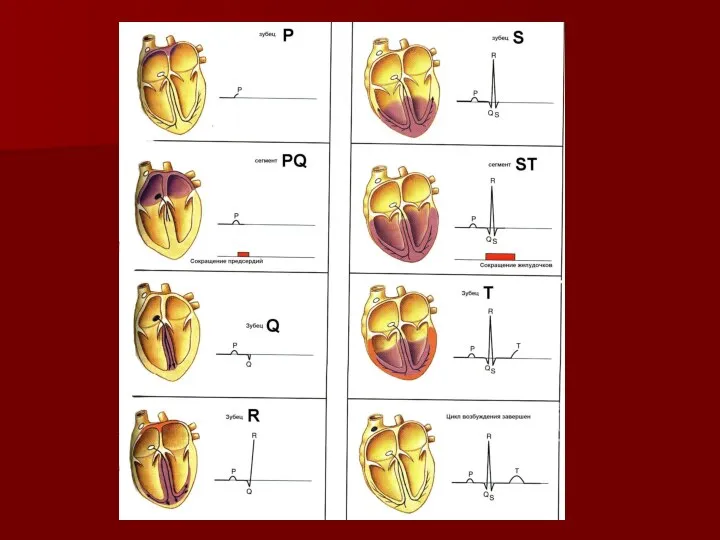 ЭКГ у детей
ЭКГ у детей История медицины в Китае и Тибете
История медицины в Китае и Тибете  Министерство Юстиции РФ
Министерство Юстиции РФ  Киберпреступность
Киберпреступность